A Sobering Example
首先来看一个真正体现回溯和效率的重要性的例子。在198页,我们用「"(\\.|[^\\"])*"」来匹配引号字符串,其中容许出现转义的双引号。这个表达式没有错,但如果我们使用NFA引擎,对每个字符都应用多选结构的效率就会很低。对字符串中每个“正常”(非转义、非引用)的字符来说,这个引擎需要测试「\\.」,遇到失败后回溯,最终由「[^\\"]」匹配。如果效率不容忽视,就应该做些改动来加快匹配速度。
稍加修改——先迈最好使的腿
A Simple Change—Placing Your Best Foot Forward
对于一般的双引号字符串来说,普通字符的数量比转义字符要多,一个简单的改动就是调换两个多选分支的顺序,把「[^\\"]」放到「\\.」之前。这样,只有在遇到字符串中的转义字符时才会按照多选结构进行回溯(还有一次回溯是星号无法匹配引起的,此时所有的多选分支都匹配失败,所以整个多选结构无法匹配)。图6-1说明了其中的差异。箭头数量的减少,说明第一个多选分支的成功匹配次数增加了,也就是说回溯的次数减少了。
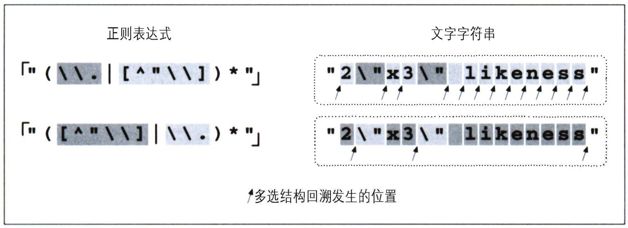
图6-1:多选分支排列顺序的影响(传统型NFA)
请从下面几个方面评价这个修改:
●哪种引擎从中获益?传统型NFA,或者POSIX NFA,或是两者?
●什么情况下,这种修改带来的收益最大?在文本能够匹配时,无法匹配时,还是所有时候。
ϖ 请思考这些问题,翻到下一页查看答案。在阅读下一节以前,务必理解答案(及原因)。
效率vs准确性
Efficiency Versus Correctness
为提高效率修改正则表达式时最需要考虑的问题是,改动是否会影响匹配的准确性。像上面那样重新安排多选分支的顺序,只有在排序与匹配成功无关时才不会影响准确性。前一章出现的「"(\\.|[^"])*"」(☞197)的例子是有缺陷的。如果正则表达式只需要(should)应用于格式正确的字符串,此问题永远也不会暴露出来。如果认为这个表达式很不错,改动的确提高了效率,我们就会遇到真正的问题。交换多选分支,把「[^"]」放在前面,避免表达式进行不正确的匹配,如果目标字符串包含一个转义的双引号:
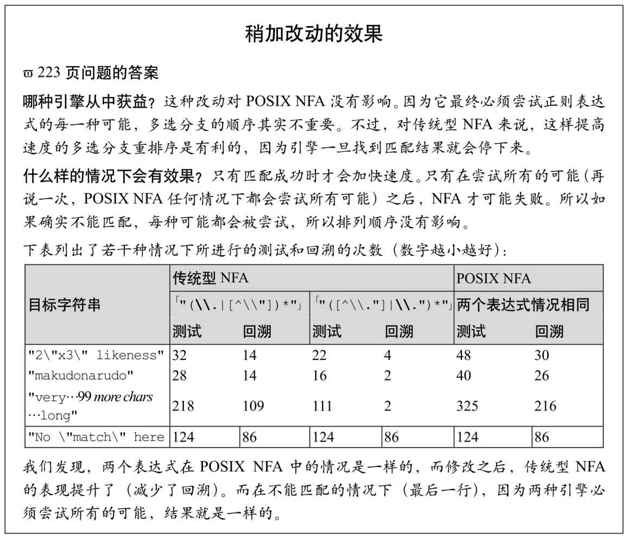
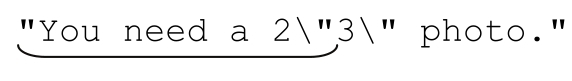
所以,在关注效率的时候,万不可忘记准确性。
继续前进——限制匹配优先的作用范围
Advancing Further—Localizing the Greediness
从图6-1可以看出,在任意正则表达式中,星号会对每个普通字符进行迭代(或者说“重复”),重复进入-退出多选结构(和括号)。这需要成本,也就是额外的处理——如果可能,我们必须避免这些额外处理。
