Match Basics
在了解不同引擎的差异之前,我们先看看它们的相似之处。汽车的各种动力系统在某些方面是一样的(或者说,从实用的角度考虑,它们是一样的),所以,下面的范例也能够适用于所有的引擎。
关于范例
About the Examples
本章关注的是一般的提供所有功能的正则引擎,所以,某些程序并不能完全支持它们。在本书所说的汽车里,机油油尺(dipstick)可能挨在机油滤清器(oil filter)的左边,而在读者那里,它却装在分电盘盖(distributor cap)的后面。不过,读者要做的只是理解这些概念,能够使用和维护自己最喜欢(以及他们最感兴趣)的正则表达式包。
在大部分例子中,我仍然使用Perl表示法,虽然我偶尔会用一些其他的表示法来提醒读者,表示法并不重要,我们讨论的问题与程序和表示法不属于一个层次。为节省篇幅,如果读者遇到不熟悉的构建方式,请查阅第3章(☞114)。
本章详细阐释了匹配执行的实际流程。理想的情况是,所有的知识都能归纳为几条容易记忆的简单规则,使用者不需要了解这些规则包含的原理。很不幸,事实并非如此。整个第4章只能列出两条普适的原则:
1.优先选择最左端(最靠开头)的匹配结果。
2.标准的匹配量词(「*」、「+」、「?」和「{m,n}」)是匹配优先的。
在本章中,我们将考察这些规则,它们的结果,以及其他许多内容。首先我们详细讨论第一条规则。
规则1:优先选择最左端的匹配结果
Rule 1:The Match That Begins Earliest Wins
根据这条规则,起始位置最靠左的匹配结果总是优先于其他可能的匹配结果。这条规则并没有规定优先的匹配结果的长度(稍后将会讨论),而只是规定,在所有可能的匹配结果中,优先选择开始位置最左端的。实际上,因为可能有多个匹配结果的起始位置都在最左端,也许我们应该把这条规则中的“某个匹配结果(a match)”改为“该匹配结果(the match)”,不过这听起来有些别扭。
这条规则的由来是:匹配先从需要查找的字符串的起始位置尝试匹配。在这里,“尝试匹配(attempt)”的意思是,在当前位置测试整个正则表达式(可能很复杂)能匹配的每样文本。如果在当前位置测试了所有的可能之后不能找到匹配结果,就需要从字符串的第二个字符之前的位置开始重新尝试。在找到匹配结果以前必须在所有的位置重复此过程。只有在尝试过所有的起始位置(直到字符串的最后一个字符)都不能找到匹配结果的情况下,才会报告“匹配失败”。
所以,如果要用「ORA」来匹配FLORAL,从字符串左边开始第一轮尝试会失败(因为「ORA」不能匹配 FLO),第二轮尝试也会失败(「ORA」同样不能匹配 LOR),从第三个字符开始的尝试能够成功,所以引擎会停下来,报告匹配结果 。
。
如果不了解这条规则,有时候就不能理解匹配的结果。例如,用「cat」来匹配:
The dragging belly indicates that your cat is too fat.
结果是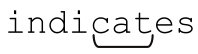 ,而不是后来出现的cat。单词cat是能够被匹配的,但indicates中的cat出现的更早,所以得到匹配的是它。对于egrep之类的程序来说,这种差别是无关紧要的,因为它只关心“是否”能够匹配,而不是“在哪里”匹配。但如果是进行其他的应用,例如查找和替换,这种差别就很重要了。
,而不是后来出现的cat。单词cat是能够被匹配的,但indicates中的cat出现的更早,所以得到匹配的是它。对于egrep之类的程序来说,这种差别是无关紧要的,因为它只关心“是否”能够匹配,而不是“在哪里”匹配。但如果是进行其他的应用,例如查找和替换,这种差别就很重要了。
这里有一个小测验(应该不困难):如果用「fat|cat|belly|your」来匹配字符串‘The dragging belly indicates that your cat is too fat.’,结果是什么呢?ϖ请看下一页。
“传动装置(transmission)”和驱动过程(bump-along)
或许汽车变速箱(译注1)的例子有助于理解这条规则,驾驶员在换档时,变速箱负责连接引擎和动力系统。引擎是真正产生动力的地方(它驱动曲轴),而变速箱把动力传送到车轮。
传动装置的主要功能:驱动
如果引擎不能在字符串开始的位置找到匹配的结果,传动装置就会推动引擎,从字符串的下一个位置开始尝试,然后是下一个,再下一个,如此继续。不过,如果某个正则表达式是以“字符串起始位置锚点(start-of-string anchor)”开头的,传动装置就会知道,不需要更多的尝试,因为如果能够匹配,结果肯定是从字符串的头部开始的。在第 6 章中,我们会讲解这一点,以及更多的内部优化措施。
