仅仅几年以前,这种被称为“商务智能”的技术,还是大公司的专利。但随着计算机处理器、存储器的价格不断下降和软件质量的不断上升,这种技术成了商业界的主流。大大小小的公司,都收集了前所未有的大量数据。过去,这些数据存储在不同的系统当中,如财务系统、人力资源系统和客户管理系统,老死不相往来。现在,这些系统彼此相连,通过“数据挖掘”的技术,可以获得一幅关于企业运营的完整图景,这被称为:一致的真相(A single version of the truth)。商务智能提高了商业运营的效率,帮助了企业总结发展过程中的模式,并改善了企业预测未来的能力。
信息技术产业把商务智能视为对20世纪上半叶企业会计服务、下半叶计算机服务的一个自然承接,正在争相涌入这个领域。爱森哲、普华永道、IBM、SAP都在这个领域投入巨资。技术平台的提供商甲骨文、Informatica、TIBCO、SAS、EMC也从中赢利。IBM更是相信:随着传感器在城市交通、医疗健康中的应用,商务智能将成为其业务增长的顶梁柱。01
——《经济学人》,2010年2月25日特别报道
联邦政府这个数据帝国,虽然拥有的数据比任何公司、企业都多,但和私营领域相比,在信息技术的应用上,还是明显落后一步、慢了几拍。
2009年3月,奥巴马就任后的第二个月,就在联邦政府之内设立了一个全新的职位:首席信息官(Chief Information Officer),并任命来自印度的移民昆德拉(Vivek Kundra)为第一任联邦政府首席信息官。昆德拉在公共和私营两个领域都有广泛的经历,他走马上任之后,曾发表过第一感受:联邦政府信息技术的装备和应用,和一流的商业公司相比,就好像手摇电话摆在了线条圆润、光彩照人的苹果手机旁边,不可同日而语。
当然,这并不奇怪。现代政治学的基本常识告诉我们:由于无法引入有效的竞争机制,政府注定难逃低效的命运。美国联邦政府也不例外。
收集数据、分析数据、发布数据,这一系列和数据有关的信息技术,在商业界其实有个更时尚、更响亮的名字:商务智能。
在商务智能的技术大潮当中,美国联邦政府的做法,只是几朵小小的浪花,公司、大学才是这个领域真正的弄潮儿和领航人。
这股技术浪潮,也在美国起源。
起源:从数据到知识的挑战和跨越
信息消费了什么是很明显的:它消费的是信息接受者的注意力。信息越丰富,就会导致注意力越匮乏……信息并不匮乏,匮乏的是我们处理信息的能力。我们有限的注意力是组织活动的主要瓶颈。02
——赫伯特·西蒙
美国经济学家、政治学家、人工智能的创始人之一,1973年
1946年,人类历史上第一台电子计算机在美国费城问世。03来自匈牙利的移民冯·诺伊曼是这台计算机的主要设计者,他被后世称为“计算机之父”。

赫伯特·西蒙(1916-2001)
20世纪全世界最具影响力的科学家之一,他横跨多个学科和领域,曾获得1975年的图灵奖、1978年的诺贝尔经济学奖、1993年的美国心理协会终身成就奖。(图片来源:卡内基梅隆大学图书馆)
仅一年之后,卡内基梅隆大学的赫伯特·西蒙(Herbert Simon)教授出版了《行政组织的决策过程》一书。在这本被后世视为经典的著作里,他指出,人类的理性是有限的,因此所有的决策都是基于有限理性(Bounded Rationality)的结果。这位天才科学家继而提出,如果能利用存储在计算机里的信息来辅助决策,人类理性的范围将会扩大,决策的质量就能提高。
他进而预测:在后工业时代,也就是信息时代,人类社会面临的中心问题将从如何提高生产率转变为如何更好地利用信息来辅助决策。
西蒙教授毕业于芝加哥大学,1943年获得政治学博士学位,此后半个多世纪,他长期在卡内基梅隆大学任教。
卡内基梅隆大学,是美国信息技术研究的“火车头”,它以计算机科学和“交叉性研究”闻名于世。西蒙的整个学术生涯都浸润着卡内基梅隆的色彩,他从政治、经济出发,把毕生的精力都集中在对决策和信息的研究上,将不同学科之间的“交叉性”应用得炉火纯青,也硕果累累。1975年,由于对人工智能的贡献,他获得了计算机学界的最高奖项:图灵奖;1978年,他又因为对“商务决策过程”的出色研究戴上了诺贝尔经济学奖的桂冠。
追本溯源,学界普遍认为,西蒙对决策支持系统的研究,是现代商务智能概念最早的源头和起点。04但西蒙可能没有想到,他播下的“决策支持”的种子,在半个世纪以后,却结出了“商务智能”的果实,并成为信息时代的一朵奇葩。
从决策支持系统到商务智能,名字变了,但新瓶装的还是旧酒。现代商务智能技术回答的还是决策支持系统面对的老问题:如何将数据、信息转化为知识,扩大人类的理性,辅助决策?
从数据到知识,这个跨越,人类用了半个多世纪。
在半个多世纪的漫长过程中,决策支持系统曾经一度因为缺乏有效的数据组织方式而徘徊不前。直到上世纪90年代,由于若干新技术的出现,打破了瓶颈,“商务智能”的概念才横空出世。随后,其发展取得了前所未有的加速度,在本世纪第一个十年蓬勃向上。今天,回头考察这些新技术的一一出现,可以清楚地看到商务智能的产业链条不断向前延伸的轨迹。
从数据、信息到知识的演变

数据、信息和知识的区别和联系
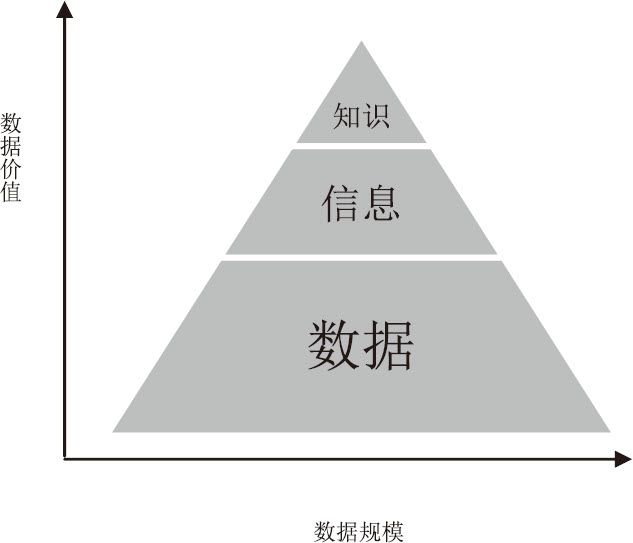
这个轨迹的起点当然就是计算机。计算机,是硬件和软件相结合的产物。它的发明,是诸多不同领域的科学家共同努力的结果。冯·诺伊曼其实是一名数学家,他之所以被称为“计算机之父”,其最大的贡献之一,在于他明确了计算机内部的数据组织形式:二进制。
二进制的引进,解决了在没有“情感、智能和生命”的物理机器中表达、计算、传送数据的最大难题,有了二进制,软件的运行才有了支点。
如前文所述,软件是由程序和数据组成的。二进制的确定,解决了数据在计算机内部传送“理解”和“流动”的问题,但当数据在计算机内部累积得越来越多的时候,如何快速地组织、存储和读取数据又成为新的挑战。
计算机科学家一直在研究数据在软件内部的最佳组织方式。1970年,IBM的研究员埃德加·科德(Edgar Codd)发明了关系型数据库,成为软件发展历史上一个跨越性的里程碑。
此前,数据库的组织结构以网状、层级制为主,复杂多变,程序和数据之间你中有我、我中有你,彼此有很强的依赖性。科德提出的关系型数据库具有结构化高、冗余度低、独立性强等优点,彻底把软件中的程序和数据分立开来。从此,软件的发展成了“两条腿”走路,程序和数据在各自的轨道上自由奔跑。
