附录B 参考资料
04-13Ctrl+D 收藏本站
本书这部分总结了C语言的基本特性和一些特定主题的详细内容,包括以下9个部分。
参考资料I:补充阅读
参考资料II:C运算符
参考资料III:基本类型和存储类别
参考资料IV:表达式、语句和程序流
参考资料V:新增了C99和C11的标准ANSI C库
参考资料VI:扩展的整数类型
参考资料VII:扩展的字符支持
参考资料VIII:C99/C11数值计算增强
参考资料IX:C与C++的区别
B.1 参考资料I:补充阅读
如果想了解更多C语言和编程方面的知识,下面提供的资料会对你有所帮助。
B.1.1 在线资源
C程序员帮助建立了互联网,而互联网可以帮助你学习C。互联网时刻都在发展、变化,这里所列的资源只是在撰写本书时可用的资源。当然,你可以在互联网中找到其他资源。
如果有一些与C语言相关的问题或只是想扩展你的知识,可以浏览C FAQ(常见问题解答)的站点:
c-faq.com
但是,这个站点的内容主要涵盖到C89。
如果对C库有疑问,可以访问这个站点获得信息:www.acm.uiuc.edu/webmonkeys/book/c_guide/index.html。
这个站点全面讨论指针:pweb.netcom.com/~tjensen/ptr/pointers.htm。
还可以使用谷歌和雅虎的搜索引擎,查找相关文章和站点:
www.google.com
search.yahoo.com
www.bing.com
可以使用这些站点中的高级搜索特性来优化你要搜索的内容。例如,尝试搜索C教程。
你可以通过新闻组(newsgroup)在网上提问。通常,新闻组阅读程序通过你的互联网服务提供商提供的账号访问新闻组。另一种访问方法是在网页浏览器中输入这个地址:http://groups.google.com。
你应该先花时间阅读新闻组,了解它涵盖了哪些主题。例如,如果你对如何使用C语言完成某事有疑问,可以试试这些新闻组:
comp.lang.c
comp.lang.c.moderated
可以在这里找到愿意提供帮助的人。你所提的问题应该与标准 C 语言相关,不要在这里询问如何在UNIX系统中获得无缓冲输入之类的问题。特定平台都有专门的新闻组。最重要的是,不要询问他们如何解决家庭作业中的问题。
如果对C标准有疑问,试试这个新闻组:comp.std.c。但是,不要在这里询问如何声明一个指向三维数组的指针,这类问题应该到另一个新闻组:comp.lang.c。
最后,如果对C语言的历史感兴趣,可以浏览下C创始人Dennis Ritchie的站点,其中1993年中有一篇文章介绍了C的起源和发展:cm.bell-labs.com/cm/cs/who/dmr/chist.html。
B.1.2 C语言书籍
Feuer,Alan R.The C Puzzle Book,Revised Printing Upper Saddle River, NJ: Addison-WesleyProfessional, 1998。这本书包含了许多程序,可以用来学习,推测这些程序应输出的内容。预测输出对测试和扩展 C 的理解很有帮助。本书也附有答案和解释。
Upper Saddle River, NJ: Addison-WesleyProfessional, 1998。这本书包含了许多程序,可以用来学习,推测这些程序应输出的内容。预测输出对测试和扩展 C 的理解很有帮助。本书也附有答案和解释。
Kernighan, Brian W.and Dennis M.Ritchie.The C Programming Language, Second Edition .Englewood Cliffs, NJ: Prentice Hall, 1988。第1本C语言书的第2版(注意,作者Dennis Ritchie是C的创始者)。本书的第1版给出了K&R C的定义,许多年来它都是非官方的标准。第2版基于当时的ANSI草案进行了修订,在编写本书时该草案已成为了标准。本书包含了许多有趣的例子,但是它假定读者已经熟悉了系统编程。
Koenig,Andrew.C Traps and Pitfalls.Reading,MA:Addison-Wesley,1989。本书的中文版《C陷阱与缺陷》已由人民邮电出版社出版。
Summit,Steve.C Programming FAQs.Reading,MA:Addison-Wesley,1995。这本书是互联网FAQ的延伸阅读版本。
B.1.3 编程书籍
Kernighan, Brian W.and P.J.Plauger.The Elements of Programming Style, Second Edition .NewYork:McGraw-Hill, 1978。这本短小精悍的绝版书籍,历经岁月却无法掩盖其真知灼见。书中介绍了要编写高效的程序,什么该做,什么不该做。
Knuth,Donald E.The Art of Computer Programming, 第1卷(基本算法),Third Edition.Reading,MA:Addison-Wesley, 1997。这本经典的标准参考书非常详尽地介绍了数据表示和算法分析。第2卷(半数学算法,1997)探讨了伪随机数。第 3 卷(排序和搜索,1998)介绍了排序和搜索,以伪代码和汇编语言的形式给出示例。
Sedgewick, Robert.Algorithms in C, Parts 1-4:Fundamentals,Data Structures,Sorting,Searching,Third Edition.Reading, MA: Addison-Wesley Professional, 1997。顾名思义,这本书介绍了数据结构、排序和搜索。本书中文版《C算法(第1卷)基础、数据结构、排序和搜索(第3版)》已由人民邮电出版社出版。
B.1.4 参考书籍
Harbison, Samuel P.and Steele, Guy L.C: A Reference Manual, Fifth Edition.Englewood Cliffs,NJ:Prentice Hall, 2002。这本参考手册介绍了C语言的规则和大多数标准库函数。它结合了C99,提供了许多例子。《C语言参考手册(第5版)(英文版)》已由人民邮电出版社出版。
Plauger,P.J.The Standard C Library.Englewood Cliffs,NJ:Prentice Hall,1992。这本大型的参考手册介绍了标准库函数,比一般的编译器手册更详尽。
The International C Standard.ISO/IEC 9899:2011。在撰写本书时,可以花285美元从www.ansi.org下载该标准的电子版,或者花238欧元从IEC下载。别指望通过这本书学习C语言,因为它并不是一本学习教程。这是一句有代表性的话,可见一斑:“如果在一个翻译单元中声明一个特定标识符多次,在该翻译单元中都可见,那么语法可根据上下文无歧义地引用不同的实体”。
B.1.5 C++书籍
Prata,Stephen.C++Primer Plus,Sixth Edition.Upper Saddle River,NJ:Addison-Wesley,2012。本书介绍了C++语言(C++11标准)和面向对象编程的原则。
Stroustrup, Bjarne.The C++Programming Language, Fourth Edition.Reading, MA: Addison-Wesley, 2013。本书由C++的创始人撰写,介绍了C++11标准。
B.2 参考资料II:C运算符
C语言有大量的运算符。表B.2.1按优先级从高至低的顺序列出了C运算符,并给出了其结合性。除非特别指明,否则所有运算符都是二元运算符(需要两个运算对象)。注意,一些二元运算符和一元运算符的表示符号相同,但是其优先级不同。例如,*(乘法运算符)和*(间接运算符)。表后面总结了每个运算符的用法。
表B.2.1 C运算符
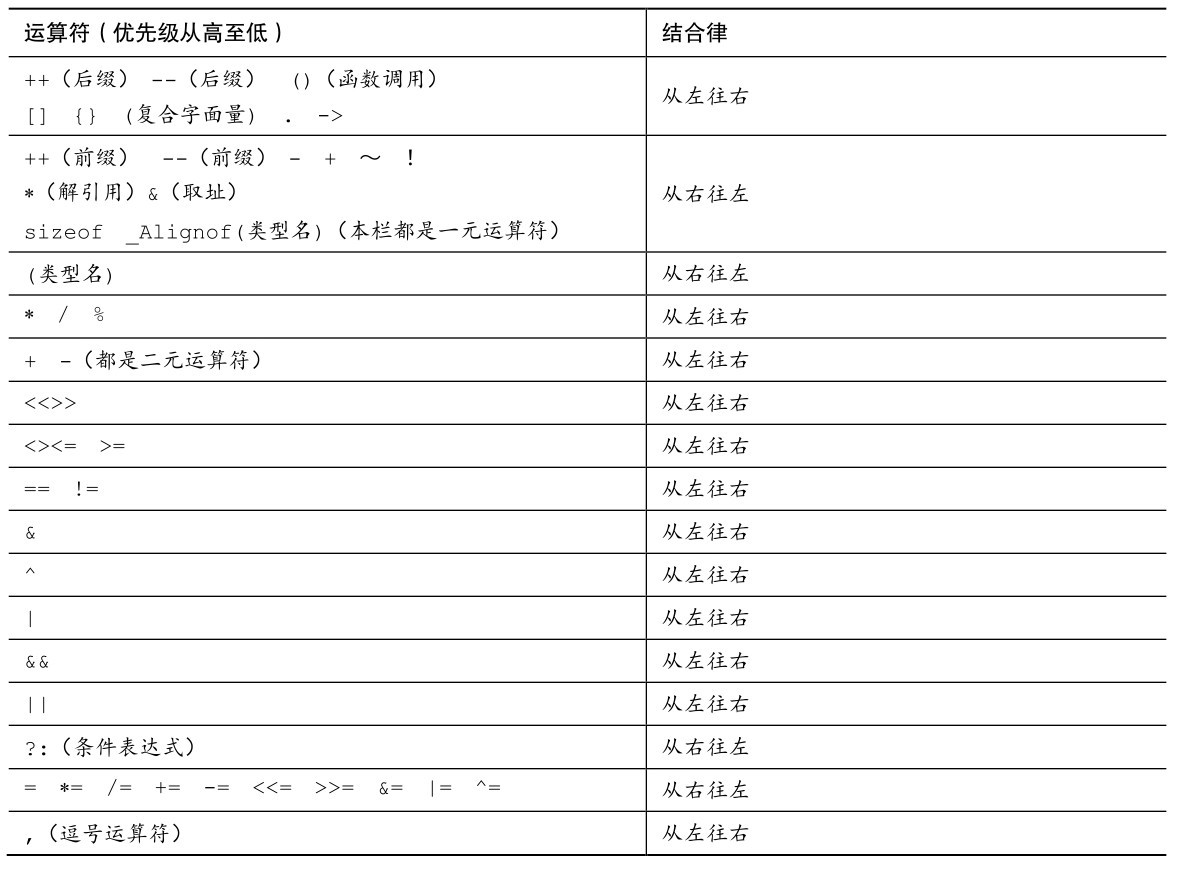
B.2.1 算术运算符
+ 把右边的值加到左边的值上。
+ 作为一元运算符,生成一个大小和符号都与右边值相同的值。
- 从左边的值中减去右边的值。
- 作为一元运算符,生成一个与右边值大小相等符号相反的值。
* 把左边的值乘以右边的值。
/ 把左边的值除以右边的值;如果两个运算对象都是整数,其结果要被截断。
% 得左边值除以右边值时的余数
++ 把右边变量的值加1(前缀模式),或把左边变量的值加1(后缀模式)。
-- 把右边变量的值减1(前缀模式),或把左边变量的值减1(后缀模式)。
B.2.2 关系运算符
下面的每个运算符都把左边的值与右边的值相比较。
<小于
<= 小于或等于
== 等于
>= 大于或等于
>大于
!= 不等于
关系表达式
简单的关系表达式由关系运算符及其两侧的运算对象组成。如果关系为真,则关系表达式的值为 1;如果关系为假,则关系表达式的值为0。下面是两个例子:
5 > 2 关系为真,整个表达式的值为1。
(2 + a) == a 关系为假,整个表达式的值为0。
B.2.3 赋值运算符
C语言有一个基本赋值运算符和多个复合赋值运算符。=运算符是基本的形式:
= 把它右边的值赋给其左边的左值。
下面的每个赋值运算符都根据它右边的值更新其左边的左值。我们使用R-H表示右边,L-R表示左边。
+= 把左边的变量加上右边的量,并把结果储存在左边的变量中。
-= 从左边的变量中减去右边的量,并把结果储存在左边的变量中。
*= 把左边的变量乘以右边的量,并把结果储存在左边的变量中。
/= 把左边的变量除以右边的量,并把结果储存在左边的变量中。
%= 得到左边量除以右边量的余数,并把结果储存在左边的变量中。
&= 把L-H & R-H的值赋给左边的量,并把结果储存在左边的变量中。
|= 把L-H | R-H的值赋给左边的量,并把结果储存在左边的变量中。
^= 把L-H ^ R-H的值赋给左边的量,并把结果储存在左边的变量中。
>>= 把L-H >> R-H的值赋给左边的量,并把结果储存在左边的变量中。
<<= 把L-H << R-H的值赋给左边的量,并把结果储存在左边的变量中。
示例
rabbits *= 1.6;与rabbits = rabbits * 1.6效果相同。
B.2.4 逻辑运算符
逻辑运算符通常以关系表达式作为运算对象。!运算符只需要一个运算对象,其他运算符需要两个运算对象,运算符左边一个,右边一个。
&& 逻辑与
|| 逻辑或
! 逻辑非
1.逻辑表达式
当且仅当两个表达式都为真时,expresson1 && expresson 2的值才为真。
两个表达式中至少有一个为真时,expresson 1 && expresson 2的值就为真。
如果expresson的值为假,则!expresson为真,反之亦然。
2.逻辑表达式的求值顺序
逻辑表达式的求值顺序是从左往右。当发现可以使整个表达式为假的条件时立即停止求值。
3.示例
6 > 2 && 3 == 3 为真。
!(6 > 2 && 3 == 3) 为假。
x != 0 && 20/x < 5 只有在x是非零时才会对第2个表达式求值。
B.2.5 条件运算符
?:有3个运算对象,每个运算对象都是一个表达式:expression1 ? expression2 : expression3
如果expression1为真,则整个表达式的值等于expression2的值;否则,等于expression3的值。
示例
(5 > 3) ? 1 : 2的值为1。
(3 > 5) ? 1 : 2的值为2。
(a > b) ? a : b的值是a和b中较大者
B.2.6 与指针有关的运算符
&是地址运算符。当它后面是一个变量名时,&给出该变量的地址。
*是间接或解引用运算符。当它后面是一个指针时,*给出储存在指针指向地址中的值。
示例
&nurse是变量nurse的地址:
nurse = 22;
ptr = &nurse; /* 指向nurse的指针 */
val = *ptr;
以上代码的效果是把22赋给val。
B.2.7 符号运算符
-是负号,反转运算对象的符号。
+ 是正号,不改变运算对象的符号。
B.2.8 结构和联合运算符
结构和联合使用一些运算符标识成员。成员运算符与结构和联合一起使用,间接成员运算符与指向结构或联合的指针一起使用。
1.成员运算符
成员运算符(.)与结构名或联合名一起使用,指定结构或联合中的一个成员。如果name是一个结构名,member是该结构模板指定的成员名,那么name.member标识该结构中的这个成员。name.member的类型就是被指定member的类型。在联合中也可以用相同的方式使用成员运算符。
示例
struct {
int code;
float cost;
} item;
item.code = 1265;
上面这条语句把1265赋给结构变量item的成员code。
2.间接成员运算符(或结构指针运算符)
间接成员运算符(->)与一个指向结构或联合的指针一起使用,标识该结构或联合的一个成员。假设ptrstr是一个指向结构的指针,member是该结构模板指定的成员,那么ptrstr->member标识了指针所指向结构的这个成员。在联合中也可以用相同的方式使用间接成员运算符。
示例
struct {
int code;
float cost;
} item, * ptrst;
ptrst = &item;
ptrst->code = 3451;
以上程序段把3451赋给结构item的成员code。下面3种写法是等效的:
ptrst->code item.code(*ptrst).code
B.2.9 按位运算符
下面所列除了~,都是按位运算符。
~ 是一元运算符,它通过翻转运算对象的每一位得到一个值。
& 是逻辑与运算符,只有当两个运算对象中对应的位都为1时,它生成的值中对应的位才为1。
| 是逻辑或运算符,只要两个运算对象中对应的位有一位为1,它生成的值中对应的位就为1。
^ 是按位异或运算符,只有两个运算对象中对应的位中只有一位为1(不能全为1),它生成的值中对应的位才为1。
<< 是左移运算符,把左边运算对象中的位向左移动得到一个值。移动的位数由该运算符右边的运算对象确定,空出的位用0填充。
>> 是右移运算符,把左边运算对象中的位向右移动得到一个值。移动的位数由该运算符右边的运算对象确定,空出的位用0填充。
示例
假设有下面的代码:
int x = 2;
int y = 3;
x & y的值为2,因为x和y的位组合中,只有第1位均为1。而y << x的值为12,因为在y的位组合中,3的位组合向左移动两位,得到12。
B.2.10 混合运算符
sizeof给出它右边运算对象的大小,单位是char的大小。通常,char类型的大小是1字节。运算对象可以圆括号中的类型说明符,如sizeof(float),也可以是特定的变量名、数组名等,如sizeof foo。sizeof表达式的类型是size_t。
_Alignof(C11)给出它的运算对象指定类型的对齐要求。一些系统要求以特定值的倍数在地址上储存特定类型,如4的倍数。这个整数就是对齐要求。
(类型名)是强制类型转换运算符,它把后面的值转换成圆括号中关键字指定的类型。例如,(float)9把整数9转换成浮点数9.0。
,是逗号运算符,它把两个表达式链接成一个表达式,并保证先对最左端的表达式求值。整个表达式的值是最右边表达式的值。该运算符通常在for循环头中用于包含更多的信息。
示例
for (step = 2, fargo = 0; fargo < 1000; step *= 2)
fargo += step;
B.3 参考资料III:基本类型和存储类别
B.3.1 总结:基本数据类型
C语言的基本数据类型分为两大类:整数类型和浮点数类型。不同的种类提供了不同的范围和精度。
1.关键字
创建基本数据类型要用到8个关键字:int、long、short、unsigned、char、float、double、signed(ANSI C)。
2.有符号整数
有符号整数可以具有正值或负值。
int是所有系统中基本整数类型。
long或long int可储存的整数应大于或等于int可储存的最大数;long至少是32位。
short或short int整数应小于或等于int可储存的最大数;short至少是16位。通常,long比short大。例如,在PC中的C DOS编译器提供16位的short和int、32位的long。这完全取决于系统。
C99标准提供了long long类型,至少和long一样大,至少是64位。
3.无符号整数
无符号整数只有 0 和正值,这使得该类型能表示的正数范围更大。在所需的类型前面加上关键字unsigned:unsigned int、unsigned long、unsigned short、unsigned long long。单独的unsigned相当于unsigned int。
4.字符
字符是如A、&、+这样的印刷符号。根据定义,char类型的变量占用1字节的内存。过去,char类型的大小通常是8位。然而,C在处理更大的字符集时,char类型可以是16位,或者甚至是32位。
这种类型的关键字是char。一些实现使用有符号的char,但是其他实现使用无符号的char。ANSI C允许使用关键字signed 和 unsigned指定所需类型。从技术层面上看,char、unsigned char和signed char是3种不同的类型,但是char类型与其他两种类型的表示方法相同。
5.布尔类型(C99)
_Bool是C99新增的布尔类型。它一个无符号整数类型,只能储存0(表示假)或1(表示真)。包含stdbool.c头文件后,可以用bool表示_Bool、ture表示1、false表示0,让代码与C++兼容。
6.实浮点数和复浮点数类型
C99识别两种浮点数类型:实浮点数和复浮点数。浮点类型由这两种类型构成。
实浮点数可以是正值或负值。C识别3种实浮点类型。
float是系统中的基本浮点类型。它至少可以精确表示6位有效数字,通常float为32位。
double(可能)表示更大的浮点数。它能表示比 float更多的有效数字和更大的指数。它至少能精确表示10位有效数字。通常,double为64位。
long double(可能)表示更大的浮点数。它能表示比double更多的有效数字和更大的指数。
复数由两部分组成:实部和虚部。C99 规定一个复数在内部用一个有两个元素的数组表示,第 1 个元素表示实部,第2个元素表示虚部。有3种复浮点数类型。
float _Complex表示实部和虚部都是float类型的值。
double _Complex表示实部虚部都是double类型的值。
long double _Complex表示实部和虚部都是long double类型的值。
每种情况,前缀部分的类型都称为相应的实数类型(corresponding real type)。例如,double是double_Complex相应的实数类型。
C99中,复数类型在独立环境中是可选的,这样的环境中不需要操作系统也可运行C程序。在C11中,复数类型在独立环境和主机环境都是可选的。
有 3 种虚数类型。它们在独立环境中和主机环境中(C 程序在一种操作系统下运行的环境)都是可选的。虚数只有虚部。这3种类型如下。
float _Imaginary表示虚部是float类型的值。
double _Imaginary表示虚部是double类型的值。
long double _Imaginary表示虚部是long double类型的值。
可以用实数和I值来初始化复数。I定义在complex.h头文件中,表示i(即-1的平方根)。
#include <complex.h>// I定义在该头文件中
double _Complex z = 3.0;// 实部 = 3.0,虚部 = 0
double _Complex w = 4.0 * I; // 实部 = 0.0,虚部 = 4.0
double Complex u = 6.0 – 8.0 * I; //实部= 6.0,虚部 = -8.0
前面章节讨论过,complex.h库包含一些返回复数实部和虚部的函数。
B.3.2 总结:如何声明一个简单变量
1.选择所需的类型。
2.选择一个合适的变量名。
3.使用这种声明格式:type-specifiervariable-name;
type-specifier由一个或多个类型关键字组成,下面是一些例子:
int erest;
unsigned short cash;
4.声明多个同类型变量时,使用逗号分隔符隔开各变量名:
char ch, init, ans;
5.可以在声明的同时初始化变量:
float mass = 6.0E24;
总结:存储类别
关键字:auto、extern、static、register、_Thread_local(C11)
一般注解:
变量的存储类别取决于它的作用域、链接和存储期。存储类别由声明变量的位置和与之关联的关键字决定。定义在所有函数外部的变量具有文件作用域、外部链接、静态存储期。声明在函数中的变量是自动变量,除非该变量前面使用了其他关键字。它们具有块作用域、无链接、自动存储期。以static关键字声明在函数中的变量具有块作用域、无链接、静态存储期。以static关键字声明在函数外部的变量具有文件作用域、内部链接、静态存储期。
C11 新增了一个存储类别说明符:_Thread_local。以该关键字声明的对象具有线程存储期,意思是在线程中声明的对象在该线程运行期间一直存在,且在线程开始时被初始化。因此,这种对象属于线程私有。
属性:
下面总结了这些存储类别的属性:

续表
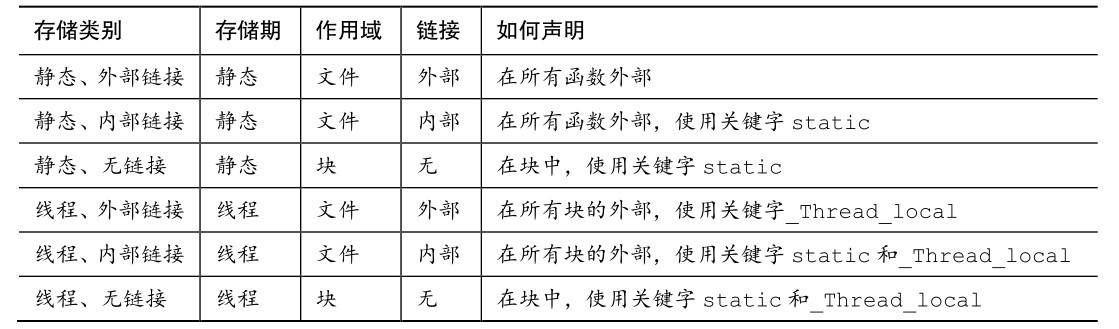
注意,关键字extern只能用来再次声明在别处已定义过的变量。在函数外部定义变量,该变量具有外部链接属性。
除了以上介绍的存储类别,C 还提供了动态分配内存。这种内存通过调用 malloc函数系列中的一个函数来分配。这种函数返回一个可用于访问内存的指针。调用 free函数或结束程序可以释放动态分配的内存。任何可以访问指向该内存指针的函数均可访问这块内存。例如,一个函数可以把这个指针的值返回给另一个函数,那么另一个函数也可以访问该指针所指向的内存。
B.3.3 总结:限定符
关键字
使用下面关键字限定变量:
const、volatile、restrict
一般注释
限定符用于限制变量的使用方式。不能改变初始化以后的 const 变量。编译器不会假设 volatile变量不被某些外部代理(如,一个硬件更新)改变。restrict 限定的指针是访问它所指向内存的唯一方式(在特定作用域中)。
属性
const int joy = 101;声明创建了变量joy,它的值被初始化为101。
volatile unsigned int incoming;声明创建了变量incoming,该变量在程序中两次出现之间,其值可能会发生改变。
const int * ptr = &joy;声明创建了指针ptr,该指针不能用来改变变量joy的值,但是它可以指向其他位置。
int * const ptr = &joy;声明创建了指针ptr,不能改变该指针的值,即ptr只能指向joy,但是可以用它来改变joy的值。
void simple (const char * s);声明表明形式参数s被传递给simple的值初始化后,simple不能改变s指向的值。
void supple(int * const pi);与void supple(int pi[const]);等价。这两个声明都表明supple函数不会改变形参pi。
void interleave(int * restrict p1, int * restrict p2, int n);声明表明p1和p2是访问它们所指向内存的唯一方法,这意味着这两个块不能重叠。
B.4 参考资料IV:表达式、语句和程序流
B.4.1 总结:表达式和语句
在C语言中,对表达式可以求值,通过语句可以执行某些行为。
表达式
表达式由运算符和运算对象组成。最简单的表达式是一个常量或一个不带运算符的变量,如 22 或beebop。稍复杂些的例子是55 + 22和vap = 2 * (vip + (vup = 4))。
语句
大部分语句都以分号结尾。以分号结尾的表达式都是语句,但这样的语句不一定有意义。语句分为简单语句和复合语句。简单语句以分号结尾,如下所示:
toes = 12; // 赋值表达式语句
printf("%d\n", toes); // 函数调用表达式语句
; //空语句,什么也不做
(注意,在C语言中,声明不是语句。)
用花括号括起来的一条或多条语句是复合语句或块。如下面的while语句所示:
while (years < 100)
{
wisdom = wisdom + 1;
printf("%d %d\n", years, wisdom);
years = years + 1;
}
B.4.2 总结:while语句
关键字
while语句的关键字是while。
一般注释
while语句创建了一个循环,在expression为假之前重复执行。while语句是一个入口条件循环,在下一轮迭代之前先确定是否要再次循环。因此可能一次循环也不执行。statement可以是一个简单语句或复合语句。
形式
while ( expression )
statement
当expression为假(或0)之前,重复执行statement部分。
示例
while (n++ < 100)
printf(" %d %d\n",n, 2*n+1);
while (fargo < 1000)
{
fargo = fargo + step;
step = 2 * step;
}
B.4.3 总结:for语句
关键字
for语句的关键字是for。
一般注释
for语句使用3个控制表达式控制循环过程,分别用分号隔开。initialize表达式在执行for语句之前只执行一次;然后对test表达式求值,如果表达式为真(或非零),执行循环一次;接着对update表达式求值,并再次检查test表达式。for语句是一种入口条件循环,即在执行循环之前就决定了是否执行循环。因此,for循环可能一次都不执行。statement部分可以是一条简单语句或复合语句。
形式:
for ( initialize; test; update )
statement
在test为假或0之前,重复执行statement部分。
C99允许在for循环头中包含声明。变量的作用域和生命期被限制在for循环中。
示例:
for (n = 0; n < 10 ; n++)
printf(" %d %d\n", n, 2 * n + 1);
for (int k = 0; k < 10 ; ++k) // C99
printf("%d %d\n", k, 2 * k+1);
B.4.4 总结:do while语句
关键字
do while语句的关键字是do和while。
一般注解:
do while语句创建一个循环,在expression为假或0之前重复执行循环体中的内容。do while语句是一种出口条件循环,即在执行完循环体后才根据测试条件决定是否再次执行循环。因此,该循环至少必须执行一次。statement部分可是一条简单语句或复合语句。
形式:
do
statement
while ( expression );
在test为假或0之前,重复执行statement部分。
示例:
do
scanf("%d", &number);
while (number != 20);
B.4.5 总结:if语句
小结:用if语句进行选择
关键字:if、else
一般注解:
下面各形式中,statement可以是一条简单语句或复合语句。表达式为真说明其值是非零值。
形式1:
if (expression)
statement
如果expression为真,则执行statement部分。
形式2:
if (expression)
statement1
else
statement2
如果expression为真,执行statement1部分;否则,执行statement2部分。
形式3:
if (expression1)
statement1
else if (expression2)
statement2
else
statement3
如果expression1为真,执行statement1部分;如果expression2为真,执行statement2部分;否则,执行statement3部分。
示例:
if (legs == 4)
printf("It might be a horse.\n");
else if (legs > 4)
printf("It is not a horse.\n");
else /* 如果legs < 4 */
{
legs++;
printf("Now it has one more leg.\n");
}
B.4.6 带多重选择的switch语句
关键字:switch
一般注解:
程序控制根据expression的值跳转至相应的case标签处。然后,程序流执行剩下的所有语句,除非执行到break语句进行重定向。expression和case标签都必须是整数值(包括char类型),标签必须是常量或完全由常量组成的表达式。如果没有case标签与expression的值匹配,控制则转至标有default的语句(如果有的话);否则,控制将转至紧跟在switch语句后面的语句。控制转至特定标签后,将执行switch语句中其后的所有语句,除非到达switch末尾,或执行到break语句。
形式:
switch ( expression )
{
case label1 : statement1//使用break跳出switch
case label2 : statement2
default : statement3
}
可以有多个标签语句,default语句可选。
示例:
switch (value)
{
case 1 : find_sum(ar, n);
break;
case 2 : show_array(ar, n);
break;
case 3 : puts("Goodbye!");
break;
default : puts("Invalid choice, try again.");
break;
}
switch (letter)
{
case 'a' :
case 'e' : printf("%d is a vowel\n", letter);
case 'c' :
case 'n' : printf("%d is in \"cane\"\n", letter);
default : printf("Have a nice day.\n");
}
如果letter的值是'a'或'e',就打印这3条消息;如果letter的值是'c'或'n',则只打印后两条消息;letter是其他值时,值打印最后一条消息。
B.4.7 总结:程序跳转
关键字:break、continue、goto
一般注解:
这3种语句都能使程序流从程序的一处跳转至另一处。
break语句:
所有的循环和switch语句都可以使用break语句。它使程序控制跳出当前循环或switch语句的剩余部分,并继续执行跟在循环或switch后面的语句。
示例:
while ((ch = getchar) != EOF)
{
putchar(ch);
if (ch == ' ')
break;// 结束循环
chcount++;
}
continue语句:
所有的循环都可以使用continue语句,但是switch语句不行。continue语句使程序控制跳出循环的剩余部分。对于while或for循环,程序执行到continue语句后会开始进入下一轮迭代。对于do while循环,对出口条件求值后,如有必要会进入下一轮迭代。
示例:
while ((ch = getchar) != EOF)
{
if (ch == ' ')
continue; // 跳转至测试条件
putchar(ch);
chcount++;
}
以上程序段打印用户输入的内容并统计非空格字符
goto语句:
goto语句使程序控制跳转至相应标签语句。冒号用于分隔标签和标签语句。标签名遵循变量命名规则。标签语句可以出现在goto的前面或后面。
形式:
goto label ;

