Core Object Details
概览完毕,来看细节。首先,我们来看如何创建 Regex 对象,然后来看如何将其应用到字符串,生成Match对象,以及如何处理这个Match对象和它的Group对象。
在实践中,很多时候不必明确创建 Regex 对象,不过明确创建看起来更顺眼,所以在讲解核心对象时,每次都会创建它们。稍后我会告诉你.NET提供的简便方法。
在下面的列表中,我会忽略从Object类继承而来的,很少用到的方法。
创建Regex对象
Creating RegexObjects
Regex的构造函数并不复杂。它可以接收一个参数(作为正则表达式的字符串),或者是两个参数(一个正则表达式和一组选项)。下面是一个参数的例子:
Dim StripTrailWS=new Regex("s+$")\'去掉结尾的空白字符
它只是创建Regex,做好应用前的准备;而没有进行任何匹配。
下面是使用两个参数的例子:
Dim GetSubject=new Regex("^subject:(.*)",RegexOptions.IgnoreCase)
这里多出了一个RegexOptions选项,不过可以用OR运算符连接多个选项,例如:

捕获异常
如果正则表达式包含了元字符的非法组合,就会抛出ArgumentException。通常,如果用户知道所使用的正则表达式能够正常工作,就不需要捕获这个异常,不过如果使用程序“之外”(例如由用户输入,或者从配置文件读入)的正则表达式,就必须捕获这个异常。

显然,根据情况的不同,在检测到异常之后可能需要不同的处理:你可能需要进行其他的处理,而不仅仅是向控制台输出报错信息。
Regex选项
在创建Regex对象时,可以使用下面的选项:
RegexOptions.IgnoreCase
此选项表示,在应用正则表达式时,不区分大小写(☞110)。
RegexOptions.IgnorePatternWhitespace
此选项表示,正则表达式应该按照自由格式和注释模式(☞111)来解析。如果使用单纯的「#…」注释,请确认在每一个逻辑行的末尾都有换行符,否则第一处注释会“注释掉”之后的整个正则表达式。
在VB.NET中,我们可以用chr(10)来实现,例如:

这样很累赘;VB.NET提供了更简便的「(?#…)」注释:

此选项表示,正则表达式在应用时应采用增强的行锚点模式(☞112)。也就是说,「^」和「$」能够匹配字符串内部的换行符,而不仅仅是匹配整个字符串的开头和结尾。
RegexOptions.Singleline
此选项表示,正则表达式使用点号通配模式(☞111)。此时点号能够匹配任意字符,也包括换行符。
RegexOptions.ExplicitCapture
此选项表示,普通括号「(…)」,在正常情况下是捕获型括号,但此时不捕获文本,而是与「(?:…)」一样,只分组,不捕获。此时只有命名捕获括号「(?<name>…)」能够捕获文本。
如果使用了命名分组,又希望使用非捕获型括号来分组,就可以使用正常的「(…)」括号和此选项,这样程序看起来更清晰。
RegexOptions.RightToLeft
此选项表示,进行从右向左的匹配(☞411)。
RegexOptions.Compiled
此选项表示,正则表达式应该在实际应用时被编译,成为高度优化的格式,这样通常会大大提高匹配速度。不过这样会增加第一次使用时的编译时间,以及程序执行期间的内存占用。
如果正则表达式只需要应用一次,或者应用并不是很频繁,就没必要使用Regex Options.Compiled,因为即使这个Regex对象已经被回收,多占的内存也不会释放。不过如果正则表达式在对时间要求很高的场合应用,这个选项可能非常有价值。
在第237 页的例子中,使用这个选项减少了大约一半的测试时间。还可以参考关于编译到装配件(assembly)的讨论(☞434)。
RegexOptions.ECMAScript
此选项表示,正则表达式应该按照 ECMAScript(☞412)兼容方式来解析。如果不清楚ECMAScript,或者不需要兼容它,可以直接忽略。
RegexOptions.None
它表示“没有额外的选项”,在初始化RegexOptions变量时,如果需要指定选项,可以使用它。也可以用OR来连接其他希望使用的选项。
使用Regex对象
Using RegexObjects
在没有实际应用之前,Regex是没有意义的,下面的程序示范了实际的应用:

IsMatch方法把目标正则表达式应用到目标字符串,返回一个 Boolean值,表示匹配尝试是否成功,这里有个例子:

如果提供了offset(一个整数),则第一次尝试会从对应的偏移值开始。
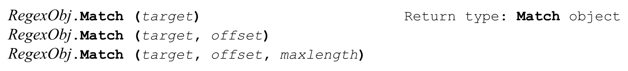
Match方法把正则表达式应用到目标字符串中,返回一个Match对象。通过这个Match对象可以查询匹配结果的信息(是否匹配成功,捕获的文本等等),初始化此正则表达式的“下一次”匹配。Match对象的细节见第427页。
如果提供了offset(一个整数),则第一次尝试会从对应的偏移值开始。
如果提供了maxlength参数,会进行特殊模式的匹配,从offset开始的字符开始计算,正则引擎会把maxlength长度的文本当作整个目标字符串,假设此范围之外的字符都不存在,所以此时「^」能够匹配原来的目标字符串中的offset位置,「$」能够匹配之后maxlength个字符的位置。同样,环视结构不能“感觉到”此范围之外的字符。这与提供offset有很大不同,如果只提供了offset,受影响的只是传动装置开始应用正则表达式的位置——正则引擎仍然能够“看到”完整的目标字符串。
下面表格中的例子比较了offset和maxlength的意义:
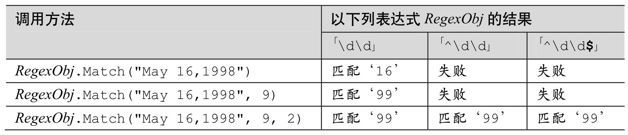
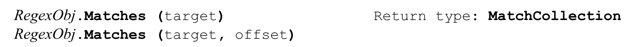
Matches方法类似Match方法,只是Matches方法返回一组Match对象,代表目标字符串中的所有匹配结果,而不是第一次的匹配结果。返回的对象为MatchCollection。
例如,初始化代码如下:
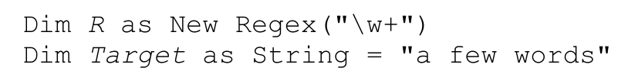
下面的程序:

运行结果是:
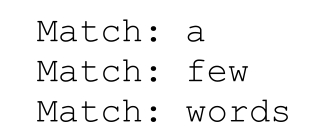
下面的程序输出同样的结果,它说明,MatchCollection 对象可以一次分配整个 Match-Collection。

作为比较,下面的代码也可以达到同样的效果,使用Match(而不是Matches)方法:

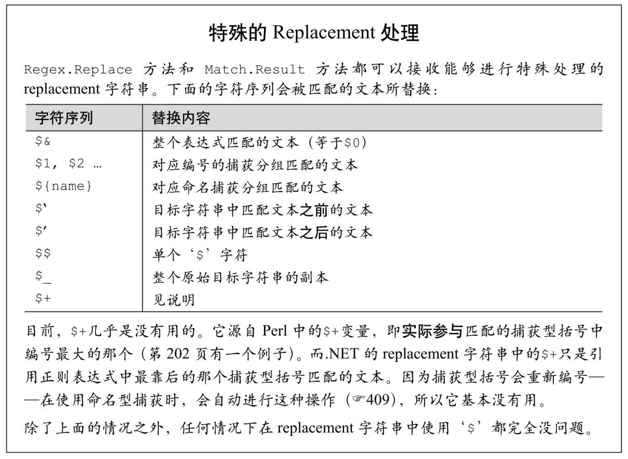
Replace方法会在目标字符串中进行查找-替换,返回(有可能已经变化的)字符串副本。它应用的是Regex对象的正则表达式,返回的不是Match对象,而是替换的结果。匹配的文本被什么内容替换,取决于replacement参数。replacement参数可以重载:它可以是一个字符串,也可以是MatchEvaluator委托(delegate)。如果replacement是一个字符串,它会按照下一页补充内容的说明进行处理。例如:

把每一个大写单词两边加上<B>…</B>。
如果设置了count,就只会进行count次替换(默认情况是进行所有的替换)。如果只希望替换第一次匹配,可以将count设置为1。如果我们知道只会有一次匹配,把count明确设置为 1 的效率会更高,因为不需要对字符串的其他部分进行查找和处理。把 count 设置为-1表示“所有匹配都必须替换”(它等价于没有设置count)。
如果设置了 offset(一个整数),则应用正则表达式时,目标字符串中对应数目的字符会被忽略。这些忽略的字符会直接被复制到结果中。
例如,这段代码会去掉多余的空白字符(也就是将连续的多个空白字符替换为单个空格):

