并发编程可以让开发者实现并行的算法以及编写充分利用多处理器和多核性能的程序。在当前大部分主流的编程语言里,如C、C++、Java等,编写、维护和调试并发程序相比单线程程序而言要困难很多。而且,也不可能总是为了使用多线程而将一个过程切分成更小的粒度来处理。不管怎么说,由于线程本身的性能损耗,多线程编程不一定能够达到我们想要的性能,而且很容易犯错误。
一种解决办法就是完全避免使用线程。例如,可以使用多个进程将重担交给操作系统来处理。但是,这里有个劣势就是,我们必须处理所有进程间通信,通常这比共享内存的并发模型有更多的开销。
Go语言的解决方案有3个优点。首先,Go语言对并发编程提供了上层支持,因此正确处理并发是很容易做到的。其次,用来处理并发的goroutine比线程更加轻量。第三,并发程序的内存管理有时候是非常复杂的,而Go语言提供了自动垃圾回收机制,让程序员的工作轻松很多。
Go语言为并发编程而内置的上层API基于CSP模型(Communicating Sequential Processes)。这就意味着显式锁(以及所有在恰当的时候上锁和解锁所需要关心的东西)都是可以避免的,因为 Go语言通过线程安全的通道发送和接受数据以实现同步。这大大地简化了并发程序的编写。还有,通常一个普通的桌面计算机跑十个二十个线程就有点负载过大了,但是同样这台机器却可以轻松地让成百上千甚至过万个goroutine进行资源竞争。Go语言的做法让程序员理解自己的程序变得更加容易,他们可以从自己希望程序实现什么样的功能来推断,而不是从锁和其他更底层的东西来考虑。
虽然其他大部分语言对非常底层的并发操作(原子级的两数相加、比较、交换等)和其他一些底层的特性例如互斥量都提供了支持,但是在主流语言里,还没有在语言层面像 Go语言一样直接支持并发操作的(以附加库方式存在的方式并不能算是语言的组成部分)。
除了作为本章主题的Go语言在较高层次上对并发的支持以外,Go和其他语言一样也提供了对底层功能的支持。在标准库的sync/atomic包里提供了最底层的原子操作功能,包括相加、比较和交换操作。这些高级功能是为了支持实现线程安全的同步算法和数据结构而设计的,但是这些并不是给程序员准备的。Go语言的sync包还提供了非常方便的底层并发原语:条件等待和互斥量。这些和其他大多数语言一样属于较高层次的抽象,因此程序员通常必须使用它们。
Go语言推荐程序员在并发编程时使用语言的上层功能,例如通道和goroutine。此外, sync.Once 类型可以用来执行一次函数调用,不管程序中调用了多少次,这个函数只会执行一次,还有sync.WaitGroup类型提供了一个上层的同步机制,后面我们会看到。
在第5章(5.4节)我们就已经接触过通道和goroutine的基本用法,已经讲过的内容不会在这里再讲一遍,但是内容主要还是这些,所以如果能快速复习一遍之前讲过的内容也许会很有帮助。
这一章我们首先对Go语言并发编程的几个关键概念做一个大概的了解,然后还有5个关于并发编程的完整程序作为示例,并展示了 Go语言中并发编程的范式。第一个例子展示了如何创建一个管道,为了最大化管道的吞吐量,管道里每一部分都各自执行一个独立的goroutine。第二个例子展示了怎么将一个工作切分成让固定的若干个goroutine去完成,而每部分的输出结果都是独立的。第三个例子展示了如何创建一个线程安全的数据结构,不需要使用锁或者其他底层的原语。第四个例子使用了3种不同的方法,展示了如何使用固定的若干个goroutine来独立处理其中的一部分工作,并将最终的结果合并在一块。第五个例子展示了如何根据需要来动态创建goroutine并将每个goroutine的工作输出到一个结果集中。
7.1 关键概念
在并发编程里,我们通常想将一个过程切分成几块,然后让每个goroutine各自负责一块工作,除此之外还有main函数也是由一个单独的goroutine 来执行的(为了方便起见,我们将main函数所在的goroutine称为主goroutine,其他附加创建用来负责处理相应工作的goroutine简称为工作goroutine,以后如果没有特别说明,我们统一沿用这种叫法,虽然本质上它们都是一样的)。每个工作goroutine执行完毕后可以立即将结果输出,或者所有的工作goroutine都完成后再做统一处理。
尽管我们使用Go语言上层的API来处理并发,但仍有必要去避免一些陷阱。例如,其中一个常见的问题就是很可能当程序完成时我们没有得到任何结果。因为当主goroutine退出后,其他的工作 goroutine 也会自动退出,所以我们必须非常小心地保证所有工作 goroutine 都完成后才让主goroutine退出。
另一个陷阱就是容易发生死锁,这个问题有一点和第一个陷阱是刚好相反的,就是即使所有的工作已经完成了,但是主 goroutine和工作 goroutine 还存活,这种情况通常是由于工作完成了但是主 goroutine 无法获得工作 goroutine的完成状态。死锁的另一种情况就是,当两个不同的goroutine(或者线程)都锁定了受保护的资源而且同时尝试去获得对方资源的时候,如图7-1所示。也就是说,只有在使用锁的时候才会出现,所以这种风险一般在其他语言里比较常见,但在Go语言里并不多,因为Go程序可以使用通道来避免使用锁。
为了避免程序提前退出或不能正常退出,常见的做法是让主goroutine在一个done通道上等待,根据接收到的消息来判断工作是否完成了(我们马上就能看到,7.2.2节和7.2.4节也有介绍,也可以使用一个哨兵值作为最后一个结果发送,不过相对其他办法来说这就显得有点拙劣了)。
另外一种避免这些陷阱的办法就是使用sync.WaitGroup来让每个工作goroutine报告自己的完成状态。但是,使用sync.WaitGroup本身也会产生死锁,特别是当所有工作goroutine都处于锁定状态的时候(等待接受通道的数据)调用 sync.WaitGroup.Wait。后面我们会看到如何使用sync.WaitGroup(参见7.2.5节)。
就算只使用通道,在Go语言里仍然可能发生死锁。举个例子,假如我们有若干个goroutine可以相互通知对方去执行某个函数(向对方发一个请求),现在,如果这些被请求执行的函数中有一个函数向执行它的goroutine发送了一些东西,例如数据,死锁就发生了。如图7-2所示(后面我们还会看到这种死锁的另一种情况)。
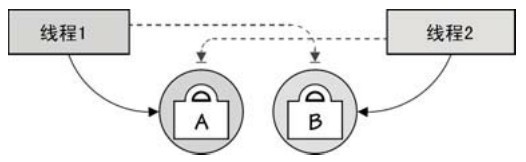
图7-1 死锁:两个或多个阻塞线程试图取得对方的锁
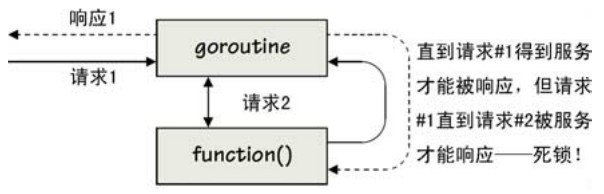
图7-2 死锁:一个试图用对自身的请求来服务于请求的goroutine
通道为并发运行的goroutine之间提供了一种无锁通信方式(尽管实现内部可能使用了锁,但无需我们关心)。当一个通道发生通信时,发送通道和接受通道(包括它们对应的goroutine)都处于同步状态。
默认情况下,通道是双向的,也就是说,既可以往里面发送数据也可以从里面接收数据。但是我们经常将一个通道作为参数进行传递而只希望对方是单向使用的,要么只让它发送数据,要么只让它接收数据,这个时候我们可以指定通道的方向。例如,chan<- Type 类型就是一个只发送数据的通道。我们之前的章节里并没有这样用过,一来没这个必要,用 chan Type就行,二来还有很多其他的东西要学习。但是从现在开始,我们会在所有合适的地方使用单向的通道,因为它们会提供额外的编译期检查,这是非常好的处理方式。
本质上说,在通道里传输布尔类型、整型或者 float64 类型的值都是安全的,因为它们都是通过复制的方式来传送的,所以在并发时如果不小心大家都访问了一个相同的值,这也没有什么风险。同样,发送字符串也是安全的,因为Go语言里不允许修改字符串。
但是Go语言并不保证在通道里发送指针或者引用类型(如切片或映射)的安全性,因为指针指向的内容或者所引用的值可能在对方接收到时已被发送方修改。所以,当涉及指针和引用时,我们必须保证这些值在任何时候只能被一个goroutine访问得到,也就是说,对这些值的访问必须是串行进行的。除非文档特别声明传递这个指针是安全的,比如,*regexp.Regexp 可以同时被多个goroutine访问,因为这个指针指向的值的所有方法都不会修改这个值的状态。
除了使用互斥量实现串行化访问,另一种办法就是设定一个规则,一旦指针或者引用发送之后发送方就不会再访问它,然后让接收者来访问和释放指针或者引用指向的值。如果双方都有发送指针或者引用的话,那就发送方和接受方都要应用这种机制(我们会在7.2.4.3节看到一个使用这个机制的例子),这种方法的问题就是使用者必须足够自律。第三种安全传输指针和引用的方法就是让所有导出的方法不能修改其值,所有可修改值的方法都不引出。这样外部可以通过引出的这些方法进行并发访问,但是内部实现只允许一个goroutine去访问它的非导出方法(例如在它们的包里,包将会在第9章介绍)。
Go语言里还可以传送接口类型的值,也就是说,只要这个值实现了接口定义的所有方法,就可以以这个接口的方式在通道里传输。只读型接口的值可以在任意多个goroutine里使用(除非文档特别声明),但是对于某些值,它虽然实现了这个接口的方法,但是某些方法也修改了这个值本身的状态,就必须和指针一样处理,让它的访问串行化。
举个例子,如果我们使用 image.NewRGBA函数来创建一个新的图片,我们得到一个*image.RGBA类型的值。这个类型实现了image.Image接口定义的所有方法(只有一个读取的方法,理所当然是只读型的接口)和draw.Image接口(这个接口除了实现了image.Image接口的所有方法之外,还实现了一个 Set方法)。所以如果我们只是让某个函数去访问一个image.Image值的话,我们可以将这个 *image.RGBA值随意发送给多个goroutine。(不幸的是,这种安全性是随时可以颠覆的,比如说,接受方可以使用一个类型断言将这个值转换成draw.Image 接口类型,因此,就必须要有一种机制能防止这种事情的发生。)或者我们希望在多个 goroutine 里访问甚至修改同一个*image.RGBA的值,就应该以 *image.RGBA 或者draw.Image类型来传送,不管哪种方式,都必须让这个值的访问是串行的。
使用并发的最简单的一种方式就是用一个 goroutine 来准备工作,然后让另一个 goroutine来执行处理,让主goroutine和一些通道来安排一切事情。例如,下面的代码是如何在主goroutine里创建一个名为“jobs”的通道和一个叫“done”的通道。