label : statement
示例:
top : ch = getchar;
if (ch != 'y')
goto top;

B.5 参考资料V:新增C99和C11的ANSI C库
ANSI C库把函数分成不同的组,每个组都有相关联的头文件。本节将概括地介绍库函数,列出头文件并简要描述相关的函数。文中会较详细地介绍某些函数(例如,一些I/O函数)。欲了解完整的函数说明,请参考具体实现的文档或参考手册,或者试试这个在线参考:http://www.acm.uiuc.edu/webmonkeys/book/c_guide/。
B.5.1 断言:assert.h
assert.h 头文件中把 assert定义为一个宏。在包含 assert.h 头文件之前定义宏标识符NDEBUG,可以禁用assert宏。通常用一个关系表达式或逻辑表达式作为assert的参数,如果运行正常,那么程序在执行到该点时,作为参数的表达式应该为真。表B.5.1描述了assert宏。
表B.5.1 断言宏

C11新增了static_assert宏,展开为_Static_assert。_Static_assert是一个关键字,被认为是一种声明形式。它以这种方式提供一个编译时检查:
_Static_assert( 常量表达式,字符串字面量);
如果对常量表达式求值为0,编译器会给出一条包含字符串字面量的错误消息;否则,没有任何效果。
B.5.2 复数:complex.h(C99)
C99 标准支持复数计算,C11 进一步支持了这个功能。实现除提供_Complex 类型外还可以选择是否提供_Imaginary类型。在C11中,可以选择是否提供这两种类型。C99规定,实现必须提供_Complex类型,但是_Imaginary类型为可选,可以提供或不提供。附录B的参考资料VIII中进一步讨论了C如何支持复数。complex.h头文件中定义了表B.5.2所列的宏。
表B.5.2 complex.h宏

对于实现复数方面,C和C++不同。C通过complex.h头文件支持,而C++通过complex头文件支持。而且,C++使用类来定义复数类型。
可以使用STDC CX_LIMITED_RANGE编译指令来表明是使用普通的数学公式(设置为on时),还是要特别注意极值(设置为off时):
#include <complex.h>
#pragma STDC CX_LIMITED_RANGE on
库函数分为3种:double、float、long double。表B.5.3列出了double版本的函数。float和long double版本只需要在函数名后面分别加上f和l。即csinf就是csin的float版本,而csinl是csin的long double版本。另外要注意,角度的单位是弧度。
表B.5.3 复数函数
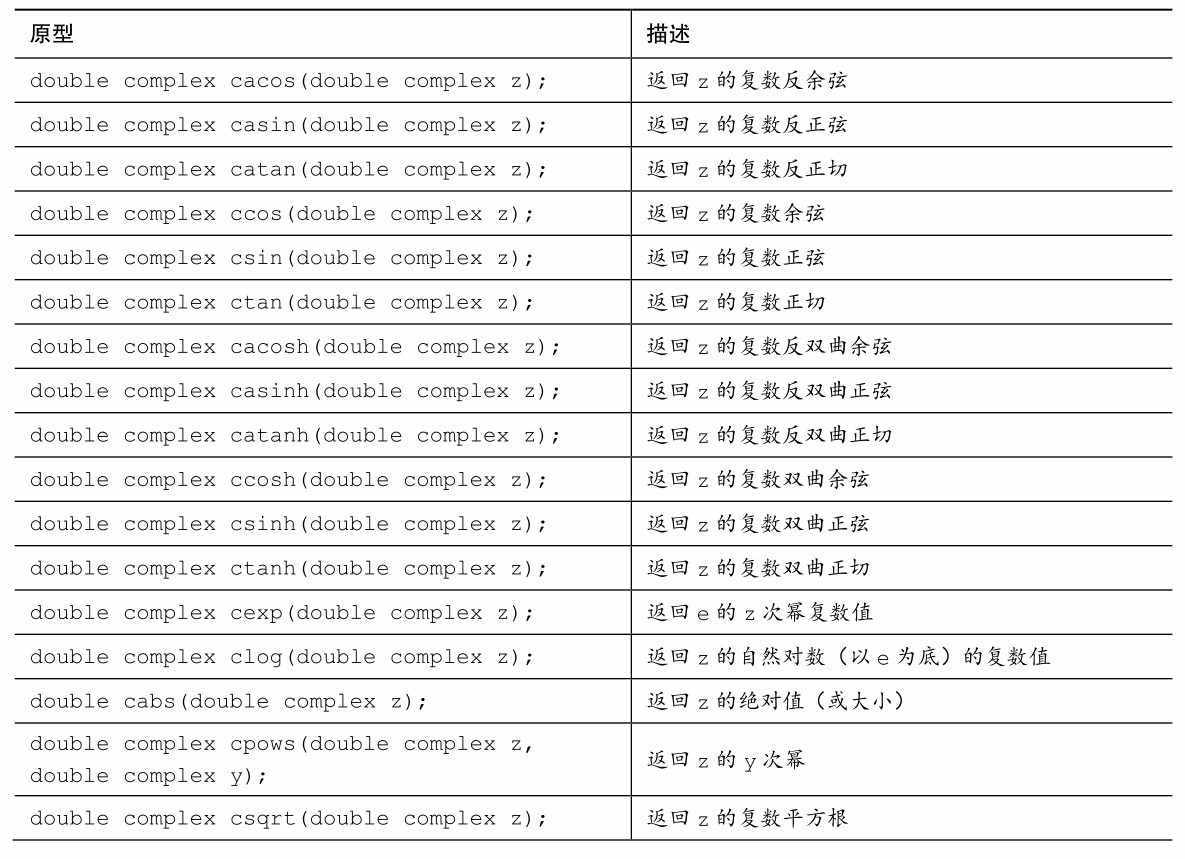
续表

