The Matcher Object
把正则表达式和目标字符串联系起来,生成Matcher对象之后,就可以以多种方式将其应用到目标字符串中,并查询应用的结果。例如,对于给定的Matcher对象m,我们可以用m.find()来把m的表达式应用到目标字符串中,返回一个Boolean值,表示是否能找到匹配。如果能找到,m.group()返回实际匹配的字符串。
在讲解Matcher的各种方法之前,不妨先了解了解它保存的各种信息。为了方便阅读,下面的清单都提供了对应的详细讲解部分的页码。第一张清单中的元素是程序员能够设置和更改的,而第二张清单中的元素是只读的。
程序员能够设置和修改的是:
●Pattern 对象,由程序员在创建 Matcher 时指定。可以通过 usePattern()方法更改(☞393)。当前所用的Pattern可以用pattern()方法获得。
●目标字符串(或其他CharSequence对象),由程序员在创建Matcher时指定。可以通过reset(text)方法更改(☞392)。
●目标字符串的“检索范围(region)”(☞394)。默认情况下,检索范围就是整个目标字符串,但是程序员可以通过 region 方法,将其修改为目标字符串的某一段。这样某些(而不是全部)匹配操作就只能在某个区域内进行。
当前检索范围的起始和结束偏移值可以通过 regionStart 和 regionEnd 方法获得(☞386)。reset方法(☞392)会把检索范围重新设置为整个目标字符串,任何在内部调用reset方法的方法也是一样。
●anchoring bounds标志位。如果检索范围不等于整个目标字符串,程序员可以设定,是否将检索范围的边界设置为“文本起始位置”和“文本结束位置”,这会影响文本行边界元字符(\A^$\z\Z)。
默认情况下,这个标志位为 true,但也可能改变,可以通过 useAnchoringBounds (☞388)和hasAnchoringBounds方法来修改和查询。Reset方法不会修改标志位。
●transparent bounds标志位。如果检索范围是整个目标字符串中的一段文本,设置为true容许各种“考察(looking)”结构(顺序环视、逆序环视,以及单词分界符)超越检索范围的边界,检查外部的文本。
默认情况下,这个标志位为false,但也可能改变,可以通过useTransparentBounds (☞388)和hasTran-sparentBounds方法来修改和查询。Reset方法不会修改标志位。
下面的只读数据保存在matcher内部:
●当前pattern的捕获型括号的数目可以通过groupCount(☞377)方法查询。
●目标字符串中的match pointer或current location,用于支持“寻找下一个匹配”的操作(通过find方法☞375)。
●目标字符串中的append pointer,在查找-替换操作中(☞380),复制未匹配的文本部分时使用。
●表示到达字符串结尾的上一次匹配尝试是否成功的标志位。可以通过 hitEnd 方法(☞390)获得这个标志位的值。
●match result。如果最近一次匹配尝试成功,Java会将各种数据收集起来,合称为match result(☞376)。包括匹配文本的范围(通过group()方法),匹配文本在目标字符串中的起始和结束偏移值(通过start()和end()方法),以及每一组捕获型括号对应的信息(通过group(num)、start(num)和end(num)方法)。
match-result 数据封装在 MatchResult 对象中,通过 toMatchResult 方法获得。MatchResult方法有自己的group、start和end方法(☞377)。
●一个标志位,表明更长的目标文本是否会导致匹配失败(匹配成功之后才可用)。如果边界元字符影响了匹配结果的生成,则此值为true。可以通过requireEnd方法查看它的值(☞390)。
上面列出的内容很多,但是如果按照功能分别讲解,便很容易掌握。这正是下面几节的内容。把这一章作为参考手册时,本章开头(☞366)的列表会很有用。
应用正则表达式
Applying the Regex
把matcher的正则表达式应用到目标文本时,主要会用到Matcher的这些方法:
boolean find
此方法在目标字符串的当前检索范围(☞384)中应用Matcher的正则表达式,返回的Boolean值表示是否能找到匹配。如果多次调用,则每次都在上次的匹配位置之后尝试新的匹配。没有给定参数的find只使用当前的检索范围(☞384)。
下面是简单示例:

