第2章 布尔与数值类型
04-13Ctrl+D 收藏本站
这是关于过程式编程的四章内容中的第一章,它构成了 Go语言编程的基础——无论是过程式编程、面向对象编程、并发编程,还是这些编程方式的任何组合。
本章涵盖了Go语言内置的布尔类型和数值类型,同时简要介绍了一下Go标准库中的数值类型。本章将介绍,除了各种数值类型之间需要进行显式类型转换以及内置了复数类型外,从C、C++以及Java等语言转过来的程序员还会有更多惊喜。
本章第一小节讲解了Go语言的基础,比如如何写注释,Go语言的关键字和操作符,一个合法标识符的构成,等等。一旦这些基础性的东西讲解完后,接下来的小节将讲解布尔类型、整型以及浮点型,之后也对复数进行了介绍。
2.1 基础
Go语言支持两种类型的注释,都是从 C++借鉴而来的。行注释以//开始,直到出现换行符时结束。行注释被编译器简单当做一个换行符。块注释以/*开头,以*/结尾,可能包含多个行。如果块注释只占用了一行(即/* inline comment*/),编译器把它当做一个空格,但是如果该块注释占用了多行,编译器就把它当做一个换行符。(我们将在第5章看到,换行符在Go语言中非常重要。)
Go标识符是一个非空的字母或数字串,其中第一个字符必须是字母,该标识符也不能是关键字的名字。字母可以是一个下划线_,或者 Unicode 编码分类中的任何字符,如大写字母“Lu”(letter,uppercase)、小写字母“Ll”(letter,lowercase)、首字母大写“Lt”(letter,titlecase)、修饰符字母“Lm”(letter, modifier)或者其他字母,“Lo”(letter,other)。这些字符包含所有的英文字母(A~Z以及a~z)。数字则是Unicode编码"Nd"分类(number, decimal digit)中的任何字符,这些字符包括阿拉伯数字 0~9。编译器不允许使用与某个关键字(见表 2-1)一样的
名字作为标识符。
表2-1 Go语言的关键字

Go语言预先定义了许多标识符(见表 2-2),虽然可以定义与这些预定义的标识符名字一样的标识符,但是这样做通常很不明智。
表2-2 Go语言预定义的标识符

标识符都是区分大小写的,因此 LINECOUNT、Linecount、LineCount、lineCount和linecount是5个不一样的标识符。以大写字母开头的标识符,即Unicode分类中属于“Lu”的字母(包含A~Z),是公开的——以Go语言的术语来说就是导出的,而任何其他的标识符都是私有的——用Go语言的术语来说就是未导出的。(这项规则不适用于包的名字,包名约定为全小写。)第6章讨论面向对象编程以及第9章讨论包时,我们会在实际的代码中看到这两者的区别。
空标识符“_”是一个占位符,它用于在赋值操作的时候将某个值赋值给空标识符,从而达到丢弃该值的目的。空标识符不是一个新的变量,因此将它用于:=操作符的时候,必须同时为至少另一个值赋值。通过将函数的某个甚至是所有返回值赋值给空标识符的形式将其丢弃是合法的。然而,如果不需要得到函数的任何返回值,更为方便的做法是简单地忽略它。这里有些例子:
count, err = fmt.Println(x) // 获取打印的字节数以及相应的error值
count, _ = fmt.Println(x) // 获取打印的字节数,丢弃error值
_, err = fmt.Println(x) // 丢弃所打印的字节数,并返回error值
fmt.Println(x) // 忽略所有返回值
打印到终端的时候忽略返回值很常见,但是使用fmt.Fprint以及类似函数打印到文件和网络连接等情况时,则应该检查返回的错误值。(Go语言的打印函数将在3.5节详细介绍。)
常量和变量
常量使用关键字const声明;变量可以使用关键字var声明,也可以使用快捷变量声明语法。Go语言可以自动推断出所声明变量的类型,但是如果需要,显式指定其类型也是合法的,比如声明一种与Go语言的常规推断不同的类型。下面是一些声明的例子:
const limit = 512 // 常量,其类型兼容任何数字
const top uint16 = 1421 // 常量,类型:uint16
start := -19 // 变量,推断类型:int
end := int64(9876543210) // 变量,类型:int64
var i int // 变量,值为0,类型:int
var debug = false // 变量,推断类型:bool
checkResults := true // 变量,推断类型:bool
stepSize := 1.5 // 变量,推断类型:float64
acronym := "FOSS" // 变量,推断类型:string
对于整型字面量 Go语言推断其类型为 int,对于浮点型字面量 Go语言推断其类型为float64,对于复数字面量Go语言推断其类型为complex128(名字上的数字代表它们所占的位数)。通常的做法是不去显式地声明其类型,除非我们需要使用一个Go语言无法推断的特殊类型。这点我们会在 2.3 节中讨论。指定类型的数值常量(即这里的top)只可用于别的数值类型相同的表达式中(除非经过转换)。未指定类型的数值常量可用于别的数值类型为任何内置类型的表达式中(例如,常量limit可以用于包含整型或者浮点型数值的表达式中)。
变量i并没有显式的初始化。这在Go语言中非常安全,因为如果没有显式初始化,Go语言总是会将零值赋值给该变量。这意味着每一个数值变量的默认值都保证为 0,而每个字符串都默认为空。这可以保证Go程序避免遭受其他语言中的未初始化的垃圾值之灾。
枚举
需要设置多个常量的时候,我们不必重复使用const关键字,只需使用const关键字一次就可以将所有常量声明组合在一起。(第1章中我们导入包的时候使用了相同的语法。该语法也可以用于使用 var 关键字来声明一组变量。)如果我们只希望所声明的常量值不同,并不关心其值是多少,那么可以使用Go语言中相对比较简陋的枚举语法。