jobs := make(chan Job)
done := make(chan bool, len(jobList))
这里我们创建了一个没有缓冲区的jobs通道,用来传递一些自定义Job类型的值。我们还创建了一个done通道,它的缓冲区大小和任务列表的数量是相对应的,任务列表jobList是Job类型(它的初始化这里我们没有列出来)。
只要设置了通道和任务列表(jobList),我们就可以开始干活了。
go func {
for _, job := range jobList {
jobs <- job // 阻塞,等待接收
}
close(jobs)
}
这段代码创建了一个goroutine(goroutine#1),它遍历jobList切片然后将每一个工作发送到jobs通道。因为通道是没有缓冲的,所以goroutine#1会马上阻塞,直到有别的goroutine从这个通道里将任务读取出去。发送完所有任务之后,就关闭 jobs 通道,这样接收工作的goroutine就会知道什么时候没有其他工作了。
这段代码所表达的语义还不止这些。例如,goroutine#1会直到for循环结束才关闭jobs通道,而且goroutine#1会和创建它的主goroutine并发执行。还有,go声明语句会立即返回,主 goroutine(main函数所在的goroutine)继续执行后面的代码,但是由于 jobs 通道是没有缓冲的,所以goroutine#1会反复执行这样一个过程:往jobs里发送一个任务,等待任务被接收,继续往jobs里发送任务,等到任务被接收……直到jobList任务列表里的所有任务都被处理完后,关闭jobs通道。显然,从for循环开始执行到关闭jobs之间得耗一段时间。
go func {
for job := range jobs { // 等待数据发送
fmt.Println(job) // 完成一项工作
done <- true
}
}
这是我们创建的第二个goroutine(goroutine#2),遍历jobs通道,并处理(这里就是打印出来),然后将完成状态true(其实什么都可以,因为我们这里只关心往done里发了多少个值,而不是实际的什么值)发送到done通道。
同理,这个go语句也是立即返回的,for循环会阻塞直到有其他的goroutine(在我们这个例子里,发送数据的是goroutine#1)往通道里发送了数据。此时,整个进程共有3个并发的goroutine在运行,主goroutine、goroutine#1和goroutine#2,如图7-3所示。
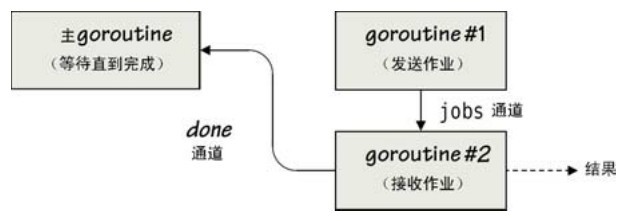
图7-3 并发独立的准备与处理
当goroutine#1发送了一个任务然后等待的时候,goroutine#2就直接接收过来然后处理,期间 goroutine#1 仍然阻塞,一直持续到它发送第二个工作。一旦 goroutine#2 处理完一个任务,它就往done通道里发送一个true值。done通道是有缓冲的,所以这个发送操作不会被阻塞。控制流回到goroutine#2的for循环里,它接收下一个从goroutine#1发送过来的工作,如此反复,直到完成所有的工作。
for i := 0; i < len(jobList); i++ {
<-done // 阻塞,等待接收
}
主goroutine创建完两个工作goroutine后(注意不会阻塞的,所有的goroutine并发执行),继续执行最后一段代码,这段代码的目的是确保主goroutine等到所有的工作完成了才退出。
for循环迭代的次数和任务列表的大小是一样的。每次迭代都从done通道里接收一个值。每次迭代和处理工作都是同步的,只有一个工作被完成后 done 通道里才有一个值可以被接收(接收到的值将被抛弃)。所有工作完成后,done 通道发送和接收数据的次数将和迭代的次数一致,此时 for 循环也将结束。这时候主 goroutine 就可以退出了,这样我们也就保证了所有任务都能处理完毕。
对于通道的使用,我们有两个经验。第一,我们只有在后面要检查通道是否关闭(例如在一个for...range循环里,或者select,或者使用<-操作符来检查是否可以接收等)的时候才需要显式地关闭通道;第二,应该由发送端的goroutine 关闭通道,而不是由接收端的goroutine来完成。如果通道并不需要检查是否被关闭,那么不关闭这些通道并没有什么问题,因为通道非常轻量,因此它们不会像打开文件不关闭那样耗尽系统资源。
例如我们这个例子就是用for...range循环来迭代读取jobs通道的,所以我们在发送端把它给关闭了。这和我们的经验是一致的。另外,我们没必要关闭 done 通道,因为它后面并没有用在什么特别的语句里(for...range或者select等)。
这个例子所展示的是 Go语言并发编程里很典型的一种模式,虽然实际上这种情况下这么做没有什么好处。下一章还有一些例子和这个模式是差不多的,但是却非常适合使用并发。
7.2 例子
虽然Go语言里使用goroutine和通道的语法很简单,如<-、chan、go、select等,但足以应付大多数的并发场合。由于篇幅有限,本章我们无法对所有的并发编程方法都一一介绍,所以这里我们只介绍并发编程中比较常见的3种模式,分别是管道、多个独立的并发任务(需要或者不需要同步的结果)以及多个相互依赖的并发任务,然后我们看下它们如何使用 Go语言的并发支持来实现。
接下来的例子以及本章的练习对 Go语言并发编程实践进行了深入的探讨。你可以将这些实践应用到其他新程序中。
7.2.1 过滤器
第一个例子用于显示一种特定并发编程范式。这个程序可以轻松地扩展以完成更多其他可以从并发模型中获益的任务。
有Unix背景的人会很容易从Go语言的通道回忆起Unix里的管道,唯一不同的是Go语言的通道为双向而Unix管道为单向。利用管道我们可以创建一个连续管道,让一个程序的输出作为另一个程序的输入,而另一个程序的输出还可以作为其他程序的输入,等等。例如,我们可以使用Unix管道命令从Go源码目录树里得到一个Go文件列表(去除所有测试文件):
find $GOROOT/src -name "*.go" | grep -v test.go
这种方法的一个妙处就是可以非常容易地扩展。比如说,我们可以增加| xargs wc -l来列出每一个文件和它包含的行数,还可以用| sort -n得到一个按行数进行排序的文件列表。
真正的Unix风格的管道可以使用标准库里的io.Pipe函数来创建,例如Go语言标准库里就用管道来比较两个图像(在go/src/pkg/image/png/reader_test.go文件里)。除此之外,我们还可以利用Go语言的通道来创建一个Unix风格的管道,这个例子就用到了这种技术。
filter 程序(源文件是 filter/filter.go)从命令行读取一些参数(例如,指定文件大小的最大值最小值,以及只处理的文件后缀等)和一个文件列表,然后将符合要求的文件名输出,main函数的主要代码如下。
minSize, maxSize, suffixes, files := handleCommandLine
sink(filterSize(minSize, maxSize, filterSuffixes(suffixes, source(files))))
handleCommandLine函数(这里我们未显示相关代码)用到了标准库里的flag包来处理命令行参数。第二行代码展示了一条管道,从最里面的函数调用(source(files)开始)到最外面的(sink函数),为了方便大家理解,我们将管道展开如下。
channel1 := source(files)
channel2 := filterSuffixes(suffixes, channel1)
channel3 := filterSize(minSize, maxSize, channel2)
sink(channel3)
传给source函数的files是一个保存文件名的切片,然后得到一个chan string类型的通道channel1。在source函数中files里的文件名会轮流被发送到channel1。另外两个过滤函数都是传入过滤条件和chan string 通道,并各自返回它们自己的chan string 通道。其中第一个过滤器返回的通道被赋值到 channel2,第二个被赋值到channel3。每个过滤器都会迭代读传入的通道,如果符合条件,就将结果发送到输出通道(这个通道会被返回并可能会作为下一个过滤器的输入源)。sink函数会提取channel3里的每一项并打印出来。

图7-4 并发goroutine之间的管道
图7-4简略地阐明了整个filter程序发生了什么事情,sink函数是在主goroutine里执行的,而另外几个管道函数(如source、filterSuffixes和filterSize函数)都会创建各自的goroutine 来处理自己的工作。也就是说,主 goroutine的执行过程会很快地执行到sink这里,此时所有的goroutine都是并发执行的,它们要么在等待发送数据要么在等待接收数据,直到所有的文件处理完毕。
func source(files string) <-chan string {
out := make(chan string, 1000)
go func {
for _, filename := range files {
out <- filename
}
close(out)
}
return out
}
source函数创建了一个带有缓冲区的out通道用来传输文件名,因为实际测试中缓冲区可以提高吞吐量(这就是我们常说的以空间换时间)。
当输出通道创建完毕后,我们创建了一个goroutine 来遍历文件列表并将每一个文件名发送到输出通道。当所有的文件发送完毕之后我们将这个通道关闭。go 语句会立即返回,而且从发送第一个文件名到发送最后一个文件名还有最终关闭通道,这之间可能会有相当长的一个时间差。往通道里发送数据是不会阻塞的(至少,发送前1000个文件时是不会阻塞的,或者说文件数小于1000时不会阻塞),但是如果要发送更多的东西,还是会阻塞的,直到至少通道里有一个数据被接收。
之前我们提到,默认情况下通道是双向的,但我们可将一个通道限制为单向。回忆下前一节我们讲过的,chan<- Type 是一个只允许发送的通道,而<-chan Type 是一个只允许接收的通道。函数最后返回的out通道就被强制设置成了单向,我们可以从里面接收文件名。当然,直接返回一个双向的通道也是可以的,但我们这里这么做是为了更好地表达程序的思想。