结果是:
match [Mastring]
如果这样写:

结果就是:

如果指定了整型参数,匹配尝试会从距离目标字符串开头offset个字符的位置开始。如果offset为负数或超出了目标字符串的长度,会抛出IndexOutOfBoundsException异常。
这种形式的find不会受当前检索范围的影响,而会把它设置为整个“目标字符串”(它会在内部调用reset方法☞392)。
第400页的补充内容(作为第399页问题的答案)给出了恰当的例子。
boolean matches
此方法返回的Boolean值表示matcher的正则表达式能否完全匹配目标字符串中当前检索范围的那段文本。也就是说,如果匹配成功,匹配的文本必须从检索范围的开头开始,到检索范围的结尾结束(默认情况就是整个目标字符串)。如果检索范围设置为默认的“所有文本”,matches比使用「\A(?:…)\z」要简单。
不过,如果当前检索范围不等于默认情况(☞384),使用matches可以在不受anchoring-bounds标志位(☞388)影响的情况下检查整个检索范围中的文本。
举例来说,如果使用 CharBuffer 来保存程序中用户输入的文本,而检索范围设定为用户用鼠标选定的部分。如果用户点击选区的部分,可以用m.usePattern(urlPattern).matches()来检查选定部分是否为URL(如果是,则进行相应的处理)。

此方法返回的 Boolean 值表示 Matches 的正则表达式能否在当前目标字符串的当前检索范围中找到匹配。它类似于matches方法,但不要求检索范围中的整段文本都能匹配。
查询匹配结果
Querying Match Results
下面列出的Matcher方法返回了成功匹配的信息。如果正则表达式还未应用过,或者匹配尝试不成功,它们会抛出IllegalStateException。接收num参数(对应一组捕获型括号)的方法,如果给定的num非法,会抛出IndexOutOfBoundsException。
请注意start和end方法,它们返回的偏移值不受检索范围的影响——偏移值从整个目标字符串的开头开始计算,而不是检索范围的开头。
后面还给出了一个例子,讲解其中大部分方法的使用。
String group
返回前一次应用正则表达式的匹配文本。
int groupCount
返回正则表达式中与Matcher关联的捕获型括号的数目。在 group、start和 end方法中可以使用小于此数目的数字作为numth参数,下文介绍(注4)。
String gropu(int num)
返回编号为numth的捕获型括号匹配的内容,如果对应的捕获型括号没有参与匹配,则返回null。如果numth为0,表示返回整个匹配的内容,group(0)就等于group()。
int start(int num)
此方法返回编号为 numth的捕获型括号所匹配文本的起点在目标字符串中的绝对偏移值——即从目标字符串起始位置开始计算的偏移值。如果捕获型括号没有参与匹配,则返回-1。
int start
此方法返回整个匹配起点的绝对偏移值,start()就等于start(0)。
int end(int num)
此方法返回编号为 numth的捕获型括号所匹配文本的终点在目标字符串中的绝对偏移值——即从目标字符串起始位置开始计算的偏移值。如果捕获型括号没有参与匹配,则返回-1。
int end
次方法返回整个匹配的终点的绝对偏移值,end()就等于end(0)。
MatcheResult toMatchResult
此方法从Java 1.5.0开始提供,返回的MatchResult对象封装了当前匹配的信息。它和Matcher类一样,也包含上面列出的group、start、end和groupCount方法。如果前一次匹配不成功,或者 Matcher 还没有进行匹配操作,调用 toMatcheResult会抛出IllegalStateException。
示例
下面的例子示范了若干方法的使用。给定一个URL 字符串,这段代码会找出URL 的协议名(‘http’或是‘https’)、主机名,以及可能出现的端口号:

执行的结果是:

简单查找-替换
Simple Search and Replace
上面介绍的方法足够进行查找-替换操作了,只是比较麻烦,但是 Matcher 提供了简便的方法。
String replaceAll(String replacement)
返回目标字符串的副本,其中Matcher能够匹配的文本都会被替换为replacement,具体处理过程在380页。
此方法不受检索范围的影响(它会在内部调用reset方法),不过第382页介绍了在检索范围中进行这样操作的方法。
String类也提供了replaceAll的方法,所以:
string.replaceAll(regex,replacement)
就等于:
Pattern.compile(regex).matcher(string).replaceAll(replacement)
String replaceFirst(String replacement)
此方法类似replaceAll,但它只对第一次匹配(如果存在)进行替换。
String类也提供了replaceFirst方法。
static String quoteReplacement(String text)
此static方法从Java 1.5开始提供,返回text的文字用作replacement的参数。它为text副本中的特殊字符添加转义,避免了下一页讲解的正则表达式特殊字符处理(下一节也给出了Matcher.quoteReplacement的例子)。
简单查找-替换的例子
下面的程序将所有的“Java 1.5”改为“Java 5.0”,用市场化的名称取代开发名称:

结果是:
Before Java 5.0 was Java 1.4.2.After Java 5.0 is Java 1.6
如果pattern和matcher不需要复用,可以使用链式编程:
Pattern.compile("\\bJava\\s*1\\.5\\b").matcher(text).replaceAll("Java 5.0")
(如果单个线程中需要多次用到同一pattern,预编译pattern对象可以提升效率☞372)
对正则表达式稍加修改,就可以用它来把“Java 1.6”改为“Java 6.0”(当然也需要修改replacement字符串,讲解见下页)。
Pattern.compile("\\bJava\\s*1\\.([56])\\b").matcher(text).replaceAll("Java$1.0")
对于同样的输入文本,结果如下:
Before Java 5.0 was Java 1.4.2.After Java 5.0 is Java 6.0
如果只需要替换第一次出现的文本,可以使用replaceFirst,而不是replaceAll。除了这种情况,还有一种情况可以使用replaceFirst,即明确知道目标字符串中只存在一个匹配时,使用 replaceFirst 可以提高效率(如果了解正则表达式或是目标字符串,可以预知这一点)。
replacement参数
replaceAll 和 replaceFirst 方法(以及下一节的 appendReplacement 方法)接收的replacement参数在插入到匹配结果之前,会进行特殊处理:
●‘$1’、‘$2’之类会替换为对应编号的捕获型括号匹配的文本($0会被替换为所有匹配的文本)。
●如果‘$’之后出现的不是ASCII的数字,会抛出IllegalArgumentException异常。
‘$’之后的数字,只会应用“有意义”的部分。如果只有3组捕获型括号,则‘$25’会被视为$2然后是‘5’,而此时$6会抛出IndexOutOfBoundsException。
●反斜线用来转义后面的字符,所以‘\$’表示美元符号。同样的道理,‘\\’表示反斜线(在Java的字符串中,表示正则表达式中的‘\\’需要用四个斜线‘\\\\’)。同样,如果有12组捕获型括号,而我们希望使用第一组捕获型括号匹配的文本,然后是‘2’,应该是这样‘$1\2’。
如果不清楚replacement字符串的内容,最好使用Matcher.quoteReplacement方法,确保不会出错。如果用户的正则表达式是uRegex,replacement是uRepl,下面的做法可以确保替换的安全:
Pattern.compile(uRegex).matcher(text).replaceAll(Matcher.quoteReplacement(uRepl))
高级查找-替换
Advanced Search and Replace
有两个方法可以直接操作 Matcher 的查找-替换过程。它们配合起来,把结果存入用户指定的 StringBuffer中。第一种方法每次匹配之后都会调用,在result中存入replacement字符串和匹配之间的文本。第二种方法会在所有匹配完成之后调用,将目标字符串中最后的文本拷贝过来。
Matcher appendReplacement(StringBuffer result,String replacement)
在正则表达式应用成功之后(通常是find)马上调用此方法会把两个字符串添加到指定的 result 中:第一个是原始目标字符串匹配之前的文本,然后是经过上面讲解的特殊处理的replacement字符串。
举例来说,如果matcher m与正则表达式「\w+」和‘-->one+test<--’相联系,while循环的第一轮情况如下:
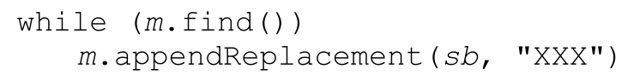
find找到下画线标注的部分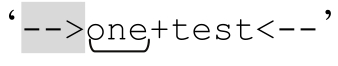 ’。
’。
然后,第一次appendReplacement调用会在StringBuffer result中加入匹配之前的文本‘-->’,跳过匹配的文本,再插入replacement字符串‘XXX’。
While循环的第二轮,find匹配 。此时调用appendReplacement会给sb附加上匹配之前的文本‘+’,然后仍然是字符串‘XXX’。
。此时调用appendReplacement会给sb附加上匹配之前的文本‘+’,然后仍然是字符串‘XXX’。
这样sb的值就是‘-->XXX+XXX’,m在原始目标字符串中对应的位置是‘-->one+test
☞
<--’。现在该使用appendTail方法了,下文将会介绍。
StringBuffer appendTail(StringBuffer result)
找到所有匹配之后(或者是,找到期望的匹配之后——此时用户可以停止匹配过程),这个方法将目标字符串中剩下的文本附加到提供的StringBuffer中。
在上例中,接下来就是:
m.appendTail(sb)
将‘<--’附加到sb。这样就得到‘-->XXX+XXX<--’,查找-替换完成。
查找-替换示范
下面实现了一个自己的replaceAll的方法(并非必须,只是作为示范)。