B.5.3 字符处理:ctype.h
这些函数都接受int类型的参数,这些参数可以表示为unsigned char类型的值或EOF。使用其他值的效果是未定义的。在表B.5.4中,“真”表示“非0值”。对一些定义的解释取决于当前的本地设置,这些由locale.h中的函数来控制。该表显示了在解释本地化的“C”时要用到的一些函数。
表B.5.4 字符处理函数
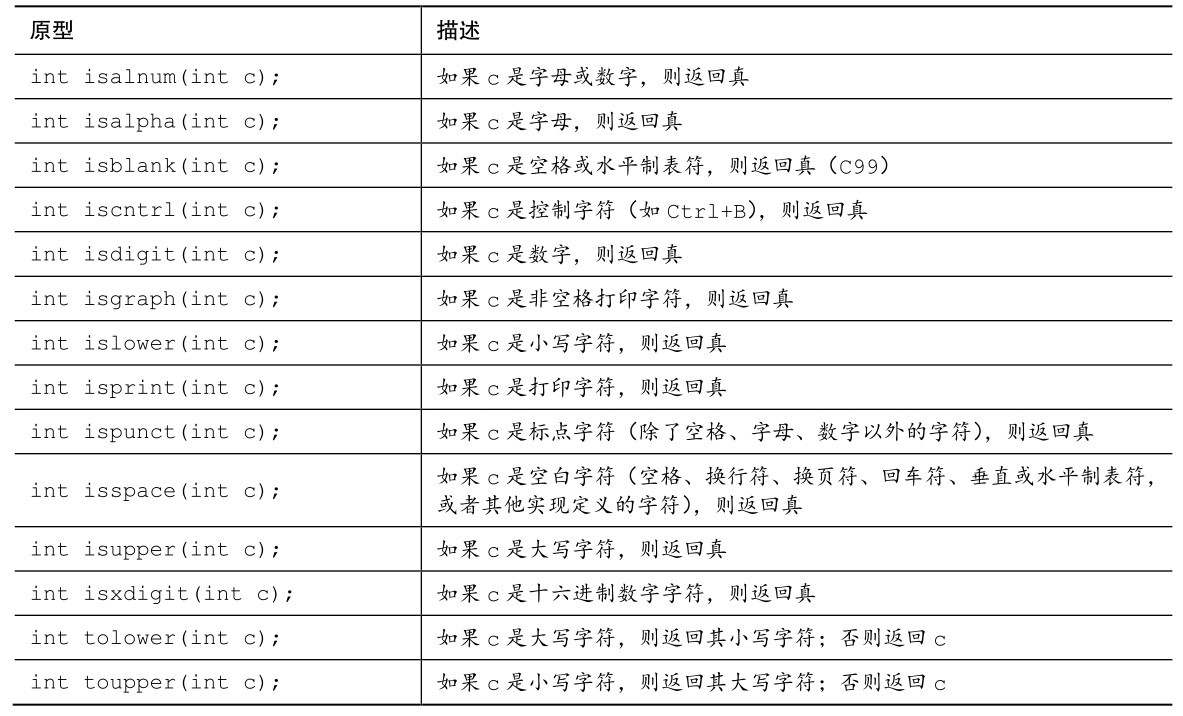
B.5.4 错误报告:errno.h
errno.h头文件支持较老式的错误报告机制。该机制提供一个标识符(或有时称为宏)ERRNO可访问的外部静态内存位置。一些库函数把一个值放进这个位置用于报告错误,然后包含该头文件的程序就可以通过查看ERRNO的值检查是否报告了一个特定的错误。ERRNO机制被认为不够艺术,而且设置ERRNO值也不需要数学函数了。标准提供了3个宏值表示特殊的错误,但是有些实现会提供更多。表B.5.5列出了这些标准宏。
表B.5.5 errno.h宏

B.5.5 浮点环境:fenv.h(C99)
C99标准通过fenv.h头文件提供访问和控制浮点环境。
浮点环境(floating-point environment)由一组状态标志(status flag)和控制模式(control mode)组成。在浮点计算中发生异常情况时(如,被零除),可以“抛出一个异常”。这意味着该异常情况设置了一个浮点环境标志。控制模式值可以进行一些控制,例如控制舍入的方向。fenv.h头文件定义了一组宏表示多种异常情况和控制模式,并提供了与环境交互的函数原型。头文件还提供了一个编译指令来启用或禁用访问浮点环境的功能。
下面的指令开启访问浮点环境:
#pragma STDC FENV_ACCESS on
下面的指令关闭访问浮点环境:
#pragma STDC FENV_ACCESS off
应该把该编译指示放在所有外部声明之前或者复合块的开始处。在遇到下一个编译指示之前、或到达文件末尾(外部指令)、或到达复合语句的末尾(块指令),当前编译指示一直有效。
头文件定义了两种类型,如表B.5.6所示。
表B.5.6 fenv.h类型

头文件定义了一些宏,表示一些可能发生的浮点异常情况控制状态。其他实现可能定义更多的宏,但是必须以FE_开头,后面跟大写字母。表B.5.7列出了一些标准异常宏。
表B.5.7 fenv.h中的标准异常宏

表B.5.8中列出了fenv.h头文件中的标准函数原型。注意,常用的参数值和返回值与表B.5.7中的宏相对应。例如,FE_UPWARD是fesetround的一个合适参数。
表B.5.8 fenv.h中的标准函数原型
B.5.6 浮点特性:float.h
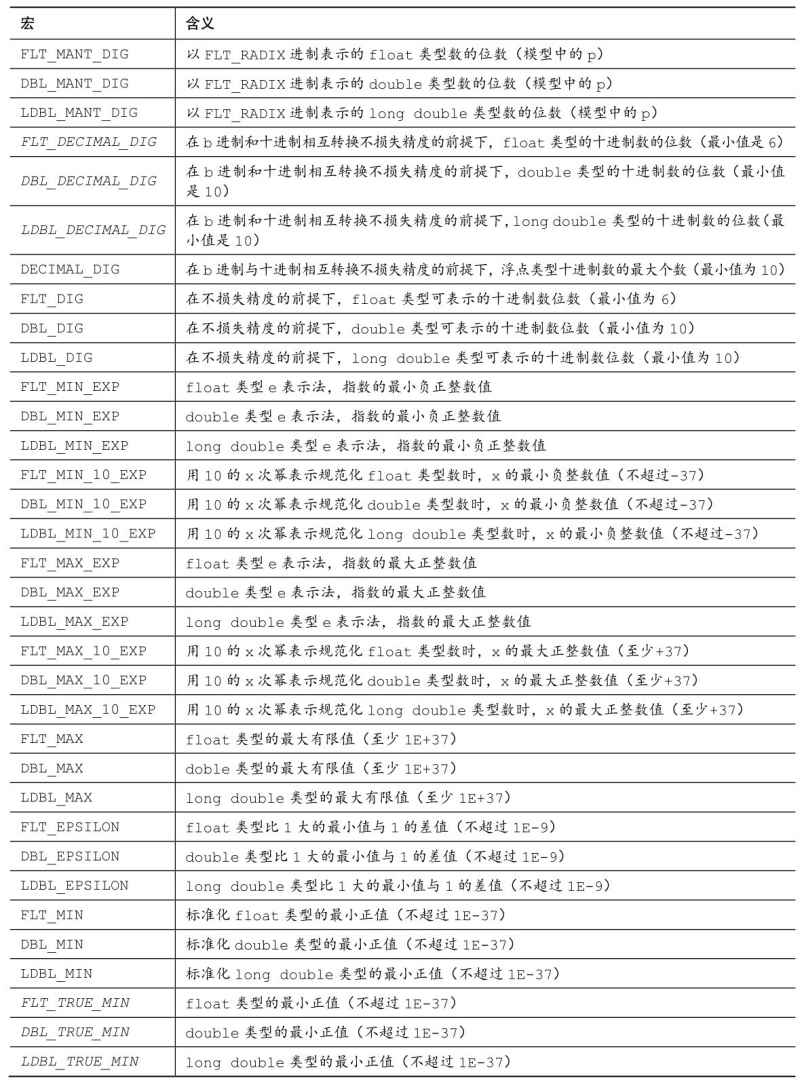
float.h头文件中定义了一些表示各种限制和形参的宏。表B.5.9列出了这些宏,C11新增的宏以斜体并缩进标出。许多宏都涉及下面的浮点表示模型:
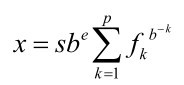
如果第1个数f1是非0(且x是非0),该数字被称为标准化浮点数。附录 B的参考资料VIII中将更详细地解释一些宏。
表B.5.9 float.h宏
1 FLT_RADIX用于表示3种浮点数类型的基数。——译者注
续表
B.5.7 整数类型的格式转换:inttypes.h
该头文件定义了一些宏可用作转换说明来扩展整数类型。参考资料VI“扩展的整数类型”将进一步讨论。该头文件还声明了这个类型:imaxp_t。这是一个结构类型,表示ipmax函数的返回值。
该头文件中还包含 stdint.h,并声明了一些使用最大长度整数类型的函数,这种整数类型在stdint.h中声明为intmax。表B.5.10列出了这些函数。
表B.5.10 使用最大长度整数的函数
B.5.8 可选拼写:iso646.h
该头文件提供了11个宏,扩展了指定的运算符,如表B.5.11所列。
表B.5.11 可 选 拼写
B.5.9 本地化:locale.h
本地化是一组设置,用于控制一些特定的设置项,如表示小数点的符号。本地值储存在struct lconv类型的结构中,定义在 locale.h 头文件中。可以用一个字符串来指定本地化,该字符串指定了一组结构成员的特殊值。默认的本地化由字符串"C"指定。表 B.5.12 列出了本地化函数,后面做了简要说明。
表B.5.12 本地化函数

setlocale函数的locale形参所需的值可能是默认值"C",也可能是"",表示实现定义的本地环境。实现可以定义更多的本地化设置。category形参的值可能由表B.5.13中所列的宏表示。
表B.5.13 category宏
表B.5.14列出了struct lconv结构所需的成员。
表B.5.14 struct lcconv所需的成员
续表
B.5.10 数学库:math.h
C99为math.h头文件定义了两种类型:float_t和double_t。这两种类型分别与float和double类型至少等宽,是计算float和double时效率最高的类型。
该头文件还定义了一些宏,如表B.5.15所列。该表中除了HUGE_VAL外,都是C99新增的。在参考资料VIII:“C99数值计算增强”中会进一步详细介绍。
表B.5.15 math.h宏

续表
数学函数通常使用double类型的值。C99新增了这些函数的float和long double版本,其函数名为分别在原函数名后添加f后缀和l后缀。例如,C语言现在提供这些函数原型:
double sin(double);
float sinf(float);
long double sinl(long double);
篇幅有限,表B.5.16仅列出了数学库中这些函数的double版本。该表引用了FLT_RADIX,该常量定义在float.h中,代表内部浮点表示法中幂的底数。最常用的值是2。
表B.5.16 ANSI C标准数学函数
续表

续表

1 NaN 分为两类:quite NaN 和 singaling NaN。两者的区别是:quite NaN 的尾数部分最高位定义为 1,而singaling NaN最高位定义为0。——译者注
续表
B.5.11 非本地跳转:setjmp.h
setjmp.h 头文件可以让你不遵循通常的函数调用、函数返回顺序。setjmp函数把当前执行环境的信息(例如,指向当前指令的指针)储存在jmp_buf类型(定义在setjmp.h头文件中的数组类型)的变量中,然后longjmp函数把执行转至这个环境中。这些函数主要是用来处理错误条件,并不是通常程序流控制的一部分。表B.5.17列出了这些函数。
表B.5.17 setjmp.h中的函数

B.5.12 信号处理:signal.h
信号(signal)是在程序执行期间可以报告的一种情况,可以用正整数表示。raise函数发送(或抛出)一个信号,signal函数设置特定信号的响应。
标准定义了一个整数类型:sig_atomic_t,专门用于在处理信号时指定原子对象。也就是说,更新原子类型是不可分割的过程。
标准提供的宏列于表B.5.18中,它们表示可能的信号,可用作raise和signal的参数。当然,实现也可以添加更多的值。
表B.5.18 信 号 宏
signal函数的第2个参数接受一个指向void函数的指针,该函数有一个int类型的参数,也返回相同类型的指针。为响应一个信号而被调用的函数称为信号处理器(signal handler)。标准定义了3个满足下面原型的宏:
void (*funct)(int);
表B.5.19列出了这3种宏。
表B.5.19 void (*f)(int)宏