科德后来又总结出构建关系型数据库的“黄金十二定律”,把理论扎扎实实地推向了实践,关系型数据库开始得到大范围地推广,引发了一场软件领域的革命。科德也因此获得1981年的图灵奖。
此后,大型软件,即大型信息管理系统的应用一日千里、遍地开花。
这些信息系统的建立和运行,使人类从繁杂的重复性劳动当中解放出来,大大提高了商业效率。但这些信息系统,都是针对特定的业务过程、处理离散事务的“运营式”信息系统。
所谓“运营式系统”,是指为提高日常工作的效率而设计的系统,数据在其中的作用,是一个个商务流程的记录,数据在这些系统内不断累积的结果,仅仅用于查询,而不是分析。
上个世纪90年代,面对信息管理系统的普及、各行各业数据记录的激增,管理大师彼得·德鲁克(Peter Drucker)曾发出慨叹:迄今为止,我们的系统产生的还仅仅是数据,而不是信息,更不是知识!05
怎样从各个独立的信息系统中提取、整合有价值的数据,从而实现从数据到信息、从信息到知识、从知识到利润的转化?这个要求,随着信息管理系统的普及,变得越来越迫切。企业的规模越来越庞大、组织越来越复杂,市场更加多变、竞争更加激烈,信息是否及时准确、决策是否正确合理,对组织的兴衰存亡影响越来越大,一步走错,可能全盘皆输。
由于实业界这些迫切的需要,决策支持系统的旧问题又重新占据了顶尖科学家的大脑。
商务智能的“幽灵”开始徘徊……
结蛹:数据仓库之厚积薄发
岳不群叹了口气,缓缓地道:“三十多年前,咱们气宗是少数,剑宗中的师伯、师叔占了大多数。再者,剑宗功夫易于速成,见效极快。大家都练十年,定是剑宗占上风;各练二十年,那便是各擅胜场,难分上下;要到二十年之后,练气宗功夫的才渐渐地越来越强;到得三十年时,练剑宗功夫的便再也不能望气宗之项背了。然而要到二十余年之后,才真正分出高下,这二十余年中双方争斗之烈,可想而知。”
——金庸,《笑傲江湖》第九章,1967年
决策支持系统面临的“瓶颈式”难题,是如何有机地聚集、整合多个不同运营信息系统产生的数据。对这个问题的关注起源于美国计算机科学研究的另一所重镇:麻省理工学院。和卡内基梅隆大学一起,这两所大学先后为现代商务智能的发展奠定了主要的基石。
20世纪70年代,麻省理工学院的研究人员第一次提出,决策支持系统和运营信息系统截然不同,必须分开,这意味着要为前者设计独立的数据存储结构。但受限于当时的数据存储能力,该研究在确立了这一论点后便停滞不前。
但这个研究如灯塔般为实业界指明了方向。1979年,一家以决策支持系统为己任、致力于构建独立数据存储结构的公司Teradata诞生了。Tera,是太字节,其大小为240,Teradata的命名表明了公司处理海量数据的决心。1983年,该公司利用并行处理技术为美国富国银行(Wells Fargo Bank)建立了第一个决策支持系统。这种先发优势令Teradata至今一直雄踞在数据行业的龙头榜首。
另一家信息技术的巨头——国际商业机器公司(IBM)也在为集成企业内不同的运营系统大伤脑筋。越来越多的IBM客户要面对多个分立系统的数据整合问题,这些处理不同事务的系统,由于不同的编码方式和数据结构,像一个个信息孤岛,处于老死不相往来的状态。1988年,为解决企业的数据集成问题,IBM公司的两名研究员(Barry Devlin和Paul Murphy)创造性地提出了一个新的术语:数据仓库(Data Warehouse)。
一声惊雷,似乎宣告了数据仓库的诞生。可惜IBM在首创这个概念之后,也停步不前,只把它当做一个花哨的新名词用于市场宣传,而没有乘胜追击、进一步提出实际的架构和设计。IBM很快在这个领域丧失其领先地位;2008年,IBM甚至通过兼并Cognos才使自己在商务智能的市场上重占一席之地,这是后话。
但这之后,更多的信息技术企业垂涎于数据仓库的“第一桶金”,纷纷开始尝试搭建实验性的数据仓库。
又是几年过去,1992年,尘埃终于落定。比尔·恩门(Bill Inmon)出版了《数据仓库之构建》(Building the Data Warehouse)一书,第一次给出了数据仓库的清晰定义和操作性很强的实战法则,真正拉开了数据仓库走向大规模应用的序幕。恩门不仅是长期活跃在这个领域的理论领军人物,还是一名企业家。此后,他的“江湖地位”也得以确定,被誉为“数据仓库之父”。
恩门所提出的定义至今仍被广泛地接受:
“数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理中的决策制定。”

比尔·恩门:数据仓库之父
2007年曾被《计算机世界》评为近40年计算机产业最具影响力的十大人物之一,目前还活跃在数据仓库领域,他的最新成果是将“非结构化的文本数据”通过特定的工具装入数据仓库。
数据仓库和数据库的最大差别在于,前者是以数据分析、决策支持为目的来组织存储数据,而数据库的主要目的则是为运营性系统保存、查询数据。
江山代有才人出。
恩门一统江湖没多久,风头又被拉尔夫·金博尔(Ralph Kimball)抢了去。金博尔是斯坦福大学毕业的博士,长期在决策支持系统的软件公司工作。1996年,他也出版了一本书:《数据仓库的工具》(The Data Warehouse Toolkit),金博尔在书里认同了比尔·恩门对于数据仓库的定义,但却在具体的构建方法上和他分庭抗礼。

拉尔夫·金博尔
他的数据仓库构建方法目前在市场上占据了主流。和普适计算的创始人马克·韦泽一样,他也曾经在施乐公司的帕罗奥多研究中心(PARC)长期工作过。(图片来源:datamgmt.com网站)
恩门强调数据的一致性,主张由顶至底的构建方法,一上来,就要先创建企业级的数据仓库。金博尔却说:不!务实的数据仓库应该从下往上,从部门到企业,并把部门级的数据仓库叫做“数据集市”(Data Mart)。两人针锋相对,各自的追随者也唇舌相向,很快形成了明显对立的两派。
两派的异同,就好比华山剑法的气宗和剑宗。主张练“气”的着眼全面和长远,耗资大,见效慢;主张练“剑”的强调短、平、快,效果可能立竿见影。
如金庸在《笑傲江湖》中描写的剑气之争一样,两派华山论剑的结果不难猜测,金博尔“从易到难”的架构迎合了人类的普遍心理,大受欢迎,商务界随即掀起了一股创建数据集市的狂潮。“吃螃蟹”的结果,有大面积的企业碰壁撞墙,也有不少企业尝到了甜头,赚了个盆满钵盈。
