Benchmarking
本章主要讲解速度和效率,而且会时常使用性能测试,所以我希望介绍一些测试的原则。我会用几种语言来介绍简单的测试方法。
基本的性能测试就是记录程序运行的时间:先取系统时间,运行程序,再取系统时间,计算两者的差,就是程序运行的时间。举个例子,比较「^(a|b|c|d|e|f|g)+$」和「^[a-g]+$」。先来看Perl的表现,然后再来看其他语言。下面是简单的Perl程序(不过,我们将会看到,这个例子有欠缺):

它看来(而且也确实是)很简单,但是在进行性能测试时,我们需要记住几点:
●只记录“真正关心的(interesting)”处理时间。尽可能准确地记录“处理”时间,尽可能避免“非处理时间”的影响。如果在开始前必须进行初始化或其他准备工作,请在它们完成之后开始计时;如果需要收尾工作,请在计时停止之后进行这些工作。
●进行“足够多”的处理。通常,测试需要的时间是相当短暂的,而计算机时钟的单位精度不够,无法给出有意义的数值。
在我的机器上运行这个Perl程序,结果是:
Alternation takes 0.000 seconds.
Character class takes 0.000 seconds.
我们只能知道,这段程序所需的时间比计算机能够测量的最短时间还要短。所以,如果程序运行的时间太短,就运行两次、十次,甚至一千万次,来保证“足够多”的工作。这里的“足够多”取决于系统时钟的精度,大多数系统能够精确到1/100s,这样,即使程序只需要0.5s,也能取得有意义的结果。
●进行“准确的”处理。进行1 000万次快速操作需要在负责计时的代码块中升级1 000万次计数器。如果可能,最好的办法是增加真正的处理部分的比例,而不增加额外的开销。在Perl的例子中,正则表达式应用的文本相当短:如果应用到长得多的字符串,在每次循环中所作的“真正的”处理也会多一些。
考虑到这些因素,我们可以得出下面的程序:

请注意,$TestString和$Count的初始化在计时开始之前($TestString使用了Perl提供的 x 操作符进行初始化,它表示将左边的字符串重复右边的次数)。在我的机器上,使用Perl5.8运行的结果是:
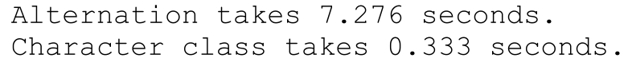
所以,对这个例子来说,多选结构要比字符组快22倍左右。此测试应该执行多次,选取最短的时间,以减少后台系统活动的影响。
理解测量对象
Know What You\'re Measuring
我们把初始化程序更改为下面这样,会得到更有意思的结果:
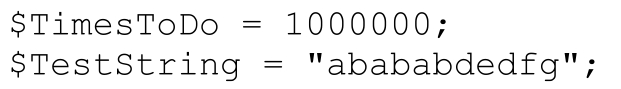
现在,测试字符串只是上面的长度的1/1 000,而测试需要进行1 000次。每个正则表达式测试和匹配的字符总数并没有变化,因此从理论上讲,“工作量”应该没有变化。不过,结果却大不相同:

两个时间都比之前的要长。原因是新增的“非处理”开销——对$Count的检测和更新,以及建立正则引擎的时间,现在的次数是以前的1 000倍。
对于字符组测试来说,新增的开销花费了大约5s的时间,而多选结构则增加了将近10秒。为什么多选结构测试的时间变化如此之大?主要是因为捕获型括号(在每次测试之前和之后,它们都需要额外处理,这样的操作要多1 000倍)。
无论如何,进行这点修改的要点在于说明,真正处理部分和非真正处理部分在计时中所占的比重会强烈地影响到测试结果。
PHP测试
Benchmarking with PHP
下面是PHP的测试,使用preg引擎:

在我的机器上,结果是:

如果在测试中遇到PHP错误“not being safe to rely on the system\'s timezone settings”,请添加下面的代码:
Java测试
Benchmarking with Java
因为某些原因,用Java测试很有讲究。首先看个考虑不够周到的例子,然后请思考它为什么考虑不周到,应该如何改进:

你注意到在这个程序中正则表达式如何初始化部分编译了吗?我们需要测试的是匹配的速度,而不是编译的速度。
速度取决于所使用的虚拟机(VM)。Sun的标准JRE有两种虚拟机,client VM为快速启动而优化,server VM为长时间、大负荷的作业而优化。
在我的机器上,使用client VM运行测试的结果如下:

使用server VM的结果如下:

这样看来测试有点不可信了,之所以说它不够周到,原因在于计时的结果在很大程度上取决于自动的预执行编译器(automatic pre-execution compiler)的工作,或者说运行时编译器(run-time compiler)与测试代码的交互情况。某些虚拟机包含JIT(Just-In-Time compiler),JIT会根据需要,在需要执行代码之前才进行编译。
Java使用了我称为BLTN(Better-Late-Than-Never)的编译器,在执行期间计数,对反复使用的代码根据需要进行编译和优化。BLTN的性质是,它只对认为“热门”(hot,即大量使用)的代码进行干预。如果虚拟机已经运行了一段时间,例如在服务器环境中,它已经“预热”完毕,而我们的简单例子确保了一台“凉”的服务器(BLTN没有进行任何优化)。
可以把测试部分放入一个循环,来观察“预热”现象:
//第一轮测试计时...

如果新增的循环运行足够长(例如,10s),BLTN就会优化热门代码,最后一次输出的时间就代表了已预热系统的情况。再次使用server VM,这些时间确实比之前有了8%和25%的提高。
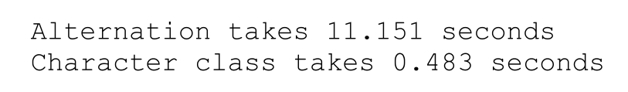
另一个问题在于,负责调度GC线程的工作是不确定的。所以,进行足够长时间的测试能够降低这些不确定因素的影响。
VB.NET测试
Benchmarking with VB.NET
下面是VB.NET的测试程序:
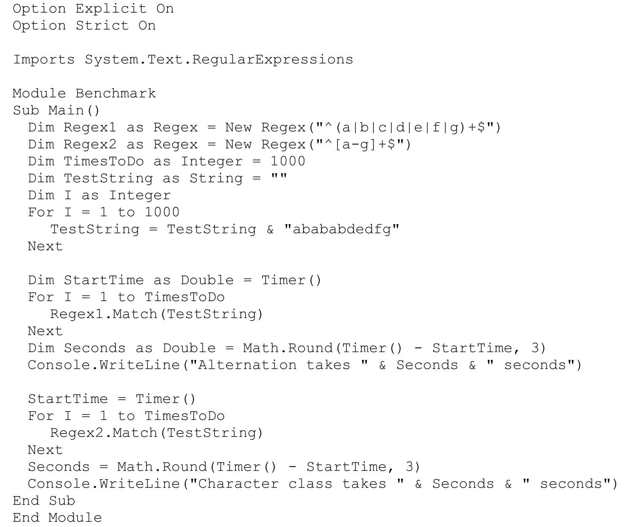
在我的机器上,结果是:

在.NET Framework中使用RegexOptions.Compiled作为正则表达式构造函数的第2个参数,能够把正则表达式编译为效率更高的形式(☞410),其结果为:

使用Compiled功能之后,两个测试的速度都有提高,但是多选结构的相对上升幅度更为明显(几乎是之前的3倍,而字符组的程序只提高到之前的1.5倍),所以多选结构从中获益更大。
Ruby测试
Benchmarking with Ruby
下面是Ruby的测试代码:

在我的机器上,结果如下:
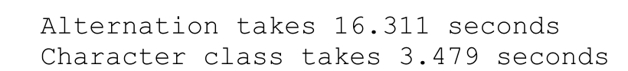
Python测试
Benchmarking with Python
下面是Python的测试代码:

因为Python的正则引擎设定的限制,我们必须减少字符串的长度,因为原来长度的字符串会导致内部错误(“maximum recursion limit exceeded”)。这种规定有点像减压阀,它有助于终止无休止匹配。
作为弥补,我相应增加了测试的次数。在我的机器上,测试结果为:

Tcl测试
Benchmarking with Tcl
下面是Tcl的测试代码:

在我的机器上,结果如下:

神奇的是,两者速度相当。还记得吗,我们在第145页说过,Tcl使用的是NFA/DFA混合引擎,对DFA引擎来说,这两个表达式是没有区别的。本章所举的大部分例子并不适用于Tcl,详细信息请参考第243页。