Egrep Metacharacters
现在我们来看egrep中支持正则表达式功能的元字符。我会用几个例子来简要介绍它们,把详细的例子和描述留到后面的章节。
印刷体例 在开始之前,请务必回顾前言第V页上解释的体例说明。本书使用了一些新的文字形式,所以某些体例读者初次接触可能并不熟悉。
行的起始和结束
Start and End of the Line
或许最容易理解的元字符就是脱字符号「^」和美元符号「$」了,在检查一行文本时,「^」代表一行的开始,「$」代表结束。我们曾经看到,正则表达式「cat」寻找的是一行文本中任意位置的c·a·t,但是「^cat」只寻找行首的 c·a·t——「^」用来把匹配文本(这个表达式的其他部分匹配的字符)“锚定”(anchor)在这一行的开头。同样,「cat$」只寻找位于行末的c·a·t,例如以scat结尾的行。
读者最好能养成按照字符来理解正则表达式的习惯。例如,不要这样:
「^cat」匹配以cat开头的行
而应该这样理解:
「^cat」匹配的是以c作为一行的第一个字符,紧接一个a,紧接一个t的文本。
这两种理解的结果并无差异,但按照字符来解读更易于明白新遇到的正则表达式的内部逻辑。egrep会如何解释「^cat$」、「^$」和单个的「^」呢?ϖ 请翻到下页查看答案。
脱字符号和美元符号的特别之处就在于,它们匹配的是一个位置,而不是具体的文本。当然,有很多方式可以匹配具体文本。在正则表达式中,除了使用「cat」之类的普通字符,还可以使用下面几节介绍的元字符。
字符组
Character Classes
匹配若干字符之一
如果我们需要搜索的是单词“grey”,同时又不确定它是否写作“gray”,就可以使用正则表达式结构体(construct)「[…]」。它容许使用者列出在某处期望匹配的字符,通常被称作字符组(character class(译注2))。「e」匹配字符e,「a」匹配字符a,而正则表达式「[ea]」能匹配a或者e。所以,「gr[ea]y」的意思是:先找到g,跟着是一个r,然后是一个a或者e,最后是一个y。我很不擅长拼写,所以总是用正则表达式从一大堆英文单词中找到正确的拼写。我经常使用的一个正则表达式是「sep[ea]r[ea]te」,因为我从来都记不住这个单词到底是写作“seperate”,“separate”,“separete”,还是别的什么样子。匹配的结果的就是正确的拼法,而正则表达式就是我的领路人。
请注意,在字符组以外,普通字符(例如「gr[ae]y」中的「g」和「r」)都有“接下来是(and then)”的意思——“首先匹配「g」,接下来是「r」……”。这与字符组内部的情况是完全相反的。字符组的内容是在同一个位置能够匹配的若干字符,所以它的意思是“或”。
来看另一个例子,我们还必须考虑单词的第一个字母为大写的情况,例如「[Ss]mith」。请记住,这个表达式仍然能够匹配内嵌在其他单词里头的 smith(或者是 Smith),例如blacksmith。在综述阶段,我不打算为这种情况费太多笔墨,但是这确实是某些新手遇到的问题的根源。等了解了更多的元字符以后,我会介绍一些办法来解决单词嵌套的问题。在一个字符组中可以列举任意多个字符。例如「[123456]」匹配1到6中的任意一个数字。这个字符组可以作为「<H[123456]>」的一部分,用来匹配<H1>、<H2>、<H3>等等。在搜索HTML代码的头文件时这非常有用。
在字符组内部,字符组元字符(character-class metacharacter)‘-’(连字符)表示一个范围:「<H[1-6]>」与「<H[123456]>」是完全一样的。「[0-9]」和「[a-z]」是常用的匹配数字和小写字母的简便方式。多重范围也是容许的,例如「[0123456789abcdefABCDEF]」可以写作「[0-9a-fA-F]」(或者也可以写作「[A-Fa-f0-9]」,顺序无所谓)。这3个正则表达式非常适用于处理十六进制数字。我们还可以随心所欲地把字符范围与普通文本结合起来:「[0-9A-Z_!.?]」能够匹配一个数字、大写字母、下画线、惊叹号、点号,或者是问号。
