Java's Regex Flavor
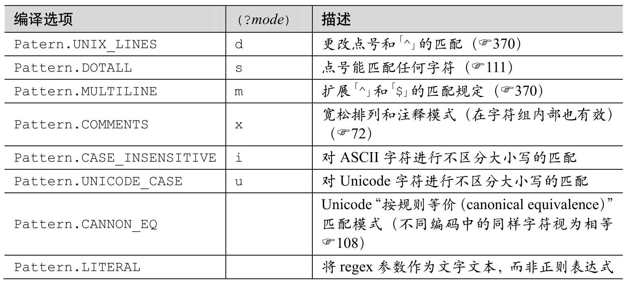
java.util.regex使用传统型NFA,所以第4、5、6章介绍的丰富特性都适用于它。下页的表8-2总结了它的元字符。此流派的某些方面已经发生了变化,原因是各种匹配模式,匹配模式的启用通过各种 method 和 factory 来设定标志位,或者内嵌在表达式中的「(?mods-mods)」和「(?mods-mods:…)」修饰符。这些模式在第368页的表8-3中有列出。下面是对表8-2的说明:
① 只有在字符组内部,\b才代表退格字符。在其他场合,\b都代表单词分界符。
表中给出的是“纯(raw)”反斜线,但是用作Java正则表达式的字符串时必须使用双反斜线。例如,表中的「\n」在Java的字符串中必须写作“\\n”。请参考“作为正则表达式的字符串”(☞101)。
\x##容许且只容许出现两位十六进制数字,所以「\xFCber」匹配‘über’。
表8-2:java.util.regex的正则流派
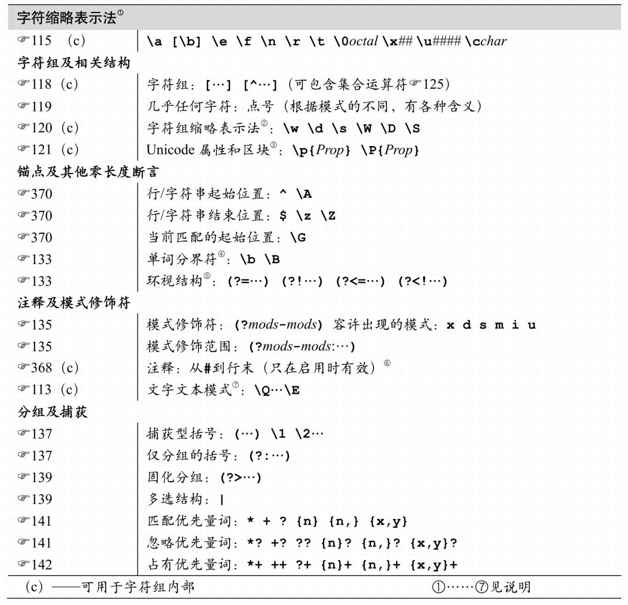
\u####容许且只容许四位十六进制数字,例如,「\u00FCber」匹配‘über’,「\u20AC」匹配‘€’。
\0octal要求开头为0,后接1到3位十进制数字。
\cchar是区分大小写的,直接对后面字符的十进制编码进行异或(xoring)操作。与我见过的任何流派都不一样,在这里\cA和\ca是不同的。\cA等于传统意义上的\x01,\ca则等价于\x21,匹配‘!’。
②\w、\d和\s(以及对应的大写缩略法)只适用于ASCII字符,而不包括其他的字母、数字或者 Unicode 空白字符。也就是说,\d 等价于[0-9],\w 等价于[0-9a-zA-Z],\s等价于[·\t\n\f\r\x0B](\x0B是ASCII中基本不用的VT字符)。
要覆盖完整的Unicode字符,可以使用Unicode属性(☞121):用\p{L}表示\w,\p{Nd}表示\d,用\p{Z}表示\s。(把小写的p替换为大写的P,就可以对应\W、\D和\S)。
③\p{…}和\P{…}支持 Unicode 属性和区块,以及某些额外的“Java 属性”。它不支持Unicode字母表。详细信息在下一页。
④ 对单词分界符元字符\b和\B来说,“单词字符”的规定不同于\w和\W。单词分界符能够识别Unicode字符,而\w和\W只能识别ASCII字符。
⑤ 顺序环视结构中可以使用任意正则表达式,但是逆序环视中的子表达式只能匹配长度
有限的文本。也就是说,「?」可以出现在逆序环视中,但「*」和「+」则不行。请参考第3章133页开始的内容。
⑥ 只有在使用/x修饰符,或者使用Pattern.COMMENTS选项(☞368)(请不要忘记在多
行文本字符串中添加换行符,如第401页的例子)时,#… 才算注释。没有转义的ASCII字空白字符会被忽略。注意:这一点与大多数支持此模式的正则引擎不同,在 Java 中字符组内部的注释和空白字符也会被忽略。
才算注释。没有转义的ASCII字空白字符会被忽略。注意:这一点与大多数支持此模式的正则引擎不同,在 Java 中字符组内部的注释和空白字符也会被忽略。
⑦\Q…\E一直是被支持的,但在Java 1.6之前,字符组内部的此种结构是不可靠的。
表8-3:java.util.regex中Match和Regex的方法