潮起潮落中,两派又有新的融合和纷争。油灯越拨越亮,道理越辩越明,数据仓库的理论和技术,在争论中不断地得以丰富,到2000年,其理念和架构,已经完全成熟,并被业界所接受。
如蚕之蛹,数据仓库是商务智能的依托,是对海量数据进行分析的核心物理构架。它可以形象地理解为一种格式一致的多源数据存储中心,数据源可以来自多个不同的系统,如企业内部的财务系统、客户管理系统、人力资源系统,甚至是企业外部的系统;这些系统,即使运行的平台不同、编制的语言不同、所处的物理位置不同,但其数据可以按统一定义的格式被提取出来,再通过清洗、转换、集成,最后百流归海,加载进入数据仓库。这个提取、转换、装载的主要过程,可以通过专门的ETL(Extraction, Transformation, Load)工具来实现,这种工具,如今已是数据仓库领域的主打产品。
ETL工具和数据仓库理论的成熟,突破了决策支持系统的瓶颈。从此,商务智能的发展走上了顺风顺水的“快车道”,接下来,好戏连台上演。
蚕动:联机分析之惊艳
当越来越多的组织认识到联机分析的需要以及其带来的巨大收益的时候,分析型的用户就会增加。在人类的历史上,只有很少一部分运筹学专家曾经负有这样的责任:为企业开展如此高端的分析。06
——埃德加·科德,关系型数据库之父,1993年
数据仓库的物理结构出现以后,活跃在前沿的科学家一下子找到了自己的专属“阵地”,商务智能的下一个产业链:联机分析,如水到渠成般迅速形成。数据仓库开始散发真正的魅力。
联机分析(Online Analytical Processing),也称多维分析,本意是把分立的数据库“相联”,进行多维度地分析。
“维”是联机分析的核心概念,指的是人们观察事物、计算数据的特定角度。例如,跨国零售商沃尔玛如果要分析自己的销售量,它可以按时间序列分析、商品门类分析、地区国别分析,也可以按进货渠道分析、客户群体分析,这些不同的分析角度,就叫“维度”。
分析问题的任何角度,都可以视为一个或多个维度的交叉。例如:
沃尔玛2011年在美国纽约州的销售量是多少?这是个“地区”和“时间”两个维度交叉的问题。
沃尔玛2011年在纽约州奶制品的销售量是多少?这是个“地区”、“时间”和“产品类别”三个维度交叉的问题。
沃尔玛2011年在纽约州进口奶制品的销售量是多少?这是个“地区”、“时间”、“产品类别”及“供货渠道”四个维度交叉的问题。
随着维度的不断增多,问题可能变得很复杂。三个维度就是三度空间,也可以想象成一个立方体。一旦超过了三个维度,人类的思维和想象能力就受到了很大的限制。
理解一个维度或两个维度的交叉
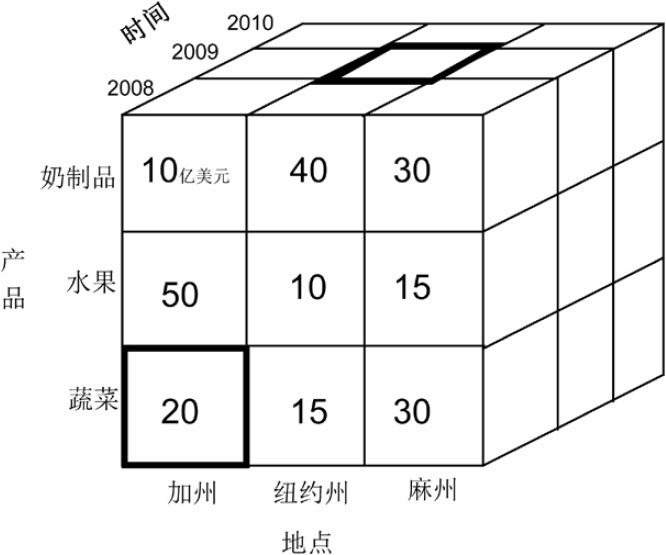
加粗方块(上):表示2009年纽约州奶制品的销售量
加粗方块(下):2008年加州蔬菜的销售量为20亿美元
理解时间、产品和地点三个维度的交叉
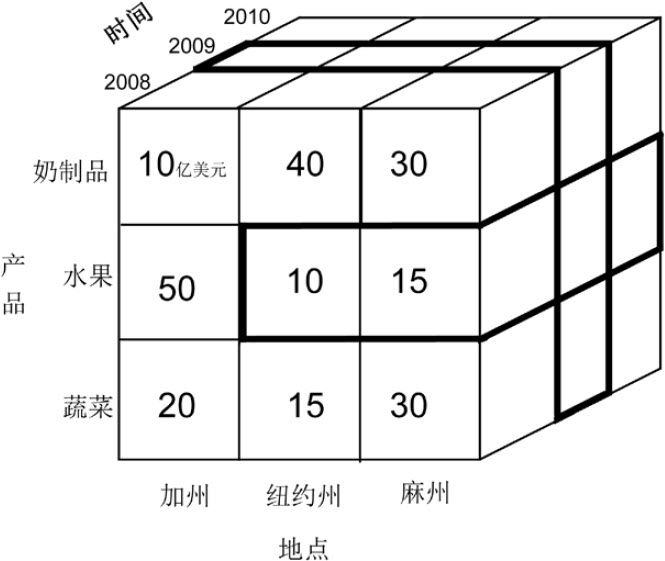
横割(地点和产品两个维度的交叉):所有年份(本图只有2008年至2010年)纽约州和麻州水果的总销量,为横向加粗部分
竖切(时间一个维度):所有州、所有产品(本图只有3个州、3种产品)在2009年的总销量,为纵向加粗部分
说明:为了绘图的方便,这个例子每一个维度只取了3个值。事实上,每个维度的值都可以无限制增加,例如,年份可以增加2005、2006、2007年等,产品可以增加甜点、咖啡等,地点可以增加佛州等。
同时,一个维度,还可以下钻细分(drill down)。例如,就时间的维度而言,问完了一年的销量,分析人员可能会对半年的、一个季度的销量,甚至每个月、每一天的销量感兴趣;又如,就地点的维度而言,知道了纽约州的销量,分析人员可能又立刻想知道某个地区、某个城市甚至某个小区的销量。
和下钻相对应的,是上卷(roll up),例如,从各个州的销量,加总到全美国的销量,就是一个典型的上卷。
理解下钻和上卷
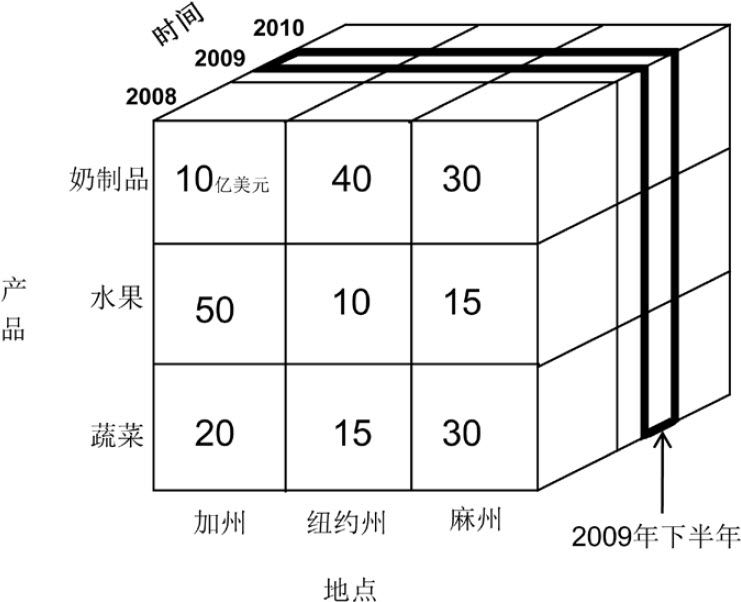
下钻:可以按“年—半年—季度—月—日”的层级一直下钻到每一天加粗部分:下钻到半年——2009年下半年3个州、3种产品的总销量
上卷:这个例子里只有3个州,如果有50个州,就可以上卷到全国
以关系型数据库为基础的运营式信息系统,事实上,也可以回答以上任何一个问题,但它回答问题的方式,是通过事先设计的报表,也就是说,根据用户指定的条件,由软件开发人员事先一一定制,通过“一对一”的查询,将结果通过报表的形式返回给用户。
报表,是关系型数据库时代将数据转化为信息和知识最主要的手段。
基于一或两个维度的分析,是简单报表;交叉的维度越多,报表就越复杂,而且不同维度的组合将产生不同的报表,对一个立足于决策的用户来说,他的需要是“动态”的:他可能问出任意维度交叉和细分的问题,但软件开发人员只能将最常见的问题定制在软件中。没有定制的问题,系统就无法回答。所以,在联机分析技术出现之前,这种静态的、固定的报表根本无法满足决策分析人员的全部需要。

埃德加·科德(1923-2003)
英国人,1948年移居美国,加盟IBM,因提出关系型数据库,获得1981年图灵奖。1993又率先定义了“联机分析”(OLAP)。(图片来源:维基百科)
早在1960年代,研究人员就意识到了这种“动态”决策需求和“静态”报表之间的矛盾,决策支持系统的先行者就开始探索联机分析的方法。1970年,第一个联机分析的产品就已经问世。它通过建立一个复杂的、中介性的“数据综合引擎”,把分布在不同系统的数据库人为地联结起来,实现了联机分析。
1993年,发明关系型数据库的科德再一次站到了创新的潮头。他发表了论文《信息技术的必然:给分析用户提供联机分析》(Providing OLAP to User-Analysts: An IT Mandate),在这篇文章中,他详尽地阐述了联机分析的定义,并为如何构建联机分析提出了“黄金十二定律”。他形象地比喻说:
“用关系型数据库来分析数据,是试图用‘锤子’把一个‘螺丝钉’硬生生地‘敲’进墙,虽然最后可以勉强完成任务,但很费劲,为什么不用‘螺丝刀’呢?”