‘some·····random·····spacing’被替换为‘some·random·spacing’。下面代码的结果相同,只是它会保留行开头任意数目的空白字符。
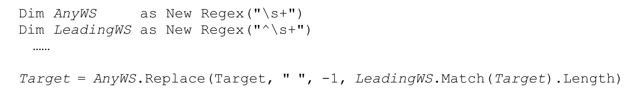
它会把‘····some···random·····spacing’转化为‘····some·random·spacing’,在查找和替换时,它使用LeadingWS匹配文本的长度作为偏移值(就是要跳过的字符数目)。这里用到了Match对象的简便特性,即LeadingWS.Match(Target)的Length属性(即便失败也没问题,此时Length的值为0,也就是说我们需要对整个目标字符串应用AnyWS)。
使用replacement委托
replacement 参数不只能用简单字符串,还可以是委托(delegate,简单说就是函数指针)。代理函数在每次匹配之后调用,生成作为replacement的文本。因为这个函数能够进行我们需要的任何处理,这种查找替换的机制功能非常强大。
委托的类型是 MatchEvaluator,每次匹配都会调用。它所引用的函数必须接受 Match 对象,进行你所需要的任何处理,返回作为replacement的文本。
做个比较,下面两段程序输出同样的结果:

两段程序都用<<…>>标注匹配的文本。使用委托的好处在于,在计算replacement时我们可以进行任意复杂的操作。下面的例子把摄氏温度转换为华氏温度:

如果目标字符串中包含‘Temp is 37C.’,它会被替换为‘Temp is 98.6F.’。

Split 方法将目标正则表达式应用于目标字符串,返回由各匹配分隔的字符串数组。如下面这个例子所示:
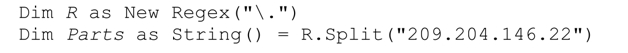
R.Split返回包含四个字符串的数组(‘209’、‘204’、‘146’和‘22’),它们由「.」在目标字符串中的三次匹配来分隔。
如果提供了count参数,则至多返回count个字符串(除非使用了捕获型括号,一会儿会说到这个问题)。如果没有提供count,Split返回所有匹配分隔的字符串。提供count的意思是,正则表达式可能在找到最终匹配之前停止应用,若果真如此,数组中最后的元素就是目标字符串中余下的部分。
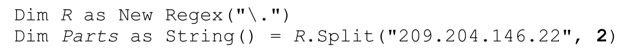
此时,Parts得到两个字符串,‘209’和‘204.146.22’。
如果设置了 offset(一个整数),则正则表达式的匹配尝试从对应编号的字符开始。前面的offset个字符会作为数组的第一个元素返回(如果设置了RegexOptions.RightToLeft,就会作为最后一个元素)。
在Split中使用捕获型括号
如果出现了任何形式的捕获型括号,数组中通常会包含额外的捕获文本(也有些情况下根本不会包含)。来看个简单的例子,要拆分字符串‘2006-12-31’或是‘04/12/2007’,你可能会使用「[-/]」:

结果包含 3 个元素(均为字符串)。不过,使用捕获型括号的正则表达式「([-/,])」,则会返回5个字符串:如果MyDate包含‘2006-12-31’,这5个元素是‘2006’、‘-’、‘12’、‘-’、‘31’。多出来的‘-’是每次捕获的$1。
如果有多组捕获型括号,它们会按照编号排序(也就是说,所有的命名捕获跟随在未命名捕获之后☞409)。
只要实际参与了匹配捕获型括号的捕获型括号,都会包含在 Split的结果中。不过,目前的.NET 有一个bug,即如果某组捕获型括号没有参与匹配,它和所有编号更靠后的捕获型括号都不会包含在返回的结果中。
来看个极端点的例子,如果需要以左右可能出现空白字符的逗号作为分隔,而且空白字符必须包含在返回结果中。用「(s+)?,(s+)?」分隔‘this·,··that’,得到四个字符串‘this’、‘·’、‘··’和‘that’。但是,如果目标字符串为‘this,·that’,因为第一组捕获型括号没有参与最终匹配,所有的捕获型括号都不包含在最终结果中,所以只会返回两个字符串‘this’和‘that’。无法预知到底会返回多少字符串,是当前版本的.NET 的一个重大问题。
在这个例子中,我们可以使用「(s*),(s*)」绕开这个问题(这样两个分组一定都能参与匹配)。不过,更复杂的表达式就没这么容易改写了。