这3个代码片段的作用完全一样。声明一组常量的方式是,如果第一个常量的值没有被显式设置(设为一个值或者是iota),则它的值为零值,第二个以及随后的常量值则设为前面一个常量的值,或者如果前面常量的值为iota,则将其后续值也设为iota。后续的每一个iota值都比前面的iota值大1。
更正式的,使用iota预定义的标识符表示连续的无类型整数常量。每次关键字const出现时,它的值重设为零值(因此,每次都会定义一组新的常量),而每个常量的声明的增量为1。因此在最右边的代码片段中,所有常量(指Magenta和Yellow)都被设为iota值。由于Cyan紧跟着一个const关键字,其iota值重设为0,即Cyan的值。Magenta的值也设为iota,但是这里iota的值为1。类似地,Yellow的值也是iota,它的值为2。而且,如果我们在其末尾再添加一个Black(在const组内部),它的值就被隐式地设为iota,这时它的值就是3。
另一方面,如果最右边的代码片段中没有iota标识符,Cyan就会被设为0,而Magenta的值则会设为Cyan的值,Yellow的值则被设为Magenta的值,因此最后它们都被设为零值。类似的,如果Cyan被设为9,那么随后的值也会被设为9。或者,如果Magenta的值设为5, Cyan的值就被设为 0(因为是组中的第一个值,并且没有被设为一个显式的值或者 iota), Magenta的值就是5(显式地设置),而Yellow的值也是5(前一个常量的值)。
也可以将iota与浮点数、表达式以及自定义类型一起使用。
type BitFlag int
const (
Active BitFlag = 1 << iota // 1 << 0 == 1
Send // 隐式地设置成BitFlag = 1 << iota // 1 << 1 == 2
Receive //隐式地设置成BitFlag = 1 << iota // 1 << 2 == 4
)
flag := Active | Send
在这个代码片段中,我们创建了3个自定义类型BitFlag的位标识,并将变量flag(其类型为BitFlag)的值设为其中两个值的按位或(因此flag的值为3,Go语言的按位操作符已在表2-6中给出)。我们可以略去自定义类型,这样Go语言就会认为定义的常量是无类型整数,并将 flag的类型推断成整型。BitFlag 类型的变量可以保存任何整型值,然而由于BitFlag是一个不同的类型,因此只有将其转换成int型后才能将其与int型数据一起操作(或者将int型数据转换成BitFlag类型数据)。
正如这里所表示的,BitFlag 类型非常有用,但是用来调试不太方便。如果我们打印 flag的值,那么得到的只是一个3,没有任何标记表示这是什么意思。Go语言很容易控制自定义类型的值如何打印,因为如果某个类型定义了String方法,那么fmt包中的打印函数就会使用它来进行打印。因此,为了让 BitFlag 类型可以打印出更多的信息,我们可以给该类型添加一个简单的String方法。(自定义类型和方法的内容将在第6章详细阐述。)
func (flag BitFlag) String string {
var flags string
if flag & Active == Active {
flags = append(flags, "Active")
}
if flag & Send == Send {
flags = append(flags, "Send")
}
if flag & Receive == Receive {
flags = append(flags, "Receive")
}
if len(flags) > 0 { // 在这里,int(flag)用于防止无限循环,至关重要!
return fmt.Sprintf("%d(%s)", int(flag), strings.Join(flags, "|"))
}
return "0"
}
对于已设置好值的位域,该方法构建了一个(可能为空的)字符串切片,并将其以十进制整型表示的位域的值以及表示该值的字符串打印出来。(通过将%d标识符设为%b,我们可以轻易地将该值以二进制整数打印出来。)正如其中的注释所说,当将flag传递给fmt.Sprintf函数的时候,将其类型转换成底层的int 类型至关重要,否则 BitFlag.String方法会在flag上递归地调用,这样就会导致无限的递归调用。(内置的append函数将在4.2.3节中讲解。fmt.Sprintf和strings.Join函数将在第3章讲解。)
Println(BitFlag(0), Active, Send, flag, Receive, flag|Receive)
0 1(Active) 2(Send) 3(Active|Send) 4(Receive) 7(Active|Send|Receive)
上面的代码片段给出了带String方法的BitFlag类型的打印结果。很明显,与打印纯整数相比,这样的打印结果对于调试代码更有用。
当然,也可以创建表示某个特定范围内的整数的自定义类型,以便创建一个更加精细的自定义枚举类型,我们会在第6章详细阐述自定义类型的内容。Go语言中关于枚举的极简方式是Go哲学的典型:Go语言的目标是为程序员提供他们所需要的一切,包括许多强大而方便的特性,同时又让该语言尽可能地保持简小、连贯而且快速编译和运行。
2.2 布尔值和布尔表达式
Go语言提供了内置的布尔值true和false。Go语言支持标准的逻辑和比较操作,这些操作的结果都是布尔值,如表2-3所示。
表2-3 布尔值和比较操作符

续表

布尔值和表达式可以用于if语句中,也可以用于for语句的条件中,以及switch语句的case子句的条件判断中,这些都将在第5章讲述。
二元逻辑操作符(||和&&)使用短路逻辑。这意味着如果我们的表达式是b1||b2,并且表达式b1的值为true,那么无论b2的值为什么,表达式的结果都为true,因此b2的值不会再计算而直接返回true。类似地,如果我们的表达式为b1&&b2,而表达式b1的计算结果为false,那么无论表达式b2的值是什么,都不会再计算它的值,而直接返回false。
Go语言会严格筛选用于使用比较操作符(<、<=、==、!=、>=、>)进行比较的值。这两个值必须是相同类型的,或者如果它们是接口,就必须实现了相同的接口类型。如果有一个值是常量,那么它的类型必须与另一个类型相兼容。这意味着一个无类型的数值常量可以跟另一个任意数值类型的值进行比较,但是不同类型且非常量的数值不能直接比较,除非其中一个被显式的转换成与另一个相同类型的值。(数字之间转换的内容已在2.3节讨论过。)
==和!=操作符可以用于任何可比较的类型,包括数组和结构体,只要它们的元素和成员变量与==和!=操作符相兼容。这些操作符不能用于比较切片,尽管这种比较可以通过 Go 标准库中的reflect.DeepEqual函数来完成。==和!=操作符可以用于比较两个指针和接口,或者将指针、接口或者引用(比如指向通道、映射或切片)与nil比较。别的比较操作符(<、<=、>=和>)只适用于数字和字符串。(由于Go也跟C和Java一样,不支持操作符重载,对于我们自定义的类型,如果需要,可以实现自己的比较方法或者函数,如Less或者Equal,详见第6章。)
2.3 数值类型
Go语言提供了大量内置的数值类型,标准库也提供了big.Int类型的整数和big.Rat类型的有理数,这些都是大小不限的(只限于机器的内存)。每一个数值类型都不同,这意味着我们不能在不同的类型(例如,类型int32和类型int)之间进行二进制数值运算或者比较操作(如+或者<)。无类型的数值常量可以兼容表达式中任何(内置的)类型的数值,因此我们可以直接将一个无类型的数值常量与另一个数值做加法,或者将一个无类型的常量与另一个数值进行比较,无论另一个数值是什么类型(但必须为内置类型)。
如果我们需要在不同的数值类型之间进行数值运算或者比较操作,就必须进行类型转换,通常是将类型转换成最大的类型以防止精度丢失。类型转换采用 type(value)的形式,只要合法,就总能转换成功——即使会导致数据丢失。请看下面的例子。
const factor = 3 // factor与任何数值类型兼容
i := 20000 // 通过推断得出i的类型为int
i *= factor
j := int16(20) // j的类型为int16,与这样定义效果一样:var j int16 = 20
i += int(j) // 类型必须匹配,因此需要转换
k := uint8(0) // 效果与这样定义一样:var k uint8
k = uint8(i) // 转换成功,但是k的值被截为8位
fmt.Println(i, j, k) // 打印:60020 20 16
为了执行缩小尺寸的类型转换,我们可以创建合适的函数。例如:
func Uint8FromInt(x int) (uint8, error) {
if 0 <= x && x <= math.MaxUint8 {
return uint8(x), nil
}
return 0, fmt.Errorf("%d is out of the uint8 range", x)
}
该函数接受一个int型参数,如果给定的int值在给定的范围内,则返回一个uint8和nil,否则返回0和相应的错误值。math.MaxUint8常量来自于math包,该包中也有一些类似的Go语言中其他内置类型的常量。(当然,无符号的类型没有最小值常量,因为它们的最小值都为 0。)fmt.Errorf函数返回一个基于给定的格式化字符串和值创建的错误值。(字符串格式化的内容将在3.5节讨论。)
相同类型的数值可以使用比较操作符进行比较(参见表 2-3)。类似地,Go语言的算术操作符可以用于数值。表 2-4 给出的算术运算操作符可用于任何内置的数值,而表 2-6 给出的算术运算操作符适用于任何整型值。
表2-4 可用于任何内置的数值的算术运算操作符