科德认为,联机分析就是解决“数据分析”问题的“螺丝刀”。其惊艳之美在于用户可以根据自己的需要随时创建“万维”动态报表,也就是说,报表的定制权由后台的开发人员直接转移到了前端的用户。
有了联机分析,用户可以自己随时创建自己所需要的报表,开发人员只需要预先为用户在后台构建多维的数据立方体(Cube)。一旦多维立方体建模完成,用户可以在前端的各个维度之间自由切换,并可以从不同的维度、不同的粒度对数据进行分析,从而获得全面、动态、可随时加总或细分的分析结果。在多维立方体的构建和运算方面,曾在IBM和微软工作过的詹姆斯·格雷(James Gray)多有贡献,他也于1998年获得了图灵奖。
因为有了数据仓库,不再需要不同数据库之间的人为“联机”,联机分析找到了真正的用武之地,如有源之水,活力四射。任何复杂的报表,都可以在鼠标的瞬间点击之下从用户的指尖弹出,数据尽在手中,如玲珑剔透的水晶体,任意横切竖割,流畅的美感令人叹为观止。
破茧:数据挖掘之智能生命的产生
每天早上一醒来,我就要问自己:怎么才能让数据流动得更好、管理得更好、分析得更好?07
——罗林·福特,沃尔玛首席信息官
数据仓库、联机分析技术的发展和成熟,为商务智能奠定了框架,但真正给商务智能赋予“智能”生命的是它的下一个产业链:数据挖掘。
一开始,数据挖掘曾一度被称为“基于数据库的知识发现”(Knowledge discovery in database)。随着数据仓库的产生,“数据挖掘”的叫法开始被广泛接受。也正是因为有了数据仓库的依托,数据挖掘如虎添翼,如“巧妇”走进了“米仓”,在实业界不断创造点“数”成金的故事。其中,最为经典的例子当属啤酒和尿布。
这是一个关于零售帝国沃尔玛的故事。
沃尔玛,是全世界最大的零售商,拥有8400多家分店、200多万雇员;它的人数,和美国联邦政府的雇员等量齐观;它的收入,2010年突破了4000亿美元,超过了很多国家的GDP总值。
沃尔玛拥有世界上数一数二的数据仓库,是最早应用数据挖掘技术的企业之一,也是数据挖掘技术的集大成者。在一次例行的数据分析之后,研究人员突然发现:跟尿布一起搭配购买最多的商品竟是啤酒!
数据挖掘(Data Mining)
数据挖掘是指通过特定的计算机算法对大量的数据进行自动分析,从而揭示数据之间隐藏的关系、模式和趋势,为决策者提供新的知识。
之所以称之为“挖掘”,是比喻在海量数据中寻找知识,就像开矿掘金一样困难。
尿布和啤酒,听起来风马牛不相及,但这是对历史数据进行挖掘的结果,反映的是数据层面的规律。
这种关系令人费解,这是一个真正的规律吗?
经过跟踪调查,研究人员终于发现事出有因:一些年轻的爸爸经常要到超市去购买婴儿尿布,有30%到40%的新爸爸会顺便买点啤酒犒劳自己。沃尔玛随后对啤酒和尿布进行了捆绑销售,不出意料,销售量双双增加。
沃尔玛还有很多利用数据挖掘扩大销售的故事。2004年,分析人员发现,每次飓风来临,一种袋装小食品“Pop-Tarts”的销售量都会明显上升。手电筒、电池、水,这些商品的销量会随着飓风的到来而上升,很容易理解,但Pop-Tarts的上升是不是必然的呢?
研究人员后来发现,这也是一个有用的规律:Pop-Tarts的销量上升,一是因为美国人喜欢甜食,二是因为它在停电时吃起来非常方便。此后,飓风来袭之前,沃尔玛也会提高Pop-Tarts的仓储量,以防脱销,并把它和水捆绑起来销售。
如果没有数据挖掘,Pop-Tarts和飓风的微妙关系就难以被发现。
1989年,可谓数据挖掘技术兴起的元年。
这一年,图灵奖的主办单位计算机协会(ACM)下属的知识发现和数据挖掘小组(SIGKDD)举办了第一届数据挖掘的学术年会,出版了专门期刊。此后,数据挖掘一直被热捧,其发展如火如荼,甚至成为一门独立的课目走进了大学课堂;在美国的不少大学,还先后设立了专门的数据挖掘硕士学位。
也正是1989年,高德纳咨询公司的德斯纳(Howard Dresner)在商业界为“商务智能”给出了一个正式的定义:
“商务智能(Business Intelligence),指的是一系列以事实为支持、辅助商业决策的技术和方法。”
这个定义,强调了商务智能是一系列技术的集合,获得了业界的广泛认同。
商务智能的概念在1989年完全破茧而出,并不是历史的巧合,而是因为数据挖掘这种新技术的出现,使商务智能真正具备了“智能”的内涵,也标志着商务智能完整产业链的形成。
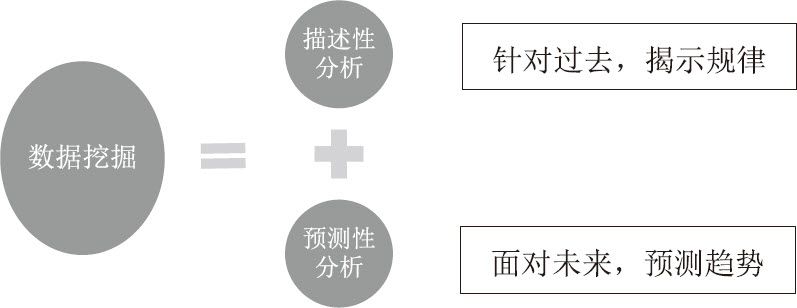