这几个方法容许用户查询对应编号(可以用数字,如果是命名捕获,也可以用名字)的捕获型分组的信息。它们引用的不是特定的匹配内容,只是正则表达式中存在的分组的名字和编号。下面的补充内容说明了使用方法。

这几个方法容许用户查询 Regex 对象本身(而不是将此对象应用到字符串上)的信息。ToString()方法返回正则表达式构造函数接收的字符串。RightToLeft 属性返回一个Boolean 值,表明它是否启用了 RegexOptions.RightToLeft选项。Options属性返回与此正则表达式相关的RegexOptions。下面说明了各个选项的值,把对应选项的值相加,就得到返回结果。

这里没有128,因为它用于微软内部的调试,没有出现在最终产品中。
补充内容给出了这些方法的应用实例。
使用Match对象
Using MatchObjects
有三种方法创建Match对象:Regex的Match方法、静态函数Regex.Match(稍后介绍)和Match对象自己的NextMatch方法。它封装某个正则表达式的单次应用的所有相关信息。其属性和方法如下:
MatchObj.Success
返回一个 Boolean 值,表示匹配是否成功。如果不成功,则返回一个静态的 Match.Empty对象(☞433)。
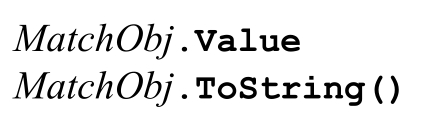
它返回实际匹配文本的副本。

MatchObj.Length
返回实际匹配文本的长度。
MatchObj.Index
返回一个整数,显示匹配文本在目标中的起始位置。编号从 0 开始,所以这个数字表示从目标字符串的开头(最左边)到匹配文本的开头(最左边)的长度。即使在创建 Match对象时设置了RegexOptions.RightToLeft,回值也不会变化。
MatchObj.Groups
此属性是一个GroupCollection对象,其中封装了多个Group对象。它是一个普通的集合类(collection),包含了Count和Item属性,但是最常用的办法还是按照索引值访问,取出对应的Group对象。例如,M.Groups(3)对应第3组捕获型括号,M.Groups("HostName")对应命名捕获“HostName”(正则表达式中的「(?<HostName>…)」)。
在C#中,使用M.Groups[3]和M.Groups["HostName"]。
编号为0的分组表示整个正则表达式匹配的所有文本。MatchObj.Groups(0).Value等价于MatchObj.Value。
MatchObj.NextMatch
NextMatch()方法将正则表达式应用于目标字符串,寻找下一个匹配,返回新的 Match 对象。
MatchObj.Result(string)
string是一个特殊的序列,按照第424页补充内容的介绍来处理,返回结果文本。这里有个简单例子:

下面的程序可以依次匹配内容左侧和右侧文本的副本

调试时可能需要显示某些和行有关的信息:
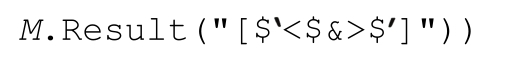
如果把「d+」应用到‘May 16,1998’得到的Match对象,返回的是‘May <16>,1998’,这清楚地体现了匹配文本。
MatchObj.Synchronized
它返回一个新的,与当前Match完全一样的Match对象,只是它适合于多线程使用。MatchObj.Captures
Captures属性并不常用,参见第437页的介绍。
使用Group对象
Using GroupObjects
Group对象包含一组捕获型括号(如果编号是0,就表示整个匹配)的信息。其属性和方法如下:
GroupObj.Success
它返回一个Boolean值,表明此分组是否参与了匹配。并不是所有的分组都必须“参与”成功的全局匹配。如果「(this)|(that)」能够成功匹配,肯定有一个分组能参与匹配,另一个不能。第139页的脚注中有另一个例子。
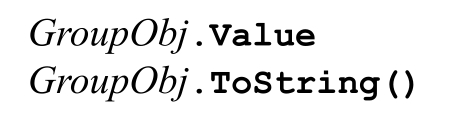
它们都返回本分组捕获文本的副本。如果匹配不成功,则返回空字符串。
GroupObj.Length
返回本分组捕获文本的长度。如果匹配不成功,则返回0。
GroupObj.Index
返回一个整数,表示本分组捕获的文本在目标字符串中的位置。编号从 0 开始,所以它就是从目标字符串的开头(最左边)到捕获文本的开头(最左边)的长度(即使在创建Match对象时设置了RegexOptions.RightToLeft,结果仍然不变)。
GroupObj.Captures
请参考第437页Group对象的Capture属性。