请注意,只有在字符组内部,连字符才是元字符——否则它就只能匹配普通的连字符号。其实,即使在字符组内部,它也不一定就是元字符。如果连字符出现在字符组的开头,它表示的就只是一个普通字符,而不是一个范围。同样的道理,问号和点号通常被当作元字符处理,但在字符组中则不是如此(说明白一点就是,「[0-9A-Z_!.?]」里面,真正的特殊字符就只有那两个连字符)。

不妨把字符组看作独立的微型语言。在字符组内部和外部,关于元字符的规定(哪
些是元字符,以及它们的意义)是不同的。
我们很快就会看到更多的例子。
排除型字符组
用「[^…]」取代「[…]」,这个字符组就会匹配任何未列出的字符。例如,「[^1-6]」匹配除了1到 6 以外的任何字符。这个字符组中开头的「^」表示“排除(negate)”,所以这里列出的不是希望匹配的字符,而是不希望匹配的字符。
读者可能注意到了,这里的^和第8页的表示行首的脱字符是一样的。字符确实相同,但意义截然不同。英语里的“wind”,根据情境的不同,可能表示一阵强烈的气流(风),也可能表示给钟表上发条;元字符也是如此。我们已经看过用来表示范围的连字符的例子。只有在字符组内部(而且不是第一个字符的情况下),连字符才能表示范围。在字符组外部,^表示一个行锚点(line anchor),但是在字符组内部(而且必须是紧接在字符组的第一个方括号之后),它就是一个元字符。请不要担心——这就是最复杂的情况,接下来的内容比这简单。
来看另一个例子,我们需要在一堆英文单词中搜索出一些特殊的单词:在这些单词中,字母 q后面的字母不是 u。用正则表达式来表示,就是「q[^u]」。用这个正则表达式来搜索我手头的数据,确实得到了一些结果,但显然不多,其中还有些是我没见过的英文单词。
下面是结果(我输入的命令用粗体表示):

其中有两个单词值得注意:伊拉克“Iraq”和澳大利亚航空公司的名字“Qantas”。尽管它们都在word.list文件中,但都不包含在egrep结果中。为什么呢?ϖ请动动脑筋,然后翻到下一页来检查你的答案。
请记住,排除型字符组表示“匹配一个未列出的字符(match a character that's not listed)”,而不是“不要匹配列出的字符(don't match what is listed)”。这两种说法看起来一样,但是Iraq的例子说明了其中的细微差异。有一种简单的理解排除型字符组的办法,就是把它们看作普通的字符组,里面包含的是除了“排除型字符组中所有字符”以外的字符。
用点号匹配任意字符
Matching Any Character with Dot
元字符「.」(通常称为点号dot或者小点point)是用来匹配任意字符的字符组的简便写法。如果我们需要在表达式中使用一个“匹配任何字符”的占位符(placeholder),用点号就很方便。例如,如果我们需要搜索03/19/76、03-19-76或者03.19.76,不怕麻烦的话用一个明确容许‘/’、‘-’、‘.’的字符组来构建正则表达式,例如「03[-./]19[-./]76」。也可以简单地尝试「03.19.76」。
读者第一次接触这个表达式时,可能还不清楚某些情况。在「03[-./]19[-./]76」中,点号并不是元字符,因为它们在字符组内部(记住,在字符组里面和外面,元字符的定义和意义是不一样的)。这里的连字符同样也不是元字符,因为它们都紧接在[或者[^之后。如果连字符不在字符组的开头,例如「[.-/]」,就是用来表示范围的,在本例中就是错误的用法。

在「03.19.76」中,点号是元字符——它能够匹配任意字符(包括我们期望的连字符、句号和斜线)。不过,我们也需要明白,点号可以匹配任何字符,所以这个正则表达式也能够匹配下面的字符串:‘lottery numbers: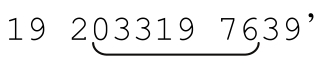