如果说联机分析是对数据的一种透视性的探测,数据挖掘则是对数据进行挖山凿矿式的开采。它的主要目的,一是要发现潜藏在数据表面之下的历史规律,二是对未来进行预测,前者称为描述性分析,后者称为预测性分析。沃尔玛发现的啤酒和尿布的销售关联性就是一种典型的描述性分析;考察所有历史数据,以特定的算法对下个月啤酒的销售量进行估测以确定进货量,则是一种预测性分析。
数据挖掘把数据分析的范围从“已知”扩大到了“未知”,从“过去”推向了“将来”,是商务智能真正的生命力和“灵魂”所在。它的发展和成熟,最终推动了商务智能在各行各业的广泛应用。
数据挖掘的两个侧重点
通过十多年的发展,数据挖掘的范围正在不断扩大。传统的数据挖掘是指在结构化的数据当中发现潜在的关系和规律,但随着商业竞争的白热化,更加高端的数据挖掘也开始初现端倪。例如,通过网络留言挖掘顾客的意见。顾客在博客、论坛、社交网站和微博上用文字记录的消费体验,对商品和服务发表的看法和评价,是一种非结构化的数据。如何把散布在网络上的这些资源整合起来,并从中自动挖掘有价值的信息和知识,正是当前数据挖掘面临的最大挑战之一。数据仓库之父比尔·恩门近年来就在这个领域多有建树。
结构化数据和非结构化数据
按结构,数据可以划分为两类:结构化数据和非结构化数据。
结构化数据是指存储在数据库当中、有统一结构和格式的数据,这种数据,比较容易分析和处理。非结构化数据是指无法用数字或统一的结构来表示的信息,包括各种文档、图像、音频和视频等,这种数据,没有统一的大小和格式,给分析和挖掘带来了更大的挑战。
从结构化数据到非结构化数据的推进,也代表着可供挖掘的数据在大幅增加。
化蝶:数据可视化的华丽上演
图形是解决逻辑问题的视觉方法。08
——杰克·伯廷(1918-2010),法国统计学家,1977年
随着数据仓库、联机分析和数据挖掘技术的不断完善,业界曾一度认为,商务智能系统已经功德圆满,很好地完成了智能分析的使命,因此早期商务智能的产业链条只含有这三块。
但技术无止境。
进入21世纪之后,风生水起,新的技术浪潮又使商务智能的产业链条向前延伸了一大步:数据可视化。
数据可视化(Data Visualization)
数据可视化是指以图形、图像、地图、动画等更为生动、易为理解的方式来展现数据的大小,诠释数据之间的关系和发展的趋势,以期更好地理解、使用数据分析的结果。
数据可视化也是几代统计学家上百年的梦想。
故事可以追溯到19世纪中期。1850年代,土耳其、英、法等国与俄罗斯之间爆发了克里米亚战争。这场战争共死亡50多万人,异常惨烈。弗罗伦斯·南丁格尔(Florence Nightingale)是英国的一名战地护士,也是一名自学成才的统计专家。她在考察了英国士兵的死亡情况之后,发现由于医疗卫生条件恶劣导致的死亡人数,大大超出了前线的直接阵亡人数。南丁格尔将她的统计结果制成一个图表,该图表清晰地反映了“战斗死亡”和“非战斗死亡”两种原因死亡人数的悬殊对比,强烈的视觉效果引起了英国社会的极大反响,最后直接促成了英国政府出台建立野战医院的决定。
南丁格尔后来被誉为现代护理业之母,她的这份图形,是历史上第一份“极区图”(Polar Area Diagram),也是统计学家对利用图形来展示数据进行的早期探索。
1854年4月至1855年3月,英国军队士兵的死亡原因
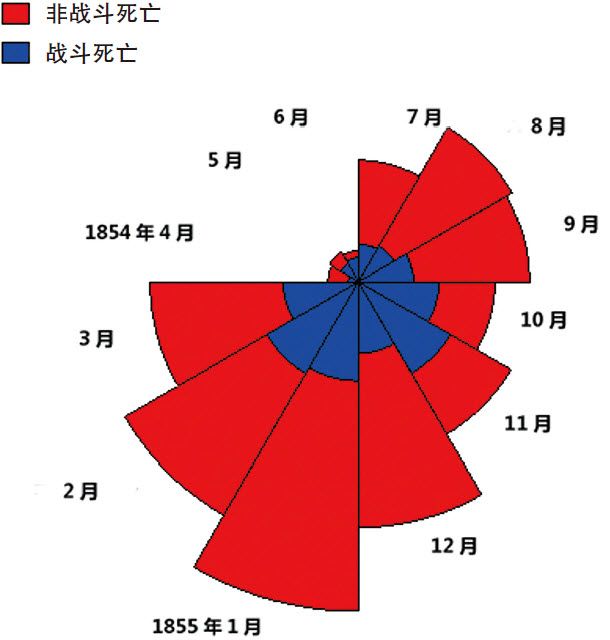
图形说明:每月的死亡人数以30°的扇形面积表示,内环蓝色代表因战斗死亡的人数,外环红色代表非战斗死亡的人数,也就是可以预防、改善的医疗卫生原因。(图片来源:SAS公司)
一份图表催生了一座医院,改变了一个制度。
南丁格尔的贡献,充分证明了数据可视化的价值,特别是在公共领域的价值。官僚们麻木的神经尤其需要强烈的视觉效果来冲击、来刺激。生理学也证明,人的大脑皮层当中,有40%是视觉反应区,人类的神经系统天生就对图像化的信息最为敏感。通过图像,信息的表达和传递将更加直观、快捷、有效。
更重要的原因在于:人的创造力不仅仅取决于逻辑思维,还取决于形象思维。数据可视化的技术,可以通过图像在逻辑思维的基础上进一步激发人的形象思维和空间想象能力,吸引、帮助用户洞察数据之间隐藏的关系和规律。
到了20世纪70年代,由于计算机技术的兴起,美国一批有远见卓识的学者都看到了这个领域巨大的潜力。耶鲁大学的统计学教授弗朗西斯·安斯科姆(F. J. Anscombe)就是其中的先驱人物。1973年,他发表论文《统计分析中的图形》,专门阐述了图形在统计研究当中不可替代的作用。他认为:
“未来的计算机不仅要能计算,还要能将计算结果转变为直观的图形。我们应该研究这两种结果,因为每一种都有助于我们理解问题。”09