如果产生了信号sig,而且 func指向一个函数(参见表B.5.20中signal原型),那么大多数情况下先调用 signal(sig, SIG_DFL)把信号重置为默认设置,然后调用(*func)(sig)。可以执行返回语句或调用abort、exit或longjmp来结束func指向的信号处理函数。
表B.5.20 信 号 函 数

B.5.13 对齐:stdalign.h(C11)
stdalign.h头文件定义了4个宏,用于确定和指定数据对象的对齐属性。表B.5.21中列出了这些宏,其中前两个创建的别名与C++的用法兼容。
表B.5.21 void (*f)(int)宏

B.5.14 可变参数:stdarg.h
stdarg.h 头文件提供一种方法定义参数数量可变的函数。这种函数的原型有一个形参列表,列表中至少有一个形参后面跟有省略号:
void f1(int n, ...); /* 有效 */
int f2(int n, float x, int k, ...);/* 有效 */
double f3(...); /* 无效 */
在下面的表中,parmN是省略号前面的最后一个形参的标识符。在上面的例子中,第1种情况的parmN为n,第2种情况的parmN为k。
头文件中声明了va_lis类型表示储存形参列表中省略号部分的形参数据对象。表B.5.22中列出了3个带可变参数列表的函数中用到的宏。在使用这些宏之前要声明一个va_list类型的对象。
表B.5.22 可变参数列表宏
B.5.15 原子支持:stdatomic.h(C11)
stdatomic.h和threads.h头文件支持并发编程。并发编程的内容超过了本书讨论的范围,简单地说,stdatomic.h 头文件提供了创建原子操作的宏。编程社区使用原子这个术语是为了强调不可分割的特性。一个操作(如,把一个结构赋给另一个结构)从编程层面上看是原子操作,但是从机器语言层面上看是由多个步骤组成。如果程序被分成多个线程,那么其中的线程可能读或修改另一个线程正在使用的数据。例如,可以想象给一个结构的多个成员赋值,不同线程给不同成员赋值。有了stdatomic.h头文件,就能创建这些可以看作是不可分割的操作,这样就能保证线程之间互不干扰。
B.5.16 布尔支持:stdbool.h(C99)
stdbool.h头文件定义了4个宏,如表B.5.23所列。
表B.5.23 stdbool.h宏

B.5.17 通用定义:stddef.h
该头文件定义了一些类型和宏,如表B.5.24和表B.5.25所列。
表B.5.24 stddef.h类型

表B.5.25 stddef.h宏

示例
#include <stddef.h>
struct car
{
char brand[30];
char model[30];
double hp;
double price;
};
int main(void)
{
size_t into = offsetof(struct car, hp); /* hp成员的偏移量 */
...
B.5.18 整数类型:stdint.h
stdint.h头文件中使用typedef工具创建整数类型名,指定整数的属性。stdint.h头文件包含在inttypes.h中,后者提供输入/输出函数调用的宏。参考资料VI的“扩展的整数类型”中介绍了这些类型的用法。
1.精确宽度类型
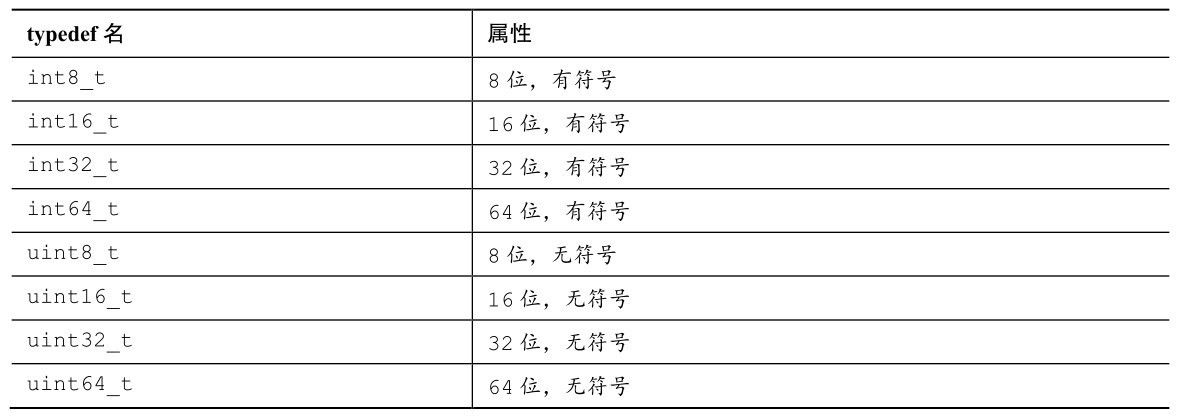
stdint.h头文件中用一组typedef标识精确宽度的类型。表B.5.26列出了它们的类型名和大小。然而,注意,并不是所有的系统都支持其中的所有类型。
表B.5.26 确切宽度类型
2.最小宽度类型
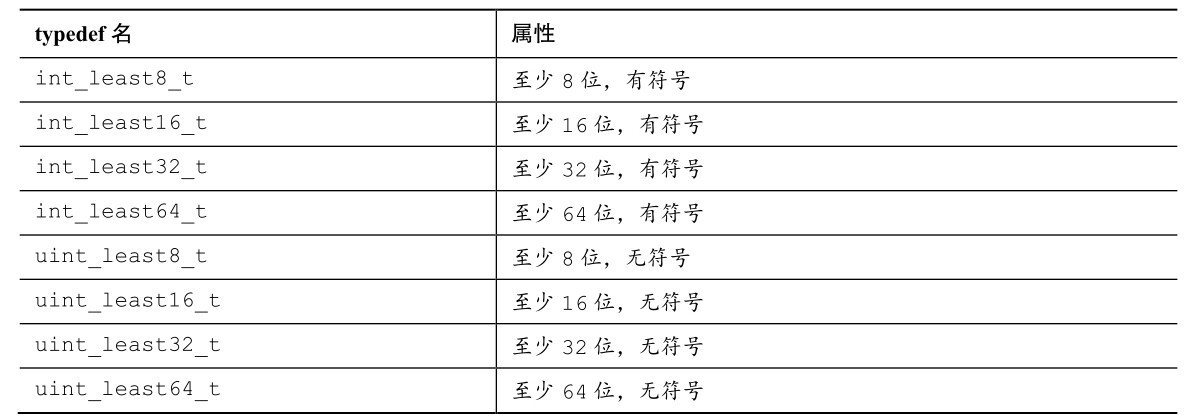
最小宽度类型保证其类型的大小至少是某数量位。表B.5.27列出了最小宽度类型,系统中一定会有这些类型。
表B.5.27 最小宽度类型
3.最快最小宽度类型
在特定系统中,使用某些整数类型比其他整数类型更快。为此,stdint.h 也定义了最快最小宽度类型,如表B.5.28所列,系统中一定会有这些类型。
表B.5.28 最快最小宽度类型
4.最大宽度类型
stdint.h 头文件还定义了最大宽度类型。这种类型的变量可以储存系统中的任意整数值,还要考虑符号。表B.5.29列出了这些类型。
表B.5.29 最大宽度类型

5.可储存指针值的整数类型
stdint.h头文件中还包括表B.5.30中所列的两种整数类型,它们可以精确地储存指针值。也就是说,如果把一个void *类型的值赋给这种类型的变量,然后再把该类型的值赋回给指针,不会丢失任何信息。系统可能不支持这类型。
表B.5.30 可储存指针值的整数类型

6.已定义的常量
stdint.h头文件定义了一些常量,用于表示该头文件中所定义类型的限定值。常量都根据类型命名,即用_MIN或_MAX代替类型名中的_t,然后把所有字母大写即得到表示该类型最小值或最大值的常量名。例如,int32_t类型的最小值是INT32_MIN、unit_fast16_t的最大值是UNIT_FAST16_MAX。表B.5.31总结了这些常量以及与之相关的intptr_t、unitptr_t、intmax_t和uintmax_t类型,其中的N表示位数。这些常量的值应等于或大于(除非指明了一定要等于)所列的值。
表B.5.31 整 型 常 量
该头文件还定义了一些别处定义的类型使用的常量,如表B.5.32所示。
表B.5.32 其他整型常量
7.扩展的整型常量
stdin.h头文件定义了一些宏用于指定各种扩展整数类型。从本质上看,这种宏是底层类型(即在特定实现中表示扩展类型的基本类型)的强制转换。
把类型名后面的_t 替换成_C,然后大写所有的字母就构成了一个宏名。例如,使用表达式UNIT_LEAST64_C(1000)后,1000就是unit_least64_t类型的常量。
B.5.19 标准I/O库:stdio.h
ANSI C标准库包含一些与流相关联的标准I/O函数和stdio.h头文件。表B.5.33列出了ANSI中这些函数的原型和简介(第13章详细介绍过其中的一些函数)。stdio.h头文件定义了FILE类型、EOF和NULL的值、标准I/O流(stdin、stdout和stderr)以及标准I/O库函数要用到的一些常量。
表B.5.33 C标准I/O函数

续表

B.5.20 通用工具:stdlib.h
ANSI C标准库在stdlib.h头文件中定义了一些实用函数。该头文件定义了一些类型,如表B.5.34所示。
表B.5.34 stdlib.h中声明的类型
stdlib.h头文件定义的常量列于表B.5.35中。
表B.5.35 stdlib.h中定义的常量
表B.5.36列出了stdlib.h中的函数原型。
表B.5.36 通 用 工 具
续表
续表

续表
B.5.21 _Noreturn:stdnoreturn.h
stdnoreturn.h定义了noreturn宏,该宏展开为_Noreturn。
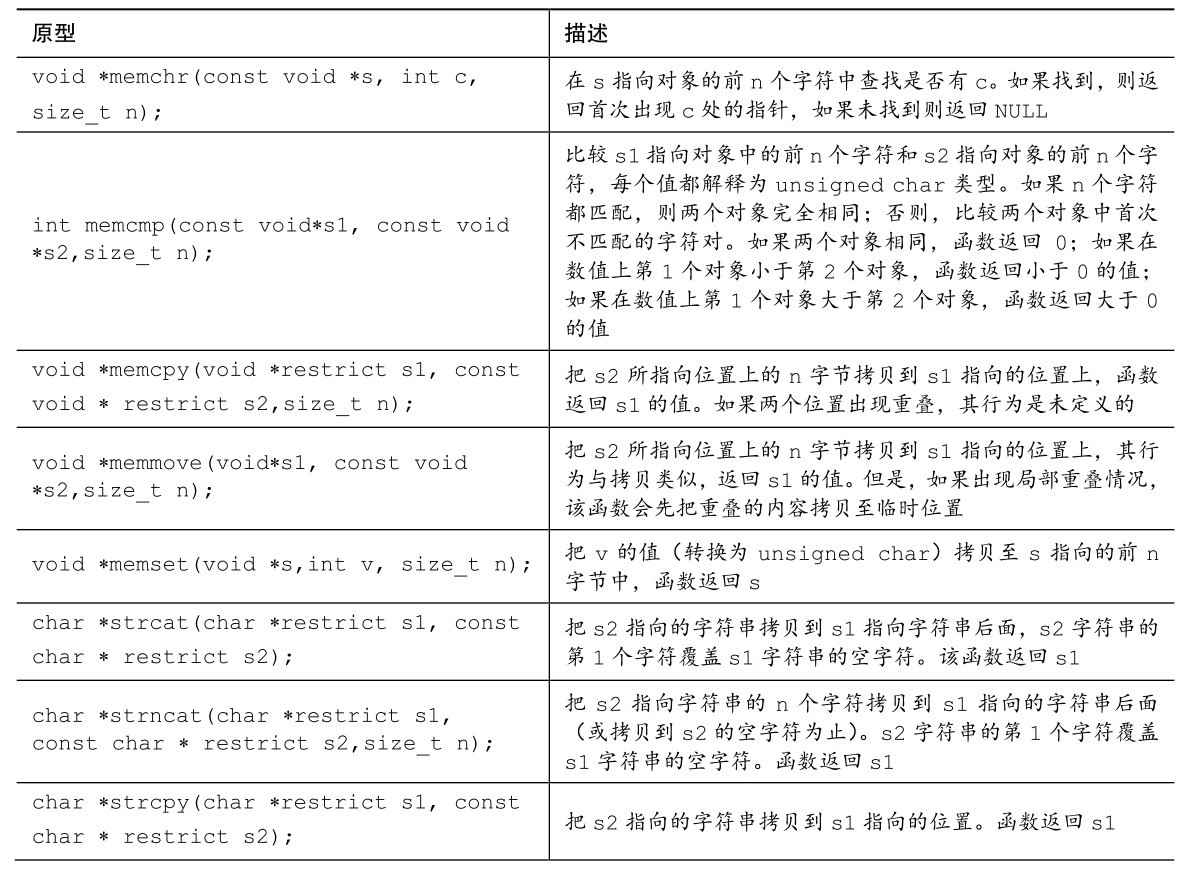
B.5.22 处理字符串:string.h
string.h库定义了size_t类型和空指针要使用的NULL宏。string.h头文件提供了一些分析和操控字符串的函数,其中一些函数以更通用的方式处理内存。表B.5.37列出了这些函数。
表B.5.37 字符串函数
续表

