.NET\'s Regex Flavor
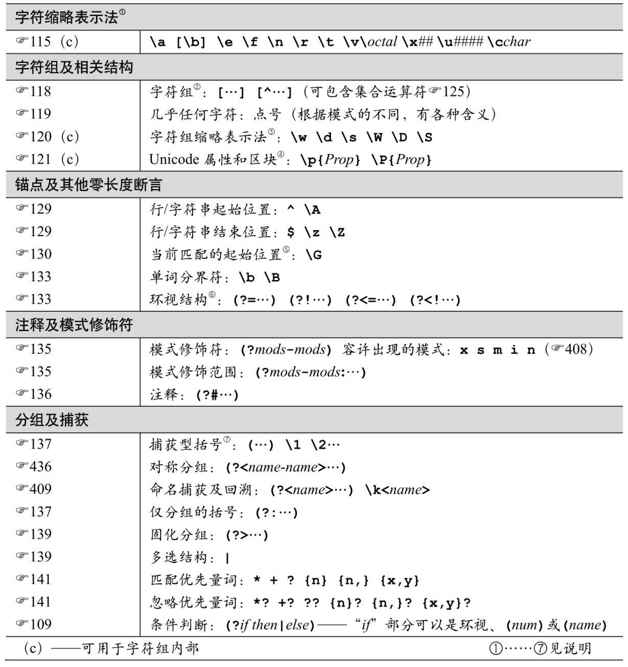
.NET使用的是传统型NFA引擎,所以第4、5、6章讲解的NFA的知识都适用于.NET。下一页的表9-1简要说明了.NET的正则流派,其中大部分已经在第3章介绍过。
在接收正则表达式的函数和结构中设置标志位(flag),或是在正则表达式之内使用「(?modes-modes)」和「(?mods-mods:…)」结构,可以使用不同的匹配模式,流派的许多方面也会因此发生变化(☞110)。408页的表9-2列出了这些模式。
其中包括了「w」之类的“纯”转义。它们可以直接用到 VB.NET 的字符串文字("w")和C#的verbatim字符串(@"w")中。C++的语言没有提供针对正则表达式的字符串文字,所以正则表达式中的反斜线在字符串文本中需要双写("\\w")。请参考“作为正则表达式的字符串”(☞101)。
下面是对表9-1的补充说明:
①b只有在字符组内部才作为退格符。在字符组之外,b匹配单词分界符(☞133)。
x##容许出现两位十六进制数字,例如「xFCber」匹配‘über’。
u####容许且只容许四位十六进制数字,例如「u00FCber」匹配‘über’,「u20AC」匹配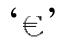 。
。
②.NET Framework Version 2.0中的字符组支持集合减法,例如「[a-z-[aeiou]]」表示小写的非元音ASCII字母(☞125)。在字符组内部,连字符之后又跟着字符组表示字符组的减法运算,减去后面字符组内部的字符。
③w、d和s(以及对应的W、D和S)通常能处理所有合适的Unicode字符,但是如果启用了RegexOptions.ECMAScript(☞412),就只能处理ASCII字符。
在此默认模式下,w 匹配 Unicode 属性p{Ll}、p{Lu}、p{Lt}、p{Lo}、p{Nd}和p{Pc}。请注意,其中并没有p{Lm}(请参考第123页的属性列表)。
表9-1:NET正则表达式流派概览
在默认模式下,s匹配「[·fnrtvx85p{Z}]」,U+0085是Unicode 中的NEXT LINE控制字符,p{Z}匹配Unicode的“分隔符”字符(☞122)。
④p{…}和P{…}支持标准的Unicode属性和区块(针对Unicode Version 4.0.1)。不支持Unicode字母表。
区块名要求出现‘Is’前缀(参考第125页的表格),只能够使用含有空格或者下画线的格式。例如,p{Is_Greek_Extended}和p{Is Greek Extended}是不容许的,正确的只有p{IsGreekExtended}。
.NET只支持p{Lu}之类的短名称,而不支持p{Lowercase_Letter}之类的长名称。单字母属性也要求使用花括号(也就是说,不能把p{L}简记为pL)。请参考第 122和第123页的表格。
.NET 也不支持特殊的复合属性p{L&},以及特殊属性p{All}、p{Assigned}和p{Unassigned}。相反,你可以使用「(?s:.)」、「P{Cn}」、「p{Cn}」分别来代替。
⑤G表示上一次匹配的结束位置,虽然文档介绍说它表示本次匹配的开头位置(☞130)。
⑥ 顺序环视和逆序环视中都可以使用任意形式的正则表达式。就我所知,.NET正则引擎是唯一容许在逆序环视中出现能够匹配任意长度文本表达式的引擎(☞133)。
⑦ RegexOptions.ExplicitCapture选项(也可通过模式修饰符(?n)设定)会禁止普通的「(…)」括号的捕获功能。不过明确命名的捕获型括号——例如「(?<num>d+)」——仍然有效(☞138)。如果使用了命名分组,此选项容许你使用更加美观的「(…)」,而不是「(?:…)」,来进行纯粹的分组。
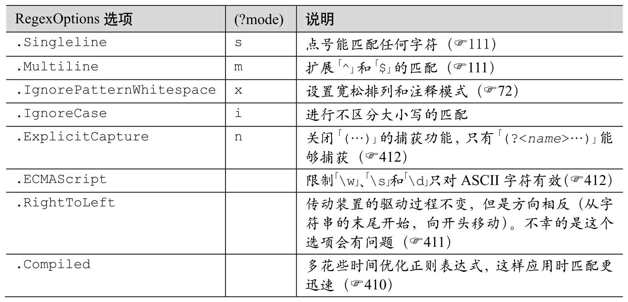
表9-2:NET的匹配模式和正则表达式模式
对于流派的补充
Additional Comments on the Flavor
下面介绍一些其他的相关细节。
命名捕获
.NET支持命名捕获(☞138),它通过「(?<name>…)」或是「(?\'name\'…)」实现。这两种办法是等价的,可以随意选用其中一种,不过我更喜欢<…>,因为我相信使用它的人多一些。