有一次,在处理这类正则表达式时,我想到一个优化的办法,考虑到「[^\\"]」匹配“普通”(非引号,非反斜线)的情况,使用「[^\\"]+」会在(…)*的一次迭代中读入尽可能多的字符。对没有转义字符的字符串来说,这样会一次读入整个字符串。于是就几乎不会进行回溯,也就把星号迭代的次数减少到最小。我很为自己的发现而高兴。
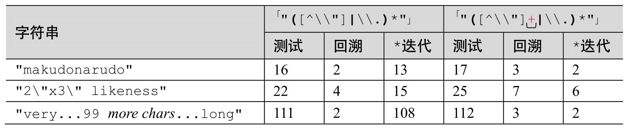
我们会在本章更深入地考察这个例子,不过看一眼统计数据会清楚地发现好处。图6-2展示了传统型 NFA 上应用这个例子的情况。比较原来的「"(\\.|[^\\"])*"」(上面的两个表达式),与多选结构相关的回溯和星号迭代都减少了。下面的两个例子说明,结合之前的重排序技巧,这种修改会带来更多的收益。
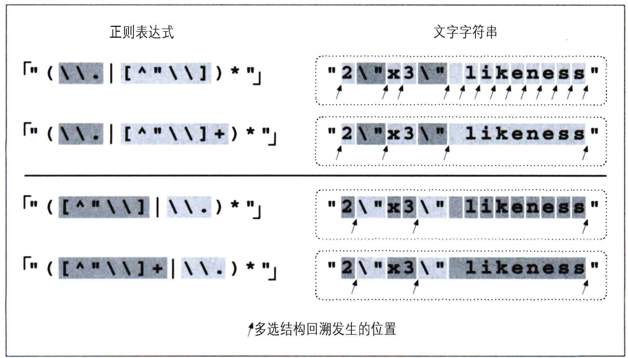
图6-2:添加加号的结果(传统型NFA)
新增的加号大大减少了多选结构回溯的次数,以及星号的迭代次数。星号量词作用于括号内的子表达式,每次迭代都需要进入然后再退出括号,这都需要成本,因为引擎需要记录括号内的子表达式匹配的文本(本章会深入探讨此问题)。
表6-1与第224页答案中的表格类似,不过表达式不同,另外还给出了星号的迭代次数。在每种情况下,独立测试次数和回溯次数的增加都很有限,但是迭代次数有了显著降低,这是很大的进步。
表6-1:传统型NFA的匹配效率
实测
Reality Check
是的,我对自己的发现颇为得意。但这个看起来很奇妙的“改动”不过是场还未爆发的灾难。你可能注意到了,在考察它的各项指标时,我没有给出POSIX NFA的统计数据。如果这样做,你可能会很惊奇地发现"  "的匹配需要超过 3 亿亿亿次(实际上是324 518 553 658 426 726 783 156 020 576 256)回溯。说简单点就是,回溯是个天文数字。这需要超过50百亿亿(quintillion)年,或者是若干千万亿个千年(注1)。
"的匹配需要超过 3 亿亿亿次(实际上是324 518 553 658 426 726 783 156 020 576 256)回溯。说简单点就是,回溯是个天文数字。这需要超过50百亿亿(quintillion)年,或者是若干千万亿个千年(注1)。
确实很出乎意料!那么,为什么会发生这种情况呢?简单地说,原因在于——这个正则表达式中某个元素受加号限定的同时,还受括号外的星号限定,无法区分哪个量词控制哪个特殊的字符。这种不确定性就是症结。下一节给出了详细解释。
“指数级”匹配
没有添加星号时,「[^\\"]」是星号的约束对象,真正的「([^\\"])*」能够匹配的字符是有限的。它先匹配一个字符,然后匹配下一个字符,如此继续,最多就是匹配目标文本中的每个字符。它也可能无法匹配目标字符串中的所有字符,不过,充其量,匹配字符的个数与目标字符串的长度成线性关系。目标字符串越长,可能的工作量相对也越大。
但是,对正则表达式的「([^\\"]+)*」来说,加号和星号二者分割(pvy up)字符串的可能性是成指数形式增长的。如果目标字符串是 makudonarudo,是星号会迭代12次,每一次迭代中「[^\\"]+」匹配一个字符(就像这样 )?还是星号迭代3次,内部的「[^\\"]+」分别匹配 5、3、4 个字符(
)?还是星号迭代3次,内部的「[^\\"]+」分别匹配 5、3、4 个字符( ’)?或者 2、2、5、3 个字符(‘
’)?或者 2、2、5、3 个字符(‘ ’)?还是其他……
’)?还是其他……
你现在知道,存在许多种可能(对长度为12的字符串存在4 096种可能)。字符串中的每个字符,都存在两种可能,POSIX NFA在给出结果之前必须尝试所有可能。这就是“指数级匹配”的来历。我还听说过一个不错的名字:“超线性(super-linear)”。
无论叫什么名字,终归都是回溯,大量的回溯(注2)!12个字符需要4 096种可能,这可能不需要多久时间,不过20个字符需要超过一百万种可能,时间长达若干秒。30个字符,就需要超过十亿种可能,长达若干小时,如果是40个字符,就需要一年多的时间。这显然不是什么好事情。
你可能会想,“没关系,POSIX NFA 并不常见。我知道我的工具用的是传统型NFA,所以这问题对我不存在。”的确,POSIX NFA和传统型NFA的主要差别在于,传统型NFA在遇到第一个完整匹配可能时会停止。如果没有完整匹配,即使是传统型NFA也需要尝试所有的可能,在找到之前。即使是前面提到的"No·"match"·here这样短短的字符串,在报告失败之前,也需要尝试8 192种可能。
在正则引擎忙于尝试这些数量庞大的可能时,整个程序看起来好像“锁死(lock up)”了。我第一次遇到这种情况时,以为自己发现了程序的bug,不过现在我理解了,现在我把这个正则表达式加入自己的正则表达式工具包里,用来测试引擎的类型。
●如果其中的某个表达式,即使不能匹配,也能很快给出结果,那可能就是DFA。
●如果只有在能够匹配时才很快出结果,那就是传统型NFA。
●如果总是很慢,那就是POSIX NFA。
第一个判断中我使用了“可能”这个单词,因为经过高级优化的NFA没准能检测并且避免这些指数级的无休止(neverending)匹配(详见本章后文☞250)。同样,我们会见到各种方法来改进或重写这些表达式,加快它们匹配或报错的速度。
前面列出的几点表明,如果排除某些高级优化的影响,就能根据正则表达式的相对性能判断引擎的类型。这就是第4章中(☞146)我们能用某些正则表达式来“测试引擎的类型”的原因。
当然,不是每点改动都会带来像本例一样的灾难性后果,不过除非知道正则表达式的幕后原理,否则在实际运行之前永远不能判断后果。为此,本章考察了各种例子的效率和后果。不过,对许多事来说,牢固理解基本概念对深入学习是非常重要的;所以,在讲解指数级匹配之前,我们不妨仔细复习复习回溯。