go语句之后,这个新创建的goroutine就开始执行匿名函数里的工作里,它会往out通道里发送文件名,而当前的函数也会立即将out通道返回。所以,一旦调用source函数就会执行两个goroutine,分别是主goroutine和在source函数里创建的那个工作goroutine。
func filterSuffixes(suffixes string, in <-chan string) <-chan string {
out := make(chan string, cap(in))
go func {
for filename := range in {
if len(suffixes) == 0 {
out <- filename
continue
}
ext := strings.ToLower(filepath.Ext(filename))
for _, suffix := range suffixes {
if ext == suffix {
out <- filename
break
}
}
}
close(out)
}
return out
}
这是两个过滤函数中的第一个。第二个函数filterSize的代码也是类似的,所以这里就不显示了。
其实参数里的in 通道是只读或者可读写都是没有关系的,不过,这里我们在参数类型声明时指定了in是一个只读的通道(我们知道source函数返回的,也就是这个in通道,实际上就是一个只读的通道)。对应地,函数最后将双向(创建时默认就是可读写的)out通道以只读的方式返回,和之前source的做法一样。其实就算我们忽略掉所有的<-,函数也一样可以工作,但是指定了通道的方向有助于精确地表达到底我们想让程序做什么事情,并借助编译器来强制程序按照这种语义来执行。
filterSuffixes函数首先创建一个带有缓冲区的输出通道,通道缓冲区和输入通道 in的大小是一样的,以最大化吞吐量。然后程序新建一个goroutine做相应的处理。在goroutine里,遍历in通道(例如,轮流接收每个文件名)。如果没有指定任何后缀的话则任意后缀的文件名我们都接收,也就是简单地发送到输出通道里去。如果我们指定了文件名的后缀,那么只有匹配的文件名(大小写不敏感)才会发送到输出通道,其他的则被丢弃。(filepath.Ext函数返回文件名的扩展名,也就是它的后缀,包括前导的句点,如果没有匹配的话就返回一个空的字符串。)
和source函数一样,一旦所有的处理完毕,输出通道就会被关闭,尽管还需要一些时间才会执行到这里。创建goroutine之后输出通道就被函数返回了,这样管道就能从这里接收文件名。
这时,有3个goroutine会在运行,它们是主goroutine和source函数里的goroutine,以及这个函数里的goroutine。filterSize函数调用之后就会有4个goroutine,它们都会并发地执行。
func sink(in <-chan string) {
for filename := range in {
fmt.Println(filename)
}
}
source函数和两个过滤函数分别在它们各自的goroutine里并发处理,并通过通道来进行通信。sink函数在主goroutine里处理其它函数返回的最后一个通道,它迭代读取成功通过所有过滤器的文件名并进行相应输出。
sink函数的range语句遍历一个只读通道,将文件名打印出来或者等待通道被关闭,这样就可以保证主goroutine在所有工作goroutine处理完毕之前不会提前退出。
自然地,我们可以给管道增加一些额外的函数,例如过滤文件名或者处理到目前为止所有通过了过滤器的文件。只要这个函数能接收一个输入通道(前一个函数的输出通道)和返回它自己的输出通道。当然,如果我们想传一些更复杂的值,我们也可以让通道传输的是一个结构而不是一个简单的字符串。
虽然这一节里的管道程序是一个管道框架非常好的示例,不过由于每一阶段处理的东西并不多,所以从管道方案并没有得到非常大的好处。真正能够从并发中获益的管道类型是每一个阶段可能有很多的工作需要处理,或者依赖于别的其他正在被处理的项,这样每个goroutine都能尽可能充分地利用时间。
7.2.2 并发的Grep
并发编程的一种常见的方式就是我们有很多工作需要处理,且每个工作都可以独立地完成。例如,Go语言标准库里的net/http包的HTTP服务器利用这种模式来处理并发,每一个请求都在一个独立的goroutine 里处理,和其他的goroutine 之间没有任何通信。这一节我们以实现一个cgrep程序为例说明实现这种模式的一种方法,cgrep表示“并发的grep”。
和标准库里的HTTP服务不同的是,cgrep使用固定数量的goroutine来处理任务,而不是动态地根据需求来创建。(我们会在后面的7.2.5节看到一个动态创建goroutine的例子。)
cgrep程序从命令行读取一个正则表达式和一个文件列表,然后输出文件名、行号,和每个文件里所有匹配这个表达式的行。没匹配的话就什么也不输出。
cgrep1程序(在文件cgrep1/cgrep.go里)使用了3个通道,其中两个是用来发送和接收结构体的。
type Job struct {
filename string
results chan<- Result
}
我们用这个结构体来指定每一个工作,filename表示需要被处理的文件,results是一个通道,所有处理完的文件都会被发送到这里。我们可以将results定义为一个chan Result类型,但我们只往通道里发送数据,不会从里面读取数据,所以我们指定这是一个单向的只允许发送的通道。
type Result struct {
filename string
lino int
line string
}
每个处理结果都是一个Result类型的结构体,包含文件名、行号码,以及匹配的行。
func main {
runtime.GOMAXPROCS(runtime.NumCPU) // 使用所有的机器核心
if len(os.Args) < 3 || os.Args[1] == "-h" || os.Args[1] == "--help" {
fmt.Printf("usage: %s <regexp> <files>\n",filepath.Base(os.Args[0]))
os.Exit(1)
}
if lineRx, err := regexp.Compile(os.Args[1]); err != nil {
log.Fatalf("invalid regexp: %s\n", err)
} else {
grep(lineRx, commandLineFiles(os.Args[2:]))
}
}
程序的main函数的第一条语句告诉 Go 运行时系统尽可能多地利用所有的处理器,调用 runtime.GOMAXPROCS(0)仅仅是返回当前处理器的数量,但如果传入一个正整数就会设置Go运行时系统可以使用的处理器数。runtime.NumCPU函数返回当前机器的逻辑处理器或者核心的数量[1],Go语言里大多数并发程序的开始处都有这一行代码,但这行代码最终将会是多余的,因为Go语言的运行时系统会变得足够聪明以自动适配它所运行的机器。
main函数处理命令行参数(一个正则表达式和一个文件列表),然后调用grep函数来进行相应处理(我们在4.4.2节里已经看过commandLineFiles函数)。
lineRx是一个*regexp.Regexp类型(参见3.6.5节)的变量,传给grep函数并被所有的工作goroutine共享。这里有一点需要注意的,通常,我们必须假设任何共享指针指向的值都不是线程安全的。这种情况下我们必须自己来保证数据的安全性,如使用互斥量(mutex)等。或者,我们为每个工作goroutine单独提供一个值而不是共享它,这就需要多一点内存的开销。幸运的是,对于 *regexp.Regexp,Go语言的文档说这个指针指向的值是线程安全的,这就意味着我们可以在多个goroutine里共享使用这个指针。
var workers = runtime.NumCPU
func grep(lineRx *regexp.Regexp, filenames string) {
jobs := make(chan Job, workers)
results := make(chan Result, minimum(1000, len(filenames)))
done := make(chan struct{}, workers)
go addJobs(jobs, filenames, results) // 在自己的goroutine中执行
for i := 0; i < workers; i++ {
go doJobs(done, lineRx, jobs) // 每一个都在自己的goroutine中执行
}
go awaitCompletion(done, results) // 在自己的goroutine中执行
processResults(results) // 阻塞,直到工作完成
}
这个函数为程序创建了 3 个带有缓冲区的双向通道,所有的工作都会分发给工作goroutine来处理。goroutine的总数量和当前机器的处理器数相当,jobs通道和done通道的缓冲区大小也和机器的处理器数量一样,将不必要的阻塞尽可能地降到最低。(当然,我们也可以不用管实际机器的处理器数量,而让用户在命令行指定到底需要开启多少个工作goroutine。)对于 results 通道我们像前一小节的filter 程序那样使用了一个更大的缓冲区,然后使用一个自定义的minimum函数(这里不显示,参见5.6.1.2节的实现,或者cgrep.go源码)。
和之前章节的做法不同,之前通道的类型是chan bool而且只关心是否发送了东西,不关心是true还是false,我们这里的通道类型是chan struct{}(一个空结构),这样可以更加清晰地表达我们的语义。我们能往通道里发送的是一个空的结构(struct{}{}),这样只是指定了一个发送操作,至于发送的值我们不关心。
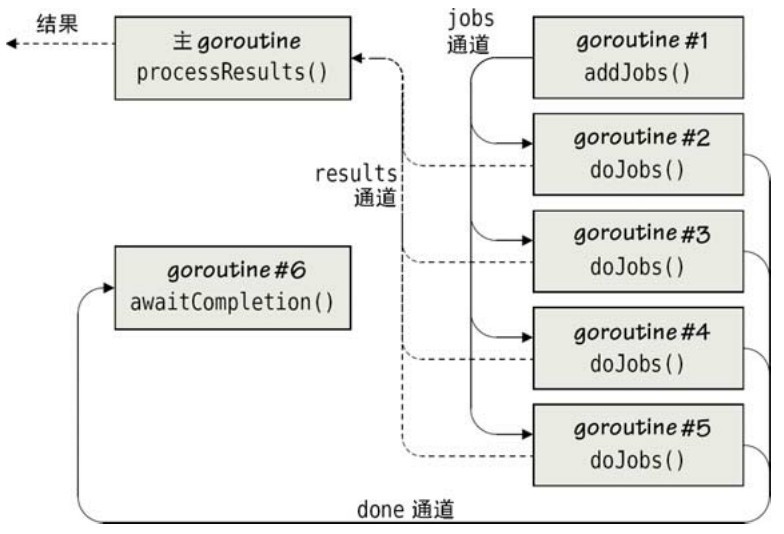
图7-5 多个独立的并发作业