要反向引用命名捕获匹配的文本,可以使用「k<name>」或是「k\'name\'」。
在匹配之后(也就是Match对象生成之后;下文从第416页开始概要介绍.NET的对象模型),命名捕获匹配的文本可以通过 Match 对象的 Groups(name)属性来访问(C#使用Groups[name])。
在replacement字符串中(☞424),命名捕获的结果通过${name}来访问。
某些情况下,可能需要按数字顺序访问所有的分组,所以命名捕获的分组也会被标上序号。它们的编号从所有未命名的分组之后开始:
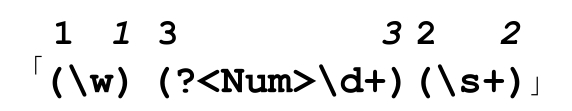
本例中,我们可以用Groups("Num")或Groups(3)来访问「d+」匹配的文本。这两个名字对应同一个分组。
不幸的结果
一般情况下不应该把正常的捕获型括号和命名捕获混合起来,不过如果你这样做了,就必须彻底理解捕获分组的编号顺序。如果捕获型括号用于Split(☞425),或者在replacement字符串中使用了‘$+’(☞424),编号就很重要。
条件测试
如果「(?if then|else)」中的if部分(☞140)可以使用任意类型的环视结构,也可以在括号中使用捕获分组的编号,或者是命名分组的名字。这里出现的纯文本(或者纯正则表达式)会被自动当作肯定型顺序环视来处理(也就是说,可以将其看作「(?=…)」包围的结构)。这可能带来麻烦:例如,「…(?(Num) then|else)…」中的「(Num)」会变为「(?=Num)」(也就是顺序环视的‘Num’),如果在正则表达式的其他地方没有出现「(?<Num>…)」时会这样。如果存在这样的命名捕获,if判断的就是它是否捕获成功。
我推荐不要依赖这种“自动化顺序环视(auto-lookaheadfication)”,而明确使用「(?=…)」把意图传达给看程序的人,这样如果正则引擎在未来修改了if语法,也不会带来意外。
“编译好的”正则表达式
在前面几章,我使用“编译(compile)”这个词来描述所有正则表达式系统中,在应用正则表达式之前必须做的准备工作,它们用来检查正则表达式是否格式规范,并将其转换为能够实际应用的内部形式。在.NET 的正则表达式中,它的术语是“解析(parsing)”。.NET使用两种意义的“编译”来指涉解析阶段的优化。
下面是增进优化效果的细节:
●解析(Parsing) 程序在执行过程中,第一次遇到正则表达式时必须检查它是否格式规范,并将其转换为适于正则引擎实际应用的内部形式。此过程在本书的其他部分称为“编译(compile)”。
●即用即编译(On-the-Fly Compilation)在构建正则表达式时,可以指定RegexOptions.Compiled选项。它告诉正则引擎,要做的不仅是此表达式转换为某种默认的内部形式,而是编译为底层的MSIL(Microsoft Intermediate Language)代码,在正则表达式实际应用时,可以由JIT(“Just-In-Time”编译器)优化为更快的本地机器代码。
这样做需要花费更多的时间和空间,但这样得到的正则表达式速度更快。本节之后会讨论这样的权衡。
●预编译的正则表达式 一个(或多个)Regex对象能够封装到DLL(Dynamically Loaded Library,例如共享的库文件)中,保存在磁盘上。这样其他的程序也可以直接调用它。称为“编译装配件(assembly)”。请参考“正则表达式装配件”(☞434)获得更多信息。
如果使用RegexOptions.Compiled来进行“即用即编译”的编译,在启动速度,持续内存占用和匹配速度之间,存在此消彼长的关系:

在程序第一次遇到正则表达式时进行初始的正则表达式解析(默认情况,即不用RegexOp-tions.Compiled)相对来说是很快的。即使在我这台有年头的550MHz NT的机器上,每秒钟也能进行大约1 500次复杂编译。如果使用RegexOptions.Compiled,则速度下降到每秒25次,每个正则表达式需要多占用大约10KB内存。
更重要的是,在程序的执行过程中,这块内存会一直占用——它无法释放。
在对时间要求不严格的场合使用RegexOptions.Compiled无疑是很有意义的,在这里,速度是很重要的,尤其是需要处理大量的文本时更是如此。另一方面,如果正则表达式很简单,需要处理的文本也不是很多,这样做就没有意义。如果情况不是这样黑白分明,该如何选择就不那么容易了——必须具体情况具体分析,以进行取舍。