所以,「03[-./]19[-./]76」更加精确,但是更难读,也更难写。「03.19.76」更容易理解,但是不够细致。我们应该选择哪一个呢?这取决于你对需要检索的文本的了解,以及你需要达到的准确程度。一个重要但常见的问题是,写正则表达式时,我们需要在对欲检索文本的了解程度与检索精确性之间求得平衡。例如,如果我们知道,针对某个检索文本,「03.19.76」这个正则表达式基本不可能匹配不期望的结果,使用它就是合理的。要想正确使用正则表达式,清楚地了解目标文本是非常重要的。
多选结构
Alternation
匹配任意子表达式
「|」是一个非常简捷的元字符,它的意思是“或”(or)。依靠它,我们能够把不同的子表达式组合成一个总的表达式,而这个总的表达式又能够匹配任意的子表达式。假如「Bob」和「Robert」是两个表达式,但「Bob|Robert」就是能够同时匹配其中任意一个的正则表达式。在这样的组合中,子表达式称为“多选分支(alternative)”。
回头来看「gr[ea]y」的例子,有意思的是,它还可以写作「grey|gray」,或者是「gr(a|e)y」。后者用括号来划定多选结构的范围(正常情况下,括号也是元字符)。请注意,「gr[a|e]y」不符合我们的要求——在这里,‘|’只是一个和「a」与「e」一样的普通字符。
对表达式「gr(a|e)y」来说,括号是必须的,因为如果没有括号,「gra|ey」的意思就成了“「gra」或者「ey」”,而这不符合我们的要求。多选结构可以包括很多字符,但不能超越括号的界限。另一个例子是「(First|1st)·[Ss]treet」(注 5)。事实上,因为「First」和「1st」都以「st」结尾,我们可以把这个结合体缩略表示为「(Fir|1)st·[Ss]treet」。这样可能不容易看得清楚,但我们知道「(First|1st)」与「(fir|1)st」表示的是同一个意思。
下面是一些用多选结构来拼写我名字的例子。这3个表达式是一样的,请仔细比较:

英国拼写法如下:

最后要注意的是,这 3 个表达式其实与下面这个更长(但是更简单)的表达式是等价的:「Jeffrey|Geoffery|Jeffery|Geoffrey」。它们只是“殊途同归”而已。
「gr[ea]y」与「gr(a|e)y」的例子可能会让人觉得多选结构与字符组没太大的区别,但是请留神不要混淆这两个概念。一个字符组只能匹配目标文本中的单个字符,而每个多选结构自身都可能是完整的正则表达式,都可以匹配任意长度的文本。
字符组基本可以算是一门独立的微型语言(例如,对于元字符,它们有自己的规定),而多选结构是“正则表达式语言主体(main regular expression language)”的一部分。你将会发现,这两者都非常有用。
同样,在一个包含多选结构的表达式中使用脱字符和美元符的时候也要小心。比较「^From|Subject|Date:·」和「^(From|Subject|Date):·」就会发现,虽然它们看起来与之前的E-mail的例子很相似,匹配结果(即它们的用处)却大不相同。第一个表达式由3个多选分支构成,所以它能匹配「^From」或者「Subject」或者「Date:·」,实用性不大。我们希望在每一个多选分支之前都有脱字符,之后都有「:·」。所以应该使用括号来“限制”(constrain)这些多选分支:
「^(From|Subject|Date):·」
现在 3 个多选分支都受括号的限制,所以,这个正则表达式的意思是:匹配一行的起始位置,然后匹配「^From」、「Subject」或「Date」中的任意一个,然后匹配「:·」,所以,它能够匹配的文本是:
1)行起始,然后是F·r·o·m,然后是‘:·’,
或者 2)行起始,然后是S·u·b·j·e·c·t,然后是‘:·’,
或者 3)行起始,然后是D·a·t·e,然后是‘:·’。
简单点说,就是匹配以‘From:·’,‘Subject:·’或者‘Date:·’开头的文本行,在提取E-mail文件中的信息时这很有用。
下面是一个例子:

忽略大小写
Ignoring Differences in Capitalization
