The Freeflowing Regex
我们花了不少时间来构建匹配 C 的注释的正则表达式,但是没有考虑如何避免字符串中的错误匹配。使用Perl的话,你可能会想到用下面的程序过滤注释:
$prog=~s{/*[^*]**+(?:[^/*][^*]**+)*/}{}g;#去掉C语言注释(但有错误!)
表达式中,变量$prog保存的文本会被删除(也就是,被空文本替换掉)。问题在于,如果在字符串内部找到注释的起始标记,正则表达式的匹配也不会停止,比如这段C代码:
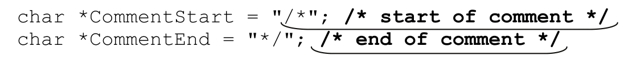
这里,下画线标注的部分是正则表达式的匹配结果,但是粗体标注的部分才是我们期望的。引擎寻找匹配时会在目标字符串的每个位置开始尝试匹配表达式。因为这种尝试只有在注释开始的地方(或者是看起来有可能开始的地方)成功,所以在大部分位置都无法匹配,传动装置的驱动过程继续向前,进入双引号字符串,其内容似乎是注释的开始。最好是能够告诉正则引擎,遇见双引号字符串时是应该尝试匹配还是直接跳过。当然,我们确实能做到这一点。
引导匹配的工具
A Helping Hand to Guide the Match
看下面的程序:
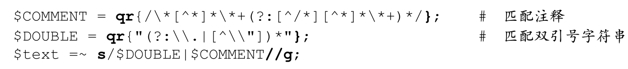
这里出现了两件新事物。其中之一是表达式「$DOUBLE|$COMMENT」,它由两个变量组成,都使用了Perl特有的qr/…/正则表达式“双引号字符串”操作符。我们曾在第3章仔细讨论过(☞101),如果用字符串表示正则表达式,使用字符串的时候必须格外小心。Perl提供的qr/…/运算符解决了这个问题,它会把操作对象(operand)视为正则表达式,但不会实际应用它。我们在第2章(☞76)已经看到,这样非常方便。与m/…/和s/…/…/一样,我们可以自己选择分隔符(☞71),上面使用的是花括号。
另一点是通过用$DOUBLE来匹配双引号字符串。传动装置驱动到$DOUBLE能匹配的位置时,会一次性匹配整个双引号字符串。这里使用多选分支完全没有问题,因为二者之间并没有重叠。如果我们从左向右扫描这个正则表达式就会发现,应用到字符串时,存在三种可能:
●注释部分能够匹配,于是一次性匹配注释部分,直接到达注释的末尾,或者…
●双引号字符串部分能够匹配,于是一次性匹配双引号字符串,直接到达其结尾,或者…
●上面两者都不能匹配,本轮尝试失败。启动驱动过程,跳过一个字符。
这样,正则表达式永远不会从双引号字符串或者注释内部开始尝试,这就是成功的关键。实际上,到目前为止还不够,因为这个表达式在删除注释的同时也会删除双引号字符串,不过我们只需要再修改一小点就可以了。
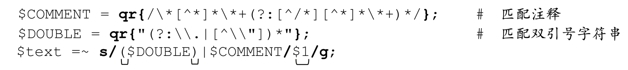
唯一的区别在于:
●设置了捕获型括号,如果能够匹配双引号字符串对应的多选分支,则$1会保存对应的内容。如果匹配通过注释多选分支,$1为空。
●把replacement的值设置为$1。结果就是,如果双引号字符串匹配了,replacement就等于双引号字符串——并没有发生删除操作,替换不会进行任何修改(不过存在伴随效应,即一次性匹配这个双引号字符串,直接到达其结尾,这就是把它放在多选结构首位的原因)。另一方面,如果匹配注释的多选分支能够匹配,$1 为空,所以会按照期望删除注释(注8)。
最后我们还必须小心对付单引号的C常量,例如\'t\'。这很容易——只需要在括号内添加另外一个多选分支。如果我们希望去掉 C++、Java、C#的//的注释,就可以把「//[^n]*」作为第四个多选分支,列在括号外。
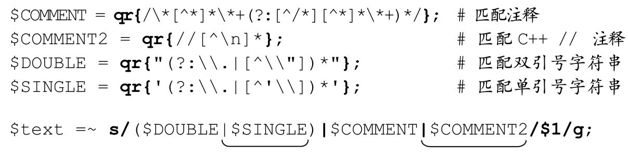
基本原理很好懂:引擎检查文本,迅速捕获(如果合适,则是删除)这些特殊结果。在我的老机器(配置大概停留在1997年的水平)上,Perl脚本在16.4秒的时间内去掉了16MB,500 000行的测试文件中的注释。这已经很快了,不过我们仍然需要提高速度。
引导良好的正则表达式速度很快
A Well-Guided Regex is a Fast Regex
暂停一会儿,我们能够直接控制这个正则引擎的运转,进一步提高匹配速度。来考虑注释和字符串之间的普通 C 代码。在每个位置,正则引擎都必须尝试四个多选分支,才能确认是否能匹配,只有四个多选分支都匹配失败,它才会前进到下一个位置,这些复杂工作其实是不必要的。
我们知道,如果其中任何一个多选分支有机会匹配,开头的字符都必须是斜线、单引号或是双引号。这些字符并不能保证能够匹配,但是不满足这些条件绝对不能匹配。所以,与其让引擎缓慢而痛苦地认识到这一点,不如把「[^\'"/]」作为多选分支,直接告诉引擎。实际上,同一行中任何数量的此类字符都能归为一个单元,所以我们使用「[^\'"/]+」。如果你记得无休止匹配,可能会为添加的加号担心。确实,如果在某种(…)*循环中,它可能是很大的问题,但是在这个例子中,它完全没有问题(之后没有元素强迫它回溯),所以,添加:

出于某些我们即将要看到的原因,我把加号量词放在$OTHER之后,而不是$OTHER的内容之中。
我重新进行了性能测试,出乎意料的是,这样可以减少 75%的时间。通过改进,这个表达式节省了频繁尝试所有多选分支的大部分时间。仍然有些情况,所有多选分支都不能匹配(例如‘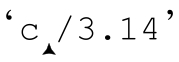 ’),此时,我们只能接受驱动过程。
’),此时,我们只能接受驱动过程。
不过,事情还没有结束,我们仍然可以让表达式更快:
●在大多数情况下,最常用的多选分支可能是「$OTHER+」,所以我们把它排在第一位。POSIX NFA没有这个问题,因为它总会检查所有的多选分支,但是对于传统型NFA,它只要找到匹配就会停止,为什么不把最可能出现的多选分支放在第一位呢?
●一个引用字符串匹配之后,在其他字符串和注释匹配之前,很可能出现的就是$OTHER的匹配。若在每个元素之后都添加「$OTHER*」,就能够告诉引擎下面必须匹配$OTHER,而不用马上进入下一轮/g循环。
这与消除循环的技巧是很相似的,此技巧之所以能提高速度,是因为它主导了正则引擎的匹配。这里我们使用了关于全局匹配的知识来进行局部优化,给引擎提供快速运转必须的条件。
非常重要是,「$OTHER*」是加在每个匹配引用字符串的子表达式之后的,而之前的$OTHER(排在多选结构最前面的)必须用加号量词。如果你不清楚原因,请考虑下面的情况:添加的是$OTHER+,而某行中有两个连在一起的双引号字符串。同样,如果开头的$OTHER使用星号量词,则任何情况都能匹配。
最终得到:
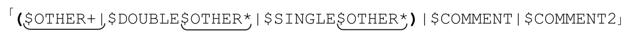
这个表达式能把时间再减少5%。
回过头来想想最后两个改动。如果每个添加的$OTHER*匹配了过多的内容,开头的$OTHER+(我们将其作为第一个多选分支)只有两种情况下能够匹配:1)它匹配的文本在整个s/…/…/g的开头,此时还轮不到引用字符串的匹配;2)在任意一段注释之后。
你可能会想“从第二点考虑,我们不妨在注释后添加$OTHER+”。这很不错,只是我们希望用第一对括号内的表达式匹配所有希望保留的文本——不要把孩子连洗澡水一起倒掉。
那么,如果$OTHER+出现在注释之后,我们是否需要把它放在开头呢?我觉得,这取决于所应用的数据——如果注释比引用字符串更多,答案就是肯定的,把它放在第一位有意义。否则,我就会把它放后面。从测试数据来看,把它放在前面的效果更好。排在后面大约会损失最后的修改一半的效率。
完工
Wrapup
事情还没有结束。不要忘记,每个匹配引号字符串的子表达式都应该消除循环,本章已经花了很长的篇幅讲解这个问题。所以,最后我们要把这两个子表达式替换为:
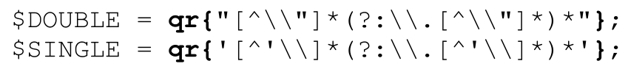
这样修改节省了15%的时间。这些细小的修改把匹配的时间从16.4秒缩短到2.3秒,提升了7倍。
最后的修改还说明,用变量来构建正则表达式多么方便。$DOUBLE 可以作为单独的元素独立出来,可以改变,而不需要修改整个正则表达式。虽然还会存在一些整体性问题(包括捕获文本括号的计数),但这个技巧确实很方便。
这种便利是由 Perl 的 qr/…/操作符提供的,它表示与正则表达式相关的“字符串”。其他语言没有提供相同的功能,但是大多数语言提供了便于构建正则表达式的字符串。请参见101页的“作为正则表达式的字符串”。
下面是原始的正则表达式,看到它,你肯定会觉得上面的办法非常方便。为了便于印刷,我把它分为两行:
([^"\'/]+|"[^\\"]*(?:\\.[^\\"]*)*"[^"\'/]*|\'[^\'\\]*
(?:\\.[^\'\\]*)*\'[^"\'/]*)|/*[^*]**+(?:[^/*][^*]**+)*/|//[^n]*