6.2 电子商务数据模型中的更新
04-13Ctrl+D 收藏本站
在股票的例子里更新MongoDB文档中的这个或那个属性是很容易的。但生产环境中的数据模型和真实的应用程序中,会出现不少困难,对指定属性的更新可能不再是简单的一行语句。在后续的内容里,我会使用上两章里出现的电子商务数据模型作为示例,演示在生产环境中的电子商务网站里可能看到的更新。其中某些更新很直观,而另一些则不那么直观。但总的来说,我们会对第4章中设计的Schema有更深入的认识,对MongoDB更新语言的特性和限制有更进一步的理解。
6.2.1 产品与分类
本节你将看到一些实际的针对性更新的例子,首先了解如何计算产品平均评分,随后是更复杂的维护分类层级的任务。
1. 产品平均评分
产品可以运用很多更新策略。假设管理员有一个界面可用于编辑产品信息,最简单的更新涉及获取当前产品文档,将其与用户编辑的文档进行合并,执行一次文档替换。有时候,可能只需更新几个值,显然这时针对性更新是更好的选择。计算产品平均评分就是这种情况。因为用户会基于平均评分对产品列表排序,可以将该评分保存在产品文档中,在添加或删除评论时进行更新。
执行此类更新的方式很多,下面就是其中之一:
average = 0.0
count = 0
total = 0
cursor = @reviews.find({:product_id => product_id}, :fields => [\"rating\"])
while cursor.has_next? && review = cursor.next
total += review[\'rating\']
count += 1
end
average = total / count
@products.update({:_id => BSON::ObjectId(\"4c4b1476238d3b4dd5003981\")},
{\'$set\' => {:total_reviews => count, :average_review => average}})
这段代码聚合并处理了每条产品评论中的rating字段,然后计算了平均值。实际上,我们迭代了每个评分,借此计算产品的总评分,这节省了一次额外的count函数调用。有了评论的总条数和平均评分之后,在代码中使用$set执行一次针对性更新。
关注性能的用户可能会尽量避免每次更新时重新聚合所有产品评论这种做法。此处提供的方法虽然保守,但在大多数情况下还是可以接受的。也会有其他策略,举例来说,可以在产品文档中保存额外的字段来缓存评论的总评分。在插入一条新评论后,查询产品以获得当前评论总数和总评分,随后计算平均值,用如下选择器发起一次更新:
{\'$set\' => {:average_review => average, :ratings_total => total},
\'$inc\' => {:total_reviews => 1}})
只有使用典型数据对系统进行评测之后才能确定哪种方式更好。但这个例子恰恰说明了MongoDB通常提供多种可选方法,应用程序的需求可用于帮助确定哪种方法是最好的。
2. 分类层级
在很多数据库中都没有简单的方法来表示分类层级,虽然文档结构对此有所帮助,但MongoDB里的情况也差不多。文档可以针对读取进行优化,因为每个分类都能包含其祖先的列表。唯一麻烦的要求是始终保持最新的祖先列表。让我们来看一个例子。
首先需要一个通用的方法更新任意给定分类的祖先列表。下面是一个可行方案:
def generate_ancestors(_id, parent_id)
ancestor_list =
while parent = @categories.find_one(:_id => parent_id) do
ancestor_list.unshift(parent)
parent_id = parent[\'parent_id\']
end
@categories.update({:_id => _id},
{\"$set\" {:ancestors => ancestor_list}})
end
该方法回溯了分类层级,连续查询每个节点的parent_id属性,直到根节点(parent_id是nil的节点)为止。总之,它构建了一个有序的祖先列表,保存在ancestor_list数组里。最后,使用$set更新分类的ancestors属性。
既然已经有了基本的构建模块,那就让我们来看看插入新分类的过程吧。假设有一个简单的分类层级,如图6-1所示。
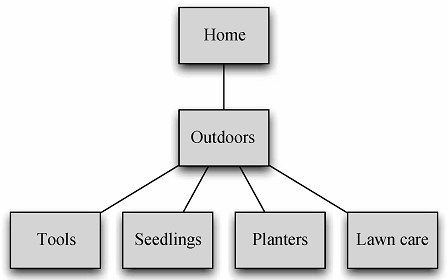
图6-1 初始的分类层级
假设想在Home分类下添加一个名为Gardening的新分类,插入新分类文档后运行方法来生成它的祖先列表:
category = {
:parent_id => parent_id,
:slug => \"gardening\",
:name => \"Gardening\",
:description => \"All gardening implements, tools, seeds, and soil.\"
}
gardening_id = @categories.insert(category)
generate_ancestors(gardening_id, parent_id)
图6-2显示了更新后的树。
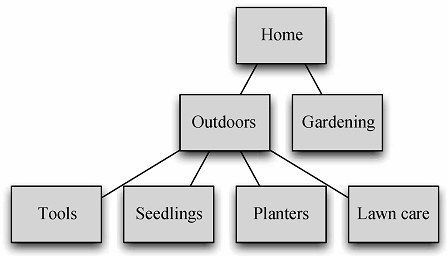
图6-2 添加Gardening分类
这太简单了。但如果现在想把Outdoors分类放在Gardening下面又会怎么样呢?这就有点复杂了,因为要修改很多分类的祖先列表。可以从把Outdoors的 parent_id修改为Gardening的_id开始做起,这还不是很困难:
@categories.update({:_id => outdoors_id},
{\'$set\' => {:parent_id => gardening_id}})
因为移动了Outdoors分类,所以其所有后代的祖先列表都无效了。可以查询所有祖先列表里有Outdoors的分类,随后重新生成它们的祖先列表。MongoDB可深入数组进行查询,因而能轻而易举地完成这项工作:
@categories.find({\'ancestors.id\' => outdoors_id}).each do |category|
generate_ancestors(category[\'_id\'], outdoors_id)
end
这就是一个处理分类parent_id属性的更新的方法,图6-3显示了变更后的分类排列方式。
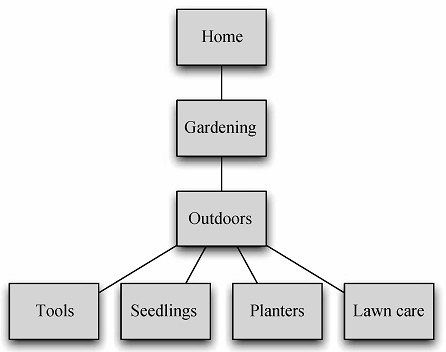
图6-3 最终状态的分类树
要是想要修改分类名称又会怎么样呢?如果将Outdoors分类的名称改为The Great Outdoors,那么还必须修改其他祖先列表中出现Outdoors的分类。这时你会想“看到没?这种情况下去正规化就麻烦了”。但了解到不用重新计算祖先列表就能执行这个更新后,你应该会感觉好多了。方法如下:
doc = @categories.find_one({:_id => outdoors_id})
doc[\'name\'] = \"The Great Outdoors\"
@categories.update({:_id => outdoors_id}, doc)
@categories.update({\'ancestors.id\' => outdoors_id},
{\'$set\' => {\'ancestors.$\'=> doc}}, :multi => true)
我们先取得了Outdoors文档,在本地修改它的name属性,随后通过替换进行更新,最后再用修改后的Outdoors文档来替换多个祖先列表中的旧文档。我们通过位置操作符和多项更新实现了这个操作。多项更新很容易理解;回忆一下,如果希望修改能作用于所有选择器匹配到的文档,需要指定:multi => true。此处,我们想更新所有祖先列表中有Outdoors的分类。
位置操作符更巧妙一些。假设无从获知Outdoors分类会出现在给定分类祖先列表中的什么地方,此时就需要更新操作符针对任意文档动态定位Outdoors分类在数组中的位置。说到位置操作符,即ancestors.$中的$,代替了查询选择器匹配到的数组下标,这才使这个更新操作成为可能。
因为需要更新数组中单独的子文档,总是会用到位置操作符。总的来说,在要处理子文档数组时,这些更新分类层级的技术都能适用。
6.2.2 评论
评论并不是完全“平等”的,这就是应用程序会允许用户对评论进行投票的原因。投票很简单,它们指出了哪些评论是有用的。我们已经对评论做了建模,其中能缓存总投票数以及投票者ID的列表。评论文档中相关的部分看起来是这样的:
{helpful_votes: 3,
voter_ids: [ ObjectId(\"4c4b1476238d3b4dd5000041\"),
ObjectId(\"7a4f0376238d3b4dd5000003\"),
ObjectId(\"92c21476238d3b4dd5000032\")
]}
可以通过针对性更新来记录用户投票。使用$push操作符将投票者的ID添加到列表里,使用$inc操作符来增加总投票数,这两个操作都在同一个更新操作里:
db.reviews.update({_id: ObjectId(\"4c4b1476238d3b4dd5000041\")},
{$push: {voter_ids: ObjectId(\"4c4b1476238d3b4dd5000001\")},
$inc: {helpful_votes: 1}
})
大多数情况下这个更新没有问题,但我们需要确保仅当正在投票的用户尚未对该评论投过票时才能进行更新。因此要修改此处的查询选择器,只匹配voter_ids数组中不包含要添加的ID的情况。使用$ne查询操作符就能轻松实现了:
query_selector = {_id: ObjectId(\"4c4b1476238d3b4dd5000041\"),
voter_ids: {$ne: ObjectId(\"4c4b1476238d3b4dd5000001\")}}
db.reviews.update(query_selector,
{$push: {voter_ids: ObjectId(\"4c4b1476238d3b4dd5000001\")},
$inc : {helpful_votes: 1}
})
这是一个很强大的示例,演示了MongoDB的更新机制以及如何将其用于面向文档的Schema。本例中的投票既是原子操作,又有很高的效率。原子性保证了即使在高并发环境下,也没人能投两次票。高效是因为对投票者身份的判断、更新计数器和投票者列表的操作都是在同一个服务器请求内完成的。
现在,如果最终确定使用该技术来保存投票信息,请务必保证其他对评论文档的更新都是针对性更新,因为替换更新的方式一定会导致不一致性。想象一下,假设用户通过替换更新来修改评论的内容,先要查询希望修改的文档,在查询评论和更新之间,另一个用户很有可能在为该评论投票。图6-4中就描述了这个事件序列。

图6-4 通过针对性更新和替换更新并发地修改评论时会丢失数据
很明显,T3时刻的文档替换会覆盖T2时刻发生的投票更新。使用之前描述的乐观锁技术是可以避免这种情况的,但确保本例中所有的更新都是针对性更新似乎更容易一些。
6.2.3 订单
在评论中看到的更新操作的原子性和高效性也能被运用在订单上。接下来,我们会看到如何使用针对性更新实现“添加到购物车”功能(Add to Cart)。这个过程有两步:第一步,构建一个产品文档,用来保存订单条目数组;第二步,发起一次针对性更新,标明这是一次upsert ——如果要更新的文档不存在则插入一个新文档的更新操作。(在下一节里我会详细描述upsert的。)如果订单对象不存在,该操作会创建一个新的订单对象,无缝地处理初始化以及后续“添加到购物车”的动作。1
1. 我交换使用购物车和订单这两个词,因为它们都是使用同一个文档来表示的。两者仅在文档的state字段上有所不同(文档状态是CART的表示购物车)。
我们先构建一个要添加到购物车中的示例文档:
cart_item = {
_id: ObjectId(\"4c4b1476238d3b4dd5003981\"),
slug: \"wheel-barrow-9092\",
sku: \"9092\",
name: \"Extra Large Wheel Barrow\",
pricing: {
retail: 589700,
sale: 489700
}
}
构建该文档时,很可能就是查询products集合,随后抽取出需要保存为订单条目的字段。产品中的_id、sku、slug、name和price字段应该就够了2。有了购物车明细文档,就可以把它upsert进订单集合了:
2. 在实际的电子商务应用程序中,会需要在结账时验证一下价格是否发生变化。
selector = {user_id: ObjectId(\"4c4b1476238d3b4dd5000001\"),
state: \'CART\',
\'line_items.id\':
{\'$ne\': ObjectId(\"4c4b1476238d3b4dd5003981\")}
}
update = {\'$push\': {\'line_items\': cart_item}}
db.orders.update(selector, update, true, false)
为了让代码更清晰一点,我分别构造了查询选择器和更新文档。更新文档将购物车明细文档塞进订单条目数组里。查询选择器中指出仅在数组中不存在特定订单条目时,更新才会成功。当然,用户第一次执行“添加到购物车”功能时,根本就没有购物车。这就是此处使用upsert的原因。upsert会根据查询选择器和更新文档里的键和值构建文档。因此,初始的upsert会产生如下订单文档:
{
user_id: ObjectId(\"4c4b1476238d3b4dd5000001\"),
state: \'CART\',
line_items: [{
_id: ObjectId(\"4c4b1476238d3b4dd5003981\"),
slug: \"wheel-barrow-9092\",
sku: \"9092\",
name: \"Extra Large Wheel Barrow\",
pricing: {
retail: 589700,
sale: 489700
}
}]
}
随后需要再发起一次针对性更新,确保明细数量和订单小计的正确性:
selector = {user_id: ObjectId(\"4c4b1476238d3b4dd5000001\"),
state: \"CART\",
\'line_items.id\': ObjectId(\"4c4b1476238d3b4dd5003981\")}
update = {$inc:
{\'line_items.$.qty\': 1,
sub_total: cart_item[\'pricing\'][\'sale\']
}
}
db.orders.update(selector, update)
请注意,这里使用了$inc操作符来更新订单小计和单独条目的数量。第二条更新使用了上一节介绍的位置操作符($),方便了不少。需要第二条更新的主要原因是要处理用户单击添加到购物车的东西已经存在于购物车中的情况。针对这种情况,第一条更新不会成功,但仍然需要调整数量和小计。因此,在两次单击手推车的“添加到购物车”功能按钮后,购物车看起来应该是这样的:
{
\'user_id\': ObjectId(\"4c4b1476238d3b4dd5000001\"),
\'state\' : \'CART\',
\'line_items\': [{
_id: ObjectId(\"4c4b1476238d3b4dd5003981\"),
qty: 2,
slug: \"wheel-barrow-9092\",
sku: \"9092\",
name: \"Extra Large Wheel Barrow\",
pricing: {
retail: 589700,
sale: 489700
}
}],
subtotal: 979400
}
现在购物车里有两部手推车了,小计上也有所体现。
还需要更多操作才能完整实现一个购物车,其中大多数都能通过一个或者多个针对性更新来实现,例如从购物车中删除一项,或者清空购物车。如果这还不明显,接下来的小节中会描述每个查询操作符,应该会让一切都清晰明了的。在实际的订单处理中,可以通过推进订单状态以及应用每个状态的处理逻辑来处理订单。下一节会演示这些内容,而且我还会解释原子文档处理和findAndModify命令。