它与 Java 内建的 replaceAll方法一样,它不受检索范围(☞384)的影响,而是在查找-替换之前重置检索范围。
为了弥补这个缺憾,下面的replaceAll只在检索范围中进行,修改和新增的代码会标注出来:

这里使用“方法链(译注1)”结合reset和region,详细讲解请参阅第389页。下面的程序更加完善,它将metric变量中的摄氏温度转换为华氏温度:

如果metric变量包含“from 36.3C to 40.1C.”,结果就是“from 97F to 104F.”。
原地查找-替换
In-Place Search and Replace
现在还只出现过对 String对象使用 java.util.regex的例子,但是Matcher其实适用于任何实现了CharSequence接口的类,所以我们能够对目标文本进行实时的、原地(in place)的修改。
StringBuffer和 StringBuilder是两种常用的实现了 CharSequence接口的类,前者保证线程安全性,但效率略低。这两者都可以作为String来使用,但它们的值可以变化。本书中的例子使用了StringBuilder,但如果在多线程环境中,请使用StringBuffer。
这个简单的例子在StringBuilder中搜索大写单词,将它们替换为小写形式(注5):

结果是:
It's so very rude to shout!
其中匹配了两次,调用了两次text.replace。头两个参数指定需要替换的文本范围(跳过表达式匹配的文本),然后是用作replacement的文本(也就是匹配文本的小写形式)。
因为replacement和匹配文本长度相同,原地的查找-替换很简单。如果不需要迭代进行查找-替换,这种方法非常方便。
长度变化的替换
如果replacement的长度不同于要替换文本的长度,情况就复杂起来。对目标字符串的修改是在“背后”进行的,所以“匹配指针(match pointer)”(在目标字符串中进行下一次find的开始位置)会发生错误。
要解决这个问题,我们可以自己维护匹配指针,明确告诉find下一次尝试应该从何处开始。下面的例子做了这样的改进,在需要插入的小写文本两端添加了<b>…</b>:

结果是:
It's <b>so</b> very <b>rude</b> to shout!
Matcher的检索范围
The Matcher's Region
从Java1.5 开始,Matcher 支持可变化的检索范围,通过它,我们可以把匹配尝试限制在目标字符串之中的某个范围。通常情况下,Matcher的检索范围包含整个目标字符串,但可以通过region方法实时修改。
下面的例子检索 HTML 代码字符串,报告不包含 ALT 属性的 image tag。对同一段文本(HTML),它使用了两个Matcher:一个寻找image tag,另一个寻找ALT属性。
尽管两个Matcher应用到同一个字符串,但它们的关联只局限于,用找到的image tag来限定寻找ALT属性的范围。在调用ALT-matcher的find方法之前,我们用刚刚完成的image-tag的匹配来设定ALT-matcher的检索范围。
单拿出image tag的body之后,就可以通过查找ALT来判断当前的tag内是否包含ALT属性:

或许在一处指定目标字符串(创建 mAlt Matcher 时),另一处指定检索范围(调用mAlt.region时)的做法有些怪异。果真如此的话,我们可以为mAlt创建虚构的目标字符串(一个空字符串),然后每次都调用 mAlt.reset(html).region(…)。调用 reset可能会降低些效率,但是同时设定目标字符串和检索范围的逻辑更加清晰。
无论采取哪种办法,都必须明白,如果不设定ALT Matcher的检索范围,对它调用find就会检索整个目标字符串,返回无关的‘ALT=’属性。
下面继续完善这个程序,返回找到的 image tag 在HTML 代码中的行数。我们首先隔离出image tag之前的HTML代码,然后计算其中的换行符数。
标注部分为新增代码:

与之前一样,每次设定ALT Matcher的检索范围时,都使用image matcher的start(1)方法得到image tag body在HTML中的起始位置。相反,在设定换行符匹配的检索范围终点时,使用start()方法来判断整个image tag的开始位置(也就是换行符计算的终点)。
几点提醒
记住,某些检索相关的方法并非不受检索范围的影响,而是它们在内部调用了reset方法,把检索范围设定为默认的“全部文本”。
●受检索范围影响的查找方法:

●会重置matcher及其检索范围的方法:

另外请记住,匹配结果数据中的偏移值(也就是start和end方法返回的数值)是不受检索范围影响的,它们只与整个目标字符串的开始位置有关。
设定及查看检索范围的边界
与设定及查看检索范围边界的方法有3个:
Matcher region(int start,int end)
将matcher的检索范围设定在整个目标字符串的start和end之间,数值均从目标字符串的起始位置开始计算。它同样会重置Matcher,将“匹配指针”指向检索范围的开头,所以下一次调用find从此处开始。
如果没有重新设定,或是调用reset方法(无论是显式调用还是在其他方法内部调用☞392),检索范围都不会变化。
返回值为Matcher对象本身,所以此方法可用于方法链(☞389)。
如果start或end超出了目标字符串的范围,或者start比end要大,会抛出IndexOutOf-BoundsException。
int regionStart
返回当前检索范围的起始位置在目标字符串中的偏移值,默认为0。
int regionEnd
返回当前检索范围的结束位置在目标字符串中的偏移值,默认为目标字符串的长度。因为region方法要求同时提供start和end,如果只希望设置其中一个,可能不太方便操作。表8-4给出了方法。
表8-4:设定检索范围的单个边界

