9.3 分片集群的查询与索引
04-13Ctrl+D 收藏本站
从应用程序的角度来看,查询分片集群和查询单个mongod没什么区别。这两种情况下,查询接口和迭代结果集的过程是一样的。但在外表之下,两者还是有区别的,有必要了解一下其中的细节。
9.3.1 分片查询类型
假设正在查询一个分片集群,为了返回一个恰当的查询响应,mongos要与多少个分片进行交互?稍微思考一下,就能发现这与分片键是否出现在查询选择器里有关。还记得吗?配置服务器(就是mongos)维护了一份分片范围的映射关系,就是我们在本章早些时候看到的块。如果查询包含分片键,那么mongos通过块数据能很快定位哪个分片包含查询的结果集。这称为针对性查询(targeted query)。
但是,如果分片键不是查询的一部分,那么查询计划器就不得不访问所有分片来完成查询。这称为全局查询或分散/聚集查询(scatter/gather query)。图9-3对这两种查询做了描述。
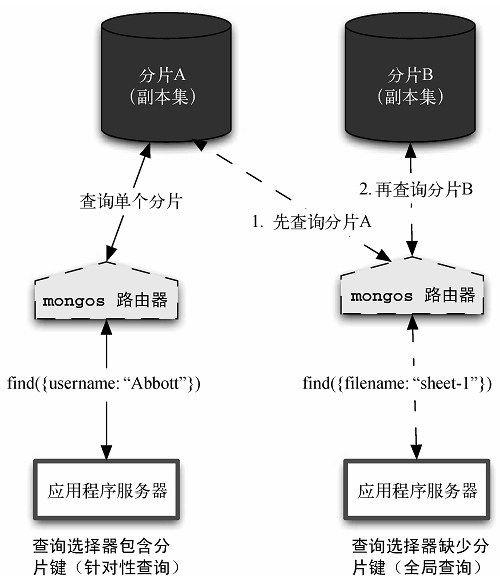
图9-3 针对副本集的针对性查询与全局查询
针对任意指定的分片集群查询,explain命令能显示其详细查询路径。让我们先来看一个针对性查询,此处要查询位于集合第一个块里的文档。
> selector = {username: \"Abbott\",
\"_id\" : ObjectId(\"4e8a1372238d3bece8000012\")}
> db.spreadsheets.find(selector).explain
{
\"shards\" : {
\"shard-b/arete:30100,arete:30101\" : [
{
\"cursor\" : \"BtreeCursor username_1__id_1\",
\"nscanned\" : 1,
\"n\":1,
\"millis\" : 0,
\"indexBounds\" : {
\"username\" : [
[
\"Abbott\",
\"Abbott\"
]
],
\"_id\" : [
[
ObjectId(\"4d6d57f61d41c851ee000092\"),
ObjectId(\"4d6d57f61d41c851ee000092\")
]
]
}
}
]
},
\"n\" : 1,
\"nscanned\" : 1,
\"millisTotal\" : 0,
\"numQueries\" : 1,
\"numShards\" : 1
}
explain的结果清晰地说明查询命中了一个分片——分片B,返回了一个文档。1查询计划器很聪明地使用了分片键前缀的子集来路由查询。也就是说你也可以单独根据用户名进行查询:
1. 注意,简单起见,在这个执行计划以及接下来的执行计划里,我省略了很多字段。
> db.spreadsheets.find({username: \"Abbott\"}).explain
{
\"shards\" : {
\"shard-b/arete:30100,arete:30101\" : [
{
\"cursor\" : \"BtreeCursor username_1__id_1\",
\"nscanned\" : 801,
\"n\" : 801,
}
]
},
\"n\" : 801,
\"nscanned\" : 801,
\"numShards\" : 1
}
该查询总共返回了801个用户文档,但仍然只访问了一个分片。
那么全局查询又会怎么样呢?也可以方便地使用explain命令。下面就是一个根据filename字段进行查询的例子,其中既没有用到索引,也没有用到分片键:
> db.spreadsheets.find({filename: \"sheet-1\"}).explain
{
\"shards\" : {
\"shard-a/arete:30000,arete:30002,arete:30001\" : [
{
\"cursor\" : \"BasicCursor\",
\"nscanned\" : 102446,
\"n\" : 117,
\"millis\" : 85,
}
],
\"shard-b/arete:30100,arete:30101\" : [
{
\"cursor\" : \"BasicCursor\",
\"nscanned\" : 77754,
\"nscannedObjects\" : 77754,
\"millis\" : 65,
}
]
},
\"n\" : 2900,
\"nscanned\" : 180200,
\"millisTotal\" : 150,
\"numQueries\" : 2,
\"numShards\" : 2
}