引擎的构造
Engine Pieces and Parts
所有的引擎都是由不同的零部件组合而成的。如果对这些零件缺乏了解,也就不可能真正理解引擎的工作原理。正则引擎中的这些零件分为几类——文字字符(literal characters)、量词(qualifiers)、字符组(character classes)、括号,等等,我们在第3章介绍过(☞114)。这些零件的组合方式(以及正则引擎对它们的处理方式)决定了引擎的特性,所以,这些零件的组合方式,以及它们之间的配合,是我们主要关注的东西。首先,让我们来看看这些零件:
文字文本(Literal Text)例如a、*、!、枝…
对于非元字符的文字字符,尝试匹配时需要考虑就是“这个字符与当前尝试的字符相同吗?”。如果一个正则表达式只包含纯文本字符,例如「usa」,那么正则引擎会将其视为:一个「u」,接着一个「s」,接着一个「a」。进行不区分大小写的匹配时的情况要复杂一点,因为「b」能够匹配 B,而「B」也能匹配 b,不过这仍然不难理解(Unicode的情况稍微复杂一些☞110)。
字符组、点号、Unicode属性及其他
通常情况下,字符组、点号、Unicode属性及其他的匹配是比较简单的:无论字符组的长度是多少,它都只能匹配一个字符(注2)。
点号可以很方便地表示复杂的字符组,它几乎能匹配所有字符,所以它的作用也很简单,其他的简便方式还包括「w」,「W」和「d」。
捕获型括号
用于捕获文本的括号(而不是用于分组的括号)不会影响匹配的过程。

锚点(e.g.,「^」 「z」 「(?<=d)」…)
锚点可以分为两大类:简单锚点(^、$、G、b、…☞129)和复杂锚点(例如顺序环视和逆序环视☞133)。简单锚点之所以得名,就在于它们只是检查目标字符串中的特定位置的情况(^、Z…),或者是比较两个相邻的字符(<、b、…)。相反,复杂锚点(环视)能包含任意复杂的子表达式,所以它们也可以任意复杂。
非“电动”的括号、反向引用和忽略优先量词
虽然本章希望讲解的是引擎之间的相似之处,但为了方便读者理解本章余下的内容,这里必须指出一些有意义的差异。捕获括号(以及相应的反向引用和$1表示法)就像汽油添加剂一样——它们只对汽油机(NFA)起作用,对电动机(DFA)不起作用。忽略优先量词也是如此。这种情况是由DFA的工作原理决定的(注3)。这解释了,为什么DFA引擎不支持这些特性。读者会看到,awk、lex和egrep都不支持反向引用和$1功能(表示法)。
也许读者会注意到,GNU 版本的egrep 确实支持反向引用。这是因为它包含了两台不同的引擎。它首先使用DFA查找可能的匹配结果,再用NFA(支持包括反向引用在内的所有特性)来确认这些结果。接下来,我们将看到DFA不能支持反向引用及捕获括号的原因,以及这种引擎能够存在的理由(DFA有很多显著的优势,例如匹配速度非常快)。
规则2:标准量词是匹配优先的
Rule 2:The Standard Quantifiers Are Greedy
至今为止,我们看到的特性都非常易懂。但仅仅靠它们还很不够——要完成复杂点的任务,就需要使用星号、加号、多选结构之类功能更强大的元字符。要彻底理解这些功能,需要学习更多的知识。
读者首先需要记住的是,标准匹配量词(?、*、+,以及{min,max})都是“匹配优先(greedy)”的。如果用这些量词来约束某个表达式,例如「(expr)*」中的「(expr)」、「a?」中的「a」和「[0-9]+」中的「[0-9]」,在匹配成功之前,进行尝试的次数是存在上限和下限的。在前面的章节中我们已经提到过这一点——而规则 2 表明,这些尝试总是希望获得最长的匹配(一些工具提供了其他的匹配量词,但是本节只讨论标准的匹配优先量词)。
简而言之,标准匹配量词的结果“可能”并非所有可能中最长的,但它们总是尝试匹配尽可能多的字符,直到匹配上限为止。如果最终结果并非该表达式的所有可能中最长的,原因肯定是匹配字符过多导致匹配失败。举个简单的例子:用「bw+sb」来匹配包含‘s’的字符串,比如说‘regexes’,「w+」完全能够匹配整个单词,但如果用「w+」来匹配整个单词,「s」就无法匹配了。为了完成匹配,「w+」必须匹配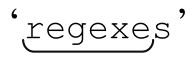 ’,把最后的「sb」留出来。
’,把最后的「sb」留出来。
如果表达式的其他部分能够成功匹配的唯一条件是,匹配优先的结构不匹配任何字符,在容许零匹配(译注2)的情况下(例如使用星号、问号,或者{0,max},这是没有问题的。不过,这种情况只有在表达式的后续部分强迫下才能发生。匹配优先量词之所以得名,是因为它们总是(或者,至少是尝试)匹配多于匹配成功下限的字符。
匹配优先的性质可以非常有用(有时候也非常讨厌)。它可以用来解释「[0-9]+」为什么能匹配March·1998中的所有数字。1匹配之后,实际上已经满足了成功的下限,但此正则表达式是匹配优先的,所以它不会停在此处,而会继续下去,继续匹配‘998’,直到这个字符串的末尾(因为「[0-9]」不能匹配字符串最后的空档,所以会停下来)。
邮件主题
显然,这种匹配方式并非只能用于匹配数字。举例来说,如果我们需要判断E-mail的header中的某行字符是否标题行(subject line)。前面(☞55)我们已经说过,可以用「^Subject:」来实现。不过,如果使用 ,我们就能在之后的程序中使用捕获型括号来访问主题的内容(例如Perl中的$1)(译注3)。
,我们就能在之后的程序中使用捕获型括号来访问主题的内容(例如Perl中的$1)(译注3)。
在探讨「.*」匹配邮件主题之前,请读者记住,一旦「^Subject:·」能够部分匹配,整个正则表达式就一定能够全部匹配。因为「^Subject:·」之后没有字符会导致表达式匹配失败:「.*」永远不会失败,因为“不匹配任何字符”也是「.*」的可能结果之一。
那么,为什么要添加「.*」呢?这是因为我们知道,星号是匹配优先的,它会用点号匹配尽可能多的字符,所以我们用它来“填充”$1。事实上,括号并没有影响正则表达式的匹配过程,在本例中,我们只是用它们来包括「.*」匹配的字符。
「.*」到达字符串的末尾之后点号不能继续匹配,所以星号最终停下来,尝试匹配表达式中的下一个元素(尽管「.*」无法继续匹配了,但下面的子表达式或许能够继续匹配)。不过,因为本例中不存在后面的元素,到达表达式的末尾之后,我们就获得了成功的匹配结果。
过度的匹配优先
现在让我们回过头去看“尽可能匹配”的匹配优先量词。如果我们在上面的例子中增加一个「.*」,把正则表达式写作 ,结果会是如何呢?答案是,没有变化。开头的「.*」(括号中的)会霸占整个标题的文本,而不给第二个「.*」留下任何字符。而第二个「.*」的匹配失败并不要紧,因为「.*」不匹配任何字符也能成功。如果我们给第二个「.*」也加上括号,$2将会是空白。
,结果会是如何呢?答案是,没有变化。开头的「.*」(括号中的)会霸占整个标题的文本,而不给第二个「.*」留下任何字符。而第二个「.*」的匹配失败并不要紧,因为「.*」不匹配任何字符也能成功。如果我们给第二个「.*」也加上括号,$2将会是空白。
这是否说明,在正则表达式中,「.*」的部分没有机会匹配任何字符呢?答案显然是否定的。就像我们在「w+s」这个例子中看到的,如果进行全部匹配必须这样做,表达式中的某些部分可能“强迫”之前匹配优先的部分“释放”(或者说“交还(unmatch)”)某些字符。
「^.*([0-9][0-9])」或许是个有用的正则表达式,它能够匹配一行字符的最后两位数字,如果有的话,然后将它们存储在$1 中。下面是匹配的过程:「.*」首先匹配整行,而「[0-9] [0-9]」是必须匹配的,在尝试匹配行末的时候会失败,这样它会通知「.*」:“嗨,你占的太多了,交出一些字符来吧,这样我没准能匹配。”匹配优先组件首先会匹配尽可能多的字符,但为了整个表达式的匹配,它们通常需要“释放”一些字符(抑制自己的天性)。当然,它们并不“愿意”这样做,只是不得已而为之。当然,“交还”绝不能破坏匹配成立必须的条件,比如加号的第一次匹配。
明白了这一点,我们来看「^.*([0-9][0-9])」匹配‘about·24·characters·long’的过程。「.*」匹配整个字符串以后,第一个「[0-9]」的匹配要求「.*」释放一个字符‘g’(最后的字符)。但是这并不能让「[0-9]」匹配,所以「.*」必须继续“交还”字符,接下来交还的字符是‘n’。如此循环15次,直到「.*」最终释放‘4’为止。
不幸的是,即使第一个「[0-9]」能够匹配‘4’,第二个「[0-9]」仍然不能匹配。为了匹配整个正则表达式,「.*」必须再次释放一个字符,这次是‘2’,由第一个「[0-9]」匹配。现在,‘4’能够由第二个「[0-9]」匹配,所以整个表达式匹配的是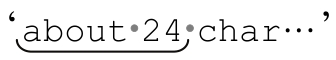 ’,$1的值是‘24’。
’,$1的值是‘24’。
先来先服务
如果用「^.*[0-9]+」来匹配一行的最后两个数字,期望匹配的不止是最后两位数字,而是最后的整个数,结果会是多长呢?如果用它来匹配‘Copyright 2003.’,结果是什么?ϖ答案在下一页。
深入细节
在这里必须澄清一些东西。因为“「.*」必须交还…”或者“「[0-9]」迫使…”之类的说法或许容易引起混淆。我使用这些说法是因为它们易于理解,而且跟实际的结果一致。不过,事情的真相是由基本的引擎类型决定——是DFA,还是NFA。现在我们就来看这些。