① 异常,即panic,见1.6节和5.5节。
常量表达式的值在编译时计算,它们可能使用任何算术、布尔以及比较操作符。例如:
const (
efri int64 = 10000000000 // 类型:int64
hlutföllum = 16.0 / 9.0 // 类型:float64
mælikvarða = complex(-2, 3.5) * hlutfö llum // 类型:complex128
erGjaldgengur = 0.0 <= hlutföllum && hlutföllum < 2.0 // 类型: bool
)
该例子使用冰岛语标识符表示 Go语言完全支持本土语言的标识符。(我们马上会讨论complex,参见2.3.2节。)
虽然Go语言的优先级规则比较合理(即不像C和C++那样),我们还是推荐使用括号来保证清晰的含义。强烈推荐使用多种语言进行编程的程序员使用括号,以避免犯一些难以发现的错误。
2.3.1 整型
Go语言提供了11种整型,包括5种有符号的和5种无符号的,再加上1种用于存储指针的整型类型。它们的名字和值在表2-5中给出。另外,Go语言允许使用byte来作为无符号uint8类型的同义词,并且使用单个字符(即Unicode码点)的时候提倡使用rune来代替int32。大多数情况下,我们只需要一种整型,即int。它可以用于循环计数器、数组和切片索引,以及任何通用目的的整型运算符。通常,该类型的处理速度也是最快的。本书撰写时,int类型表示成一个有符号的32位整型(即使在64位平台上也是这样的),但在Go语言的新版本中可能会改成64位的。
表2-5 Go语言的整数类型及其范围