有了通道之后,我们开始调用 addJobs函数往 jobs 通道里增加工作,这个函数也是在一个单独的goroutine里运行的。再调用doJobs函数来执行实际的工作,实际上我们调用了这个函数四次,也就是创建了 4 个独立的goroutine,各自做自己的事情。然后我们调用awaitCompletion函数,它在自己的goroutine里等待所有的工作完成然后关闭results通道。最后,我们调用processResults函数,这个函数是在主goroutine里执行的,这个函数处理从 results 通道接收到的结果,当通道里没有结果时就会阻塞,直到接收完所有的结果才继续执行。图7-5展示了这个程序并发部分的语义。
func addJobs(jobs chan<- Job, filenames string, results chan<- Result) {
for _, filename := range filenames {
jobs <- Job{filename, results}
}
close(jobs)
}
这个函数将文件名一个接一个地以Job类型发送到jobs通道里。jobs通道有一个大小为4的缓冲区(和工作goroutine的数量一样),所以最开始那4个工作是立即就增加到通道里去的,然后该函数所在的goroutine 阻塞等待其他的工作 goroutine 从通道里接收工作,以腾出通道空间来发送其他的工作。一旦所有的工作发送完毕(这取决于有多少个文件名需要处理,和处理每一个文件名的时间多长),jobs通道会被关闭。
尽管实际上传入的两个通道是双向的,但是我们将它们都指定为单向只允许发送的通道,因为我们在函数里就是这样使用的,Job结构里Job.results通道也是这么定义的。
func doJobs(done chan<- struct{}, lineRx *regexp.Regexp, jobs <-chan Job) {
for job := range jobs {
job.Do(lineRx)
}
done <- struct{}{}
}
前面我们已经知道,分别有4个独立的goroutine在执行doJobs函数,它们都共享同一个jobs通道(只读),并且每个goroutine都会阻塞到直到有一个工作分配给它。拿到工作之后调用这个工作的Job.Do方法(很快我们就可以看到Do方法里做了什么事情),当一个调用遍历完jobs之后,往done通道里发送一个空的结构报告自己的完成状态。
顺便提一下,按照 Go语言的惯例,带有通道参数的函数,通常会将目标通道放在前面,接下来才是源通道。
func awaitCompletion(done <-chan struct{}, results chan Result) {
for i := 0; i < workers; i++ {
<-done
}
close(results)
}
这个函数(以及processResults函数)确保主goroutine在所有的处理都完成后才退出,这样可以避免我们在前一节里提到过的陷阱(7.1节)。这个函数在它自己的goroutine里运行,然后等待从done通道里接收所有工作goroutine的完成状态,等待过程中它是阻塞的。一旦退出循环后 results 通道也会被关闭,因为这个函数能知道什么时候接收最后一个结果。注意这里我们不能将results通道作为一个只允许接收的通道(<-chan Result)来传给函数,因为Go语言不允许关闭这样的通道。
func processResults(results <-chan Result) {
for result := range results {
fmt.Printf("%s:%d:%s\n", result.filename, result.lino, result.line)
}
}
这个函数是在主goroutine里执行的,遍历results通道或者阻塞在那里,一旦接收并处理完(例如打印)所有的完成状态后,循环结束,函数就会返回,然后整个程序将退出。
Go语言的并发支持是相当灵活的,这里我们使用的方法是,等待所有工作完成,关闭通道,并输出所有的结果,但我们还有其他的方法。例如,cgrep2(它的文件在cgrep2/cgrep.go文件里)这个程序就是我们这一节讨论的cgrep1的另一个变种,它并没有使用awaitCompletion或者precessResults函数,只用了一个waitAndProcessResults函数。
func waitAndProcessResults(done <-chan struct{}, results <-chan Result) {
for working := workers; working > 0; {
select { // 阻塞
case result := <-results:
fmt.Printf("%s:%d:%s\n", result.filename, result.lino, result.line)
case <-done:
working--
}
}
DONE:
for {
select { // 非阻塞
case result := <-results:
fmt.Printf("%s:%d:%s\n", result.filename, result.lino, result.line)
default:
break DONE
}
}
}
这个函数首先就是一个for循环,它会一直执行到所有的goroutine退出。每一次进入循环体里都会执行select语句,然后阻塞直到接收到一个结果值或者一个完成值。(如果我们使用了一个非阻塞的select,也就是有一个default分支,相当于创建了一个非常省CPU的spin-lock。)当所有的goroutine退出后for循环也会结束,也就是说,所有的工作goroutine都往done通道里发送了一个结果值。
所有的工作goroutine完成自己的任务后,我们启动了另一个for循环,在这个循环里我们使用了非阻塞的select。如果results通道里还有未处理的值,select就会匹配第一个分支,将这个值输出,然后再一次执行循环体,一直重复到 results 通道里所有的值都被处理完毕。但如果这时没有结果值需要接收(最明显的就是刚进入for循环的时候results通道里是空的),程序就会退出for循环然后跳转到DONE标签处(单纯使用一个break语句是不够的,它只会跳出select语句),这个for循环不是很耗CPU,因为每一次迭代要么接收了一个结果值要么我们就完成了,没有不必要的等待时间。
实际上 waitAndProcessResults函数要比原先的awaitCompletion和process Results函数更长和更复杂一点。但是,当有好几个不同的通道需要处理的时候,使用 select语句是非常有好处的。例如我们可以在一定时间之后停止处理,即使那时还有未完成的任务。
下面是这个程序的第三个版本,也是最后一个版本,cgrep3(在文件cgrep3/cgrep.go里)。
func waitAndProcessResults(timeout int64, done <-chan struct{}, results <-chan Result) {
finish := time.After(time.Duration(timeout))
for working := workers; working > 0; {
select { // 阻塞
case result := <-results:
fmt.Printf("%s:%d:%s\n", result.filename, result.lino, result.line)
case <-finish:
fmt.Println("timed out")
return // 超时,因此直接返回
case <-done:
working--
}
}
for {
select { // 非阻塞
case result := <-results:
fmt.Printf("%s:%d:%s\n", result.filename, result.lino, result.line)
case <-finish:
fmt.Println("timed out")
return // 超时,因此直接返回
default:
return
}
}
}
这是cgrep2的一个变种,不同的就是多了一个超时的参数,将一个time.Duration(其实就是一个纳秒值)值传入time.After函数,返回一个超时通道。这个超时通道的作用就是超过了time.Duration指定的时间后,通道会返回一个值,如果我们从这个通道里读到一个值,也就是说超时了。这里我们将返回的通道赋值给finish变量,并在两个for循环里为finish增加一个case分支。一旦超时(即finish通道发送了一个值),即使还有工作未完成,函数也会返回,然后程序结束。
如果在超时之前我们得到了所有的结果值,也就是所有的工作goroutine都完成自己的任务并向results通道发送了一个结果值,这时第一个for循环就会退出,程序接着执行第二个for循环,这过程和cgrep2是完全一样的,唯一不同的是这里并没有直接从for循环中跳出,而是简单地在默认分支里执行一个return语句,还增加了一个超时的case分支。
现在我们已经知道并发是怎么处理的了,下面的代码是关于每个工作是怎么被处理的,这个之后cgrep例子的所有的代码我们就已经讲解完了。
func (job Job) Do(lineRx *regexp.Regexp) {
file, err := os.Open(job.filename)
if err != nil {
log.Printf("error: %s\n", err)
return
}
defer file.Close
reader := bufio.NewReader(file)
for lino := 1; ; lino++ {
line, err := reader.ReadBytes('\n')
line = bytes.TrimRight(line, "\n\r")
if lineRx.Match(line) {
job.results <- Result{job.filename, lino, string(line)}
}
if err != nil {
if err != io.EOF {
log.Printf("error:%d: %s\n", lino, err)
}
break
}
}
}
这个方法是用来处理每一个文件的,它传入一个*regexp.Regexp值,这是一个线程安全的指针,所以它不必关心有多少个不同的goroutine同时在用它。整个函数的代码我们已经很熟悉了:打开一个文件,读取它的数据,对所有的出错进行处理,如果没有错误我们就用 defer 语句来关闭文件,然后创建了一个带缓冲区的reader来遍历文件内容里的所有行,一旦遇到了匹配的行,我们就将它作为一个Result值发送到results通道,当通道满时发送操作会被阻塞,最后所有被处理的文件都会产生N个结果值,如果文件里没有匹配的行,那N的值为0。
