有些语言学者似乎认为我们处理语言的方式是独一无二的,也就是用一些框架填充另一些框架来展示一些复杂的结构形式。但是想一想我们在理解视觉场景时是不是也常常会做同样复杂的事。语言智能组在处理一个短语时必须能够打断自己,去攻克另一个短语的组件,这个过程涉及一些复杂的短时记忆技能。而在视觉中,一定也有一些相似的程序会把景象分裂开来,然后把它们表述成组合在一起的客体和关系。下页的图显示了这类程序可以多么相似。在语言中,主要问题是认出“带着”和“出去”两个词都属于同一个动词短语,尽管它们在时间上是分开的。在视觉中,主要的问题是要识别出桌子的两个区域是同一客体的组成部分,尽管它们在空间上是分开的。
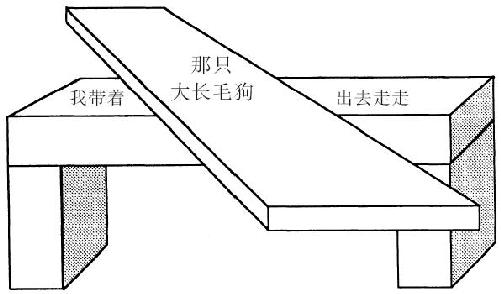
还要注意,我们看不到充当桌腿的那些积木的顶端,但我们一点儿也不怀疑它们会在哪里结束。与此相似,语言中短语的终点也常常没有标记,但我们也能够知道它会在哪里结束。在“The thief who took the moon moved it to Paris”(偷走了月亮的小偷把它移到了巴黎)这句话中,“who”这个词是新框架开始的标志,但是没有一个特别的词会提示短语结束了。为什么我们不会把“the moon”错误地安排给那个假短语“The moon moved it to Paris”中的“行动者”呢?这是因为我们先听到的是“……who took the moon”,它把“the moon”与“took”的Trans-框架中的“对象”代原体连在了一起,所以它就不能再充当“moved”框架中的“行动者”了。“The thief”仍然可以充当这一角色。我并不是想说我们永远不能把同样的短语安排给两个不同的角色,只是说一个好的讲话者会谨慎选择语言形式,不会不小心发生这种事。
我们处理短语式结构的能力是先在语言中还是先在视觉中发展的呢?在我们的祖先中,视觉比语言发展要早得多,所以如果这些能力是相关的,那么很有可能发展出语言智能组的那些基因变体开始时先影响了我们视觉系统的结构。今天我们无法确认这种推测,但未来的遗传学也许能够通过检查产生相应脑结构的基因来追溯许多此类关系的起源。