从外部程序(如从文件或者网络连接)读写整数时,可能需要别的整数类型。这种情况下需要确切地知道需要读写多少位,以便处理该整数时不会发生错乱。
常用的做法是将一个整数以int 类型存储在内存中,然后在读写该整数的时候将该值显式地转换为有符号的固定尺寸的整数类型。byte(uint8)类型用于读或者写原始的字节。例如,用于处理UTF-8编码的文本。在前一章的americanise示例中,我们讨论了读写UTF-8编码的文本的基本方式,第8章中我们会继续讲解如何读写内置以及自定义的数据类型。
Go语言的整型支持表2-4中所列的所有算术运算,同时它们也支持表2-6中所列出的算术和位运算。所有这些操作的行为都是可预期的,特别是本书给出了很多示例,因此无需更深入讨论。
表2-6 只适用于内置的整数类型的算术运算操作符
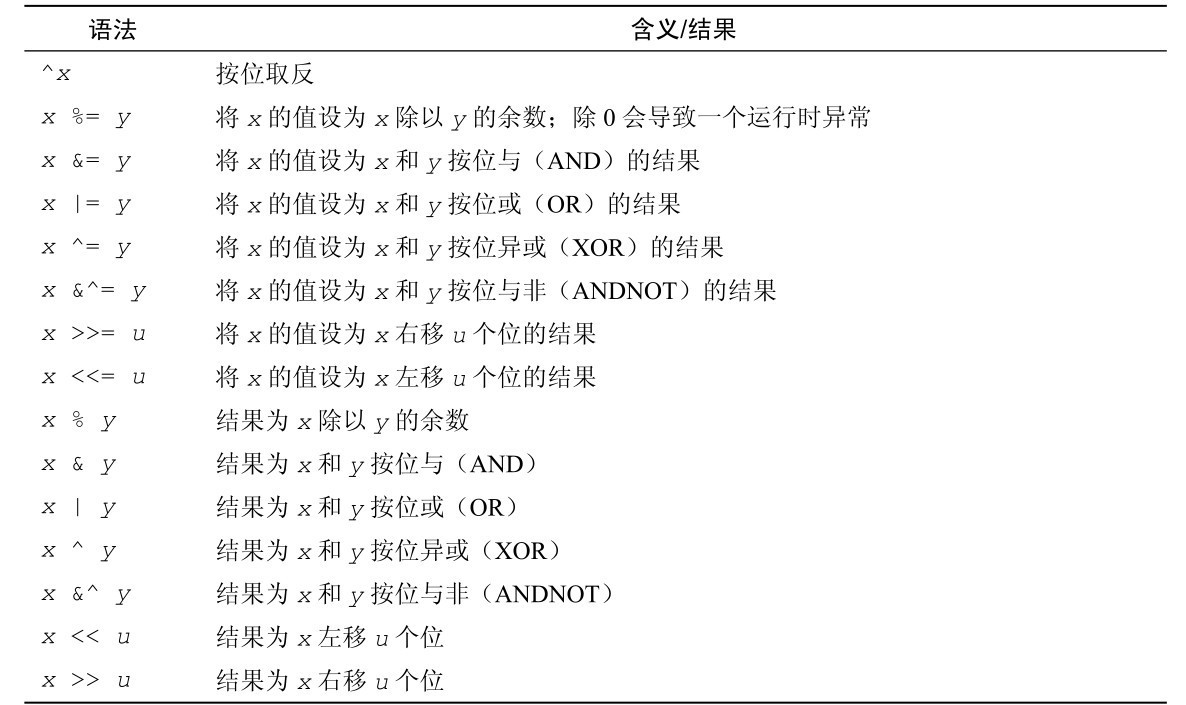
将一个更小类型的整数转换成一个更大类型的整数总是安全的(例如,从 int16 转换成int32),但是如果向下转换一个太大的整数到一个目标类型或者将一个负整数转换成一个无符号整数,则会产生无声的截断或者一个不可预期的值。这种情况下最好使用一个自定义的向下转换函数,如前文给出的那个。当然,当试图向下转换一个字面量时(如int8(200)),编译器会检测到问题,并报告异常错误。也可以使用标准 Go 语法将整数转换成浮点型数字(如float64(integer))。
有些情况下,Go语言对64位整数的支持让使用大规格的整数来进行高精度计算成为可能。例如,在商业上计算财务时使用int64类型的整数来表示百万分之一美分,可以使得在数十亿美元之内计算还保持着足够高的精度,这样做有很多用途,特别是当我们很关心除法操作的时候。如果计算财务时需要完美的精度,并且需要避免余数错误,我们可以使用big.Rat类型。
大整数
有时我们需要使用甚至超过int64位和uint64位的数字进行完美的计算。这种情况下,我们就不能使用浮点数了,因为它们表示的是近似值。幸运的是,Go语言的标准库提供了两个无限精度的整数类型:用于整数的big.Int型以及用于有理数的big.Rat型(即包括可以表示成分数的数字如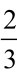 和1.1496,但不包括无理数如e或者π)。这些整数类型可以保存任意数量的数字——只要机器内存足够大,但是其处理速度远比内置的整型慢。
和1.1496,但不包括无理数如e或者π)。这些整数类型可以保存任意数量的数字——只要机器内存足够大,但是其处理速度远比内置的整型慢。
Go语言也像C和Java一样不支持操作符重载,提供给big.Int和big.Rat类型的方法有它自己的名字,如Add和Mul。在大多数情况下,方法会修改它们的接收器(即调用它们的大整数),同时会返回该接收器来支持链式操作。我们并没有列出 math/big 包中提供的所有函数和方法,它们都可以在文档上查到,并且也可能在本书出版之后又添加了新内容。但是,我们会给出一个具有代表性的例子来看看big.Int是如何使用的。
使用Go语言内置的float64类型,我们可以很精确地计算包含大约15位小数的情况,这在大多数情况下足够了。但是,如果我们想要计算包含更多位小数,即数十个甚至上百个小数时,例如计算 π的时候,那么就没有内置的类型可以满足了。
1706年,约翰·梅钦(John Machin)发明了一个计算任意精度 π 值的公式(见图2-1),我们可以将该公式与Go标准库中的big.Int结合起来计算 π,以得到任意位数的值。在图2-1中给出了该公式以及它依赖的arccot函数。(理解这里介绍的big.Int包的使用无需理解梅钦的公式。)我们实现的arccot函数接受一个额外的参数来限制计算结果的精度,以防止超出所需的小数位数。
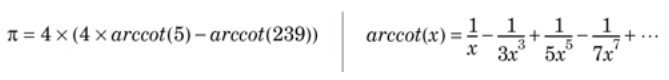
图2-1 Machin的公式
整个程序在文件pi_by_digits/pi_by_digits.go中,不到80行。下面是它的main函数[1]。
func main {
places := handleCommandLine(1000)
scaledPi := fmt.Sprint(π(places))
fmt.Printf("3.%s\n", scaledPi[1:])
}
该程序假设默认的小数位数为1 000,但是用户可以在命令行中指定任意的小数位数。handleCommandLine函数(这里没有给出)返回传递给它的值,或者是用户从命令行输入的数字(如果有并且是合法的话)。π函数将 π 以big.Int型返回,它的值为314159…。我们将该值打印到一个字符串,然后将字符串以适当的格式打印到终端,以便看起来像3.1415926535897 9323846264338327950288419716939937510这样(这里我们打印了将近50位)。
func π(places int) *big.Int {
digits := big.NewInt(int64(places))
unity := big.NewInt(0)
ten := big.NewInt(10)
exponent := big.NewInt(0)
unity.Exp(ten, exponent.Add(digits, ten), nil) ①
pi := big.NewInt(4)
left := arccot(big.NewInt(5), unity)
left.Mul(left, big.NewInt(4)) ②
right := arccot(big.NewInt(239), unity)
left.Sub(left, right)
pi.Mul(pi, left) ③
return pi.Div(pi, big.NewInt(0).Exp(ten, ten, nil)) ④
}
π函数开始时计算unity变量的值(10digits+10),我们将其当做一个放大因子来使用,以便计算的时候可以使用整数。为了防止余数错误,使用+10操作为用户添加额外10个数字。然后,我们使用了梅钦公式,以及我们修改过的接受unity 变量作为其第二个参数的arccot函数(没有给出)。最后,我们返回除以1010的结果,以还原放大因子unity的效果。
为了让unity变量保存正确的值,我们开始创建4个变量,它们的类型都是*big.Int(即指向big.Int的指针,参见4.1节)。unity和exponent变量都被初始化成0,变量ten初始化成10,digits被初始化成用户请求的数字的位数。unity值的计算一行就完成了(①)。big.Int.Add方法往变量digits中添加了10。然后big.Int.Exp方法用于将10增大到它的第二个参数(digits+10)的幂。如果第三个参数像这里一样是nil,big.Int.Exp(x, y, nil)进行xy计算。如果3个参数都是非空的,big.Int.Exp(x, y, z)执行(xy模z)。值得注意的是,我们无需将结果赋给unity变量,这是因为大部分big.Int方法返回的同时会修改它的接收器,因此在这里unity被修改成包含结果值。
接下来的计算模式类似。我们为pi设置一个初始值4,然后返回梅钦公式内部的左半部分。创建完成之后,我们无需将left的值赋回去(②),因为big.Int.Mul方法会在返回时将结果(我们可以安全地忽略它)保存回其接收器中(在本例中即保存回 left 变量中)。接下来,我们计算公式内部右半部分的值,并从left中减去right的值(将其结果保存在left)中。现在我们用pi(其值为4)乘以left(它保存了梅钦公式的结果)。这样就得到了结果,只是被放大了unity倍。因此,在最后一行中(④),我们将其值除以(1010)以还原其结果。
使用big.Int类型需小心,因为它的大多数方法都会修改它的接收器(这样做是为了节省创建大量临时big.Int值的开销)。与执行pi×left计算并将计算结果保存在pi中的那一行(③)相比,我们计算pi÷1010并将结果立即返回(④),而无需关心pi的值最后已经被修改。
无论什么时候,最好只使用int类型,如果int型不能满足则使用int64型,或者如果不是特别关心它们的近似值,则可以使用float32或者float64类型。然而,如果计算需要完美的精度,并且我们愿意付出使用内存和处理器的代价,那么就使用 big.Int 或者 big.Rat类型。后者在处理财务计算时特别有用。进行浮点计算时,如果需要可以像这里所做的那样对数值进行放大。
2.3.2 浮点类型
Go语言提供了两种类型的浮点类型和两种类型的复数类型,它们的名字及相应的范围在表 2-7中给出。浮点型数字在 Go语言中以广泛使用的IEEE-754 格式表示(http://en.wikipedia.org/wiki/IEEE_754-2008)。该格式也是很多处理器以及浮点数单元所使用的原生格式,因此大多数情况下Go语言能够充分利用硬件对浮点数的支持。
表2-7 Go语言的浮点类型