在这篇文章中,安斯科姆教授提出了“安斯科姆四重奏”,通过这个例子,他强调:在研究数据、使用数据的时候,图形和计算同等重要,有的时候,图形甚至是解决逻辑问题更为直接有效的方法。
这个著名的“四重奏”,是4组同时呈现在你面前的数据(X,Y)。
当你粗略浏览这4组数据之后,你会感觉其数值大多在5到11之间,比较杂乱。稍做对比,你会发现:
X1=X2=X3
X4的值,除一个之外,全部都等于8
Y1≠Y2≠Y3≠Y4
如果再进行简单的统计学计算,很容易得到以下结果:
X1、X2、X3和X4的平均值都等于9,其方差等于10
Y1、Y2、Y3和Y4的平均值都等于7.50,其方差等于3.75
4组数据都符合线性回归:y=3+0.5x
第一组数据

第二组数据

第三组数据

第四组数据

也就是说:
4组数据当中,X和Y之间的关系都是相同的,个别数据的偏离,可以视为随机产生的干扰。
但当我们用散点图把它们在坐标中标出来之后,面对图形,就会立刻发现,统计学“欺骗”了我们:
4组数据当中,仅仅只有第一组数据严格符合利用统计学作出的线性回归结论;
图形是解决逻辑问题的视觉方法:安斯科姆四重奏的真实分布
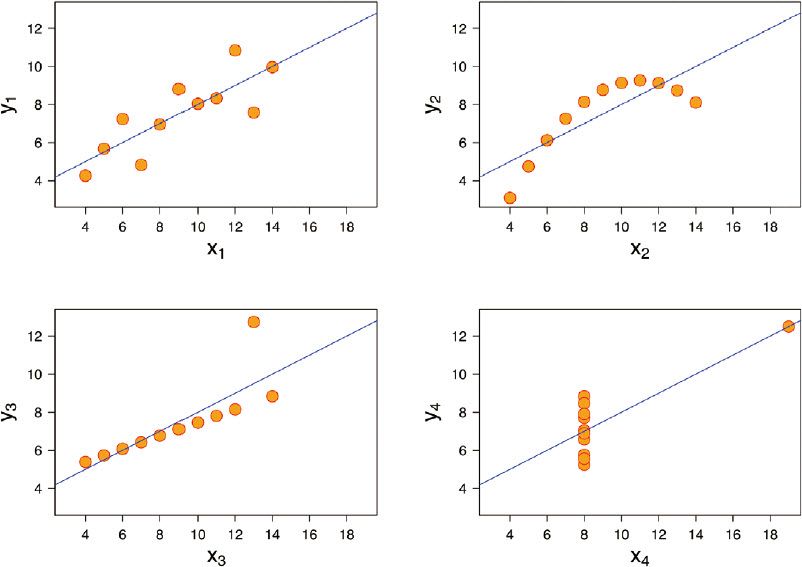
(图片来源:维基百科)
第二组数据存在某种规律,但显然不是线性的;
第三组数据大部分符合线性回归的模型,但有一对数据明显异常,它是第三对数据(13.0,12.74);
第四组数据则呈垂直分布,其之所以貌似符合线性回归的分布,是因为其第8对数据(19.0,12.50)在其中起了很大的扭曲作用。
1983年,耶鲁大学的政治学教授爱德华·塔夫特(Edward Tufte)率先奠基了数据可视化这门学科。塔夫特系统地考证了人类用“图形”表达“数据”和“思想”的渊源,整理了种种历史古籍中的图形瑰宝,并结合计算机的发展给统计领域带来的革命,出版了《定量信息的视觉展示》(The Visual Display of Quantitative Information)一书。这本书后来被公认为“数据可视化”作为一门学科的开山之作。
这本书的出版,也有一段曲折。因为塔夫特整理了从古到今很多优秀的图表,他坚持要在新书中使用高质量、高精度的彩色插图,几乎所有的出版商都认为这是赔本买卖,没人愿意出版。塔夫特最后无计可施,用自己的房子做了抵押,自费出版了这本书。
结果当然令出版商大跌眼镜:这本书最终获得了很大的商业成功,塔夫特教授也由“政治学”专家成功转型为“信息学”专家。近十多年来,他又先后出版了《视觉解释》(Visual Explanations)、《美丽的证据》(Beautiful Evidence)等几本重量级的著作,本本都洛阳纸贵,造成了不小的轰动。他本人也成了数据可视化领域当仁不让的掌门人。2010年3月,奥巴马任命塔夫特为顾问,要求他运用“数据可视化”的技术推进联邦政府专项资金使用情况的透明度。
塔夫特教授强调数据可视化的关键在于“设计”,他认为:
“信息过载这回事并不存在,问题出在糟糕的设计,如果你用来表达数据的图形让人感觉杂乱不解,那就要修改你的设计。”10
进入21世纪之后,大数据的爆炸使人们急需展示数据、理解数据、演绎数据的工具。这种需求,刺激了数据可视化专业市场的形成,其产品迅速增多,使现在的市场可谓绚丽多彩、百花齐放。从最早的点线图、直方图、饼图、网状图等简单图表,发展到以监控商务绩效为主的仪表盘(dashboard)、记分板(scorecard),到以交互式的三维地图、动态模拟、动画技术等等更加直觉化、趣味化的表现方法,曾经冰冷坚硬、枯燥乏味的数据开始“动”了起来、“舞”了起来,变得“性感”!
数据可视化把美学的元素带进了商务智能,给它锦上添花。一幅好的数据图像不仅能有效地传达数据背后的知识和思想,而且华美精致,如一只只振动翅膀的彩蝶,刺激视觉神经,调动美学意识,令人过目不忘,留下栩栩如生的印象。
2010年2月,奥巴马宣布了联邦政府新的年度预算。《华盛顿邮报》立即对这份新鲜出炉的预算进行了分析报道,它利用数据可视化的技术,抓住了读者的眼球。在图形中以线条的粗细表明各项收支金额的大小,左边是收,右边是支,中间的红色部分是赤字缺口,形象贴切。奥巴马政府收入多少钱,要办哪些事,各项收入与支出的轻重大小,一目了然。
奥巴马政府2011年度预算开支的可视化展示
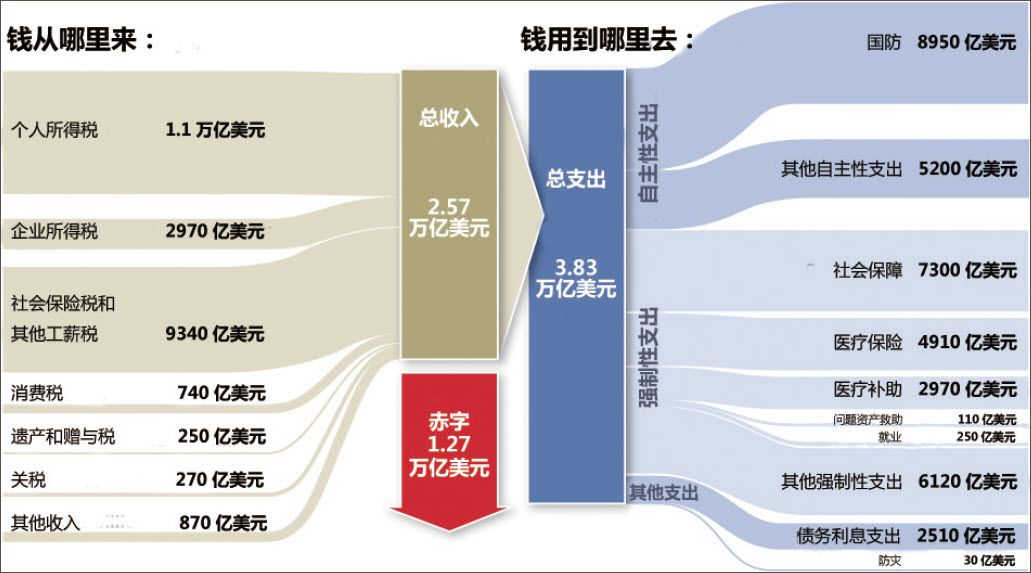
说明:一眼就可以看出,赤字约占美国总支出的1/3,个人所得税是美国政府最大的财政来源,而国防支出是其最大的支出。(图片来源:《华盛顿邮报》,2010年2月1日11)
2012年2月,《纽约时报》又用另外一种形式对2013年联邦政府的预算进行了可视化展示。他们用圆形的大小表示金额的多少,颜色表示增减,绿色代表增加,红色代表缩减,变化额度越大,则颜色越深,而且整个图形是动态的,会放大、缩小、移动,也引起了很多读者的兴趣和转载。12
每年的10月,诺贝尔奖花落谁家是全世界的热门话题。2011年10月,《福布斯》(Forbes)对100多年来各项诺贝尔奖的获得情况做了一个可视化的展示。这是一个以时间为横坐标、以大奖得主的国籍为纵坐标的散点图。不难看出,1940年以前,德国是世界科学和文化的中心,但二次世界大战之后,这个中心毫无疑问转移到了美国。还能看到,美国人的崛起首先在物理领域,其次是医学领域,再次是经济学领域。1969年,开始设立了诺贝尔经济学奖。这之后,美国人几乎囊括了全部的诺贝尔经济学奖。
2013年度联邦政府预算开支的可视化展示
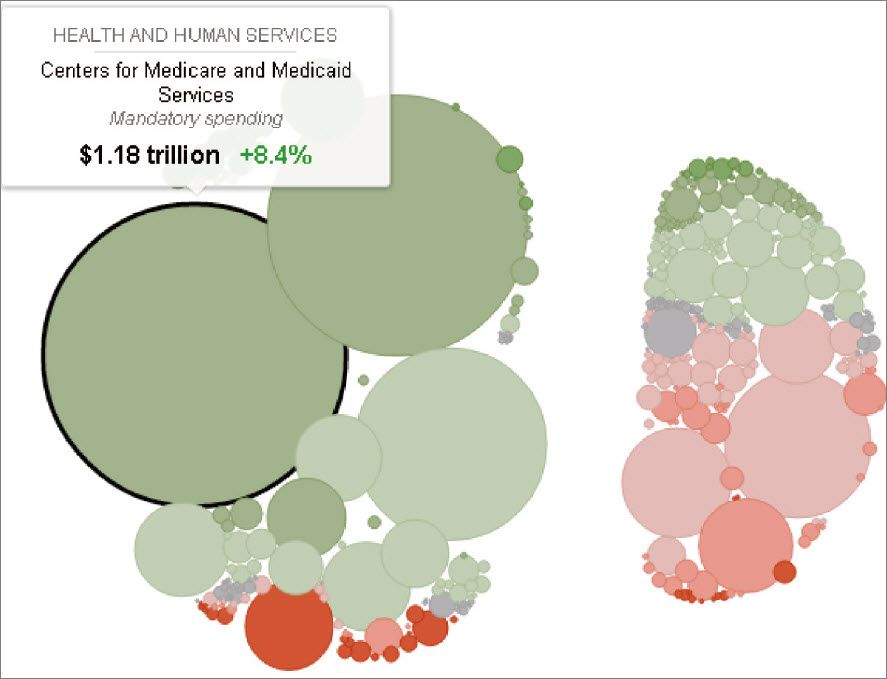
说明:左边为强制性开支,右边为自主性开支。强制开支中最大的圆为医疗保险和医疗补助,其为绿色,表示较去年增加了,鼠标停留处显示其大小为1.18万亿,较去年增加了8.4%,是强制性开支中最大的一块。图为网站截屏。
百年诺贝尔奖得主的分布(按国别和奖项)
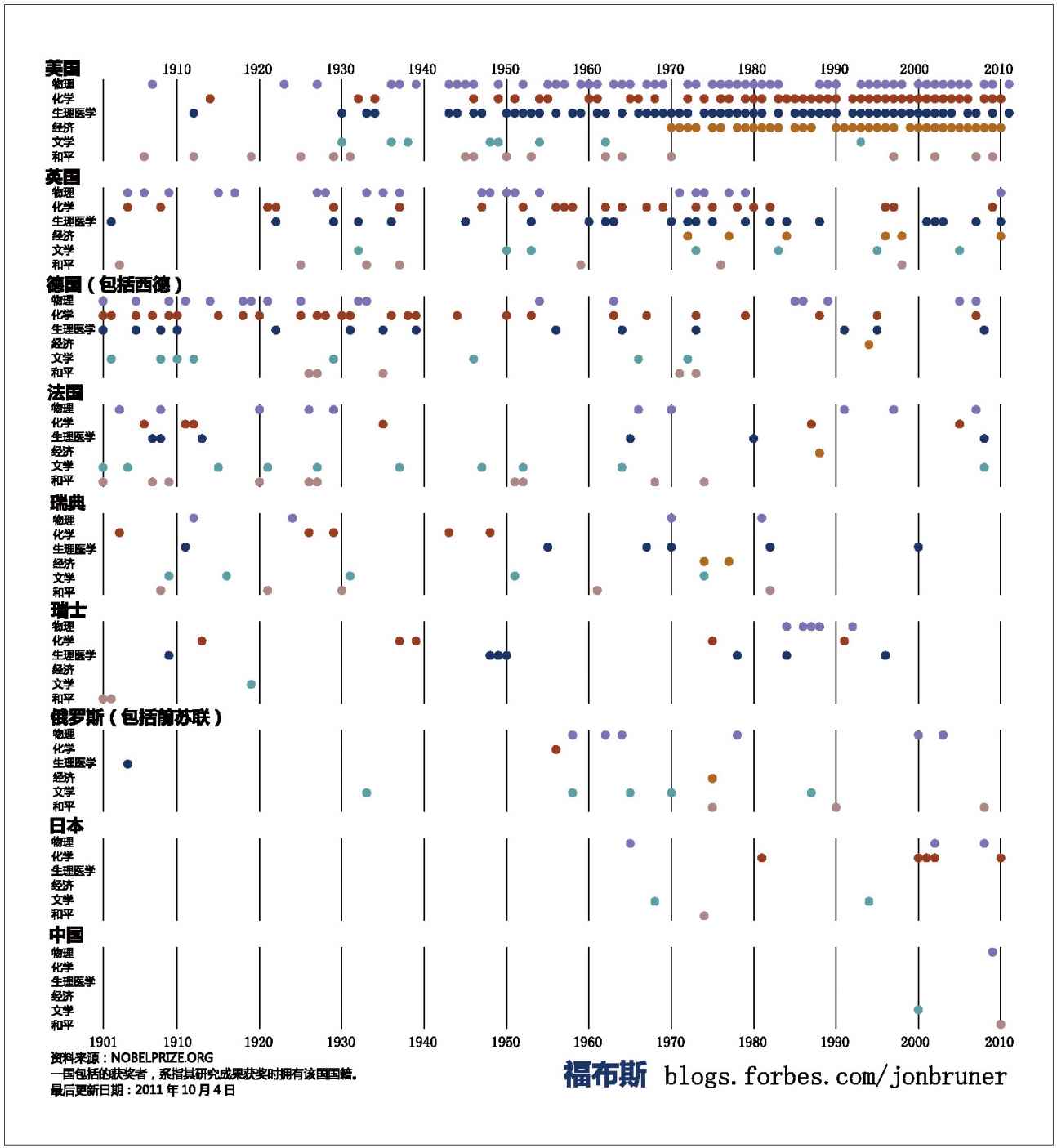
说明:获奖人的国籍,有时候难以甄别,例如,历史上曾出现以难民身份获奖者。又比如,2009年,高锟获物理学奖时,为英国国籍,但持有香港身份证并居住在香港,制作者将他归入中国。制作者还指出:在美国的314位获得者中,有102位(32%)是在美国本土之外出生的,其中有德裔15位、加拿大裔12位、英国裔10位、俄裔6位、华裔6位;而德国的65位获奖者中,只有11位出生在海外;日本的获奖者,则全是在本土出生的。(图片来源:《福布斯》,2011年10月5日)13
作为一个新兴的行业,数据可视化的发展潜力不容小觑。2010年起,谷歌的首席经济学家范里安(Hal Varian)就一直在多种场合强调,下一个十年,将出现一类新的专业人才:数据科学家。其中一种,正是数据可视化工程师,这种人才既懂得数据分析,又精通构图的艺术,集故事讲述和艺术家的特质于一身,将是我们大数据时代的导航员。
数据可视化的这种“导航”作用也极大地推动了商务智能的大众化。通过把复杂的数据转化为直观的图形,并呈现给最普通的用户,商务智能已经不再是少部分高级分析人员的专利,而是贴近大众生活、浅显易懂、人皆可用的工具和手段。
美国联邦政府也意识到“数据可视化”的战略意义。2004年,联邦政府在国土安全部成立了国家可视化分析中心(NVAC),专门推动该项技术在政府部门的应用,特别是在情报分析领域的应用。
可视化技术的出现,使商务智能的产业链形成了一个从数据整合、分析、挖掘到展示的完整闭环。它的起点是多个独立的关系型数据库,经过数据整合之后形成统一的、多源的数据仓库,再根据用户的需要,重新取出若干数据子集,或构造多维立方体(Cube)进行联机分析,或进行数据挖掘,发现潜藏的规律和趋势。如果挖掘的结果经得起现实的检验,那就形成了新的知识,这种知识,还可以通过数据可视化来表达、展示和传递。
商务智能的这四个产业链,每一块都相当复杂,彼此的独立性也很强。一个好的商务智能产品,并不见得一定要面面俱到,时下不少公司,都专注在一个链条上大做文章。
商务智能的历史,是一个渐进的、复杂的演进过程。至今为止,它的内涵和外延,还处于动态的发展之中。它的各个产业链条,还有不断丰富扩大的趋势。特别是作为其“智能灵魂”的数据挖掘技术,潜力非常巨大,可以预见,将对人类社会的发展产生深远的影响。
大数据时代的竞争,将是知识生产率的竞争。以发现新知识为使命的商务智能,无疑是这个时代最为瞩目的竞争利器。
完整的商务智能流程
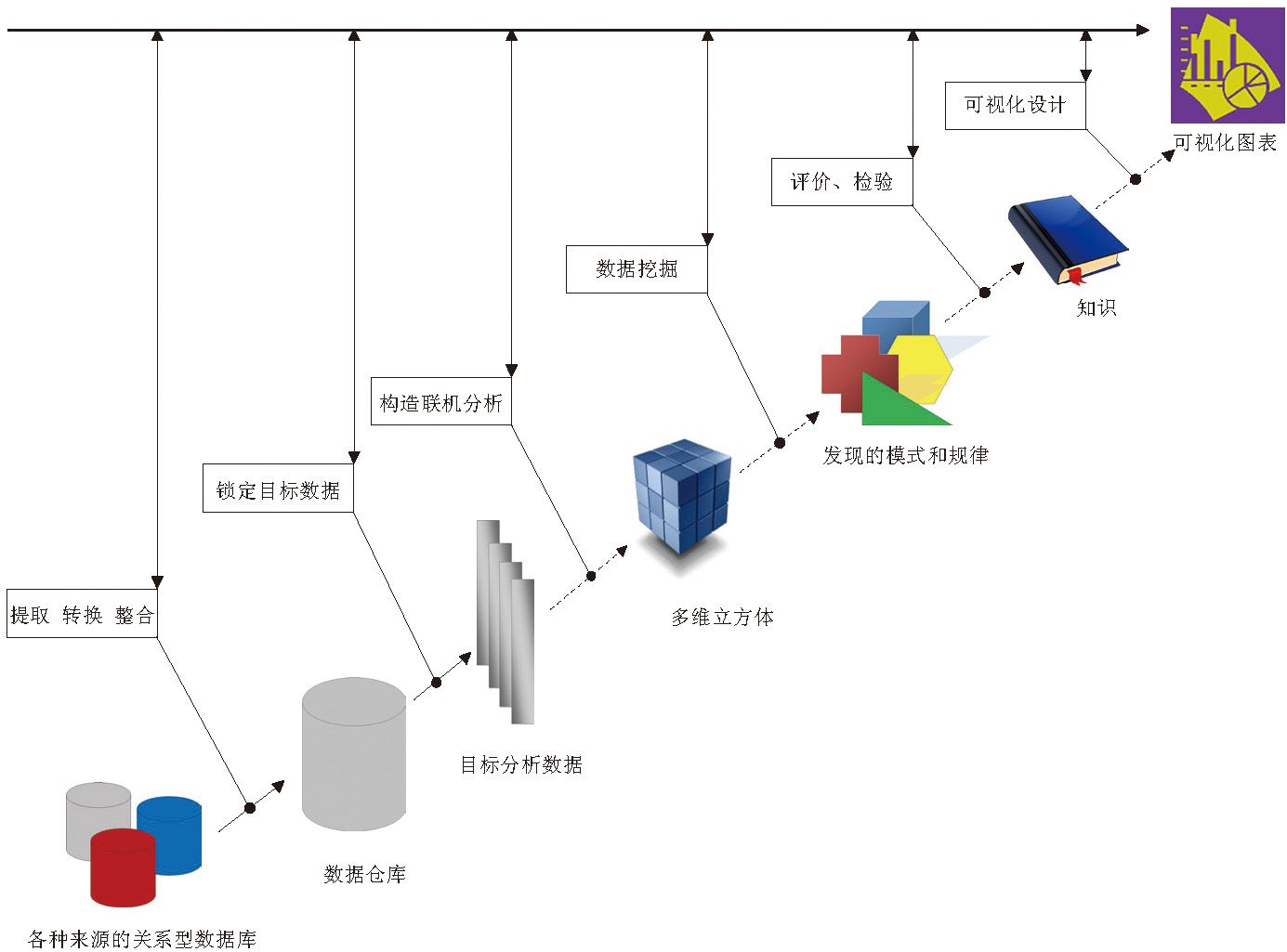
说明:虚线代表可选择路径
注释
01 A Different Game: Information is Transforming Traditional Businesses, Economist, Feb 25th, 2010. 02 英语原文为:“What information consumes is rather obvious: it consumes the attention of its recipients. Hence a wealth of information creates a poverty of attention…The scarce resource is not information; it is processing capacity to attend to information. Attention is the chief bottleneck in organizational activity.”—Designing Organizations for an Information-Rich World, Simon, 1971 03 人类第一台计算机到底在哪年发明的,近年来学界对此有所争议。本书以1946年2月在宾夕法尼亚大学发明的ENIAC计算机为准。 04 数据分析技术,在商业领域多被称为“商务智能”,在政府领域则多被称为决策支持系统。 05 英语原文为:“Our systems are great at producing data but not at producing information. In our daily life, we deal with huge amount of data and information. Data and information is not knowledge until we know how to dig the value out of it.”—Forbes, 24 August 1998 06 英语原文为:“As more and more organizations recognize the need and significant benefit of OLAP, the number of user analysts will increase. Historically, a small number of experts in operations research have been responsible for performing this type of sophisticated analysis for business enterprises.”—Providing OLAP to User-Analysts: An IT Mandate E.F. Codd, 1993 07 英语原文为:“Every day I wake up and ask,‘How can flow the data better, manage data better, analyze data better?’”—Rollin Ford, Chief Information Officer of Wal-Mart 08 英语原文为:“Graphic is the visual means of resolving logical problems.”—Graphics and graphic information processing, P.16, Jacques Bertins, 1977 09 英语原文为:“A computer should make both calculations and graphs. Both sorts of output should be studied; each will contribute to understanding.”—Graphs in Statistical Analysis, F.J. Anscombe, 1973 10 英语原文为:“There is no such thing as information overload, just bad design. If something is cluttered and/or confusing, fix your design.”—Edward Tufte 11 Taking apart the federal budget,Data Source: White House Office of Management and Budget; GRAPHIC: Wilson Andrews, Jacqueline Kazil, Laura Stanton, Karen Yourish. The Washington Post, Feb1, 2010. 图片翻译处理:肖准。 12 Four Ways to Slice Obama's 2013 Budget Proposal, February 12, 2012, New York Time 13 American Leadership in Science, Measured in Nobel Prizes(Infographic), Jon Bruner, Forbes, Oct 5th, 2011. 图片翻译处理:肖准。