E-mail header的例子很适合用来说明不区分大小写(case-insensitive)的匹配的概念。E-mail header中的字段类型(field type)通常是以大写字母开头的,例如“Subject”和“From”,但是E-mail标准并没有对大小写进行严格的规定,所以“DATE”或者“from”也是合法的字段类型。但是,之前使用的正则表达式无法处理这种情况。
一种办法是用「[Ff][Rr][Oo][Mm]」取代「From」,这样就能匹配任何形式的“from”,但缺点之一就是很不方便。幸好,我们有一种办法告诉egrep在比较时忽略大小写,也就是进行不区分大小写的匹配,这样就能忽略大小写字母的差异。
该功能并不是正则表达式语言的一部分,却是许多工具软件提供的有用的相关特性。egrep的命令行参数“-i”表示进行忽略大小写的匹配。把-i写在正则表达式之前:
%egrep-i'^(From|Subject|Date):'mailbox
结果除了包括之前的内容外,还包含这一行:
SUBJECT:MAKE MONEY FAST
我使用-i参数的频率很高(也许与第12页的注解有关),所以我推荐读者记住它。在下面的章节中我们还会见到其他的简捷特性。
单词分界符
Word Boundaries
使用正则表达式时经常会遇到的一个问题,期望匹配的“单词”包含在另一个单词之中。在cat、gray和Smith的例子中,我曾提到过这个问题。不过,某些版本的egrep对单词识别提供了有限的支持:也就是单词分界符(单词开头和结束的位置)的匹配。
如果你的egrep支持“元字符序列(metasequences)” 「\<」和「\>」,就可以使用它们来匹配单词分界的位置。可以把它们想象为单词版本的「^」和「$」,分别用来匹配单词的开头和结束位置。就像作为行锚点的脱字符和美元符一样,它们锚定了正则表达式的其他部分,但在匹配过程中并不对应到任何字符。表达式「\<cat\>」的意思是“匹配单词的开头位置,然后是c·a·t这3个字母,然后是单词的结束位置”。更直接点说就是“匹配cat这个单词”。如果读者愿意,也可以用「\<cat」和「cat\>」来匹配以cat开头和结束的单词。
请注意,「<」和「>」本身并不是元字符——只有当它们与斜线结合起来的时候,整个序列才具有特殊意义。这就是我称其为“元字符序列”的原因。重要的是它们的特殊意义,而不是字符的个数,所以我说的“元字符”和“元(字符)序列”大多数时候是等价的。
请记住,并不是所有版本的 egrep 都支持单词分界符,即使是支持的版本也不见得聪明到能“认得出”英语单词。“单词的起始位置”只不过是一系列字母和数字符号(alphanumeric characters)开始的位置,而“结束位置”就是它们结尾的地方。下一页的图1-2说明了一行简单文本中的单词分界符。
(egrep 认定的)单词开头位置用向上的箭头标识,单词结束位置用向下的箭头标识。我们看到,“单词的开始和结束”准确地说是“字母数字符号的开始和结束”,不过这样说太麻烦了。
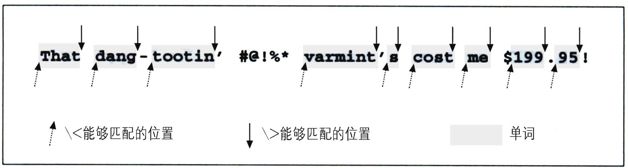
图1-2:“单词”的起始和结束位置
小结
In a Nutshell
表1-1总结了我们已经介绍过的元字符。
表1-1:至今为止所见的元字符小结

另外还有几点需要注意:
●在字符组内部,元字符的定义规则(及它们的意义)是不一样的。例如,在字符组外部,点号是元字符,但是在内部则不是如此。相反,连字符只有在字符组内部(这是普遍情况)才是元字符,否则就不是。脱字符在字符组外部表示一个意思,在字符组内部紧接着[时表示另一个意思,其他情况下又表示别的意思。
●不要混淆多选项和字符组。字符组「[abc]」和多选项「(a|b|c)」固然表示同一个意思,但是这个例子中的相似性并不能推广开来。无论列出的字符有多少,字符组只能匹配一个字符。相反,多选项可以匹配任意长度的文本,每个多选项可能匹配的文本都是独立的,例如「\<(1,000,000|million|thousand·thou)\>」。不过,多选项没有像字符组那样的排除功能。