strtok函数的用法有点不寻常,下面演示一个简短的示例。
#include <stdio.h>
#include <string.h>
int main(void)
{
char data = " C is\t too#much\nfun!";
const char tokseps = " \t\n#";/* 分隔符 */
char * pt;
puts(data);
pt = strtok(data,tokseps); /* 首次调用 */
while (pt) /* 如果pt是NULL,则退出 */
{
puts (pt); /* 显示记号 */
pt = strtok(NULL, tokseps);/* 下一个记号 */
}
return 0;
}
下面是该示例的输出:
C is too#much
fun!
C
is
too
much
fun!
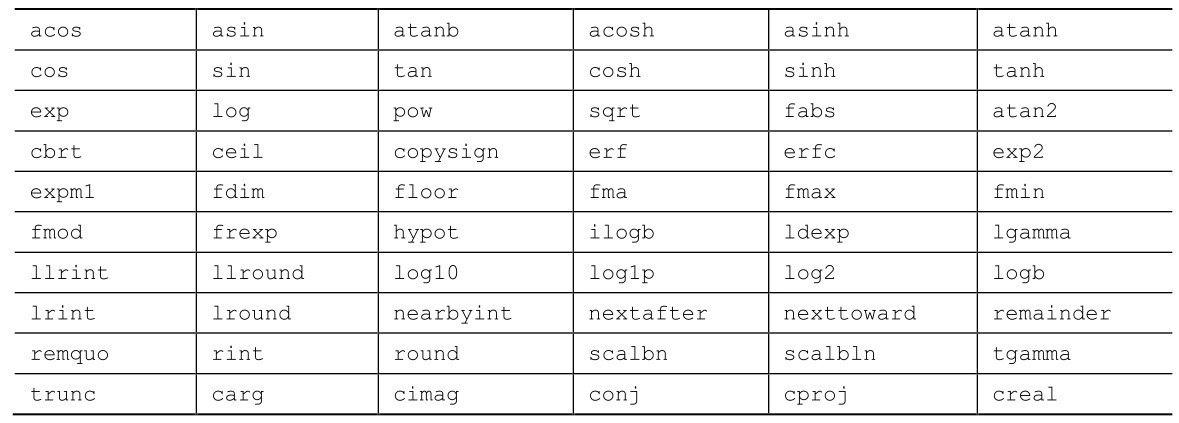
B.5.23 通用类型数学:tgmath.h(C99)
math.h和complex.h库中有许多类型不同但功能相似的函数。例如,下面6个都是计算正弦的函数:
double sin(double);
float sinf(float);
long double sinl(long double);
double complex csin(double complex);
float csinf(float complex);
long double csinl(long double complex);
tgmath.h 头文件定义了展开为通用调用的宏,即根据指定的参数类型调用合适的函数。下面的代码演示了使用sin宏时,展开为正弦函数的不同形式:
#include <tgmath.h>
...
double dx, dy;
float fx, fy;
long double complex clx, cly;
dy = sin(dx); // 展开为dy = sin(dx) (函数)
fy = sin(fx); // 展开为fy = sinf(fx)
cly = sin(clx); // 展开为cly = csinl(clyx)
tgmath.h头文件为3类函数定义了通用宏。第1类由math.h和complex.h中定义的6个函数的变式组成,用l和f后缀和c前缀,如前面的sin函数所示。在这种情况下,通用宏名与该函数double类型版本的函数名相同。
第2类由math.h头文件中定义的3个函数变式组成,使用l和f后缀,没有对应的复数函数(如,erf)。在这种情况下,宏名与没有后缀的函数名相同,如erf。使用带复数参数的这种宏的效果是未定义的。
第3类由complex.h头文件中定义的3个函数变式组成,使用l和f后缀,没有对应的实数函数,如cimag。使用带实数参数的这种宏的效果是未定义的。
表B.5.38列出了一些通用宏函数。
表B.5.38 通用数学函数
在C11以前,编写实现必须依赖扩展标准才能实现通用宏。但是使用C11新增的_Generic表达式可以直接实现。
B.5.24 线程:threads.h(C11)
threads.h和stdatomic.h头文件支持并发编程。这方面的内容超出了本书讨论的范围,简而言之,该头文件支持程序执行多线程,原则上可以把多个线程分配给多个处理器处理。
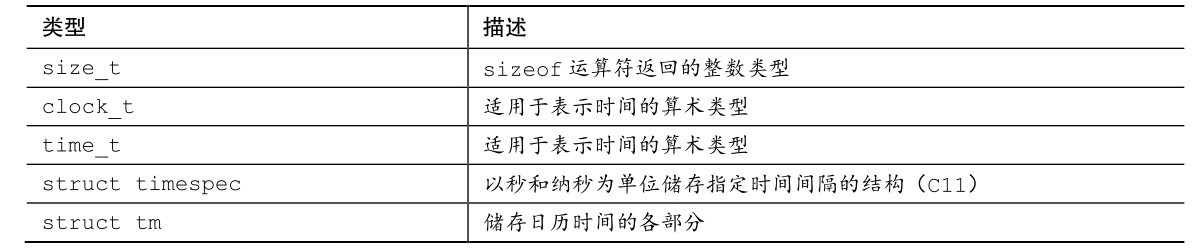
B.5.25 日期和时间:time.h
time.h定义了3个宏。第1个宏是表示空指针的NULL,许多其他头文件中也定义了这个宏。第2个宏是CLOCKS_PER_SEC,该宏除以clock的返回值得以秒为单位的时间值。第3个宏(C11)是TIME_UTC,这是一个正整型常量,用于指定协调世界时 [1](即UTC)。该宏是timespec_get函数的一个可选参数。
UTC是目前主要世界时间标准,作为互联网和万维网的普通标准,广泛应用于航空、天气预报、同步计算机时钟等各领域。
time.h头文件中定义的类型列在表B.5.39中。
表B.5.39 time.h中定义的类型
timespec结构中至少有两个成员,如表B.5.40所列。
表B.5.40 timespec结构中的成员

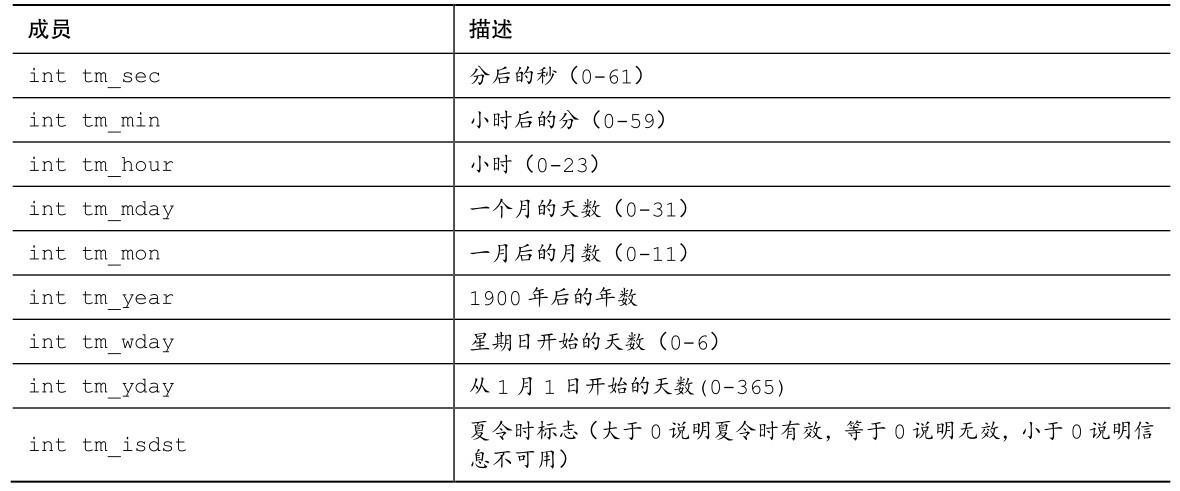
日历类型的各组成部分被称为分解时间(broken-down time)。表B.5.41列出了struct tm结构中所需的成员。
表B.5.41 struct tm结构中的成员
日历时间(calendar time)表示当前的日期和时间,例如,可以是从1900年的第1秒开始经过的秒数。本地时间(local time)指的是本地时区的日历时间。表B.5.42列出了一些时间函数。
表B.5.42 时 间 函 数
续表
表B.5.43列出了strftime函数中使用的转换说明。其中许多替换的值(如,月份名)都取决于当前的本地化设置。
表B.5.43 strftime函数中使用的转换说明
续表
B.5.26 统一码工具:uchar.h(C11)
C99 的 wchar.h 头文件提供两种途径支持大型字符集。C11 专门针对统一码(Unicode)新增了适用于UTF-16和UTF-32编码的类型(见表B.5.44)。
表B.5.44 uchar.h中声明的类型

该头文件中还声明了一些多字节字符串与char16_t、char32_t格式相互转换的函数(见表B.5.45)。
表B.5.45 宽字符与多字节转换函数
续表

B.5.27 扩展的多字节字符和宽字符工具:wchar.h(C99)
每种实现都有一个基本字符集,要求C的char类型足够宽,以便能处理这个字符集。实现还要支持扩展的字符集,这些字符集中的字符可能需要多字节来表示。可以把多字节字符与单字节字符一起储存在普通的 char 类型数组,用特定的字节值指定多字节字符本身及其大小。如何解释多字节字符取决于移位状态(shift state)。在最初的移位状态中,单字节字符保留其通常的解释。特殊的多字节字符可以改变移位状态。除非显式改变特定的移位状态,否则移位状态一直保持有效。
wchar_t类型提供另一种表示扩展字符的方法,该类型足够宽,可以表示扩展字符集中任何成员的编码。用这种宽字符类型来表示字符时,可以把单字符储存在wchar_t类型的变量中,把宽字符的字符串储存在wchar_t类型的数组中。字符的宽字符表示和多字节字符表示不必相同,因为后者可能使用前者并不使用的移位状态。
wchar.h 头文件提供了一些工具用于处理扩展字符的两种表示法。该头文件中定义的类型列在表B.5.46中(其中有些类型也定义在其他的头文件中)。
表B.5.46 wchar.h中定义的类型

wchar.h头文件中还定义了一些宏,如表B.5.47所列。
表B.5.47 wchar.h中定义的宏

该库提供的输入/输出函数类似于stdio.h中的标准输入/输出函数。在标准I/O函数返回EOF的情况中,对应的宽字符函数返回WEOF。表B.5.48中列出了这些函数。
表B.5.48 宽字符I/O函数

有一个宽字符I/O函数没有对应的标准I/O函数:
int fwide(FILE *stream, int mode)[2];
如果mode为正,函数先尝试把形参表示的流指定为宽字符定向(wide-charaacter oriented);如果 mode为负,函数先尝试把流指定为字节定向(byte oriented);如果 mode为0,函数则不改变流的定向。该函数只有在流最初无定向时才改变其定向。在以上所有的情况中,如果流是宽字符定向,函数返回正值;如果流是字节定向,函数返回负值;如果流没有定向,函数则返回0。
wchar.h 头文件参照 string.h,也提供了一些转换和控制字符串的函数。一般而言,用 wcs 代替sting.h中的str标识符,这样wcstod就是strtod函数的宽字符版本。表B.5.49列出了这些函数。
表B.5.49 宽字符字符串工具