在Go语言里处理文本文件时,如果在读一行文本中出现错误,我们会在处理完当前行后处理这个错误。如果bufio.Reader.ReadBytes方法遇到了一个错误(包括文件结束),它会和错误一起返回出错前已经成功读取到的字节数。有时候文件最后一行不是以换行符结束的,所以为了确保我们处理最后一行(不管它是否是以换行符结束的),我们都会在处理完这一行后再处理相关错误。这样做有一点不好,就是正则表达式如果匹配了一个空的字符串,我们会得到既不是nil也不是io.EOF的错误,从而被当做一个假的匹配(当然,我们有办法绕过这个问题)。
bufio.Reader.ReadBytes方法会一直读到一个指定的字符后才返回。返回的字节流里包括那个指定的字符,如果整个文件都没出现这个字符的话,会将整个文件的数据都读取出来。我们这里不需要换行符,所以我们使用 bytes.TrimRight方法将它去掉。bytes.TrimRight方法的作用就是从行的右边向左去除指定的字符串或字符(类似于strings.TrimRight函数)。为了能让我们的程序跨平台,我们将换行和回车字符都除掉。
另一个需要注意的小细节就是,我们读出来的是字节切片,而 regexp.Regexp.Match和regexp.Regexp.MatchString方法只能处理字符串,所以我们将byte转换成string类型,当然转换的代价很小。还有我们统计行数从1开始而不是从0开始,这样会方便很多。
cgrep程序的设计中比较好的一点就是它的并发框架足够简单,并和实际的业务处理过程(也就是Job.Do方法)分离,只使用results通道来进行交互。这种框架与业务的分离在Go语言的并发编程里是很常见的,与那些使用底层同步数据结构(如同步锁)的方法相比有诸多好处,因为锁相关的代码会让程序的逻辑变得更加复杂和晦涩难懂。
7.2.3 线程安全的映射
Go语言标准库里的sync和sync/atomic包提供了创建并发的算法和数据结构所需要的基础功能。我们也可以将一些现有的数据结构变成线程安全,例如映射或者切片等(参见6.5.3节),这样可以确保在使用上层API时所有的访问操作都是串行的。
这一节我们会开发一个线程安全的映射,它的键是字符串,值是 interface{}类型,不需要使用锁就能够被任意多个goroutine共享(当然,如果我们存的值是一个指针或引用,我们还必须得保证所指向的值是只读的或对于它们的访问是串行的)。线程安全的映射的实现在safemap/safemap.go 文件里,包含了一个导出的SafeMap 接口,以及一个非导出的safeMap 类型,safeMap 实现了 SafeMap 接口定义的所有方法。下一节我们来看看这个safeMap是怎么使用的。
安全映射的实现其实就是在一个goroutine里执行一个内部的方法以操作一个普通的map数据结构。外界只能通过通道来操作这个内部映射,这样就能保证对这个映射的所有访问都是串行的。这种方法运行着一个无限循环,阻塞等待一个输入通道中的命令(即“增加这个”,“删除那个”等)。
我们先看看 SafeMap 接口的定义,再分析内部 safeMap 类型可导出的方法,然后就是safemap包的New函数,最后分析未导出的safeMap.run方法。
type SafeMap interface {
Insert(string, interface{})
Delete(string)
Find(string) (interface{}, bool)
Len int
Update(string, UpdateFunc)
Close map[string]interface{}
}
type UpdateFunc func(interface{}, bool) interface{}
这些都是SafeMap接口必须实现的方法。(我们在前一章讨论过可导出的接口和不能导出的具体类型是什么样的。)
UpdateFunc类型让自定义更新操作函数变得很方便,我们会在后面讨论Update方法时讲到它。
type safeMap chan commandData
type commandData struct {
action commandAction
key string
value interface{}
result chan<- interface{}
data chan<- map[string]interface{}
updater UpdateFunc
}
type commandAction int
const (
remove commandAction = iota
end
find
insert
length
update
)
safeMap的实现基于一个可发送和接收commandData类型的通道。每个commandData类型值指明了一个需要执行的操作(在 action 字段)及相应的数据,例如,大多数方法需要一个key来指定需要处理的项。我们会在分析safeMap的方法时看到所有的字段是如何被使用的。
注意,result和data通道都是被定义为只写的,也就是说,safeMap可以往里面发送数据,不能接收。但是下面我们会看到,这些通道在创建的时候都是可读写的,所以它们能够接收safeMap发给它们的任何值。
func (sm safeMap) Insert(key string, value interface{}) {
sm <- commandData{action: insert, key: key, value: value}
}
这种方法相当于一个线程安全版本的m[key] = value 操作,其中 m 是 map[string] interface{}类型。它创建了一个commandData值,指明是一个insert操作,并将传入的key和value保存到commandData结构中并发送到一个安全的映射里。我们刚刚介绍过,这个安全映射的类型是基于chan commandData实现的(我们在6.4节讲过,在Go语言里创建一个结构时所有未被显式初始化的字段都会被默认初始化成它们各自的零值)。
当我们查看 safemap 包里的New函数时我们会发现该函数返回的safeMap 关联了一个goroutine。safeMap.run方法在这个goroutine里执行,也是一个捕获了该safeMap通道的闭包。safeMap.run里有一个底层 map 结构,用来保存这个安全映射的所有项,还有一个 for循环遍历safeMap通道,并执行每一个从safeMap通道接收到的对底层map的操作。
func (sm safeMap) Delete(key string) {
sm <- commandData{action: remove, key: key}
}
这个方法告知该安全映射删除key所对应的项,如果给定key不存在则不做任何事。
type findResult struct {
value interface{}
found bool
}
func (sm safeMap) Find(key string) (value interface{}, found bool) {
reply := make(chan interface{})
sm <- commandData{action: find, key: key, result: reply}
result := (<-reply).(findResult)
return result.value, result.found
}
safeMap.Find方法创建了一个reply通道用来接收发送commandData后的响应,然后把这个 reply 通道和指定要查找的key 放到一个 commandData 值里,再往 safeMap发送一个 find 命令。因为所有的通道都没有带缓冲区,因此一条命令的发送操作会一直阻塞直到没有其他的goroutine往里面发送命令。一旦命令发送完毕我们立即接收reply通道的返回值(对应于find命令是一个findResult结构),然后我们将这个结果返回给调用者。顺便提一句,这里我们使用命名返回值是为了让它们的用途更加清晰。
func (sm safeMap) Len int {
reply := make(chan interface{})
sm <- commandData{action: length, result: reply}
return (<-reply).(int)
}
这个方法和Find方法在结构上大体是相似的,首先创建一个用来接收结果的reply通道,最后将结果分析出来返回给调用者。
func (sm safeMap) Update(key string, updater UpdateFunc) {
sm <- commandData{action: update, key: key, updater: updater}
}
这个方法貌似看起来有点不太常规,因为它的第二个参数是一个签名为func(interface{}, bool)的函数。Update方法往通道发送一条更新命令时会带上指定的key和一个updater函数,当这条命令被接收时,updater函数会被调用并带上两个调用参数,一个是指定的key对应的值(若key不存在,则传nil作为参数),还有一个bool变量表示这个键对应的项是否存在。指定的键对应的值会被设置为updater函数的返回值(如果key不存在则创建一个新项)。
需要特别注意的是, updater函数调用safeMap的方法会导致死锁。后面涉及safemap.safeMap.run方法时会进一步解释。
但我们为什么需要这么奇怪的方法呢,又怎么去用它?
当我们需要插入、删除或查找safeMap里的项时,Insert、Delete和Find方法都能工作得很好。但当我们想去更新一个已经存在的项时会发生什么呢?举个例子,我们在safeMap里保存了机器零件的价格,现在我们需要将某个零件的价格上调5%,会发生什么事情呢?我们知道Go语言会自动将一个未初始化的值初始化为0,如果我们指定的键已经存在的话,它对应的值会增加5%,如果不存在的话,就创建一个新的零值。下面我们实现了一个能保存float64类型的值的安全映射。
if price, found := priceMap.Find(part); found { // 错误!