●排除型字符组是表示所有未列出字符的字符组的简便方法。因此,「[^x]」的意思并不是“只有当这个位置不是x时才能匹配”,而是说“匹配一个不等于x的字符”。其中的差别很细微,但很重要。例如,前面的概念可以匹配一个空行,而「[^x]」则不行。
●
-i参数规定在匹配时不区分大小写(☞15)(注6)。
●目前介绍过的知识都很有用,但“可选项(optional)”和“计数(counting)”元素更重要,下文将马上介绍。
可选项元素
Optional Items
现在来看color和colour的匹配。它们的区别在于,后面的单词比前面的多一个u,我们可以用「colou?r」来解决这个问题。元字符「?」(也就是问号)代表可选项。把它加在一个字符的后面,就表示此处容许出现这个字符,不过它的出现并非匹配成功的必要条件。
「u?」这个元字符与我们之前看到的元字符都不相同,它只作用于之前紧邻的元素。因此,「colou?r」的意思是:「c」,然后是「o」,然后是「l」,然后是「o」,然后是「u?」,最后是「r」。
「u?」是必然能够匹配成功的,有时它会匹配一个u,其他时候则不匹配任何字符。关键在于,无论 u 是否出现,匹配都是成功的。但这并不等于,任何包含?的正则表达式都永远能匹配成功。例如,「colo」和「u?」都能在‘semicolon’中匹配成功(前者匹配单词中的colo,后者什么字符都没有匹配)。可是最后的「r」无法匹配,因此,最终「colou?r」无法匹配semicolon。
来看另一个例子,我们需要匹配表示7月4日(July fourth)的文本,其中月份可能写作July或是 Jul,而日期可能写作 fourth、4th 或者是 4。显然,我们可以使用「(July|Jul)· (fourth|4th|4)」,但也可以找些其他的办法来解决这个问题。
首先,我们把「(July|Jul)」缩短为「(July?)」。你明白这种等价变换吗?删除「|」之后,就没必要保留括号了。当然保留也可以,但不保留括号显得更整洁一些。于是我们得到「July?·(fourth|4th|4)」。
现在来看第二部分,我们可以把「4th|4」简化为「4(th)?」。我们看到,现在「?」作用的元素是整个括号了。括号内的表达式可以任意复杂,但是“从括号外来看”它们是个整体。界定「?」的作用对象(还可以划定我即将介绍的其他类似元字符的作用对象)是括号的主要用途之一。
我们的表达式现在成了「July?·(fourth|4(th)?)」。尽管它包含了许多元字符,而且有嵌套的括号,但理解起来并不困难。我们花了相当的工夫来讲解这两个简单的例子,但同时也接触到了一些相关的知识,它们相当有助于——或许你现在还意识不到——我们理解正则表达式。同样,通过这些讲解,我们也积累了依靠不同思路解决问题的经验。在阅读本书(同时也是在加深理解)寻找复杂问题的最优解决方案的过程中,你可能会发现灵感可能在不断涌现。正则表达式不是死板的教条,它更像是门艺术。
其他量词:重复出现
Other Quantifiers:Repetition
「+」(加号)和「*」(星号)的作用与问号类似。元字符「+」表示“之前紧邻的元素出现一次或多次”,而「*」表示“之前紧邻的元素出现任意多次,或者不出现”。换种说法就是,「…*」表示“匹配尽可能多的次数,如果实在无法匹配,也不要紧”。「…+」的意思与之类似,也是匹配尽可能多的次数,但如果连一次匹配都无法完成,就报告失败。问号、加号和星号这 3个元字符,统称为量词(quantifiers),因为它们限定了所作用元素的匹配次数。
与「…?」一样,正则表达式中的「…*」也是永远不会匹配失败的,区别只在于它们的匹配结果。而「…+」在无法进行任何一次匹配时,会报告匹配失败。
举例来说,「·?」能够匹配一个可能出现的空格,但是「·*」能够匹配任意多个空格。我们可以用这些量词来简化第9页<H[1-6]>的例子。按照HTML规范(注7),在tag结尾的>字符之前,可以出现任意长度的空格,例如<H3·>或者<H4···>。把「·*」加入正则表达式中的可能出现(但不是必须)空格的位置,就得到「H[1-6]·*」。它仍然能够匹配<H1>,因为空格并不是必须出现的,但其他形式的tag也能匹配。