续表

该头文件还参照time.h头文件中的strtime函数,声明了一个时间函数:
size_t wcsftime(wchar_t * restrict s, size_t maxsize,const wchar_t * restrict format,
const struct tm * restrict timeptr);
除此之外,该头文件还声明了一些用于宽字符字符串和多字节字符相互转换的函数,如表B.5.50所列。
表B.5.50 宽字节和多字节字符转换函数
续表

B.5.28 宽字符分类和映射工具:wctype.h(C99)
wctype.h 库提供了一些与 ctype.h 中的字符函数类似的宽字符函数,以及其他函数。wctype.h还定义了表B.5.51中列出的3种类型和宏。
表B.5.51 wctpe.h中定义的类型和宏
在该库中,如果宽字符参数满足字符分类函数的条件时,函数返回真(非0)。一般而言,因为单字节字符对应宽字符,所以如果 ctype.h 中对应的函数返回真,宽字符函数也返回真。表 B.5.52 列出了这些函数。
表B.5.52 宽字节分类函数
该库还包含两个可扩展的分类函数,因为它们使用当前本地化的LC_CTYPE值进行分类。表B.5.53列出了这些函数。
表B.5.53 可扩展的宽字符分类函数

wctype函数的有效参数名即是宽字符分类函数名去掉 isw 前缀。例如,wctype("alpha")表示的是 iswalpha函数判断的字符类别。因此,调用 iswctype(wc, wctype("alpha"))相当于调用iswalpha(wc),唯一的区别是前者使用LC_CTYPE类别进行分类。
该库还有4个与转换相关的函数。其中有两个函数分别与ctype.h库中toupper和tolower相对应。第3个函数是一个可扩展的版本,通过本地化的LC_CTYPE设置确定字符是大写还是小写。第4个函数为第3个函数提供合适的分类参数。表B.5.54列出了这些函数。
表B.5.54 宽字符转换函数
B.6 参考资料VI:扩展的整数类型
第3章介绍过,C99的inttypes.h头文件为不同的整数类型提供一套系统的别名。这些名称与标准名称相比,能更清楚地描述类型的性质。例如,int类型可能是16位、32位或64位,但是int32_t类型一定是32位。
更精确地说,inttypes.h头文件定义的一些宏可用于scanf和printf函数中读写这些类型的整数。inttypes.h头文件包含的stdlib.h头文件提供实际的类型定义。格式化宏可以与其他字符串拼接起来形成合适格式化的字符串。
该头文件中的类型都使用typedef定义。例如,32位系统的int可能使用这样的定义:
typedef int int32_t;
用#define指令定义转换说明。例如,使用之前定义的int32_t的系统可以这样定义:
#define PRId32 "d" // 输出说明符
#define SCNd32 "d" // 输入说明符
使用这些定义,可以声明扩展的整型变量、输入一个值和显示该值:
int32_t cd_sales; // 32位整数类型
scanf("%" SCNd32, &cd_sales);
printf("CD sales = %10" PRId32 " units\n", cd_sales);
如果需要,可以把字符串拼接起得到最终的格式字符串。因此,上面的代码可以这样写:
int cd_sales; // 32位整数类型
scanf("%d", &cd_sales);
printf("CD sales = %10d units\n", cd_sales);
如果把原始代码移植到16位int的系统中,该系统可能把int32_t定义为long,把PRId32定义为"ld"。但是,仍可以使用相同的代码,只要知道系统使用的是32位整型即可。
该参考资料的其余部分列出了扩展类型、转换说明以及表示类型限制的宏。
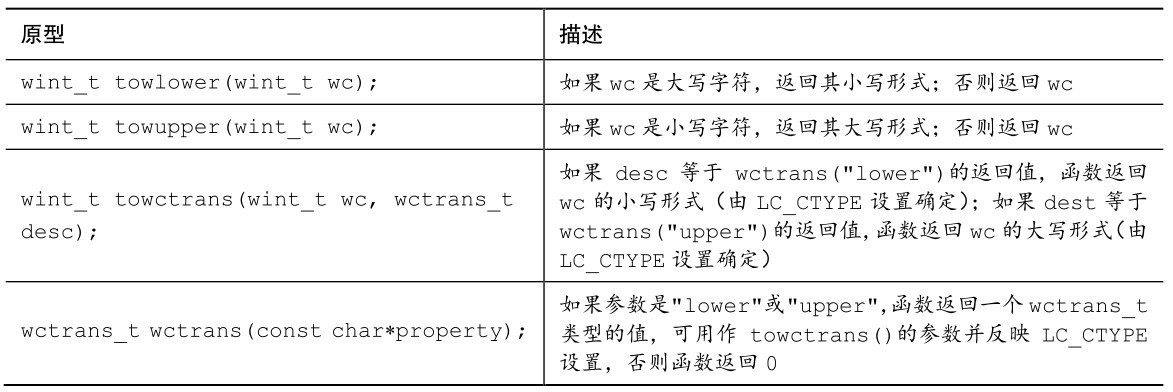
B.6.1 精确宽度类型
typedef标识了一组精确宽度的类型,通用形式是intN_t(有符号类型)和uintN_t(无符号类型),其中N表示位数(即类型的宽度)。但是要注意,不是所有的系统都支持所有的这些类型。例如,最小可用内存大小是16位的系统就不支持int8_t和uint8_t类型。格式宏可以使用d或i表示有符号类型,所以PRIi8和SCNi8都有效。对于无符号类型,可以使用o、x或u以获得%o、%x或%X转换说明来代替%u。例如,可以使用PRIX32以十六进制格式打印uint32_t类型的值。表B.6.1列出了精确宽度类型、格式说明符和最小值、最大值。
表B.6.1 精确宽度类型
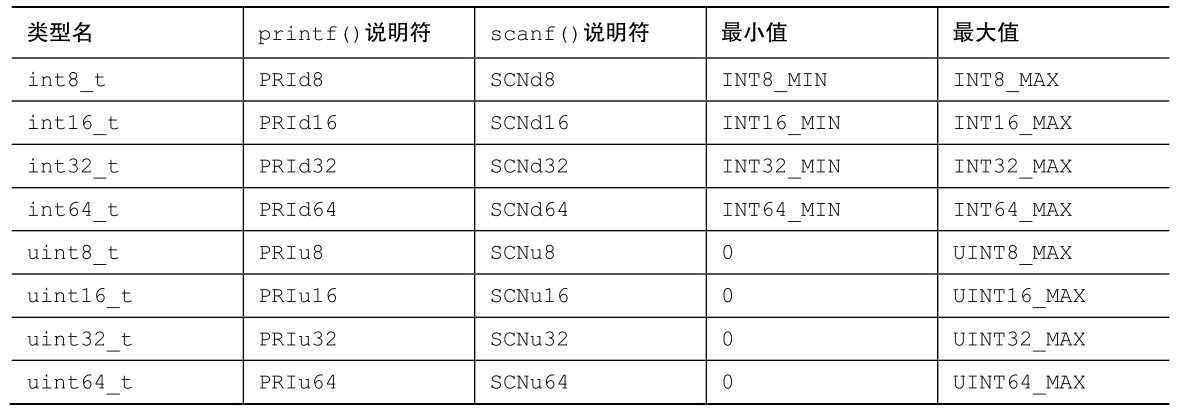
B.6.2 最小宽度类型
最小宽度类型保证一种类型的大小至少是某位。这些类型一定存在。例如,不支持 8 位单元的系统可以把int_least_8定义为16位类型。表B.6.2列出了最小宽度类型、格式说明符和最小值、最大值。
表B.6.2 最小宽度类型
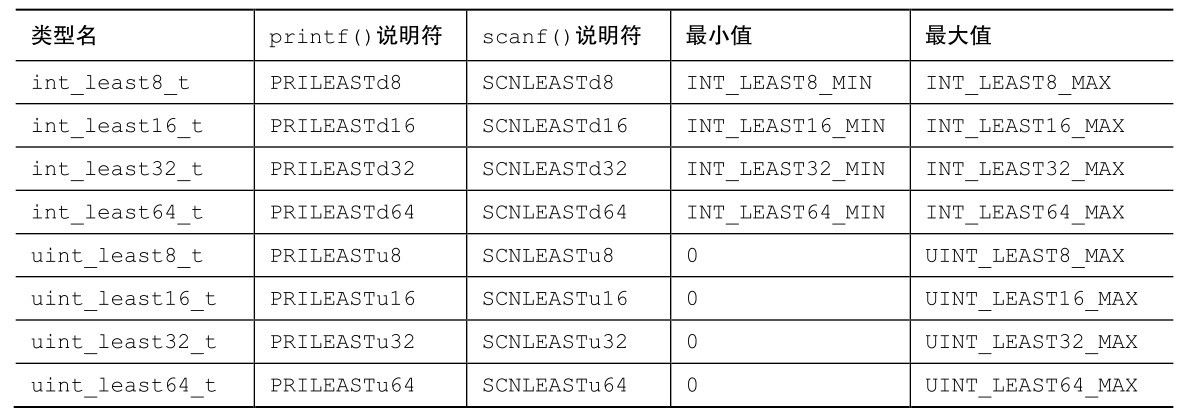
B.6.3 最快最小宽度类型
对于特定的系统,用特定的整型更快。例如,在某些实现中int_least16_t可能是short,但是系统在进行算术运算时用int类型会更快些。因此,inttypes.h还定义了表示为某位数的最快类型。这些类型一定存在。在某些情况下,可能并未明确指定哪种类型最快,此时系统会简单地选择其中的一种。表B.6.3列出了最快最小宽度类型、格式说明符和最小值、最大值。
表B.6.3 最快最小宽度类型
B.6.4 最大宽度类型
有些情况下要使用最大整数类型,表B.6.4列出了这些类型。实际上,由于系统可能会提供比所需类型更大宽度的类型,因此这些类型的宽度可能比long long或unsigned long long更大。
表B.6.4 最大宽度类型

B.6.5 可储存指针值的整型
inttypes.h头文件(通过包含stdint.h即可包含该头文件)定义了两种整数类型,可精确地储存指针值,见表B.6.5。
表B.6.5 可储存指针值的整数类型

B.6.6 扩展的整型常量
在整数后面加上L后缀可表示long类型的常量,如445566L。如何表示int32_t类型的常量?要使用inttypes.h头文件中定义的宏。例如,表达式INT32_C(445566)展开为一个int32_t类型的常量。从本质上看,这种宏相当于把当前类型强制转换成底层类型,即特殊实现中表示int32_t类型的基本类型。
宏名是把相应类型名中的_C 用_t 替换,再把名称中所有的字母大写。例如,要把 1000 设置为unit_least64_t类型的常量,可以使用表达式UNIT_LEAST64_C(1000)。
B.7 参考资料VII:扩展字符支持
C 语言最初并不是作为国际编程语言设计的,其字符的选择或多或少是基于标准的美国键盘。但是,随着后来C在世界范围内越来越流行,不得不扩展来支持不同且更大的字符集。这部分参考资料概括介绍了一些相关内容。
B.7.1 三字符序列
有些键盘没有C中使用的所有符号,因此C提供了一些由三个字符组成的序列(即三字符序列)作为这些符号的替换表示。如表B.7.1所示。
表B.7.1 三字符序列

C替换了源代码文件中的这些三字符序列,即使它们在双引号中也是如此。因此,下面的代码:
??=include <stdio.h>
??=define LIM 100
int main
??<
int q??(LIM??);
printf("More to come.??/n");
...
??>
会变成这样:
#include <stdio.h>
#define LIM 100
int main
{
int q[LIM];
printf("More to come.\n");
...
}
当然,要在编译器中设置相关选项才能激活这个特性。
B.7.2 双字符
意识到三字符系统很笨拙,C99提供了双字符(digraph),可以使用它们来替换某些标准C标点符号。
表B.7.2 双字符