priceMap.Insert(part, price.(float64)*1.05)
}
这段代码的问题是可能会有多个goroutine同时使用这个priceMap,也就有可能在Find和Insert之间修改数据,从而没法保证我们插入的价格值确实比原来的值高5%。
我们需要的是一个原子的更新操作,也就是说,读和更新这个值应该作为不可中断的一个操作。下面的Update方法就是这样做的。
priceMap.Update(part, func(price interface{}, found bool) interface{} {
if found {
return price.(float64) * 1.05
}
return 0.0
})
这段代码实现了一个原子更新操作,如果指定的键不存在,我们就创建一个新的项,它的值为0.0,否则我们就将这个键对应的值增加5%。因为这个更新是在safeMap的goroutine里执行的,这期间不会有其他的命令被执行(例如,从其他goroutine发送过来的命令)。
func (sm safeMap) Close map[string]interface{} {
reply := make(chan map[string]interface{})
sm <- commandData{action: end, data: reply}
return <-reply
}
Close方法的工作原理和Find以及 Len方法类似,不过它有两个不同的目标。首先,它需要关闭safeMap通道(在safeMap.run方法里),这样就不会再有其他的更新操作。关闭safeMap通道将导致safeMap.run方法里的for循环退出,进而释放相应用于自动垃圾收集的goroutine。第二个目标是将底层的map[string]interface{}返回给调用者(如果调用者不需要,可以忽略它)。每一个safeMap只允许执行一次Close方法,不管有多少个goroutine在访问,而且一旦Close被调用就不能再调用任何其他方法。我们可以保留Close方法返回的map并像使用一个普通map一样使用它,但只能在一个goroutine里使用。
到这里我们已经分析了safeMap所有导出的方法,最后一个我们要分析的是safemap包的New函数,New函数的作用就是创建一个safeMap并以SafeMap接口的方式返回,并执行safeMap.run方法使用通道,提供一个map[string]interface{}用来保存实际的数据,并且处理所有的通信。
func New SafeMap {
sm := make(safeMap) // safeMap类型chan commandData go sm.run
return sm
}
safeMap实际上是chan commandData类型,所以我们必须使用内置的make函数来创建一个通道并返回它的一个引用。有了safeMap之后我们调用它的run方法,在run里还会创建一个底层映射用来保存实际的数据,run在自己的goroutine里执行,执行go语句之后通常会立即返回。最后函数将这个safeMap返回。
func (sm safeMap) run {
store := make(map[string]interface{})
for command := range sm {
switch command.action {
case insert:
store[command.key] = command.value
case remove:
delete(store, command.key)
case find:
value, found := store[command.key]
command.result <- findResult{value, found}
case length:
command.result <- len(store)
case update:
value, found := store[command.key]
store[command.key] = command.updater(value, found)
case end:
close(sm)
command.data <- store
}
}
}
创建了一个用来存储的映射后,run方法启动了一个无限循环来读取 safeMap 通道的命令,如果通道是空的,就一直阻塞在那里。
因为store是一个再普通不过的映射,所以接收到每一个命令该怎么处理就怎么处理,非常容易理解。另一个稍微不同的是更新操作。某个键所对应项的值将被设置成command.updater函数的返回值。最后一个end分支对应Close调用,首先关闭通道以防止再接收其他的命令,然后将存储映射返回给调用者。
前面我们提过如果 command.updater函数要是调用了 safeMap的方法就会发生死锁,这是因为如果command.updater函数不返回,update这个分支就不能正常结束。如果updater函数调用了一个safeMap方法,它会一直阻塞到update分支完成,这样两个都完成不了。图7-2解释了这种死锁。
显然,使用一个线程安全的映射相比一个普通的map会有更大的内存开销,每一条命令我们都需要创建一个 commandData 结构,利用通道来达到多个 goroutine 串行化访问一个safeMap的目的。我们也可以使用一个普通的map配合sync.Mutex以及sync.RWMutex使用以达到线程安全的目的。另外还有一种方法就是如同相关理论所描述的那样创建一个线程安全的数据结构(例如,参见附录 C)。还有一种方法就是,每个 goroutine 都有自己的映射,这样就不需要同步了,然后在最后将所有goroutine的结果合并在一起即可。尽管方法很多,这里所实现的安全映射不但易用而且足以应对各种的场景。下一小节我们会看到如何应用这个safeMap,并顺带与一些其他方法进行了对比。
7.2.4 Apache报告
并发处理最常见的一个需求就是更新共享数据。一个常见的方案是使用互斥量来串行化所有的数据访问。在Go语言里,我们除互斥量外还可以使用通道来达到串行化的目的。这一节,我们将使用通道和一个安全的映射(上一节讲过的)来开发一个小程序,然后再分析如何使用以互斥量保护的共享map来达成同样的目标。最后,我们将讲解如何使用通道局部的map来避免访问串行化从而最大化吞吐量,并使用通道来对一个map进行更新。
这里所有的工作都由apachereport程序完成。它读取从命令行指定的Apache网页服务器的access.log文件数据,然后统计所有记录里每个HTML页面被访问的次数。这个日志文件很容易就增长到很大,所以我们用了一个 goroutine 来读取每一行日志(每行一条记录),以及另外3个goroutine一起处理这些行。每读到一个HTML页面被访问的记录,就将它更新到映射里去,如果这个HTML是第一次访问,则映射里对应的计数器为1,然后每再发现一条记录,计数器做加一处理。所以尽管有多个独立goroutine同时处理这些行记录,但是它们所有的更新都是在同一个映射里进行的。不同版本的程序采取不同的方法来更新映射。
7.2.4.1 用线程安全的共享映射同步
现在我们来回顾下apachereport1 程序(在文件apachereport1/apachereport.go里),使用前一节开发的safeMap,所用到的并发数据结构如图7-6所示。
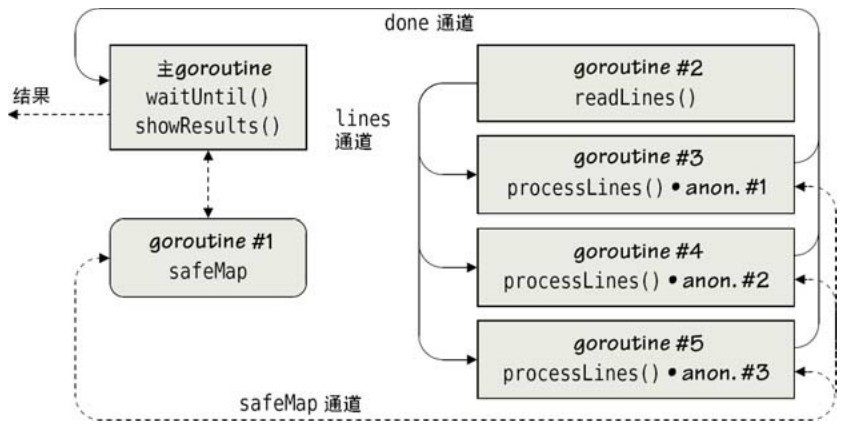
图7-6 带有同步结果的多个相互依赖的并发作业
在图7-6中,goroutine#2创建了一个通道,将从日志读到的每一行发送到工作通道里,然后goroutine#3到goroutine#5处理这个通道的每一行并更新到共享的safeMap数据结构。对safeMap的操作本身是在一个独立的goroutine里完成的,所以整个程序一共使用了6个goroutine。
var workers = runtime.NumCPU
func main {
runtime.GOMAXPROCS(runtime.NumCPU) // 使用所有的机器内核
if len(os.Args) != 2 || os.Args[1] == "-h" || os.Args[1] == "--help" {
fmt.Printf("usage: %s <file.log>\n", filepath.Base(os.Args[0]))
os.Exit(1)
}
lines := make(chan string, workers*4)
done := make(chan struct{}, workers)
pageMap := safemap.New
go readLines(os.Args[1], lines)
processLines(done, pageMap, lines)
waitUntil(done)
showResults(pageMap)
}
main函数首先确保Go运行时系统充分利用所有的处理器,然后创建两个通道来组织所有的工作。从日志文件里读取到的每一行将被发送到lines通道,然后工作goroutine再将每一行读取出来进行处理,我们为lines通道分配了一个小缓冲区以降低工作goroutine阻塞在lines 通道上的可能性。done 通道用来跟踪何时所有工作被完成。因为我们只关心发送和接收操作的发生而非实际传递的值,所以我们使用一个空结构。done 通道也是带有缓冲的,所以当一个goroutine报告工作完成时不会被阻塞在发送操作上。
接着我们使用safemap.New函数创建了一个pageMap,它是一个非导出的safeMap类型的值,实现了SafeMap接口所有定义的方法,可以随意传递。然后我们启动一个goroutine来从日志文件里读取行记录,并启动其他的goroutine 负责处理这些行。最后程序等待所有的goroutine工作完成,并将最终的结果输出。
func readLines(filename string, lines chan<- string) {
file, err := os.Open(filename)
if err != nil {
log.Fatal("failed to open the file:", err)
}
defer file.Close
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if line != "" {
lines <- line
}
if err != nil {
if err != io.EOF {
log.Println("failed to finish reading the file:", err)
}
break
}
}
close(lines)
}
这个函数看起来并不陌生,因为与之前我们见过的几个例子相当类似。首先最关键的第一个地方就是我们将每一个文本行发送到 lines 通道,lines 是只允许发送的,而且当通道缓冲区满了之后这个操作会一直阻塞在那里,直到有一个其他的goroutine从通道里接收一个文本行。不过就算有阻塞,也只会对这个 goroutine 有影响,其他的goroutine 还会继续工作而不受影响。第二个关键的地方就是当所有的文本行发送完毕之后我们关闭lines通道,这就告诉了其他的goroutine已经没有数据需要接收了。记住,尽管这个goroutine和其他的goroutine(也就是其他负责处理任务的工作 goroutine)是并发执行的,但是一般只有在大部分工作完成后close语句才会被执行到。
func processLines(done chan<- struct{}, pageMap safemap.SafeMap, lines <-chan string) {
getRx := regexp.MustCompile('GET[ \t]+([^ \t\n]+[.]html?)')