接下来看类似<HR·SIZE=14>这样的HTML tag,它表示一条高度为14像素的穿越屏幕的水平线。与<H3>的例子一样,在最后的尖括号之前可以出现任意多个空格。此外,在等号两边也容许出现任意多个空格。最后,在 HR和 SIZE之间必须有至少一个空格。为了处理更多的空格,我们可以在「·」后添加「·*」,不过最好还是改写为「·+」。加号确保至少有一个空格出现,所以它与「··*」是完全等价的,只不过更简洁。所以我们得到「<HR·+SIZE·*=·*14·*>」。
尽管这个表达式不受空格数目的限制,但它仍然受tag中直线尺寸大小的约束。我们要找的不仅仅是高度为14的tag,而是所有这些tag。所以,我们必须用能匹配普通数值(general number)的表达式来替换「14」。在这里,“数值”(number)是由一位或多位数字(digits)构成的。「[0-9]」可以匹配一个数字,因为“至少出现一次”,所以我们使用加号量词,结果就是用「[0-9]+」替换「14」。(一个字符组是一个“元素”(unit),所以它可以直接加加号、星号等,而不需要用括号。)
这样我们就得到了「<HR·+SIZE·*=·*[0-9]+·*>」,尽管我用了粗体标识元字符,用空格来分隔各个元素,而且使用了“看得见的空格符”‘·’,这个表达式仍然不容易看懂(幸好,egrep提供了-i的参数☞15,这样我就不需要用「[Hh][Rr]」来表示「HR」了)。否则,「<HR+SIZE*=*[0-9]+*>」更令人迷惑。这个表达式之所以看起来有些诡异,是因为星号和加号作用的对象大都是空格,而人眼习惯于把空格和普通字符区分开来。在阅读正则表达式时,我们必须改变这种习惯,因为空格符也是普通字符之一,它与 j或者 4这样的字符没有任何差别(在后面的章节中,我们会看到,某些工具软件支持忽略空格的特殊模式)。
我们继续这个例子,如果尺寸这个属性也是可选的,也就是说<HR>就代表默认高度的直线(同样,在>之前也可能出现空格)。你能修改我们的正则表达式,让它匹配这两种类型的 tag 吗?解决问题的关键在于明白表示尺寸的文本是可选出现的(这是个暗示)。ϖ请翻到下一页查看答案。
请仔细观察最后(答案中)的表达式,体会问号、星号和加号之间的差异,以及它们在实际应用中的真正作用。下一页的表1-2总结了它们的意义。
请注意,每个量词都规定了匹配成功至少需要的次数下限,以及尝试匹配的次数上限。对某些量词来说,下限是0,对某些量词来说,上限是无穷大。

表1-2:“表示重复的元字符”含义小结

规定重现次数的范围:区间
某些版本的egrep能够使用元字符序列来自定义重现次数的区间:「…{min,max}」。这称为“区间量词(interval quantifier)”。例如,「…{3,12}」能够容许的重现次数在3到12之间。有人可能会用「[a-zA-Z]{1,5}」来匹配美国的股票代码(1 到5 个字母)。问号对应的区间量词是{0,1}。
支持区间表示法的egrep的版本并不多,但有许多另外的工具支持它。在第3章我们会仔细考察目前经常使用的元字符,那时候会涉及区间的支持问题。
括号及反向引用
Parentheses and Backreferences
到目前为止,我们已经见过括号的两种用途:限制多选项的范围;将若干字符组合为一个单元,受问号或星号之类量词的作用。现在我要介绍括号的另一种用途,虽然它在egrep中并不常见(不过流行的GNU版本确实支持这一功能),但在其他工具软件中很常见。
在许多流派(flavor)的正则表达式中,括号能够“记住”它们包含的子表达式匹配的文本。在解决本章开始提到的单词重复问题时就会用到这个功能。如果我们确切知道重复单词的第一个单词(比方说这个单词就是“the”),就能够明确无误地找到它,例如「the·the」。这样或许还是会匹配到 的情况,但如果我们的egrep支持在第15页提到的单词分界符「\<the·the\>」,这个问题就很容易解决。我们可以添加「·+」把这个表达式变得更灵活。
的情况,但如果我们的egrep支持在第15页提到的单词分界符「\<the·the\>」,这个问题就很容易解决。我们可以添加「·+」把这个表达式变得更灵活。
然而,穷举所有可能出现的重复单词显然是不可能完成的任务。如果我们先匹配任意一个单词,接下来检查“后面的单词是否与它一样”,就好办多了。如果你的egrep支持“反向引用(backreference)”,就可以这么做。反向引用是正则表达式的特性之一,它容许我们匹配与表达式先前部分匹配的同样的文本。
我们先把「\<the·+the\>」中的第一个「the」替换为能够匹配任意单词的正则表达式「[A-Za-z]+」;然后在两端加上括号(原因见下段);最后把后一个‘the’替换为特殊的元字符序列「\1」,就得到了「\<([A-Za-z]+)·+\1\>」。
在支持反向引用的工具软件中,括号能够“记忆”其中的子表达式匹配的文本,不论这些文本是什么,元字符序列「\1」都能记住它们。
当然,在一个表达式中我们可以使用多个括号。再用「\1」、「\2」、「\3」等来表示第一、第二、第三组括号匹配的文本。括号是按照开括号‘(’从左至右的出现顺序进行的,所以「([a-z])([0-9])\1\2」中的「\1」代表「[a-z]」匹配的内容,而「\2」代表「[0-9]」匹配的内容。
在‘the·the’的例子中,「[A-Za-z]+」匹配第一个‘the’。因为这个子表达式在括号中,所以「\1」代表的文本就是‘the’。如果「·+」能够匹配,后面的「\1」要匹配的文本就是‘the’。如果「\1」也能成功匹配,最后的「\>」对应单词的结尾(如果文本是‘the·theft’,这一条就不满足)。如果整个表达式能匹配成功,我们就得到一个重复单词。有的重复单词并不是错误,例如‘that that’(译注3),这并不是正则表达式的错误,真正的判断还得靠人。我决定使用上面这个例子的时候,已经用这个表达式检查过本书之前的内容了(我使用的是支持「\<…\>」和反向引用的egrep)。我还使用了第15页提到的忽略大小写的参数-i来拓宽它的适用范围(注8),所以‘The·the’这样的单词重复也能提取出来。
我使用的命令如下:
%egrep-i'\<([a-z]+)+\1\>'files…
结果令我惊奇,居然找到了14组重复单词。我把它们全都改正了,而且把这个表达式添加到我用来检查本书拼写错误的工具中,保证从此以后全书中不会出现这样的错误。
尽管这个表达式很有用,我们仍然需要重视它的局限。因为egrep把每行文字都当作一个独立部分来看待,所以如果单词重复的第一个单词在某行末尾,第二个单词在下一行的开头,这个表达式就无法找到。所以,我们需要更加灵活的工具,下一章我们会看到这方面的例子。
神奇的转义
The Great Escape
有个重要的问题我尚未提及,即:如果需要匹配的某个字符本身就是元字符,正则表达式会如何处理呢?例如,如果我想要检索互联网的主机名ega.att.com,使用「ega.att.com」可能得到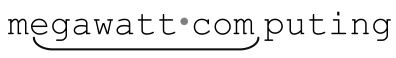 的结果。还记得吗?「.」本身就是元字符,它可以匹配任何字符,包括空格。
的结果。还记得吗?「.」本身就是元字符,它可以匹配任何字符,包括空格。
真正匹配文本中点号的元序列应该是反斜线(backslash)加上点号的组合:「ega\.att\.com」。「\.」称为“转义的点号”或者“转义的句号”,这样的办法适用于所有的元字符,不过在字符组内部无效(注9)。
这样使用的反斜线称为“转义符(escape)”——它作用的元字符会失去特殊含义,成了普通字符。如果你愿意,也可以把转义符和它之后的元字符看作特殊的元字符序列,这个元字符序列匹配的是元字符对应的普通字符。这两种看法是等价的。
我们还可以用「\([a-zA-Z]+\)」来匹配一个括号内的单词,例如‘(very)’。在开闭括号之前的反斜线消除了开闭括号的特殊意义,于是他们能够匹配文本中的开闭括号。
如果反斜线后紧跟的不是元字符,反斜线的意义就依程序的版本而定。例如,我们已经知道,某些版本的程序把「\<」、「\>」、「\1」当作元字符序列对待。在后面的章节中我们会看到更多的例子。