如你所想,该全局查询在两个分片上都进行了表扫描。如果该查询与你的应用程序有关,你一定想在filename字段上增加一个索引。无论哪种情况,它都会搜索整个集群以返回完整结果。
一些查询要求并行获取整个结果集。例如,假设想根据修改时间对电子表格进行排序。这要求在mongos路由进程里合并结果。没有索引,这样的查询会非常低效,并且会屡遭禁止。因此,在下面这个查询最近创建文档的例子里,你会先创建必要的索引:
> db.spreadsheets.ensureIndex({updated_at: 1})
> db.spreadsheets.find({}).sort({updated_at: 1}).explain
{
\"shards\" : {
\"shard-a/arete:30000,arete:30002\" : [
{
\"cursor\" : \"BtreeCursor updated_at_1\",
\"nscanned\" : 102446,
\"n\" : 102446,
\"millis\" : 191,
}
],
\"shard-b/arete:30100,arete:30101\" : [
{
\"cursor\" : \"BtreeCursor updated_at_1\",
\"nscanned\" : 77754,
\"n\" : 77754,
\"millis\" : 130,
}
]
},
\"n\" : 180200,
\"nscanned\" : 180200,
\"millisTotal\" : 321,
\"numQueries\" : 2,
\"numShards\" : 2
}
正如预期的那样,游标扫描了每个分片的updated_at索引,以此返回最近更新的文档。
更有可能出现的查询是返回某个用户最新修改的文档。同样,你要创建必要的索引,随后发起查询:
> db.spreadsheets.ensureIndex({username: 1, updated_at: -1})
> db.spreadsheets.find({username: \"Wallace\"}).sort(
{updated_at: -1}).explain
{
\"clusteredType\" : \"ParallelSort\",
\"shards\" : {
\"shard-1-test-rs/arete:30100,arete:30101\" : [
{
\"cursor\" : \"BtreeCursor username_1_updated_at_-1\",
\"nscanned\" : 801,
\"n\" : 801,
\"millis\" : 1,
}
]
},
\"n\" : 801,
\"nscanned\" : 801,
\"numQueries\" : 1,
\"numShards\" : 1
}
关于这个执行计划,有几个需要注意的地方。首先,该查询指向了单个分片。因为你指定了分片键,所以查询路由器可以找出哪个分片包含了相关的块。随后你就会发现排序并不需要访问所有的分片;当排序查询中包含分片键,所要查询的分片数量通常都能有所减少。本例中,只需访问一个分片,也能想象类似的查询,即需要访问几个分片,所访问的分片数量少于分片总数。
第二个需要注意的地方是分片使用了{username: 1, updated_at: -1}索引来执行查询。这说明了一个很重要的内容,即分片集群是如何处理查询的。通过分片键将查询路由给指定分片,一旦到了某个分片上,由分片自行决定使用哪个索引来执行该查询。在为应用程序设计查询和索引时,请牢记这一点。
9.3.2 索引
你刚看了一些例子,其中演示了索引查询是如何在分片集群里工作的。有时,如果不确定某个查询是怎么解析的,可以试试explain。通常这都很简单,但是在运行分片集群时,有几点关于索引的内容应该牢记于心,下面我会逐个进行说明。
每个分片都维护了自己的索引。这点应该是显而易见的,当你在分片集合上声明索引时,每个分片都会为它那部分集合构建独立的索引。例如,在上一节里,你通过
mongos发起了db.spreasheets.ensureIndex命令,每一个分片都单独处理了索引创建命令。由此可以得出一个结论,每个分片上的分片集合都应该拥有相同的索引。如果不是这样的话,查询性能会很不稳定。
分片集合只允许在
_id字段和分片键上添加唯一性索引。其他地方不行,因为这需要在分片间进行通信,实施起来很复杂,而且相信这么做速度也很慢,没有实现的价值。
一旦理解了如何进行查询的路由选择,以及索引是如何工作的,你应该就能针对分片集群写出漂亮的查询和索引了。第7章里几乎所有关于索引和查询优化的建议都能用得上,此外,在必要的时候,你还可以使用强大的explain工具。