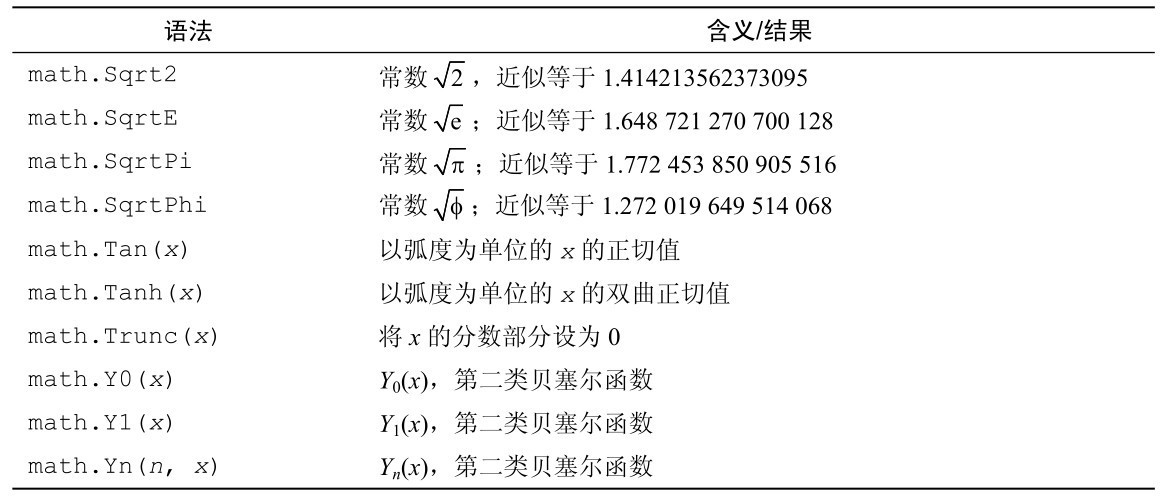
Go语言的浮点数支持表2-4中所有的算术运算。math包中的大多数常量以及所有函数都在表2-8和表2-10中列出。
表2-8 math包中的常量与函数 #1

续表

表2-9 math包中的常量与函数 #2

续表

表2-10 math包中的常量与函数 #3

续表
浮点型数据使用小数点的形式或者指数符号来表示,例如0.0、3.、8.2、−7.4、−6e4、.1以及5.9E-3等。计算机通常使用二进制表示浮点数,这意味着有些小数可以精确地表示(如0.5),但是其他的浮点数就只能近似表示(如 0.1和0.2)。另外,这种表示使用固定长度的位,因此它所能表示的数字的位数有限。这不是Go语言特有的问题,而是困扰所有主流语言的浮点数问题。然而,这种不精确性并不是总都这么明显,因为 Go语言使用了智能算法来输出浮点数,这些浮点数在保证精确性的前提下使用尽可能少的数字。
表2-3中所列出的所有比较操作都可以用于浮点数。不幸的是,由于浮点数是以近似值表示的,用它们来做相等或者不相等比较时并不总能得到预期的结果。
x, y := 0.0, 0.0
for i := 0; i < 10; i++ {
x += 0.1
if i%2 == 0{
y += 0.2
} else {
fmt.Printf("%-5t %-5t %-5t %-5t", x == y, EqualFloat(x, y, -1),
EqualFloat(x, y, 0.000000000001), EqualFloatPrec(x, y, 6))
fmt.Println(x, y)
}
}
true true true true 0.2 0.2
true true true true 0.4 0.4
false false true true 0.6 0.6000000000000001
false false true true 0.7999999999999999 0.8
false false true true 0.9999999999999999 1
这里开始时我们定义了两个float64型的浮点数,其初始值都为0。我们往第一个值中加上10个0.1,往第二个值中加上5个0.2,因此结果都为1。然而,正如代码片段下面所给出的输出所示,有些浮点数并不能得到完美的结果。这样看来,计算使用==以及!= 对浮点数进行比较时,我们必须非常小心。当然,有些情况下可以使用内置的操作符来比较浮点数的相等或者不相等性。例如,为了避免除数为0,可以这样做if y != 0.0 { return x / y}。
格式"%-5"以一个向左对齐的5 个字符宽的区域打印一个布尔值。字符串格式化的内容将在下一章讲解,参见3.5节。
func EqualFloat(x, y, limit float64) bool {
if limit <= 0.0 {
limit = math.SmallestNonzeroFloat64
}
return math.Abs(x-y) <= (limit * math.Min(math.Abs(x), math.Abs(y)))
}
EqualFloat函数用于在给定精度范围内比较两个float64型数,如果给定的精度范围为负数(如−1),则将该精度设为机器所能达到的最大精度。它还依赖于标准库math包中的一个函数(以及一个常量)。
一个可替代(也更慢)的方式是以字符串的形式比较两个数字。
func EqualFloatPrec(x, y float64, decimals int) bool {
a := fmt.Sprintf("%.*f", decimals, x)
b := fmt.Sprintf("%.*f", decimals, y)
return len(a) == len(b) && a == b
}
对于该函数,其精度以小数点后面数字的位数声明。fmt.Sprintf函数的%格式化参数能够接受一个*占位符,用于输入一个数字,因此这里我们基于给定的float64创建了两个字符串,每个字符串都以给定位数的尾数进行格式化。如果浮点数中数字的多少不一样,那么字符串a和b的长度也不一样(例如,12.32和592.85),这样就能给我们一个快速的短路测试。(字符串格式化的内容将在3.5节讲解。)
大多数情况下如果需要浮点数,float64类型是最好的选择,一个特别原因是math包中的所有函数都使用float64类型。然而,Go语言也支持float32类型,这在内存比较宝贵并且无需使用math包,或者愿意处理在与float64类型之间进行来回转换的不便时非常有用。由于Go语言的浮点类型是固定长度的,因此从外部文件或者网络连接中读写时非常安全。
使用标准的Go语法(例如int(float))可以将浮点型数字转换成整数,这种情况下小数部分会被丢弃。当然,如果浮点数的值超出了目标整型的范围,那么得到的结果值将是不可预期的。我们可以使用一个安全的转换函数来解决该问题。例如:
func IntFromFloat64(x float64) int {
if math.MinInt32 <= x && x <= math.MaxInt32 {
whole, fraction := math.Modf(x)
if fraction >= 0.5 {
whole++
}
return int(whole)
}
panic(fmt.Sprintf("%g is out of the int32 range", x))
}
Go语言规范(golang.org/doc/go_spec.html)中说明了int型所占的位数与uint相同,并且uint总是32位或者64位的。这意味着一个int型值至少是32位的,我们可以安全地使用math.MinInt32和math.MaxInt32常量来作为int的范围。
我们使用 math.Modf函数来分离给定数字(都是 float64 型数字)的整数以及分数部分,而非简单地返回整数部分(即截断),如果小数部分大于或者等于0.5,则向上取整。
与我们的自定义Uint8FromInt函数不同的是,我们不是返回一个错误值,而是将值越界当做一个需要停止程序运行的重要问题,因此我们使用了内置的panic函数,它会产生一个运行时异常,并停止程序继续运行,直到该异常被一个recover调用恢复(参见5.5节)。这意味着如果程序运行成功,我们就知道转换过程没有发生值越界。(值得注意的是,该函数并没有以一个return语句结束,Go编译器足够智能,能够意识到panic调用意味那里不会出现正常的返回值。)
复数类型
Go语言支持的两种复数类型已在表2-7中给出。复数可以使用内置的complex函数或者包含虚部数值的常量来创建。复数的各部分可以使用内置的real和imag函数来获得,这两个函数返回的都是float64型数(或者对于complex64类型的复数,返回一个float32型数)。
复数支持表2-4中所有的算术操作符。唯一可用于复数的比较操作符是==和!=(参见表2-3),但也会遇到与浮点数比较相同的问题。标准库中有一个复数包math/cmplx,表2-11给出了它的函数。
表2-11 Complex数学包中的函数

续表

这里有些简单的例子:
f := 3.2e5 // 类型:float64
x := -7.3 - 8.9i // 类型:complex128(字面量)
y := complex64(-18.3 + 8.9i) // 类型:complex64(转换)①
z := complex(f, 13.2) // 类型:complex128(构造)②
fmt.Println(x, real(y), imag(z)) // 打印:(-7.3-8.9i) -18.3 13.2
正如数学中所表示的那样,Go语言使用后缀i表示虚数[2]。这里,数x和z都是complex128类型的,因此它们的实部和虚部都是float64类型的。y是complex64类型的,因此它的各部分都是float32类型的。需要注意的一点小细节是,使用complex64类型的名字(或者是任何其他内置的类型名)来作为函数会进行类型转换。因此这里(①)复数 -18.3+8.9i(从复数字面量推断出来的复数类型为complex128)被转换成一个complex64类型的复数。然而, complex是一个函数,它接受两个浮点数输入,返回对应的complex128(②)。
另一个细节点是fmt.Println函数可以统一打印复数。(就像将在第6章看到的那样,我们可以创建自己的无缝兼容 Go语言的打印函数的类型,只需为它们简单地添加一个String方法即可实现。)
一般而言,最适合使用的复数类型是complex128,因为math/cmplx包中的所有函数都工作于complex128类型。Go语言也支持complex64类型,这在内存非常紧缺的情况下是非常有用的。Go语言的复数类型是定长的,因此从外部文件或网络连接中读写复数总是安全的。
本章中我们讲解了 Go语言的布尔类型以及数值类型,同时在表格中给出了可以查询和操作它们的操作符和函数。下一章将讲解Go语言的字符串类型,包括对Go语言的格式化打印功能(参见 3.5 节)的全面讲解,当然其中也包括我们需要的格式化打印布尔值和数字的内容。第8章中我们会看看如何对文件进行数据类型的读写,包括布尔型和数值类型,在本章结束之前,我们会讲解一个短小但是完全能够工作的示例程序。
2.4 例子:statistics
这个例子的目的是为了提高大家对Go编程的理解并提供实践机会。就如同第一章,这个例子使用了一些还没有完整讲解的Go语言特性。这应该不是大问题,因为我们提供了相应的简单解释和交叉引用。这个例子还很简单的使用了 Go语言官方网络库 net/http 包。使用net/http包我们可以非常容易地创建一个简单的HTTP服务器。最后,为了不脱离本章的主题,这节的例子和练习都是数值类型的。
statistics程序(源码在statistics/statistics.go文件里)是一个Web应用,先让用户输入一串数字,然后做一些非常简单的统计计算,如图 2-2 所示。我们分两部分来讲解这个例子,先介绍如何实现程序中相关的数学功能,然后再讲解如何使用net/http包来创建一个Web应用程序。由于篇幅有限,而且书中的源码均可从网上下载,所以有侧重地只显示部分代码(对于import部分和一些常量等可能会被忽略掉),当然,为了让大家能更好地理解我们会尽可能讲解得全面些。
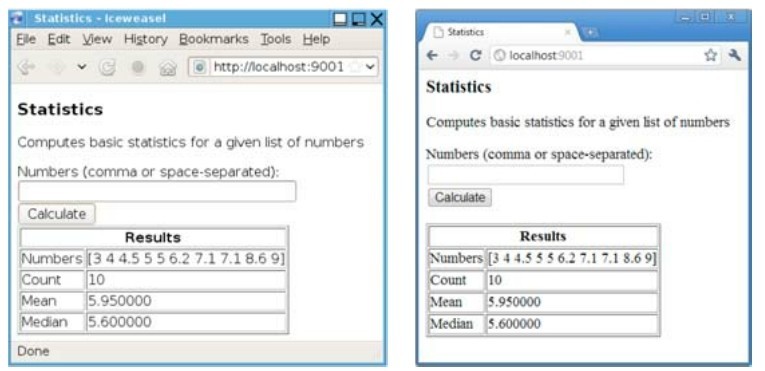
图2-2 Linux和Windows上的Statistics示例程序
2.4.1 实现一个简单的统计函数
我们定义了一个聚合类型的结构体,包含用户输入的数据以及我们准备计算的两种统计:
type statistics struct {
numbers float64
mean float64
mdian float64
}
Go语言里的结构体类似于C里的结构体或者Java里只有public数据成员的类(不能有方法),但是不同于C++的结构体,因为它并不是一个类。我们在6.4节将会看到,Go语言里的结构体对聚合和嵌入的支持是非常完美的,是Go语言面向对象编程的核心(主要介绍在第6章)。
func getStats(numbers float64) (stats statistics) {
stats.numbers = numbers
sort.Float64s(stats.numbers)
stats.mean = sum(numbers) / float64(len(numbers))
stats.median = median(numbers)
return stats
}
getStats 函数的作用就是对传入的float64 切片(这些数据都在processRequest里得到)进行统计,然后将相应的结果保存到stats结果变量中。其中计算中位数使用了sort包里的Float64s函数对原数组进行升序排列(原地排序),也就是说 getStats函数修改了它的参数,这种情况在传切片、引用或者函数指针到函数时是很常见的。如果需要保留原始切片,可以使用Go语言内置的copy函数(参见4.2.3节)将它赋值到一个临时变量,使用临时变量来工作。
结构体中的mean(通常也叫平均数)是对一连串的数进行求和然后除以总个数得到的结果。这里我们使用一个辅助函数sum求和,使用内置的len取得切片的大小(总个数)并将其强制转换成float64类型的变量(因为sum函数返回一个float64的值)。这样我们也就确保了这是一个浮点除法运算,避免了使用整数类型可能带来的精度损失问题。median是用来保存中位数的,我们使用median函数来单独计算它。
我们没有检查除数为0的情况,因为在我们的程序逻辑里,getStats函数只有在至少有1个数据的时候才会被调用,否则程序会退出并产生一个运行时异常(runtime panic)。对于一个关键性应用当发生一个异常时程序是不应该被结束的,我们可以使用 recover来捕获这个异常,将程序恢复到一个正常的状态,让程序继续运行(5.5节)。
func sum(numbers float64) (total float64) {
for _, x := range numbers {
total += x
}
return total
}
这个函数使用一个for…range循环遍历一个切片并将所有的数据相加计算出它们的和。Go语言总是将所有变量初始化为0,包括已经命名了的返回变量,例如total,这是一个相当有益的设计。
func median(numbers float64) float64 {
middle := len(numbers) / 2
result := numbers[middle]
if len(numbers)%2 == 0 {
result = (result + numbers[middle-1]) / 2
}
return result
}
这个函数必须传入一个已经排序好了的切片,它一开始将切片里最中间的那个数保存到result 变量中,但是如果总个数是偶数,就会产生两个中间数,我们取这两个中间数的平均值作为中位数返回。
在这一小部分里我们讲解了这个统计程序最主要的几个处理过程,在下一部分我们来看看一个只有简单页面的Web程序的基本实现。(读者如果对Web编程不感兴趣的话可以略过本节直接跳到练习或者跳到下一章。)
2.4.2 实现一个基本的HTTP服务器
这个statistics程序在本机上提供了一个简单网页,它的主函数如下:
func main {
http.HandleFunc("/", homePage)
if err := http.ListenAndServe(":9001", nil); err != nil {
log.Fatal("failed to start server", err)
}
}
http.HandleFunc函数有两个参数:一个路径,一个当这个路径被请求时会被执行的函数的引用。这个函数的签名必须是func(http.ResponseWriter, *http.Request)我们可以注册多个“路径-函数”对,这里我们只注册了“/”(通常是网页程序的主页)和一个自定义的homePage函数。
http.ListenAndServe函数使用给定的TCP地址启动一个Web服务器。这里我们使用localhost和端口9001。如果只指定了端口号而没有指定网络地址,默认情况下网络地址是 localhost。当然也可以这样写“localhost:9001”或者“127.0.0.1:9001”。端口的选择是任意的,如果和现有的服务器有冲突的话,比如端口已经被其他进程占用了等,修改代码中的端口为其他端口号即可。http.ListenAndServe的第二个参数支持自定义的服务器,为空的话(传一个nil参数)表示使用默认的类型。
这个程序使用了一些字符串常量,但是这里我们只展示其中的一个。
form = '<form action="/" method="POST">
<label for="numbers">Numbers (comma or space-separated):</label><br />
<input type="text" name="numbers" size="30"><br />
<input type="submit" >
</form>'
字符串常量form包含一个HTML的表单元素,包含一些文本和一个提交按钮。
func homePage(writer http.ResponseWriter, request *http.Request) {
err := request.ParseForm // 必须在写响应内容之前调用
fmt.Fprint(writer, pageTop, form)
if err != nil {
fmt.Fprintf(writer, anError, err)
} else {
if numbers, message, ok := processRequest(request); ok {
stats := getStats(numbers)
fmt.Fprint(writer, formatStats(stats))
} else if message != "" {
fmt.Fprintf(writer, anError, message)
}
}
fmt.Fprint(writer, pageBottom)
}
当统计网站被访问的时候会调用这个函数,request参数包含了请求的详细信息,我们可以往writer里写入一些响应信息(HTML格式)。
我们从分析这个表单开始吧。这个表单一开始只有一个空的文本输入框(text),我们将这个文本输入框标识为“numbers”,这样当后面我们处理这个表单的时候就能找到它。表单的action设置为"/",当用户点击Calculate按钮的时候这个页面被重新请求了一次。这也就是说不管什么情况这个homePage函数总是会被调用的,所以它必须处理几个情况:没有数据输入、有数据输入或者发生错误了。实际上,所有的工作都是由一个叫processRequest的自定义函数来完成的,它对每一种情况都做了相应的处理。
分析完表单之后,我们将pageTop(源码可见)和form这两个字符串常量写到writer里去(返回数据给客户端),如果分析表单失败我们写入一个错误信息:anError 是一个格式化字符串,err是即将被格式化的error值(格式化字符串3.5节会提到)。
anError = '<p>%s</p>'
如果分析成功了,我们调用自定义函数 processRequest处理用户键入的数据。如果这些数据都是有效的,我们调用之前提到过的getStats函数来计算统计结果,然后将格式化后的结果返回给客户端,如果接受到的数据无效,且我们得到了错误信息,则返回这个错误信息(当这个表单第一次显示的时候是没有数据的,也没有错误发生,这种情况下 ok 变量的值是false,而且message为空)。最后我们打印出pageBottom字符串常量(源码可见),用来关闭<body>和<html>标签。
func processRequest(request *http.Request) (float64, string, bool) {
var numbers float64
if slice, found := request.Form["numbers"]; found && len(slice) > 0 {
text := strings.Replace(slice[0], ",", " ", -1)
for _, field := range strings.Fields(text) {
if x, err := strconv.ParseFloat(field, 64); err != nil {
return numbers, "'" + field + "' is invalid", false
} else {
numbers = append(numbers, x)
}
}
}
if len(numbers) == 0 {
return numbers, "", false // 第一次没有数据被显示
}
return numbers, "", true
}
这个函数从request里读取表单的数据。如果这是用户首次请求的话,表单是空的,“numbers”输入框里没有数据,不过这并不是一个错误,所以我们返回一个空的切片、一个空的错误信息和一个false 布尔型的值,表明从表单里没有读取到任何数据。这些结果将会以空的表单形式被展示出来。如果用户有输入数据的话我们返回一个float64 类型的切片、一个空的错误信息以及true;如果存在非法数据,则返回一个可能为空的切片、一个错误消息和false。
request结构里有一个map[string]string类型的Form成员(参见4.3节),它的键是一个字符串,值是一个字符串切片,所以一个键可能有任意多个字符串在它的值里。例如:如果用户键入“5 8.2 7 13 6”,那么这个Form里有一个叫“numbers”的键,它的值是string{"5 8.2 7 13 6"},也就是说它的值是一个只有一个字符串的字符串切片(作为对比,这里有一个包含两个字符串的字符串切片:string{"1 2 3","a b c"})。我们检查这个“numbers”键是否存在(应该存在),如果存在,而且它的值至少有一个字符串,那么我们有数据可以读了。
我们使用strings.Replace函数(第三个参数指明要执行多少次替换,−1表示替换所有)将用户输入中的所有逗号转换为空格,得到一个新的字符串。新字符串里所有数据都是由空格分隔开的,再使用strings.Fields函数根据空白处将字符串切分成一个字符串切片,这样我们就可以直接使用for...range 循环来遍历它了(strings 这个包的函数参见3.6 节, for...range 循环请参见 5.3 节)。对于每一个字符串,例如“5”、“8.2”等,用strconv.ParseFloat函数将它转换成float64类型,这个函数需要传入一个字符串和一个位大小如32或者64(参见3.6节)。如果转换失败我们立即返回现有已经转好了的数据切片、一个非空的错误信息和false。如果转换成功我们将转换的结果float64类型的数据追加到numbers切片里去,内置的函数append可以将一个或多个值和原有切片合并返回一个新的切片,如果原来的切片的容量比长度大的话,这个函数执行的过程是非常快的,效率很高(关于append参见4.2.3节)。
假如程序没有因为错误退出(存在非法数据),将返回数值和一个空的错误信息以及true。没有数据需要处理(如这个表单第一次被访问的时候)的情况下返回false。
func formatStats(stats statistics) string {
return fmt.Sprintf('<table border="1">
<tr><th colspan="2">Results</th></tr>
<tr><td>Numbers</td><td>%v</td></tr>
<tr><td>Count</td><td>%d</td></tr>
<tr><td>Mean</td><td>%f</td></tr>
<tr><td>Median</td><td>%f</td></tr>
</table>', stats.numbers, len(stats.numbers), stats.mean, stats.median)
}
一旦计算完毕我们必须将结果返回给用户。因为程序是一个Web应用,所以我们需要生成HTML。(Go语言的标准库提供了用于创建数据驱动文本和HTML的text/template和html/template包,但是我们这里的需求比较简单,所以我们选择自己手动写HTML。9.4.2节有一个简单的使用text/template包的例子。)
fmt.Sprintf是一个字符串格式化函数,需要一个格式化字符串和一个或多个值,将这一个或多个值按照格式中指定的动作(如%v、%d、%f 等)进行转换,返回一个新的格式化后的字符串(格式化字符串在3.5节里有非常详细的描述)。我们不需要做任何的HTML转义,因为我们所有的值都是数字。(如果需要的话我们可以使用 template.HTMLEscape或者html.EscapeString函数。)
从这个例子可以了解,假如我们了解基本的HTML语法,使用Go语言来创建一个简单的Web应用是非常容易的。Go语言标准库提供的html、net/http、html/template和text/template等包让整个事情就变得更加简单。
2.5 练习
本章有两道数值相关的练习题。第一题需要修改我们之前的statistics 程序。第二题就是动手创建一个Web应用,实现一些简单的数学计算。
(1)复制 statistics 目录为比如 my_statistics,然后修改 my_statistics/statistics.go 代码,实现估算众数和标准差的功能,当用户点击页面上的Calculate 按钮时能产生类似图2-3所示的结果。
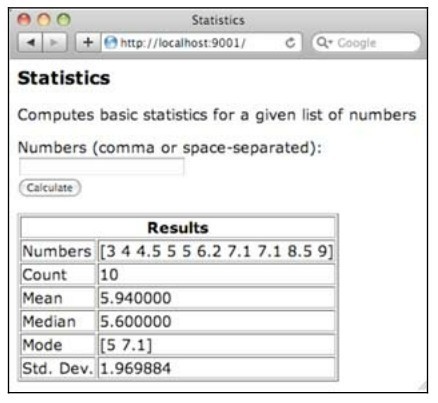
图2-3 MacOSX上的statistics示例程序
这需要在statistics 结构体里增加一些成员并实现两个新函数去执行计算。可以参考statistics_ans/statistics.go 文件里的答案。这大概增加了40 行代码和使用了Go语言内置的append函数将数字追加到切片里面。
写一个计算标准差的函数也很容易,只需要使用math 包里面的函数,不到 10 行代码就可以完成。我们使用公式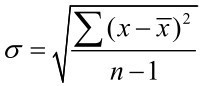 来计算,其中x表示每一个数字,
来计算,其中x表示每一个数字,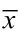 表示数学平均数,n是数字的个数。
表示数学平均数,n是数字的个数。
众数是指出现最多次的数,可能不止一个,例如有两个或者多个数的出现次数相等。但是,如果所有数的出现次数都是一样的话,我们就认为众数是不存在的。计算众数要比标准差难,大概需要20行左右的代码。
(2)创建一个Web应用,使用公式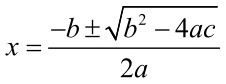 来求二次方程的解。要用复数,这样即使判别式b2−4ac部分为负能计算出方程的解。刚开始的时候可以先让程序能够工作起来,如图2-4左图所示,然后再修改你的代码让它输出得更美观一些,如图2-4右图所示。
来求二次方程的解。要用复数,这样即使判别式b2−4ac部分为负能计算出方程的解。刚开始的时候可以先让程序能够工作起来,如图2-4左图所示,然后再修改你的代码让它输出得更美观一些,如图2-4右图所示。
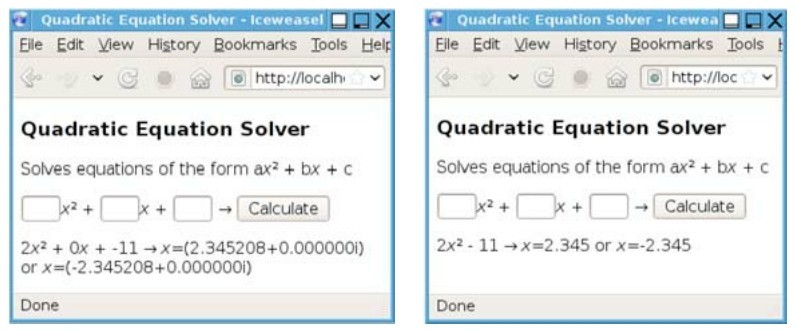
图2-4 Linux上的二次方程求解
最简单的做法就是直接使用 statistics 程序的main函数、homePage函数以及processRequest函数,然后修改 homePage让它调用我们自定义的3 个函数:formatQuestion、solve和formatSolutions,还有processRequest函数要用来读取那3个浮点数,这个改动的代码多一点。
第一个参考答案在quadratic_ans1/quadratic.go里,约120行代码,只实现了基本的功能,使用EqualFloat函数来判断方程的两个解是否是约等的,如果约等,只返回一个解。(EqualFloat函数在之前有讨论过。)
第二个参考答案在quadratic_ans2/quadratic.go里,约160行代码,相比第一个主要是优化了输出的结果。例如,它将“+ -”替换成“-”,将“1x”替换成“x”,去掉系数为0的项(例如“0x”等),使用math/cmplx包里的cmplx.IsNaN函数将一个虚数部分近似0的解转换成浮点数,等等。此外,还用了一些高级的字符串格式化技巧(主要在3.5节介绍)。
[1].这里的实现基于http://en.literateprograms.org/Pi_with_Machin's_formula_(Python)。
[2].相比之下,在工程上以及Python语言中,虚数用j来表示。