与三字符不同的是,不会替换双引号中的双字符。因此,下面的代码:
%:include <stdio.h>
%:define LIM 100
int main
<%
int q<:LIM:>;
printf("More to come.:>");
...
%>
会变成这样:
#include <stdio.h>
#define LIM 100
int main
{
int q[LIM];
printf("More to come.:>"); // :>是字符串的一部分
...
} // :>与 }相同
B.7.3 可选拼写:iso646.h
使用三字符序列可以把||运算符写成??!??!,这看上去比较混乱。C99 通过iso646.h头文件(参考资料V中的表B.5.11)提供了可展开为运算符的宏。C标准把这些宏称为可选拼写(alternative spelling)。
如果包含了iso646.h头文件,以下代码:
if(x == M1 or x == M2)
x and_eq 0XFF;
可展开为下面的代码:
if(x == M1 || x == M2)
x &= 0XFF;
B.7.4 多字节字符
C 标准把多字节字符描述为一个或多个字节的序列,表示源环境或执行环境中的扩展字符集成员。源环境指的是编写源代码的环境,执行环境指的是用户运行已编译程序的环境。这两个环境不同。例如,可以在一个环境中开发程序,在另一个环境中运行该程序。扩展字符集是C语言所需的基本字符集的超集。
有些实现会提供扩展字符集,方便用户通过键盘输入与基本字符集不对应的字符。这些字符可用于字符串字面量和字符常量中,也可出现在文件中。有些实现会提供与基本字符集等效的多字节字符,可替换三字符和双字符。
例如,德国的一个实现也许会允许用户在字符串中使用日耳曼元音变音字符:
puts("eins zwei drei vier fünf");
一般而言,程序可使用的扩展字符集因本地化设置而异。
B.7.5 通用字符名(UCN)
多字节字符可以用在字符串中,但是不能用在标识符中。C99新增了通用字符名(UCN),允许用户在标识名中使用扩展字符集中的字符。系统扩展了转义序列的概念,允许编码ISO/IEC 10646标准中的字符。该标准由国际标准化组织(ISO)和国际电工技术委员会(IEC)共同制定,为大量的字符提供数值码。10646标准和统一码(Unicode)关系密切。
有两种形式的UCN序列。第1种形式是\u hexquard,其中hexquard是一个4位的十六进制数序列(如,\u00F6)。第 2种形式是\U hexquardhexquard,如\U0000AC01。因为十六进制每一位上的数对应4位,\u形式可用于16位整数表示的编码,\U形式可用于32位整数表示的编码。
如果系统实现了UCN,而且包含了扩展字符集中所需的字符,就可以在字符串、字符常量和标识符中使用UCN:
wchar_t value\u00F6\u00F8 = L'\u00f6';
统一码和ISO 10646
统一码为表示不同的字符集提供了一种解决方案,可以根据类型为大量字符和符号制定标准的编号系统。例如,ASCII码被合并为统一码的子集,因此美国拉丁字符(如A~Z)在这两个系统中的编码相同。但是,统一码还合并了其他拉丁字符(如,欧洲语言中使用的一些字符)和其他语言中的字符,包括希腊文、西里尔字母、希伯来文、切罗基文、阿拉伯文、泰文、孟加拉文和形意文字(如中文和日文)。到目前为止,统一码表示的符号超过了 110000个,而且仍在发展中。欲了解更多细节,请查阅统一码联合站点:www.unicode.org。
统一码为每个字符分配一个数字,这个数字称为代码点(code point)。典型的统一码代码点类似:U-222B。U表示该字符是统一字符,222B是表示该字符的一个十六进制数,在这种情况下,表示积分号。
国际标准化组织(ISO)组建了一个团队开发ISO 10646和标准编码的多语言文本。ISO 10646团队和统一码团队从1991年开始合作,一直保持两个标准的相互协调。
B.7.6 宽字符
C99为使用宽字符提供更多支持,通过wchar.h和wctype.h库包含了更多大型字符集。这两个头文件把wchar_t定义为一种整型类型,其确切的类型依赖实现。该类型用于储存扩展字符集中的字符,扩展字符集是是基本字符集的超集。根据定义,char类型足够处理基本字符集,而wchar_t类型则需要更多位才能储存更大范围的编码值。例如,char 可能是 8 位字节,wchar_t 可能是 16 位的 unsigned short。
用L前缀标识宽字符常量和字符串字面量,用%lc和%ls显示宽字符数据:
wchar_t wch = L'I';
wchar_t w_arr[20] = L"am wide!";
printf("%lc %ls\n", wch, w_arr);
例如,如果把wchar_t实现为2字节单元,'I'的1字节编码应储存在wch的低位字节。不是标准字符集中的字符可能需要两个字节储存字符编码。例如,可以使用通用字符编码表示超出 char 类型范围的字符编码:
wchar_t w = L'\u00E2'; /* 16位编码值 */
内含 wchar_t 类型值的数组可用于储存宽字符串,每个元素储存一个宽字符编码。编码值为 0 的wchar_t值是空字符的wchar_t类型等价字符。该字符被称为空宽字符(null wide character),用于表示宽字符串的结尾。
可以使用%lc和%ls读取宽字符:
wchar_t wch1;
wchar_t w_arr[20];
puts("Enter your grade:");
scanf("%lc", &wch1);
puts("Enter your first name:");
scanf("%ls",w_arr);
wchar_t头文件为宽字符提供更多支持,特别是提供了宽字符I/O函数、宽字符转换函数和宽字符串控制函数。例如,可以用fwprintf和wprintf函数输出,用fwscanf和wscanf函数输入。与一般输入/输出函数的主要区别是,这些函数需要宽字符格式字符串,处理的是宽字符输入/输出流。例如,下面的代码把信息作为宽字符显示:
wchar_t * pw = L"Points to a wide-character string";
int dozen = 12;
wprintf(L"Item %d: %ls\n", dozen, pw);
类似地,还有getwchar、putwchar、fgetws和fputws函数。wchar_t头文件定义了一个WEOF宏,与EOF在面向字节的I/O中起的作用相同。该宏要求其值是一个与任何有效字符都不对应的值。因为wchar_t类型的值都有可能是有效字符,所以wchar_t库定义了一个wint_t类型,包含了所有wchar_t类型的值和WEOF的值。
该库中还有与string.h库等价的函数。例如,wcscpy(ws1, ws2)把ws1指定的宽字符串拷贝到ws2指向的宽字符数组中。类似地,wcscmp函数比较宽字符串,等等。
wctype.h头文件新增了字符分类函数,例如,如果iswdigit函数的宽字符参数是数字,则返回真;如果iswblank函数的参数是空白,则返回真。空白的标准值是空格和水平制表符,分别写作L''和L'\t'。
C11标准通过uchar.h头文件为宽字符提供更多支持,为匹配两种常用的统一码格式,定义了两个新类型。第1种类型是char16_t,可储存一个16位编码,是可用的最小无符号整数类型,用于hexquard UCN形式和统一码UTF-16编码方案。
char16_t = '\u00F6';
第2种类型是char32_t,可储存一个32位编码,最小的可用无符号整数类型,。可用于hexquard UCN形式和统一码UTF-32编码方案
char32_t = '\U0000AC01';
前缀u和U分别表示char16_t和char32_t字符串。
char16_t ws16[11] = u"Tannh\u00E4user";
char32_t ws32[13] = U"caf\U000000E9 au lait";
注意,这两种类型比wchar_t类型更具体。例如,在一个系统中,wchar_t可以储存32位编码,但是在另一个系统中也许只能储存16位的编码。另外,这两种新类型都与C++兼容。
B.7.7 宽字符和多字节字符
宽字符和多字节字符是处理扩展字符集的两种不同的方法。例如,多字节字符可能是一个字节、两个字节、三个字节或更多字节,而所有的宽字符都只有一个宽度。多字节字符可能使用移位状态(移位状态是一个字节,确定如何解释后续字节);而宽字符没有移位状态。可以把多字节字符的文件读入使用标准输入函数的普通char类型数组,把宽字节的文件读入使用宽字符输入函数的宽字节数组。
C99 在wchar.h库中提供了一些函数,用于多字节和宽字节之间的转换。mbrtowc函数把多字节字符转换为宽字符,wcrtomb函数把宽字符转换为多字节字符。类似地,mbstrtowcs函数把多字节字符串转换为宽字节字符串,wcstrtombs函数把宽字节字符串转换为多字节字符串。
C11在uchar.h库中提供了一些函数,用于多字节和char16_t之间的转换,以及多字节和char32_t之间的转换。
B.8 参考资料VIII:C99/C11数值计算增强
过去,FORTRAN是数值科学计算和工程计算的首选语言。C90使C的计算方法更接近于FORTRAN。例如,float.h中使用的浮点特性规范都是基于FORTRAN标准委员会开发的模型。C99和C11标准继续增强了C的计算能力。例如,C99新增的变长数组(C11成为可选的特性),比传统的C数组更符合FORTRAN的用法(如果实现不支持变长数组,C11指定了__STDC_NO_VLA__宏的值为1)。
B.8.1 IEC浮点标准
国际电工技术委员会(IEC)已经发布了一套浮点计算的标准(IEC 60559)。该标 准包括了浮点数的格式、精度、NaN、无穷值、舍入规则、转换、异常以及推荐的函数和算法等。C99纳入了该标准,将其作为C实现浮点计算的指导标准。C99新增的大部分浮点工具(如,fenv.h头文件和一些新的数学函数)都基于此。另外,float.h头文件定义了一些与IEC浮点模型相关的宏。
1.浮点模型
下面简要介绍一下浮点模型。标准把浮点数x看作是一个基数的某次幂乘以一个分数,而不是C语言的E记数法(例如,可以把876.54写成0.87654E3)。正式的浮点表示更为复杂:
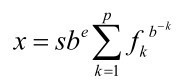
简单地说,这种表示法把一个数表示为有效数(significand)与b的e次幂的乘积。
下面是各部分的含义。
s代表符号(±1)。
b代表基数。最常见的值是2,因为浮点处理器通常使用二进制数学。
e代表整数指数(不要与自然对数中使用的数值常量e混淆),限制最小值和最大值。这些值依赖于留出储存指数的位数。
fk代表基数为b时可能的数字。例如,基数为2时,可能的数字是0和1;在十六进制中,可能的数字是0~F。
p代表精度,基数为b时,表示有效数的位数。其值受限于预留储存有效数字的位数。
明白这种表示法的关键是理解float.h和fenv.h的内容。下面,举两个例子解释内部如何表示浮点数。
首先,假设一个浮点数的基数b为10,精度p为5。那么,根据上面的表示法,24.51应写成:
(+1)103(2/10 + 4/100 + 5/1000 + 1/10000 + 0/100000)
假设计算机可储存十进制数(0~9),那么可以储存符号、指数3和5个fk值:2、4、5、1、0(这里,f1是2,f2是4,等等)。因此,有效数是0.24510,乘以103得24.51。
接下来,假设符号为正,基数b是2,p是7(即,用7位二进制数表示),指数是5,待储存的有效数是1011001。下面,根据上面的公式构造该数:
x = (+1)25(1/2 +0/4 + 1/8 + 1/16 + 0/32 + 0/64 + 1/128)
= 32(1/2 +0/4 + 1/8 + 1/16 + 0/32 + 0/64 + 1/128)
= 16 + 0 + 4 + 2 +0 + 0 + 1/4 = 22.25
float.h中的许多宏都与该浮点表示相关。例如,对于一个float类型的值,表示基数的FLT_RADIX是b,表示有效数位数(基数为b时)的FLT_MANT_DIG是p。
2.正常值和低于正常的值
正常浮点值(normalized floating-point value)的概念非常重要,下面简要介绍一下。为简单起见,先假设系统使用十进制(b = FLT_RADIX = 10)和浮点值的精度为 5(p = FLT_MANT_DIG = 5)(标准要求的精度更高)。考虑下面表示31.841的方式:
指数 = 3,有效数 = .31841(.31841E3)
指数 = 4,有效数 = .03184(.03184E4)
指数 = 5,有效数 = .00318(.00318E5)
显而易见,第1种方法精度最高,因为在有效数中使用了所有的5位可用位。规范化浮点非零值是第1位有效位为非零的值,这也是通常储存浮点数的方式。
现在,假设最小指数(FLT_MIN_EXP)是-10,那么最小的规范值是:
指数 = -10,有效数 = .10000(.10000E-10)
通常,乘以或除以10意味着使指数增大或减小,但是在这种情况下,如果除以10,却无法再减小指数。但是,可以改变有效数获得这种表示:
指数 = -10,有效数 = .01000(.01000E-10)
这个数被称为低于正常的(subnormal),因为该数并未使用有效数的全精度。例如,0.12343E-10除以10得.01234E-10,损失了一位的信息。
对于这个特例,0.1000E-10 是最小的非零正常值(FLT_MIN),最小的非零低于正常值是0.00001E-10(FLT_TRUE_MIN)。
float.h中的宏FLT_HAS_SUBNURM、DBL_HAS_SUBNORM和LDBL_HAS_SUBNORM表征实现如何处理低于正常的值。下面是这些宏可能会用到的值及其含义: