The Match Operator
基本的匹配操作:
$text=~m/regex/
是Perl的正则表达式应用的核心。在Perl中,正则表达式匹配操作需要两个运算元,其一是目标字符串,其二是正则表达式,返回一个值。
匹配如何进行,返回什么值,取决于匹配的应用场合(☞294)及其他因素。match 运算符非常方便——它可以用来测试某个正则表达式能否匹配一个字符串,或者从字符串中提取数据,甚至是与其他匹配运算符一起将字符串拆分为各个部分。虽然功能强大,这种便捷也增加了掌握的难度。需要关注的内容包括:
●如何指定正则运算元。
●如何指定匹配修饰符,以及它们的意义。
●如何指定目标字符串。
●匹配的伴随效应。
●匹配的返回值。
●能影响匹配的外部因素。
匹配的常见形式是:
StringOperand=~RegexOperand
还有许多简便方式,值得注意的是,某些简便形式下,两个运算元都不是必须出现的。本节中我们会看到各种形式的例子。
Match的正则运算元
Match's Regex Operand
正则运算元可以是正则文字或者regex对象(其实可以是字符串或者任意的表达式,但是这样做没什么好处)。如果使用正则文字,可以指定修饰符。
使用正则文字
正则运算元通常是m/…/或者就是/…/内的正则文字。如果正则文字的分隔符是斜线或问号(以问号做分隔符的情况很特殊,稍后讨论)则可以省略开头的m。为保持一致,我不管是否必要都使用m。之前介绍过,如果使用m,你可以使用自己的分隔符(☞291)。
使用正则文字时,可以结合第 292 页介绍的任何核心修饰符。匹配运算符还支持两个另外的运算符,/c和/g,下面马上介绍。
使用regex对象
正则运算元也可以是qr/…/生成的regex对象,例如:
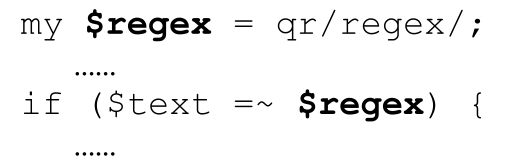
可以在m/…/中使用regex对象。特殊的情况是,如果“正则文字”中只包含一个regex对象的插值,那么它就完全等同于使用此regex对象。上面这个例子也可以写作:
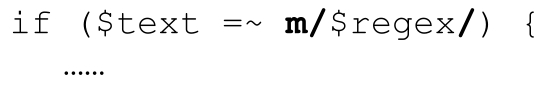
这很方便,因为它看起来更熟悉,也容许我们对regex对象使用/g修饰符(还可以使用m/…/支持的其他的修饰符,但这在本例中没有意义,因为它们不能覆盖regex对象内锁定的模式修饰符☞304)。
默认的正则表达式
如果没有指定正则表达式,例如m//(或者m/$SomeVar/而变量$SomeVar为空字符串或未定义),则Perl会使用此代码所在的动态作用域范围内最近应用成功的正则表达式。以前这样很有用,因为可以提高效率,后来因为regex对象的发展(☞303),已经没什么意义了。
?…?的特殊匹配
除了之前介绍的正则文字的各种分隔符,match运算符还可以使用一种特殊的分隔符——问号。问号分隔符(例如 m?…?)提供的是相当生僻的功能,m?…?匹配成功之后,除非在同样的package中调用reset函数,否则不会再次匹配。按照Perl Version 1的手册上的说法,这“是有用的优化措施,用于在一组文件中查找某段信息的第一次出现”,但是不知何故,我在现代Perl中从未见过。
问号分隔符的特殊情况类似斜线分隔符,m也不是必须出现的:?…?完全等价于m?…?。
指定目标运算元
Specifying the Match Target Operand
常用来指定“搜索字符串”的做法是=~,例如$text=~m/…/。请记住,=~既不是赋值运算符,也不是比较运算符,只是一个看来有趣的运算符,用来连接运算元(这个表示法改编自awk)。
因为整个“expr=~m/…/”本身就是一个表达式,我们可以在任何容许出现表达式的地方使用,例如(以连线分隔):

默认的目标字符串
如果目标字符串是变量$_,则可以省略整个“$_=~”。也就是说,默认的目标字符串就是$_。
$text=~m/regex/;
的意思是,“把regex应用到$text中的文本,忽略返回值,获取伴随效应”。如果忘了写‘~’,结果就是:
$text=m/regex/;
它的意思是“对$_中的文本应用正则表达式,获取伴随效应,把返回的 true/false 值赋给$text”。也就是说,下面两者是等价的:
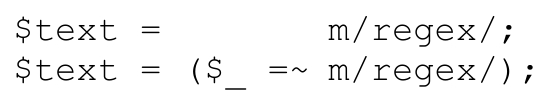
有时候使用默认目标字符串很方便,尤其是与其他默认情况的结构(许多结构都有默认值)结合时。下面的代码就很常见:

总的来说,依赖默认运算元会增加无经验程序员阅读代码的难度。
颠倒match的意义
可以用!~来取代=~,对返回值进行逻辑非操作(马上会介绍这么做的返回值和伴随效应,但是对于!~,返回值就是true或者false),下面三种办法是等价的:

从我个人出发,我喜欢中间的办法。无论选用哪种办法,都会产生设置$1等的伴随效应。!~只是判断“如果不能匹配”的简便方式。
Match运算符的不同用途
Different Uses of the Match Operator
可以从match运算符返回的true/false判断匹配是否成功,也可以从成功匹配中获取其他的信息,与其他match运算符结合起来。match运算符的行为主要取决于它的应用场合(☞294),以及是否使用了/g修饰符。
普通的“匹配与否”——scalar context,不使用/g
在scalar context中(例如if测试),match运算符返回的就是true/false:

也可以把结果赋值给一个scalar变量,然后检查

普通的“从字符串中提取数据”——list context,不使用/g
不使用/g的list context,是字符串中提取数据的常用做法。返回值是一个list,每个元素是正则表达式中捕获型括号内的表达式捕获的内容。下面这个简单的例子用来从 69/8/31中提取日期:
my ($year,$month,$day)=$date=~m{^(\d+)/(\d+)/(\d+) $}x;匹配的3个数作为3个变量(当然还包括$1、$2和$3等)。每一组捕获型括号都对应到返回序列中的一个元素,空序列表示匹配失败。
有时候,某组捕获括号没有参与最终的成功匹配。例如,m/(this)|(that)/必然有一组括号不会参与匹配。这样的括号返回未定义的值 undef。如果匹配成功,又没有使用捕获型括号,在不使用/g的list context中,会返回list(1)。
List context可以以各种方式指定,包括把结果赋值给一个数组,例如:
my@parts=$text=~m/^(\d+)-(\d+)-(\d+)$/;
如果match的接收参数是scalar变量,请将匹配的应用场合指定为list context,这样才能获得匹配的某些捕获内容,而不是表示匹配成功与否的Boolean值。比较这两个测试:
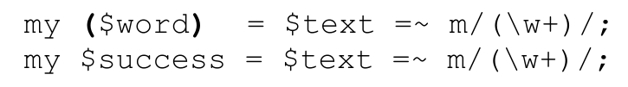
第一个例子中,变量外的括号导致my函数为赋值指定list context。第二个例子没有括号,所以应用场合为scalar context,$success只得到true/false值。
下面给出了一个更简单的做法:

这次匹配发生在list context中(由“my (…)=”提供),所以序列中的变量会根据对应的$1、$2之类进行赋值。不过,匹配完成之后,因为整个组合是在if条件语句的scalar context中,Perl把list转换为一个scalar变量。它接收的是list的长度,如果匹配不成功,长度为0,如果不为0,则表示匹配成功。
“提取所有匹配”——list context,使用/g
此结构的用处在于,它返回一个文本序列,每个元素对应捕获型括号匹配的文本(如果没有捕获型括号,就返回整个表达式匹配的文本),但上一节的例子只能针对一次匹配,而这种结构针对所有匹配。
下面这个简单的例子用来提取字符串中的所有整数:
my@nums=$text=~m/\d+/g;
如果$text包含IP地址‘64.156.215.240’,@num会接收4个元素,‘64’、‘156’、‘215’、‘240’。与其他结构相结合,就能很方便地把 IP 地址转换为 8 位 16 进制数字,例如‘409cd7f0’,如果需要创建紧凑的log文件,这很方便:
my $hex_ip=join'',map {sprintf("%02x",$_)} $ip=~m/\d+/g;
下面的代码可以把它转换回来:
my $ip=join'.',map {hex($_)} $hex_ip=~m/../g
另一个例子是匹配一行中的所有浮点数:
my@nums=$text=~m/\d+(?:\.\d+)?|\.\d+/g;
一定要使用非捕获型括号,因为捕获型括号会改变返回的结果。下面的例子说明了捕获型括号的价值:
my@Tags=$Html=~m/<(\w+)/g;
@Tags会保存$Html中依次出现的各个tag,这里假设每一个‘<’都有对应的‘>’。
下面的例子使用了多个捕获型括号:把Unix中邮箱联系人的alias文件的内容存放在一个字符串中,数据格式是:

为了提取每一行中的昵称(alias)和完整地址,我们可以使用m/^alias\s+(\S+)\s+(.+)/m (不使用/g)。在list context中,返回的序列包括两个元素,例如('Jeff','[email protected]')。现在用/g匹配所有这样的组合,得到的序列是:
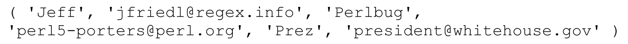
如果这个序列恰好符合key/value的形式,我们可以直接把它存入一个关联数组(associative array)。
my%alias=$text=~m/^alias\s+(\S+)\s+(.+)/mg;
返回之后,可以用$alias{Jeff}访问'Jeff'的完整地址。
迭代匹配:Scalar Context,使用/g
Iterative Matching:Scalar Context,with/g
scalar context中,m/…/g是个特殊的结构。和正常的m/…/一样,它只进行一次匹配,但是和list context中的m/…/g一样,它会检查之前匹配的发生位置。每次在scalar context中使用 m/…/g——例如在循环中,它会寻找“下一个”匹配。如果失败,就会重置“当前位置(current position)”,于是下一次应用从字符串的开头开始。
这里有个简单的例子:

有两次匹配是在scalar context中使用/g进行的,结果为:

后两次匹配配合起来,前者把“当前位置”设置到匹配的小写字母单词之后,第二个读取这个位置,在后面寻找大写字母单词。对两个匹配来说,/g都是必须的,这样匹配才能注意到“当前位置”,所以如果任何一个没有使用/g,第二行会指向‘WOW’。
scalar context 中的/g匹配非常适合用作while循环的条件:

最终会找到所有的匹配,但是 while的循环体是在匹配之间(或者说,在每次匹配之后)执行。一旦某次匹配失败,结果就是false,然后while循环结束。同样,一旦失败,/g状态会重置,也就是循环结束之后的/g匹配会从字符串的开头开始。
比较:
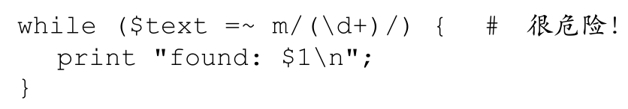
和

唯一的区别是/g,但是这区别不可小视。如果$text包含之前那个IP地址,第二个程序输出我们期望的结果:

相反,第一个程序不断地打印“found:64”,不会终止。不使用/g,就意味着“找到$text中第一个「(\d+)」”,也就是‘64’,无论匹配多少次都是如此。添加/g之后,它变成了“找到$text中的下一个「(\d+)」”,依次找到各个数字。
“当前匹配位置”和pos()函数
Perl中每个字符串都有对应的“当前匹配位置(current match position)”,传动装置会从这里开始第一次匹配的尝试。这是字符串的属性之一,而与正则表达式无关。在字符串创建或者修改时,“当前匹配位置”会指向字符串的开头,但是如果/g匹配成功,它就会指向本次匹配的结束位置。下一次对字符串应用/g匹配时,匹配会从同样的“当前匹配位置”开始。可以通过pos(…)函数得到目标字符串的“当前匹配位置”,例如:

结果是:

(记住,字符串的下标是从0开始的,所以“location 2”就是第3个字符之前的位置)。在/g匹配成功之后,$+[0](@+的第一个元素☞302)就等于目标字符串中的pos。
pos()函数的默认参数是match运算符的默认参数:变量$_。
预设定字符串的pos
pos()的真正能力在于,我们可以通过它来指定正则引擎从什么位置开始匹配(当然是针对/g的下一次匹配)。我在Yahoo!的时候,要处理的Web服务器log文件的格式是,包含32字节的定长数据,然后是请求的页面,然后是其他信息。提取请求页面的办法是「^.{32}」,跳过开头的定长数据:
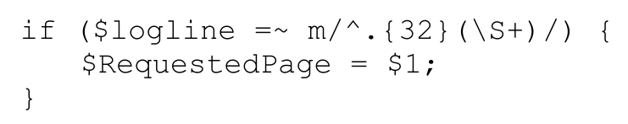
这种硬办法不够美观,而且要强迫正则引擎处理前32个字节。如果我们亲自动手,代码会好看得多,效率也高得多:

这个程序好些,但还不够好。这个正则表达式从我们规定的位置开始,而在此之前不需要匹配,这一点与上个程序不同。如果因为某些原因,第32个字符不能由「\S」匹配,前面那个程序就会匹配失败,但是新程序因为没有锚定到字符串的特殊位置,会由传动装置启动驱动过程。也就是说,它会错误地返回一个「\S+」在字符串后面部分的匹配。幸好,在下一节我们会看到,这个问题很容易修复。
使用\G
元字符\G的意思是“锚定到上一次匹配结束位置”。这正是上一节中我们希望解决的问题。

\G告诉传动装置,“不要启动驱动过程,如果在此处匹配不能成功,就报告失败”。
前面几章曾经介绍过「\G」:第3章有简单介绍(☞130),更复杂的例子在第5章(☞212)。
请注意,在Perl中,只有「\G」出现在正则表达式开头,而且没有全局性多选结构的情况下,结果才是可预测的。第 6 章的优化 CSV 解析程序的例子中(☞271),正则表达式以「\G(?:^|,)…」开头。如果更严格的「^」能够匹配,就没必要检查「\G」,所以你可能会把它改为「(?:^|\G,)…」。不幸的是,在Perl中这样行不通;其结果不可预测(注7)。
使用/gc进行“Tag-team”匹配
正常情况下,m/…/g匹配失败会把目标字符串的pos重置到字符串的开头,但给/g添加/c之后会造成一种特殊的效果:匹配失败不会重置目标字符串的 pos(/c离不开/g,所以我一般使用/gc)。
m/…/gc最常见的用法是与「\G」一起,创建“词法分析器”,把字符串解析为各个记号(token)。下例简要说明了如何解析$html中的HTML代码:

每个正则表达式的粗体部分匹配一种类型的HTML结构。从当前位置开始,依次检查每一个正则表达式(使用/gc),但是只能在当前位置尝试匹配(因为使用了「\G」)。按照顺序依次检查各个正则表达式,直到找到能够匹配的结构为止,然后报告。之后把$html 的 pos指向下一个记号的开始,进入下一轮循环的搜索。
循环终止的条件是m/\G\z/gc能够匹配,即当前位置(「\G」)指向字符串的末尾(「\z」)。
有一点要注意,每轮循环必须有一个匹配。否则(而且我们不希望退出)就会进入无穷循环,因为$html的 pos既不会变化也不会重置。对现在的程序来说,最终的else分支永远不会调用,但是如果我们希望修改这个程序(马上就会这么做),或许会引入错误,所以else分支是有必要保留的。对目前这个程序来说,如果接收预料之外的数据(例如‘<>’),会在每次遇到预料之外的字符时,就发出一条警报。
另一点需要注意的是各表达式的检查顺序,例如把「\G(.)」作为最后的检查。也可以来看下面这个识别<script>代码的例子:
$html=~m/\G (<script[^>]*>.*?</script>)/xgcsi
哇,这里使用了 5 个修饰符!为了正常运行,我们必须把它放在对字符串进行第一次「<[^>]+>」的匹配之前。否则「<[^>]+>」会匹配开头的<script>标签,这个表达式就没法运行了。
第3章还介绍了关于/gc的更高级的例子(☞132)。
Pos相关问题总结
下面是match运算符与目标字符串的pos之间互相作用的总结:

同样,只要修改了字符串,pos就会重置为undef(也就是初始值,指向字符串的起始位置)。
Match运算符与环境的关系
The Match Operator's Environmental Relations
下面几节将总结我们已经见到的,match运算符与Perl环境之间的互相影响。
match运算符的伴随效应
通常,成功匹配的伴随效应比返回值更重要。事实上,在void context中使用match运算符(这样甚至不必检查返回值),只是为了获取伴随效应(这种情况类似scalar context)。下面总结了成功匹配的伴随效应:
●匹配之后会设置$1和@+之类变量,供当前语法块内其他代码使用(☞299)。
●设置默认正则表达式,供当前语法块内其他代码使用(☞308)。
●如果m?…?能够匹配,它(也就是m?…?运算符)会被标记为无法继续匹配,至少在同样的package中,不调用reset就无法继续匹配(☞308)。
当然,这些伴随效应只能在匹配成功时发生,不成功的匹配不会影响它们。相反,下面的伴随效应在任何匹配中都会发生:
●目标字符串的pos会指定或者重置(☞313)。
●如果使用了/o,正则表达式会与这个运算符“融为一体(fuse)”,不会重新求值(evaluate,☞352)。
match运算符的外部影响
match运算符的行为会受到运算元和修饰符的影响。下面总结了影响match运算符的外部因素:
应用场合context
match运算符的应用场合(scalar、list,或者void)对匹配的进行、返回值和伴随效应有重要影响。
pos(…)
目标字符串的pos(由前一次匹配显式或隐式设定)表示下一次/g匹配应该开始的位置,同时也是「\G」匹配的位置。
默认表达式
如果提供的正则表达式为空,就使用默认的表达式(☞308)。
study
对匹配的内容或返回值没有任何影响,但如果对目标字符串调用此函数,匹配所花的时间更少(也可能更多)。参考“Study函数”(☞359)。
m?…?和reset
m?…?运算符有一个看不见的“已/未匹配”状态,在使用 m?…?匹配或者 reset 时设定(☞308)。
在context中思考(不要忘记context)
在match运算符讲解结束之前,我要提几个问题。尤其是,在while、if和foreach控制结构中发生变化时,确实需要保持头脑清醒。请问,运行下面的程序会得到什么结果?

这有点儿难度,ϖ 请翻到下页查看答案。