incrementer := func(value interface{}, found bool) interface{} {
if found {
return value.(int) + 1
}
return 1
}
for i := 0; i < workers; i++ {
go func {
for line := range lines {
if matches := getRx.FindStringSubmatch(line); matches != nil {
pageMap.Update(matches[1], incrementer)
}
}
done <- struct{}{}
}
}
}
这里函数参数的顺序遵循Go语言的约定,先是目标通道(也就是done通道),然后是源通道(lines通道)。
该函数创建了一些goroutine(实际上是3个)来处理实际的工作。每个goroutine都共享同一个*regexp.Regexp数据(和普通的指针不同,这个是线程安全的)和一个incrementer函数(这个函数不会有任何副作用,因为它不访问任何共享的数据),还共享了同一个pageMap (是一个SafeMap接口类型的值)。前面我们已经知道,safeMap的修改都是线程安全的。
如果没有匹配任何数据,那么 regexp.Regexp.FindStringSubmatch函数返回nil,否则就返回一个string 类型的字符串切片,其中第一个字符串是整个正则表达式的匹配,随后其他的字符串对应表达式里的每一个小括号括起来的子表达式。这里我们只有一个子表达式,所以如果我们得到一个匹配的结构,那这个结果里有两个字符串,一个是完整的匹配,另一个是括号里子表达式的匹配,在这里是HTML页面的文件名。
每一个工作 goroutine 从只允许接收的lines 通道里读取文本行,通道中的数据由readLines函数里的goroutine 从日志文件里读取并发送。对于某一行的匹配说明对于HTML文件发生了一个GET请求,在这种情况下safeMap.Update方法将被调用并传入页面的文件名(也就是 matches[1])和incrementer函数。incrementer函数是safeMap的内部 goroutine 调用的,对于之前被访问过的页面,那就返回一个增量值,对于未被访问过的页面则返回1(回忆起前一小节我们说过的,如果被传给safeMap.Update的函数自身又调用了 safeMap的其他方法的话会出现死锁)。当所有页面被处理后,每一个工作goroutine会发送一个空结构体到done通道以说明工作已经完成。
func waitUntil(done <-chan struct{}) {
for i := 0; i < workers; i++ {
<-done
}
}
这个函数在主 goroutine 里执行,阻塞在 done 通道上,当所有的工作 goroutine 往 done里发送了一个空结构体后,for循环将结束。和平时一样,我们不需要关闭done通道,因为没有在别的需要检查这个通道是否被关闭的地方使用这个通道。通过阻塞,这个函数可以确保所有的处理工作在主goroutine退出之前完成。
func showResults(pageMap safemap.SafeMap) {
pages := pageMap.Close
for page, count := range pages {
fmt.Printf("%8d %s\n", count, page)
}
}
当所有的文本行都被读取并且所有的匹配项都增加到 safeMap 之后,该函数将被调用以输出结果。它首先调用 safemap.safeMap.Close方法关闭 safeMap的通道,退出在goroutine里运行的safeMap.run方法,然后返回一个底层的map[string]interface{}给调用者。这个返回的映射将无法再被其他的goroutine通过安全映射的通道访问,所以可以在一个单独的goroutine中安全地使用它(或者使用互斥量来让多个goroutine串行访问)。由于从该处之后我们只在主goroutine里访问这个映射,所以串行化访问并没必要。我们简单地遍历映射里所有的“键/值”对,然后将它们输出到控制台。
使用一个 SafeMap 接口类型的值同时提供了线程安全性和简单的语法,不需要担心锁的问题。这种方法不好的一点就是安全映射的值是 interface{}类型而不是一个特定的类型,这样我们就得在incrementer函数里使用类型断言(我们将在7.2.4.3节讨论另一个缺陷)。
7.2.4.2 用带互斥量保护的映射同步
现在我们将对简单干净的基于通道的做法和传统的基于互斥量的做法做一个对比。为此我们首先简要地讨论一下apachereport2程序(在文件apachereport2/apachereport.go里)。这个程序是 apachereport1的变种,使用了一个封装了映射的自定义数据类型和互斥量来取代线程安全的映射。这两个程序所做的工作是完全一样的,唯一不同的是映射的值是一个int型值而不是SafeMap里的interface{}类型,并且相比安全映射中的完全方法列表,这里只提供了这个工作相关的最小功能集合—— 一个Increment方法。
type pageMap struct {
countForPage map[string]int
mutex *sync.RWMutex
}
使用自定义类型的好处就是我们可以用所需要的特定数据类型而不是通用的interface{}类型。
func NewPageMap *pageMap {
return &pageMap{make(map[string]int), new(sync.RWMutex)}
}
这个函数返回一个可立即使用的*pageMap值。(顺便提一句,可以使用&sync.RWMutex{}来创建一个读写锁,而不用new(sync.RWMutex)。4.1节中我们讨论过这两者的一致性。)
func (pm *pageMap) Increment(page string) {
pm.mutex.Lock
defer pm.mutex.Unlock
pm.countForPage[page]++
}
每个修改 countForPage的方法都需要使用互斥量来串行化访问。我们这里用的方法很传统:首先锁定互斥量,然后使用defer关键字来调用解锁互斥量的语句,这样无论什么时候返回都能保证可以解锁互斥量(即使发生了异常),然后再访问映射里的数据(每次锁定的时间越少越好)。
基于Go语言的自动初始化机制,当页面在countForPage中第一次被访问时(即该页面还不在countForPage里),我们就将它增加到这个映射里面并将值设置为0,然后马上递增该值。相对的,之后对已经存在于映射中的页面的访问都会导致对应值的递增。
我们使用互斥量来串行化所有方法对countForPage的访问,所以如果要更新映射的值,就必须使用sync.RWMutex.Lock和sync.RWMutex.Unlock,但对于只读的访问,我们可以用另一种只读的方法。
func (pm *pageMap) Len int {
pm.mutex.RLock
defer pm.mutex.RUnlock
return len(pm.countForPage)
}
我们将这个放进来纯粹是为了展示一下如何使用一个读锁。这个用法和普通的锁是一样的,但读锁可能更加高效一点(因为我们承诺只是读取但不修改受保护的资源)。例如,如果我们有多个goroutine都同时读同一个的countForPage,利用读锁,它们可以安全地并发执行。但如果它们其中一个得到了一个读写锁,它将可以修改映射的数据,但其余的goroutine就无法再获取任何锁。
pageMap.Increment(matches[1])
在有了pageMap类型后,工作goroutine就可以用这个语句来更新共享映射。
7.2.4.3 同步:使用通道来合并局部映射
不管我们用的是安全的映射还是用互斥量保护的映射,通过增加工作goroutine的数量可能能够提升应用程序的运行速度。但是由于访问安全映射或者用互斥量保护的映射时必须是串行化的,增加goroutine的数量会直接导致竞争的增加。
对于这种情况,通常我们可以通过牺牲一些内存来提升速度。例如,我们可以让每个工作goroutine都拥有自己的映射,这样可以极大地提高应用程序的吞吐量,因为处理过程中不会发生任何竞争,代价就是使用了更多的内存(因为很可能每个映射都有部分甚至所有相同的页面)。最后我们当然还必须将这些映射合并起来,这会是一个性能瓶颈,因为一个映射在合并时所有其他准备好合并的映射只能等着。
程序apachereport3(在文件apache3/apachereport.go里)使用每个goroutine特定的本地映射结构,并最后将它们全部合并到同一个映射里去。该程序的代码和apachereport1以及 apachereport2 几乎是一样的,这样我们就只重点介绍这个方法不一样的地方。这个程序的并发结构如图7-7所示。
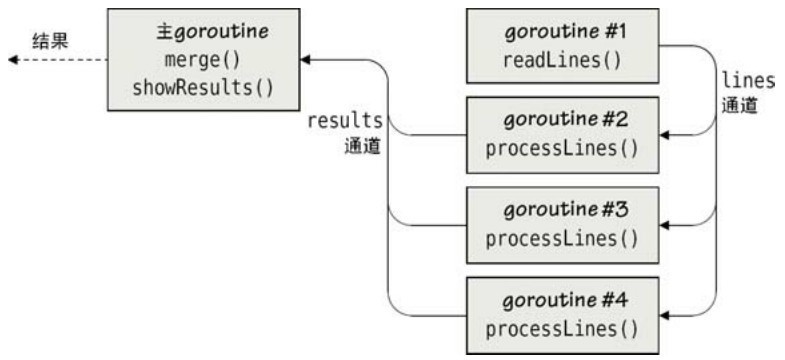
图7-7 带有同步结果的多个相互依赖的并发作业
//...
lines := make(chan string, workers*4)
results := make(chan map[string]int, workers)
go readLines(os.Args[1], lines)
getRx := regexp.MustCompile('GET[ \t]+([^ \t\n]+[.]html?)')
for i := 0; i < workers; i++ {
go processLines(results, getRx, lines)
}
totalForPage := make(map[string]int)
merge(results, totalForPage)
showResults(totalForPage)
//...
这是apachereport3程序main函数的一部分。这里我们没有使用done通道而是使用了一个results通道,当每个goroutine处理完成之后,将本地生成的映射发送到results这个通道里。另外,我们还创建一个保存所有结果的映射(叫totalForPage)以保存所有合并所有的结果。
func processLines(results chan<- map[string]int, getRx *regexp.Regexp,
lines <-chan string) {
countForPage := make(map[string]int)
for line := range lines {
if matches := getRx.FindStringSubmatch(line); matches != nil {
countForPage[matches[1]]++
}
}
results <- countForPage
}
这个函数和前一个版本几乎是一样的,关键的区别有两个,第一个就是我们创建了一个本地映射来保存页面的数量,第二个就是在函数处理完所有的文本行之后(也就是lines通道被关闭了),我们将本地的映射结果发送到results通道(而不是发送一个struct{}{}到done通道)。
func merge(results <-chan map[string]int, totalForPage map[string]int) {
for i := 0; i < workers; i++ {
countForPage := <-results
for page, count := range countForPage {
totalForPage[page] += count
}
}
}
merge函数的结构和之前我们看过的waitUntil是一样的,只是这一次我们需要使用接收到的值,用以更新 totalForPage 映射。需要注意的是,这里接收的映射不会再被发送的goroutine访问,所以无需使用锁。
showResults函数也基本上和之前的是一样的(所以这里就不贴代码了),我们将totalForPage作为它的参数,然后在函数里遍历这个映射,将每个页面的统计结果打印出来。
apachereport3程序的代码相对apachereport1和apachereport2来说非常的简洁,而且它所用的并发模型在很多场合是非常有用的,也就是每个goroutine都有局部的数据结构来保存计算结果,并将最后所有goroutine运行的结果合并在一块。
当然,对于那些习惯使用锁的程序员来说,大多还是倾向于使用互斥量来串行化共享数据的访问。但是,Go语言文档强烈推荐使用goroutine和通道,它提倡“不要使用共享内存来通信,相反,应使用通信来共享内存”,而且Go编译器对于上面提到的并发模型进行了相应的优化。
7.2.5 查找副本
这是这章最后一个关于并发的例子,使用SHA-1值而不是根据文件名来查找重复的文件[2]。
我们即将分析的程序名字是 findduplicates(在文件 fundduplicates/finddup licates.go里)。程序使用了标准库里的filepath.Walk函数,遍历一个给定路径的所有文件和目录,包括子目录、子目录的子目录等。程序根据工作量的多少而决定使用多少个goroutine。对于每一个大文件会有一个goroutine被单独创建以用于计算文件的SHA-1值,而小文件则是直接在当前的goroutine 里计算。这意味着我们不知道实际会有多少个 goroutine 在运行,不过我们也可以设置一个上限。
怎么处理若干个不固定数量的goroutine呢,一种办法就是和之前的例子一样使用done通道,只不过这一次是用来监控所有goroutine的状态。使用sync.WaitGroup虽然容易,但是我们需要将goroutine的数量传给它,而goroutine的数量我们是不知道的。
const maxGoroutines = 100
func main {
runtime.GOMAXPROCS(runtime.NumCPU) // 使用所有的机器核心
if len(os.Args) == 1 || os.Args[1] == "-h" || os.Args[1] == "--help" {
fmt.Printf("usage: %s <path>\n", filepath.Base(os.Args[0]))
os.Exit(1)
}
infoChan := make(chan fileInfo, maxGoroutines*2)
go findDuplicates(infoChan, os.Args[1])
pathData := mergeResults(infoChan)
outputResults(pathData)
}
main函数从命令行读取一个路径作为处理起始点并安排所有之后的工作。它首先创建一个通道用来传送 fileInfo 值(我们很快就会看到)。我们为这个通道设置了缓冲,因为实验表明这将能稳定的提升性能。
接下来函数在一个goroutine里执行findDuplicates函数,并调用mergeResults函数以读取infoChan通道里的数据直到它关闭。当合并结果返回后,我们将结果打印出来。
程序所有的goroutine和通信流程图如图 7-8 所示。图中的结果通道中的值是 fileInfo类型的,这些值会被一个叫“walker”的函数(filepath.WalkFunc类型)发送到infoChan通道,walker函数是我们调用filepath.Walk时传入的参数。filepath.Walk函数也是在fileDuplicates里被调用的。mergeResults函数负责接收最后的结果。图中所示的goroutine 是在 findDuplicates函数和walker 函数里创建的。另外,标准库里的filepath.Walk函数也会创建goroutine(例如,每一个goroutine处理一个目录),至于它是怎么工作的则属于实现细节。
type fileInfo struct {
sha1 byte
size int64
path string
}
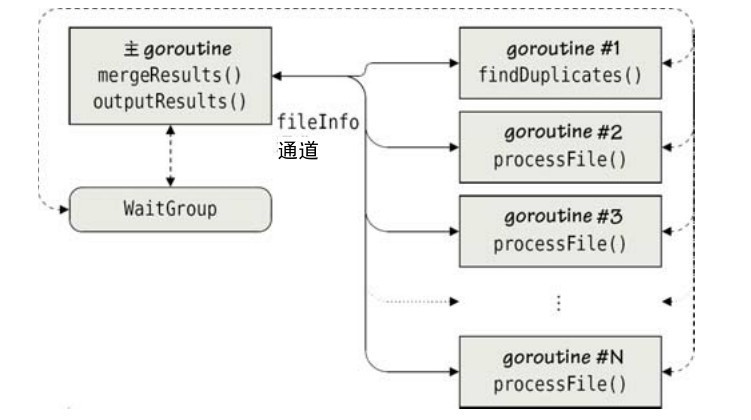
图7-8 带有同步结果的多个独立的并发作业
我们用这个结构体来保存文件的一些信息,如果两个文件的SHA-1值和文件尺寸都是一样的,不管它们的路径或者文件名是什么,我们都会把它们认为是重复的。
func findDuplicates(infoChan chan fileInfo, dirname string) {
waiter := &sync.WaitGroup{}
filepath.Walk(dirname, makeWalkFunc(infoChan, waiter))
waiter.Wait // 一直阻塞到工作完成
close(infoChan)
}
这个函数调用filepath.Walk来遍历一个目录树,并对于每一个文件或者目录调用作为该函数第二个参数传入的filepath.Walk函数来处理。
walker函数会创建任意个goroutine,我们必须等所有的goroutine完成任务之后才可以返回findDuplicates函数。为此,我们创建了一个 sync.WaitGroup,每次我们创建一个goroutine 时,就调用一次 sync.WaitGroup.Add函数,而当 goroutine 完成任务之后,再调用 sync.WaitGroup.Done。所有的goroutine 都设置为正在运行后,我们调用sync.WaitGroup.Wait函数来等待所有工作goroutine完成。sync.WaitGroup.Wait将阻塞到宣布完成的done数量和添加的数量相等为止。
所有的工作goroutine都退出后将不会再有其他的fileInfo值发送到infoChan里,因此我们可以关闭infoChan通道。当然mergeResults仍然可以读这个通道,直到将所有的数据都被读取出来。
const maxSizeOfSmallFile = 1024 * 32
func makeWalkFunc(infoChan chan fileInfo, waiter *sync.WaitGroup)
func(string, os.FileInfo, error) error {
return func(path string, info os.FileInfo, err error) error {
if err == nil && info.Size > 0 && (info.Mode&os.ModeType == 0) {
if info.Size < maxSizeOfSmallFile || runtime.NumGoroutine > maxGoroutines {
processFile(path, info, infoChan, nil)
} else {
waiter.Add(1)
go processFile(path, info, infoChan, func { waiter.Done })
}
return nil // 忽略所有错误
}
}
}
makeWalkFunc创建了一个类型为 filepath.WalkFunc的匿名函数,原型为func(string, os.FileInfo, error) error。每当filepath.Walk得到一个文件或者目录之后就会相应地调用这个匿名函数。函数中的path是指目录或者文件的名字,info保存了部分stat调用的结果,err要么为nil要么包含了详细的关于路径的错误信息。如果我们需要忽略目录,可以使用 filepath.SkipDir 作为 error的返回值,还可以返回其他non-nil的错误,这样filepath.Walk函数就会终止返回。
这里我们只处理那些非零大小的正常文件(当然,所有文件大小为0都是一样的,不过我们忽略掉这些)。os.ModeType是一个位集合,包含了目录、符号连接、命名管道、套接字和设备,所以如果这些对应的位没有设置,那它就是一个普通的文件。
如果文件很小,如不到32 KB,我们使用自定义函数processFile来计算它的SHA-1值,其他文件则创建一个新的goroutine来异步调用processFile函数,这就意味着小的文件会被阻塞(直到我们计算出它们的SHA-1值),但大文件就不会,因为它们的计算是在一个独立的goroutine里完成的。总之,当所有的计算都完成了,作为结果的fileInfo值就会被发送到infoChan通道。
当我们创建一个新的goroutine 之后,我们只需要调用 sync.WaitGroup.Add方法,但这么做的话,当goroutine完成自己的工作后还必须调用对应的sync.WaitGroup.Done方法。我们利用 Go语言的闭包来实现这个功能。如果我们在一个新的goroutine 里调用processFile函数,我们将一个匿名函数作为最后一个参数传入,当匿名函数被调用时会调用 sync.WaitGroup.Done方法,processFile函数应以延迟方式调用这个匿名函数,以保证当 goroutine 完成时 Done方法会被调用。如果我们在当前的goroutine 里调用processFile函数,我们传一个nil参数来代替匿名函数。
为什么我们不简单地为每一个文件都创建一个新的goroutine呢?在Go语言里完全可以这么做,就算我们创建了成百上千个goroutine也不会遇到任何问题。不幸的是,大部分的操作系统都限制同时打开的文件数。在Windows系统上默认只有512,尽管能提升到2048。Mac OS X系统更低,只能同时打开256个文件,Linux系统默认限制在1024,但是这些类Unix操作系统通常可以将这个值设置成一万、十万或者更高。很明显,如果我们将每一个文件都放到单独的goroutine里去处理,就很容易会超出这个限制。
为了避免打开过多的文件,我们配合使用两个策略。首先,我们将所有的小文件都放在同一个goroutine里处理(或者几个goroutine,如果碰巧filepath.Walk将它的工作分散到几个goroutine里去处理然后并发地调用walker函数的话),这样就可以确保如果我们遇到了一个包含上千个小文件的目录,不需要一次打开太多的文件,因为一个goroutine或者几个就能很快地把它处理完。
我们还应该让大文件在单独一个goroutine里处理,因为大文件通常处理起来很慢,我们也就没有办法同时打开太多的大文件。所以我们的第二个策略就是,当有足够多的goroutine在运行后,我们就不再为处理大的文件创建新的goroutine了(runtime.NumGoroutine函数能告诉我们在该函数调用的瞬间有多少goroutine在运行),而是强制让当前的goroutine直接处理后续的每一个文件,不管它的大小是多少,并同时监控当前正在运行的goroutine的总数,这也就相当于限制了我们同时打开的文件数。一个goroutine处理完大文件并被Go运行时系统移除后,goroutine的总数就会减少。这会导致有时goroutine总数低于我们限制的最大数量,这时我们可以再创建新的goroutine去处理大文件。