某些情况下,把编译的正则表达式作为“编译好的”正则对象封装到DLL中是很有价值的。最终的程序所占的内存更少(因为不必装载编译正则表达式所需的包),装载速度更快(因为在 DLL 生成时它们已经编译好了,只需要直接使用即可)。另一个不错的副产品就是,表达式还可以供其他需要的程序使用,所以这是一种组建个人正则表达式库的好办法。请参考第435页的“使用装配件构建自己的正则表达式库”。
从右向左的匹配
长期以来,正则表达式的开发人员一直觊觎着“反向(backwards)”匹配(即从右向左,而不是从左向右)。对开发人员来说,最大的问题可能是,“从右向左”的匹配到底是什么意思?是整个正则表达式都需要反过来吗?还是说,这个正则表达式仍然在目标字符串中进行尝试,只是传动装置从结尾开始,驱动过程从右向左进行?
抛开这些纯粹的概念,看个具体的例子:用「d+」匹配字符串‘123·and·456’。我们知道正常情况下结果是‘123’,根据直觉,从右向左匹配的结果应该是‘456’。不过,如果正则引擎使用的规则是,从字符串末尾开始,驱动过程从左向右进行,结果可能就会出乎意料。在某些语意下,正则引擎能够正常工作(从开始的位置向右“看”),所以第一次尝试「d+」是在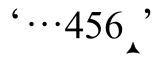 ’,这里无法匹配。第二次尝试在
’,这里无法匹配。第二次尝试在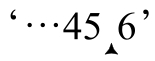 ’,这里能够匹配,所以驱动过程开始“考察”位置‘6’,这当然可以匹配「d+」,所以最后的结果是‘6’。
’,这里能够匹配,所以驱动过程开始“考察”位置‘6’,这当然可以匹配「d+」,所以最后的结果是‘6’。
.NET的正则表达式提供了RegexOptions.RightToLeft的选项。但它究竟是什么意义呢?答案是:“这问题值得思索。”它的语意没有文档,我测试了也无法找到规律。在许多情况下——例如‘123·and·456’,它给出符合直觉的结果(也就是‘456’)。
不过,有时候也会报告没有匹配结果,或是匹配跟其他结果相比毫无意义的文本。
如果需要进行从右向左的匹配,你可能会发现,RegexOptions.RightToLeft 似乎能得到你期望的结果,但是最后,你会发现这样做得冒风险。
反斜线-数字的二义性
数字跟在反斜线之后,可能表示十进制数的转义,也可能是反向引用。到底应该如何处理,取决于是否指定了RegexOptions.ECMAScript选项。如果你不关心其中的细微差别,不妨一直用「k<num>」表示反向引用,或者在表示十进制数时以0开头(例如「\08」)。这两种办法不受RegexOptions.ECMAScript的影响。
如果没有使用RegexOptions.ECMASCript,从「1」到「9」的单个转义数字通常代表反向引用,而以 0 开头的转义数字通常代表十进制转义(例如,「\012」匹配 ASCII 的进纸符linefeed),除此之外的所有情况下,如果“有意义”(也就是说某个正则表达式中有足够多的捕获型括号),数字都会被作为反向引用来处理。否则,如果数字的值处于\000和377之间,就作为十进制转义。例如,如果捕获型括号的数目多于12,则「12」会作为反向引用,否则就会作为十进制数字。
下一节详细讲解RegexOptions.ECMAScript的语意。
ECMAScript模式
ECMAScript的基础是一种标准版本的JavaScript(注2),还包含了它自己的解析和应用正则表达式的语意。如果使用 RegexOptions.ECMAScript 选项,.NET 的正则表达式就会模拟这些语意。如果你不明白ECMASCript的含义,或者不需要兼容它,就完全可以忽略该节。
如果启用了RegexOptions.ECMASCript,将会应用下面的规则:
●RegexOptions.ECMAScript只能与下面的选项同时使用:

●w、d、s、W、D、S只能匹配ASCII字符。
●正则表达式中的反斜线-数字的序列不会有反向引用和十进制转义的二义性,它只能表示反向引用,即使这样需要截断结尾的数字。例如,「(…)10」中的「10」会被处理为,第1组捕获性括号匹配的文本,然后是文字‘0’。