超越检索范围
如果将检索范围设定为整个目标字符串中的一段,正则引擎会忽略范围之外的文本。也就是说,检索范围的起始位置可以用「^」匹配,而它可能并不是目标字符串的起始位置。
不过,某些情况下也可以检查检索范围之外的文本。启用transparent bounds能够让“考察(looking)”结构检查范围之外的文本,如果禁用anchoring bounds,则检索范围的边界不会被视为输入数据的起始/结束位置(除非实际情况如此)。
修改这两个标志位的理由与修改默认检索范围密切相关。之前用到了检索范围的例子都不需要设定这两个标志位——与检索范围相关的查找既不需要锚点也不需要“考察”结构。
如果程序把需要用户编辑的文本存放在 CharBuffer中,用户希望执行查找-替换操作,就应当把操作的范围限定在光标之后的文本中,所以应当把检索范围的起始位置设定为当前光标所在的位置。如果用户的光标指向下面的位置:
Madagas☞car is much too large to see on foot,so you'll need a car.
要求把「\bcar\b」替换为“automobile”。设定了检索范围之后(即将其设定为光标之后的文本),你可能会很惊奇地发现第一次匹配就是在检索范围的开头:‘Madagascar’。这是因为默认情况下transparent bounds标志位设定为false,因此「\b」将检索范围起始位置设定为文本的起始位置,而“看不到”左侧还有字符。如果将transparent bounds设定为true,「\b」就能看到‘c’之前还有‘s’,因此「\b」不能匹配。
Transparent Bounds
与这个标志位相关的方法有两个:
Matcher useTransparentBounds(boolean b)
设定transparent bounds的值。默认为false。
此方法返回Matcher本身,故可用在方法链中。
boolean hasTransparentBounds
如果transparent生效,则返回true。
Matcher 的transparent-bounds 默认为false。也就是说检索范围的边界在顺序环视、逆序环视和单词分界符“考察”时是不透明的。这样,正则引擎不会感知到检索边界之外的字符(注6)。
也就是说尽管检索范围的起始位置可能在某个单词内部,「\b」仍然能够匹配——它看不到之前的字母。
下面的例子说明了transparent bounds设置为false(默认)的情况:

结果是:也就是说尽管检索范围的起始位置可能在某个单词内部,「\b」仍然能够匹配——它看不到之前的字母。
Matches starting at character 7
单词分界符的确匹配了检索范围的起始位置,即 Madagas☞car,尽管此处根本不是单词的边界。如果不设定transparent bounds,单词分界符就“受骗(spoofed)”了。
如果在find之前添加这条语句:
m.useTransparentBounds(true);
结果就是:
Matches starting at character 27
因为边界现在是透明的,引擎可以感知到起始边界之前有个字母‘s’,所以「\b」在此处无法匹配。于是结果就成了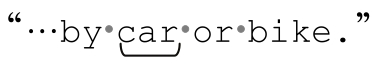 。
。
同样,transparent-bounds只有在检索范围不等于“整个目标字符串”时才有意义。即使reset方法也不会重置它。
Anchoring bounds
与anchoring bounds有关的方法有:
Matcher useAnchoringBounds(Boolean b)
设置matcher的anchoring-bounds的值,默认为true。
此方法会返回matcher对象本身,故可用于方法链中。
boolean hasAnchoringBounds
如果启用了anchoring bounds,则返回true,否则返回false。
默认状态下,anchoring bounds为true,也就是说行锚点(^\A $\z\Z)能匹配检索范围的边界,即检索范围不等于整个目标字符串。将它们设置为false表示行锚点只能匹配检索范围内,整个目标字符串中符合规定的位置。
禁用anchoring bounds的理由可能与使用transparent bounds一样,当用户的“光标不在整段文本的起始位置时”保证语意的完备。
与transparent-bounds一样,anchoring bounds也只有在检索范围不等于“整个目标字符串”时才有意义。即使reset方法也不会重置它。
方法链
Method Chaining
下面的程序初始化一个Matcher,并设定某些选项:

在前面的例子中我们看到,如果创建Matcher之后不再需要regex,可以把前面两步合并起来:

不过,因为Matcher的两个方法会返回Matcher本身,可以把它们整合成一行(尽管因为排版的原因必须列为两行):

功能并没有增加,但用起来更加简便。这种“方法链”格式紧凑,一行程序可能很难对应到单个步骤的文档,不过,好的文档重在说明“为什么”而不是“干什么”,所以这可能并不是个问题。在第399页的程序中,使用方法链可以保证格式紧凑清晰。
构建扫描程序
Methods for Building a Scanner
Java 1.5的matcher提供了两个新方法,hitEnd和requireEnd,它们主要用来构建扫描程序(Scanner)。扫描程序将字符流解析为记号(token)流。举例来说,编译器的扫描程序会把‘var·<·34’解析为三个记号:INDENTIFIER·LESS_THAN·INTEGER。
这两个方法帮助扫描程序决定,刚刚完成的匹配尝试的结果是否应该用来解释(interpretation)当前输入。一般来说,只要其中一个返回 true,就表示在做出决定之前还应该输入更多的数据。例如,如果当前的输入数据(比如用户在交互式调试器中输入的命令)是单个字符‘<’,最好还是看看下一个字符是否‘=’,才能决定这个记号是LESS_THAN还是LESS_THAN_OR_EQUAL。
在大多数应用正则表达式的项目中,这两个方法可能派不上用场,可是一旦需要,它们就是不可替代的。在这些不常见的场合,Java 1.5中hitEnd方法存在的bug就很让人恼火。不过,看起来Java 1.6已经修正了这个错误,Java 1.5中的解决办法将在本章末尾介绍。
构建扫描程序已经远远偏离了本书的主旨,所以我只会介绍些具体方法的定义,并给出例子(如果你确实需要扫描程序,应该去看看java.util.Scanner)。
boolean hitEnd
(Java 1.5中这个方法是不可靠的,解决办法参见第392页)。
此方法表示,正则引擎在上一次匹配尝试中,是否检查了输入数据结束之后的数据(而无论上一次匹配是否成功)。其中包含「\b」和「$」之类的边界检查。
如果hitEnd返回true,则输入更多数据可能会改变匹配结果(匹配成功变为匹配失败,匹配失败变为匹配成功,或者匹配文本发生变化)。相反,如果返回false,则匹配结果已经确定,输入更多的数据也不会改变匹配结果。
常见的应用是,如果匹配成功,而hitEnd返回true,则必须等待更多的输入数据才能最后做出决定。如果匹配失败,而 hitEnd返回 false,应该期待更多的输入数据,而不是报告语法错误。
boolean requireEnd
此方法只有在匹配成功之后才有意义,它表示正则引擎的匹配成功与否是否受输入数据结尾的影响。也就是说,如果requireEnd返回true,更多的输入数据可能导致匹配尝试失败,如果返回false,更多的输入数据可能改变匹配的细节,但不会导致匹配失败。
常见的应用是,如果requireEnd返回true,在最后做出决定之前,必须接受更多的输入数据。
hitEnd和requireEnd都受到检索范围的影响。
使用hitEnd和requireEnd的例子
表8-5给出了在lookingAt搜索之后使用hitEnd和requireEnd的例子。所给的两个例子虽然很简单,但足够解释这两个方法。
表8-5:在lookingAt搜索之后使用hitEnd和requireEnd的例子
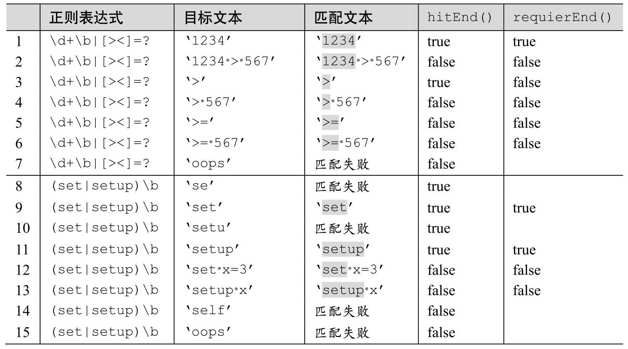
表8-5中上面7行的正则表达式寻找一个非负整数以及4个比较运算符:大于、大于等于、小于、小于等于。下面8行的正则表达式更简单,寻找单词 set或是 setup。这些例子很简单,但能说明问题。
举例来说,第5行中,虽然整个目标字符串都能匹配,hitEnd仍然会返回false。原因在于,尽管匹配文本包含目标字符串的最后一个字符,引擎也不需要检查之后的字符(无论是字符还是分界符)。
hitEnd的bug及解决办法
Java 1.5中的hitEnd方法存在bug(Java 1.6已经修正)(注7),在某些特殊情况下hitEnd会得到不可靠的结果:在不区分大小写的匹配模式下,如果正则表达式的某个可选元素为单个字符(尤其是当它的匹配尝试失败时),就会出错。
例如,在不区分大小写的情况下使用「>=?」(它作为大的正则表达式的一部分)会诱发这个错误,因为‘=’是可选的单个字符。在不区分大小写的情况下使用「a|an|the」(仍然是包含在大的正则表达式中)也会诱发这个错误,因为单个字符「a」是众多多选分支之一,因此是可选的。
另两个例子是「values?」和「\r?\n\r?\n」。
解决办法 解决的办法是破坏诱发条件,或者禁用不区分大小写的匹配(至少是对诱发的子表达式禁用),或者是把单个字符替换为其他元素,例如字符组。
第一种办法会把「>=?」替换为「(?-i:>=?)」,使用模式修饰范围(☞110)保证不区分大小写的匹配不会应用于这个子表达式(这里不存在大小写的区别,所以这种办法完全没问题)。
如果使用第二种办法,「a|an|the」就变成了「[aA]|an|the」,代表了使用 Pattern.CASE_INSENSITIVE进行不区分大小写匹配的情况。
Matcher的其他方法
Other Matcher Methods
这些Matcher方法尚未介绍过:
Matcher reset
这个方法会重新初始化 Matcher 的大多数信息,弃用前一次成功匹配的所有信息,将匹配位置指向文本的开头,把检索范围(☞384)恢复为默认的“全部文本”。只有anchoring bounds和transparent bounds(☞388)不会变化。
Matcher有三个方法会在内部调用reset,因此也会重新设定检索范围:replaceAll、replaceFirst,以及只使用一个参数的find。
这个方法返回Matcher本身,所以它可以用在方法链中(☞389)。
Matcher reset(CharSequence text)
这个方法与 reset()差不多,但还会把目标文本改为新的 String(或者任何实现CharSequence的对象)。
如果你希望对多个文本应用同样的正则表达式(例如,对所读入的文件的每一行),使用reset方法比多次创建新的Matcher更有效率。
这个方法返回Matcher本身,所以可以用在方法链中(☞389)。
Pattern pattern
Matcher的pattern方法返回与此Matcher关联的Pattern对象。如果希望观察所使用的正则表达式,请使用 m.pattern().pattern(),它会调用 Pattern 对象(名字相同,但对象不同)的pattern方法(☞394)。
Matcher usePattern(Pattern p)
从Java 1.5开始添加,这个方法会用给定的Pattern对象替换当前与Matcher关联的Pattern对象。这个方法不会重置Matcher,所以能够在文本的“当前位置”开始使用不同的pattern。第399页有此方法实际应用的例子和讨论。
这个方法返回Matcher本身,所以可以用在方法链中(☞389)。
String toString
从Java 1.5中添加,这个方法返回包含Matcher基本信息的字符串,调试时这很有用。字符串的内容可能会变化,在Java 1.6 beta中是这样:

结果是:
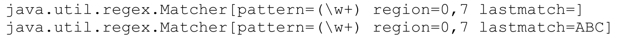
Java 1.4.2的Matcher类只有继承自java.lang.Object的toString方法,它返回没什么信息含量的字符串:‘java.util.regex.Matcher@480457’。
查询Matcher的目标字符串
Matcher类没有提供查询当前目标字符串的方法,但有些办法绕过了这种限制:

这里使用replaceFirst方法,以及虚构的pattern和replacement字符串,来取得目标字符串的未经修改的副本。其中它重置了Matcher,但也恢复了之前的检索范围。它不是特别好的解决方案(效率也不是很高,而且即便 Matcher 的目标字符串可能是其他类型也会返回String),但是在Sun给出更好的办法之前,它还凑合。