第4章 集合类型
04-13Ctrl+D 收藏本站
本章第一节首先介绍了Go语言中的值、指针以及引用类型,因为理解这些概念对于本章的后续节以及本书的后续章节都是必要的。Go语言的指针与C和C++ 中的指针类似,无论是语法上还是语意上。但是Go语言的指针不支持指针运算,这样就消除了在C和C++ 程序中一类潜在的bug。Go语言也不用free函数或者delete操作符,因为Go语言有垃圾回收器,并且自动管理内存[1]。Go语言引用类型的值以一种独特而简单的方式创建,并且一旦创建后就可以像Java或者Python中的对象引用一样使用。Go语言的值的工作方式与其他大多数主流语言一致。
本章的其他节将深入讲解Go语言内置的集合类型。其中包含了Go语言的所有内置类型:数组、切片和映射。这些类型功能齐全并且高效,能够满足大部分需求。标准库中也提供了一些额外的更加特别的集合类型container/heap、container/list和container/ring。这些类型可能在某些特殊情况下更高效。后续章节中有些关于使用堆和列表的小程序(参见9.4.3节)。第6章有个例子,展示了如何创建一个平衡二叉树(参见6.5.3节)。
4.1 值、指针和引用类型
本节我们讨论变量持有什么内容(值、指针以及指向数组、切片和映射的引用),并在接下来的节中讨论如何使用数组、切片和映射。
通常情况下 Go语言的变量持有相应的值。也就是说,我们可以将一个变量想像成它所持有的值来使用。其中有些例外是对于通道、函数、方法、映射以及切片的引用变量,它们持有的都是引用,也即保存指针的变量。
值在传递给函数或者方法的时候会被复制一次。这对于布尔变量或者数值类型来说是非常廉价的,因为每个这样的变量只占1~8个字节。按值传递字符串也非常廉价,因为Go语言中的字符串是不可变的,Go语言编译器会将传递过程进行安全的优化,因此无论传递的字符串长度多少,实际传递的数据量都会非常小。(每个字符串的代价在64位的机器上大概是16字节,在32位的机器上大概是8字节[2]。)当然,如果修改了一个传入的字符串(例如,使用 += 操作符),Go语言必须创建一个新的字符串,并且复制原始的字符串并将其加到该字符串之后,这对于大字符串来说很可能代价非常大。
与C和C++ 不同,Go语言中的数组是按值传递的,因此传递一个大数组的代价非常大。幸运的是,在 Go语言中数组不常用到,因为我们可以使用切片来代替。我们将在下面章节讲解切片的用法。传递一个切片的成本与字符串差不多(在64位机器上为16字节,在32位机器上为12字节),无论该切片的长度或者容量是多大[3]。另外,修改切片也不会导致写时复制的负担,因为不同于字符串的是,切片是可变的(如果一个切片被修改,这些修改对于其他所有指向该切片的引用变量都是可见的)。
图4-1说明了变量及它们所占用内存空间的关系。在图中,内存地址以灰色显示,因为它们是可变的,而粗体则表示变化。
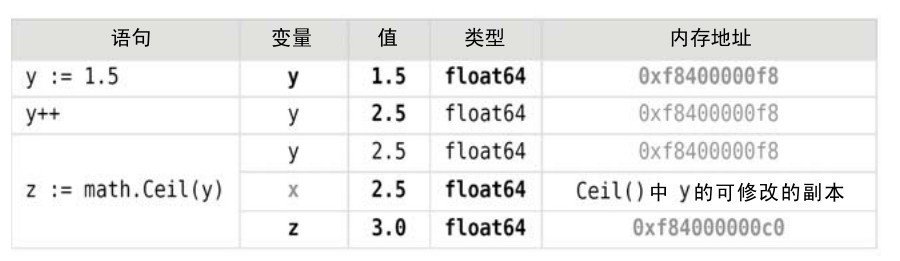
图4-1 简单类型值在内存中的表示
从概念上讲,变量是赋给一内存块的名字,该内存块用于保存特定的数据类型。因此如果我们进行一个短声明y := 1.5,Go语言就会分配一个足够放置一个float64数的内存块(8个字节)并将数字1.5保存到该内存块中。之后只要y还保存在作用域中,Go语言就会将变量y等同于这个内存块。因此如果我们在声明语句后面跟上一条y++ 语句,Go语言将修改变量y对应的内存块中保存的数值。然而如果我们将y传递给一个函数或者方法,Go语言就会传递一个y的副本。从另一方面来讲,Go语言会创建另一个与所调用的函数的参数名相关联的变量,并将y的值复制到为该新变量对应的新内存块中。
有时我们需要一个函数修改我们传入的值。由于值类型是复制的,因此任何修改只作用于其副本,而其原始值将保持不变。同时,传值的成本也可能非常高,因为它们会很大(例如,一个数组或者一个包含许多字段的结构体)。此外,本地变量在不再使用时会被垃圾回收(当它们不再被引用或者不在作用域范围时),然而在许多情况下我们希望自己来管理变量的生命周期而非由它们的作用域决定。
通过使用指针,我们可以让参数的传递成本最低并且内容可修改,而且还可以让变量的生命周期独立于作用域。指针是指保存了另一个变量内存地址的变量。创建的指针是用来指向另一个某种类型的变量,这样就保证了 Go语言知道该指针所指向的值占用多大的空间。我们马上会看到,一个被指针指向的变量可以通过该指针来修改。不管指针所指向值的大小,指针的传递是非常廉价的(64位的机器上占8字节,32位的机器上占4字节)。同时,对于某个指针所指向的变量,只要保证至少有一个指针指向该变量,该变量就会在内存中保存足够长的时间,因此它们的生命周期独立于我们所创建的作用域。[4]
在Go语言中&操作符有多重用处。当用作二元操作符时,它是按位与操作。当用作一元操作符时,它返回的是操作数的地址,该地址可由一个指针保存。在图4-2的第三个语句中,我们将int型变量 x的内存地址赋值给类型为*int的变量pi(指向int型变量的指针)。一元操作符 & 有时也被称为取址操作符。正如图4-2中的箭头所示,术语“指针”也描述了一个事实,即保存了另一变量内存地址的变量通常被认为是“指向”了那个变量。
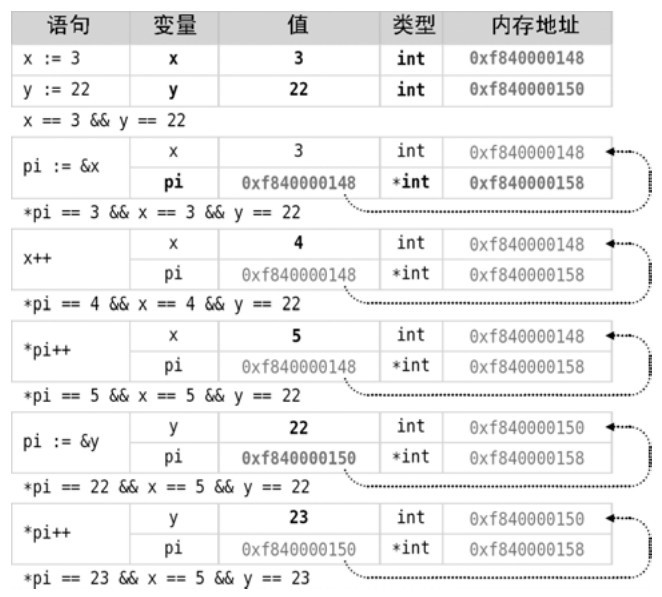
图4-2 指针和值
同样,*操作符也有多重用处。当用作二元操作符时,它将其操作数相乘。而当用作一元操作符时,它返回它所作用的指针所指向变量的值。因此,在图4-2中,pi := &x语句之后*pi和x可以相互交换着使用(但当 pi 被赋值给另一个变量的指针后就不行了)。并且,由于它们与同一块内存地址相关联,任何作用于其中一个变量的改变都会改变另一个。一元操作符*有时也叫做内容操作符、间接操作符或者解引用操作符。
图4-2说明了如果我们将指针所指向变量的值改变,其值如我们所预期的那样改变,并且当我们将该指针解引用时(*pi),它返回修改后的新值。我们也可以通过指针来改变其值。例如,*pi++意味着将指针所指的值增加;当然,这只有在其类型支持++操作符时才能够通过编译,比如Go语言内置的数值类型。
一个指针不必始终指向同一个值。例如,从图4-2的底部开始,我们将一个指针指向了不同的值(pi := &y),然后通过指针来改变其值。我们可以轻易地直接改变y的值(使用y++),然后使用*pi来返回y的新值。
指针也可以指向另一个指针(或者指向指针的指针的指针)。使用指向值的指针叫做间接引用。如果我们使用指向指针的指针,这就叫做使用多重间接引用。这在C和C++中非常普遍,但在Go语言中不常用到,因为Go语言使用引用类型。这里有个简单的例子。
z := 37 // z的类型为int
pi := &z // pi的类型为 *int(指向int型的指针)
ppi := &pi // ppi的类型为 **int (指向int类型指针的指针)
fmt.Println(z, *pi, **ppi)
**ppi++ // 语意上等同于(*(*ppi))++和*(*ppi)++
fmt.Println(z, *pi, **ppi)
37 37 37
38 38 38
在上面的代码片段中,pi是一个*int类型(指向int类型的指针)的指针,它指向一个int类型的变量z,同时ppi是一个指向pi的**int类型的指针(指向int类型指针的指针)。当解引用时,对于每一层的间接引用我们使用*操作符,因此*ppi 解引用 ppi 变量产生一个*int,即一个内存地址,再次应用*操作符(**ppi)时,我们得到所指向的整型值。
除了当做乘法和解引用操作符之外,*操作符也可以当做类型修改符。当一个*置于类型名的左边时,它将原来声明一个特定类型的值的语义修改为了声明一个指向特定类型值的指针。这在图4-2的“类型”一栏中展示。
让我们用一个小例子来解释下目前为止所讨论的内容。
i := 9
j := 5
product := 0
swapAndProduct1(&i, &j, &product)
fmt.Println(i, j, product)
5 9 45
这里我们创建了 3 个类型为整型的变量,并给它们一个初始值。然后我们调用自定义的swapAndProduct1函数。该函数接收3个整型变量指针,保证指针指向的头两个整型数按递增顺序排列,并且让第三个指针指向的整型数赋值为前两个整型数的乘积。由于该函数接受指针而非值类型的参数,我们必须传入指向int类型值的指针,而非该int类型值。每当我们看到取址操作符&被用于函数调用时,我们都要假设对应的变量值可能在函数内被修改。下面是该swapAndProduct1函数的实现。
func swapAndProduct1(x, y, product *int) {
if *x > *y {
*x, *y = *y, *x
}
*product = *x * *y // 编译器也能处理这样的写法:*product=*x**y
}
函数的参数声明*int使用*类型修改符来声明其参数全是指向整型数的指针。当然,这也意味着我们只能传入指向整型变量的指针(使用取址操作符 &),而非传入整型变量或者整型数。
在函数内部,我们更关心指针所指向的值,因此我们从头到尾都使用解引用操作符*。在最后一个可执行的行中,我们将两个指针所指向的值乘起来,然后将其结果赋值给另一个指针所指向的变量。当有两个连续的*出现时,Go语言会根据上下文将其识别成乘法而非两个解引用。在函数内部,指针是x、y和product,但是在函数调用处,它们所指向的值为3个整型变量i、j和product。
在C和早期的C++代码中,用这种方式实现函数是非常普遍的现象,但在Go语言中这种写法不是必须的。如果我们只有一个或者不多的几个值,在 Go语言中更符合常规的做法是直接返回它们,而如果有许多值要传递的话,以切片或者映射(我们马上会看到,无需指针也可以非常廉价地传递它们)的形式传递就可以了,如果它们的类型不一致则将其放在一个结构体中再用指针传递。这里有个没用到指针的更简单的改进版。
i := 9
j := 5
i, j, product := swapAndProduct2(i, j)
fmt.Println(i, j, product)
5 9 45
这里是我们所写的对应的swapAndProduct2函数。
func swapAndProduct2(x, y int) (int, int, int) {
if x > y {
x, y = y, x
}
return x, y, x * y
}
这个版本的函数应该比第一个版本清晰多了,但没用指针也导致了该函数不能就地交换数据。
在C和C++中,函数参数包含一个布尔类型指针来表示成功或者失败的做法是很常见的。这在Go语言中可以通过在函数签名处包含一个*bool变量来实现,但直接以最后一个返回值的形式返回一个布尔型的成功标志(或者最好是一个error值)的写法更好用,这也是Go语言的推荐做法。
在目前为止已经展示的代码片段中,我们使用取址操作符&来取得函数参数或者本地变量的地址。Go语言的自动内存管理机制使得这样做非常安全,因为只要一个指针引用一个变量,那个变量就会在内存中得以保留。这也是为什么在 Go语言的函数内部返回指向本地变量的指针是安全的(在C/C++中,对于非静态变量的同样操作将是灾难)。
在某些场景下,我们需要传递非引用类型的可修改值,或者需要高效地传入大类型的值,这个时候我们需要用到指针。Go语言提供了两种创建变量的语法,同时获得指向它们的指针。其中一种方法是使用内置的new函数,另一种方法是使用地址操作符。为了比较一下,我们将介绍这两种语法,并用两种语法分别创建一个扁平结构的结构体类型值。
type composer struct{
name string
birthYear int
}
给定这个结构体定义,我们可以创建 composer 值或指向 composer 值的指针,即*composer类型的变量。在这两种情况下,我们都可以利用Go语言对结构体初始化的支持使用大括号来初始化数据。
antónio := composer{"António Teixeira", 1707} // composer类型值
agnes := new(composer) // 指向composer的指针
agnes.name, agnes.birthYear = "Agnes Zimmermann", 1845
julia := &composer{} // 指向composer的指针
julia.name, julia.birthYear = "Julia Ward Howe", 1819
augusta := &composer{"Augusta Holmès", 1847} // 指向composer的指针
fmt.Println(antónio)
fmt.Println(agnes, augusta, julia)
{António Teixeira 1707}
&{Agnes Zimmermann 1845} &{Augusta Holmès 1847} &{Julia Ward Howe 1819}
当 Go语言打印指向结构体的指针时,它会打印解引用后的结构体内容,但会将取址操作符&作为前缀来表示它是一个指针。上面创建了agnes和julia两个指针的代码片段用于解释以下两种用法的等同性,只要其类型可以使用大括号进行初始化:
new(Type) ≡&Type{}
这两种语法都分配了一个Type类型的空值,同时返回一个指向该值的指针。如果Type不是一个可以使用大括号初始化的类型,我们只可以使用内置的new函数。当然,我们不必担心该值的生命周期或怎么将其删除,因为Go语言的内存管理系统会帮我们打理一切。
使用结构体的&Type{}语法的一个好处是我们可以为其指定初始值,正如我们这里创建augusta指针时所做的那样(后面我们将看到,我们也可以只声明一些可选的字段而将其他字段设为它们的0值,参见6.4节)。
除了值和指针之外,Go语言也有引用类型(另外Go语言还有接口类型,但在大多数实际使用中我们可以把接口看成某种类型的引用,引用类型将在本书稍后介绍,参见6.3节)。一个引用类型的变量指向内存中某个隐藏的值,它保存着实际的数据。保存引用类型的变量传递时也非常廉价(在64位机器上一个切片占16字节,一个映射占8字节),其使用语法与值一样(我们不必取得一个引用类型的地址,在需要得到该引用所指的值时也无需解引用它)。
一旦我们遇到需要在一个函数或方法中返回超过四五个值的情况时,如果这些值是同一类型的话最好使用一个切片来传递,如果其值类型各异则最好传递一个指向结构体的指针。传递一个切片或一个指向结构体的指针的成本都比较低,同时也允许我们修改数据。让我们用一些小例子来解释这些。
grades := int{87, 55, 43, 71, 60, 43, 32, 19, 63}
inflate(grades, 3)
fmt.Println(grades)
[261 165 129 213 180 129 96 57 189]
这里我们在一个整型切片之上进行一个操作。映射和切片都是引用类型,并且映射或者切片项中的任何修改(无论是直接的还是在它们所传入的函数中间接的修改)对于引用它们的变量来说都是可见的。
func inflate(numbers int, factor int) {
for i := range numbers {
numbers[i] *= factor
}
}
grades切片作为参数numbers传入函数。但与传入值不同的是,任何作用于numbers的更改都会作用于grades,因为它们都指向同一个切片。
由于我们希望原地修改切片的值,所以使用了一个循环来轮流获得其中的值。我们没有使用for index、item...range这样的循环是因为这样只能得到其所操作的切片元素的副本,导致其副本与因数相乘之后将该值丢弃,而原始切片的值则保持不变。我们本来可以使用更熟悉的类似于其他语言的for循环(例如for i := 0; i < len(numbers); i++),但我们可以使用更为方便的for index := range语法(下一章会讲解所有的for循环语法,参见5.3节)。
我们假设有一个矩形类型,将一个矩形的位置保存为左上角和右下角的x、y 坐标以及机器填充色。我们可以将该矩形的数据表示成一个结构体。
type rectangle struct {
x0, y0, x1, y1 int
fill color.RGBA
}
现在我们可以创建一个矩形类型的值,打印它的内容,调整大小,然后再打印它的内容。
rect := rectangle{4, 8, 20, color.RGBA{0xFF, 0, 0, 0xFF}}
fmt.Println(rect)
resizeRect(&rect, 5, 5)
fmt.Println(rect)
{4 8 20 10 {255 0 0 255}}
{4 8 25 15 {255 0 0 255}}
正如我们在前面章节所提到的,虽然 Go语言不认识我们所定义的矩形类型,但它还是能够用合适的格式将其打印出来。代码下面的输出清楚地显示出resizeRect功能的正确性。与传入整个矩形(其中的整型至少占16字节)不同的是,我们只传入其地址(无论结构体多大,在64位系统中都是8字节)。
func resizeRect(rect *rectangle, Δwidth, Δheight int) {
(*rect).x1 += Δwidth // 令人厌恶的显式解引用
rect.y1 += Δheight // "."操作符能够自动解引用结构体
}
函数的第一个语句使用显式的解引用操作,展示了其底层发生的操作。(*rect)引用的是该指针所指出的矩形值,其中的.x1引用矩形的x1字段。第二个语句所给出的才是使用结构体值的常用方法。结构体指针也使用与第二个语句一样的语法,在这种情况下,需依赖 Go语言来为我们解引用。之所以这样是因为,Go语言的.(点)操作符能够自动地将指针解引用为它所指向的结构体[5]。
Go语言中有些类型是引用类型:映射、切片、通道、函数和方法。与指针不同的是,引用类型没有特殊的语法,因为它们就像值一样。指针也可以指向一个引用类型,虽然它只对切片有用,但有时这个用法也很关键(我们将在下一章节中看到使用指向切片的指针的案例,参见5.7节)。
如果我们定义了一个变量来保存一个函数,该变量得到的实际是该函数的引用。函数引用知道它们所引用的函数的签名,因此不能传递一个签名不匹配的函数引用。这也消除了一些在某些语言中可能发生的非常麻烦的错误和崩溃,因为这些语言在使用函数指针时不保证这些函数的签名正确。我们已经看到了一些传入函数引用的例子,比如当我们传递一个映射函数给strings.Map函数时。我们会在本书余下的部分看到更多使用指针和引用类型的例子。
4.2 数组和切片
Go语言的数组是一个定长的序列,其中的元素类型相同。多维数组可以简单地使用自身为数组的元素来创建。
数组的元素使用操作符来索引,索引从0开始。因此一个数组的首元素是array[0],其最后元素是array[len(array)-1]。数组是可更改的,因此我们使用将array[index]放置在赋值操作符的左边这样的语法来设置index位置处的元素内容。我们也可以在一个赋值语句的右边或者一个函数调用中使用该语法,以获得该元素。
数组使用以下语法创建:
[length]Type
[N]Type{value1, value2,..., valueN}
[...]Type{value1, value2,..., valueN}
如果在这种场景中使用了...(省略符)操作符,Go语言会为我们自动计算数组的长度。(我们将在本章后面及第5章看到,这个省略操作符也可以用于其他目的。)在任何情况下,一个数组的长度都是固定的并且不可修改。
以下示例展示了如何创建和索引数组。
var buffer [20]byte
var grid1 [3][3]int
grid1[1][0], grid1[1][1], grid1[1][2] = 8, 6, 2
grid2 := [3][3]int{{4, 3}, {8, 6, 2}}
cities := [...]string{"Shanghai", "Mumbai", "Istanbul", "Beijing"}
cities[len(cities)-1] = "Karachi"
fmt.Println("Type Len Contents")
fmt.Printf("%-8T %2d %v\n", buffer, len(buffer), buffer)
fmt.Printf("%-8T %2d %q\n", cities, len(cities), cities)
fmt.Printf("%-8T %2d %v\n", grid1, len(grid1), grid1)
fmt.Printf("%-8T %2d %v\n", grid2, len(grid2), grid2)
Type Len Contents
[20]uint8 20 [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[4]string 4 ["Shanghai" "Mumbai" "Istanbul" "Karachi"]
[3][3]int 3[[000][862][000]]
[3][3]int 3[[430][862][000]]
正如上面的buffer、grid1和grid2变量所展示的,当创建数组时,如果没有被显式地初始化或者只是部分初始化,Go语言会保证数组的所有项都被初始化成其相应的零值。
数组的长度可以使用len函数获得。由于数组的长度是固定的,因此它们的容量总是等于其长度,对于数组而言cap函数和len函数返回的数字一样。数组可以使用与字符串或者切片一样的语法进行切片,只是其结果为一个切片,而非数组。同时,就像字符串和切片一样,数组也可以使用for...range循环来进行迭代(参见5.3节)。
一般而言,Go语言的切片比数组更加灵活、强大且方便。数组是按值传递的(即传递副本,虽然可以通过传递指针来避免)而不管切片的长度和容量如何,传递成本都会比较小,因为它们是引用。(无论包含了多少个元素,一个切片在64位机器上是以16字节的值进行传递的,在32位机器上是以12字节的值进行传递的。)数组是定长的,而切片可以调整长度。Go语言标准库中的所有公开函数使用的都是切片而非数组[6]。我们建议使用切片来代替数组,除非在特殊的案例下有非常特别的需求必须用数组。数组和切片都可以使用表4-1中所给出的语法来进行切片。
表4-1 切片操作

Go语言中的切片是长度可变、容量固定的相同类型元素的序列。我们将在后文看到,虽然切片的容量固定,但也可以通过将其切片来收缩或者使用内置的append函数来增长。多维切片可以自然地使用类型为切片的元素来创建,并且多维切片内部的切片长度也可变。
虽然数组和切片所保存的元素类型相同,但在实际使用中并不受此限。这是因为其类型可以是一个接口。因此我们可以保存任意满足所声明的接口的元素(即它们定义了该接口所需的方法)。然后我们可以让一个数组或者切片为空接口interface{},这意味着我们可以存储任意类型的元素,虽然这会导致我们在获取一个元素时需要使用类型断言或者类型转变,或者两者配合使用。(接口会在第6章讲到。反射的内容参见9.4.9节。)
我们可以使用以下语法创建切片:
make(Type, length, c apacity)
make(Type, length)
Type{}
Type{value1, value2,..., valueN}
内置函数 make用于创建切片、映射和通道。当用于创建一个切片时,它会创建一个隐藏的初始化为零值的数组,然后返回一个引用该隐藏数组的切片。该隐藏的数组与 Go语言中的所有数组一样,都是固定长度的,如果使用第一种语法创建,那么其长度即为切片的容量;如果使用第二种语法创建,那么其长度即为切片的长度;如果使用复合语法创建(第三种或者第四种),那么其长度为大括号中项的个数。
一个切片的容量即为其隐藏数组的长度,而其长度则为不超过该容量的任意值。在第一种语法中,切片的长度必须小于或者等于容量,虽然这种语法一般也是在我们希望其初始长度小于容量的时候才使用。第二种、第三种和第四种语法都是用于当我们希望其长度和容量相同时。复合语法(第四种)非常方便,因为它允许我们使用一些初始值来创建切片。
语法Type{}与语法 make(Type, 0)等价,两者都创建一个空切片。这并不是无用的,因为我们可以使用内置的append函数来有效地增加切片的容量。然而在实际使用中如果我们需要一个初始化为空的切片,使用make函数来创建会更实用,只需将长度设为0,并且将容量设为一个我们估计该切片需要保存的元素个数。
一个切片的索引位置范围为从 0 到 len(slice)-1。一个切片可以再重新切片以减小长度,并且如果一个切片的长度小于其容量值,那么该切片也可以重新切片以将其长度增长为容量值。我们将在后文提到,可以使用内置的append函数来增加切片的容量。
图4-3从概念的视角给出了切片与其隐藏数组的关系。下面这些是它所给出的切片。
s := string{"A", "B", "C", "D", "E", "F", "G"}
t := s[:5] // [A B C D E]
u := s[3 : len(s)-1] // [D E F]
fmt.Println(s, t, u)
u[1] = "X"
fmt.Println(s, t, u)
[A B C D E F G] [A B C D E] [D E F]
[A B C D x F G] [A B C D x] [D x F]
由于切片s、t和u都是同一个底层数组的引用,其中一个改变会影响到其他所有指向该相同数组的任何其他引用。
s := new([7]string)[:]
s[0], s[1], s[2], s[3], s[4], s[5], s[6] = "A", "B", "C", "D", "E", "F","G"
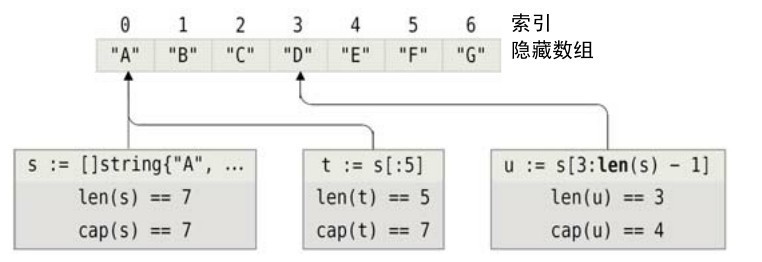
图4-3 切片与其底层数组的概念图
使用内置的make函数或者复合语法是创建切片的最好方式,但是这里我们给出了一种在实际中不常用到但是能够很明显地说明数组及其切片之间关系的方法。第一条语句使用内置的new函数创建一个指向数组的指针,然后立即取得该数组的切片。这会创建一个其长度和容量都与数组的长度相等的切片,但是所有元素都会被初始化为零值(在这里是空字符串)。第二条语句通过将每个元素设置成我们想要的初始值来完成整个切片的设置。设置完成之后,该切片与上文中使用复合语法创建的切片完全一样。
下面基于切片的例子除了我们将buffer的容量设为大于其长度以演示如何使用外,与我们之前所看到的基于数组的例子功能完全一致。
bufer := make(byte, 20, 60)
grid1 := make(int, 3)
for i := range grid1 {
grid1[i] = make(int, 3)
}
grid1[1][0], grid1[1][1], grid1[1][2] = 8, 6, 2
grid2 := int{{4, 3, 0}, {8, 6, 2}, {0, 0, 0}}
cities := string{"Shanghai", "Mumbai", "Istanbul", "Beijing"}
cities[len(cities)-1] = "Karachi"
fmt.Println("Type Len Cap Contents")
fmt.Printf("%-8T %2d %3d %v\n", buffer, len(buffer), cap(buffer), buffer)
fmt.Printf("%-8T %2d %3d %q\n", cities, len(cities), cap(cities), cities)
fmt.Printf("%-8T %2d %3d %v\n", grid1, len(grid1), cap(grid1), grid1)
fmt.Printf("%-8T %2d %3d %v\n", grid1, len(grid2), cap(grid2), grid2)
Type Len Cap Contents
unit8 20 60[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
string 4 4["Shanghai" "Mumbai" "Istanbul" "Karachi"]
int 3 3 [[0 0 0] [8 6 2] [0 0 0]]
int 3 3 [[4 3 0] [8 6 2] [0 0 0]]
buffer的内容仅仅是前面 len(buffer)个项,除非我们将其重新切片,否则我们将无法取到其他元素。后面几节会讲到如何重新做切片。
我们使用初始值长度为3(即包含3个切片)和容量为3(由于无特殊说明的情况下默认初始容量的值为其长度)来创建一个切片的切片grid1。然后我们为grid1最外层的切片的每一项设置成包含它们自身的切片,该包含的切片也含有3个项。自然地,我们也可以让最内层的切片长度不一。
对于grid2我们必须声明每一个值,因为使用了复合语法来创建它,而Go语言没有其他方法来知道我们需要多少个项。总之,我们创建了一个包含不同长度切片的切片,例如grid2 :=int{{9,7}, {8}, {4, 2, 6}}可以使得grid2是一个长度为3并且包含3个长度分别为2, 1和3的切片的切片。
4.2.1 索引与分割切片
一个切片是一个隐藏数组的引用,并且对于该切片的切片也引用同一个数组。这里有一个例子可以解释上面所提到的。
s := string{"A", "B", "C", "D", "E", "F", "G"}
t := s[2:6]
fmt.Println(t, s, "=", s[:4], "+", s[4:])
s[3] = "x"
t[len(t)-1] = "y"
fmt.Println(t, s, "=", s[:4], "+", s[4:])
[C D E F] [A B C D E F G] = [A B C D] + [E F G]
[C x E y] [A B C x E y G] = [A B C x] + [E y G]
我们可以改变数据,无论是通过原始切片s还是通过切片s的切片t,它们的底层数据都改变了,因此两个切片都受影响。上面的代码片段也说明,对于一个切片s和一个索引值i(0 <=i <= len(s)),s等于s[:i]与s[i:]的连接。在前面章节中讲字符串引用的时候我们也看到了类似的相等性:
s == s[:i] + s[i:] // s是一个字符串,i是整型,0 <= i <= len(s)
图4-4 展示了切片s,包括它所有有效的索引位置和上面代码中用到的切片。任何切片中的第一个索引位置都为0,而最后一个则为len(s) - 1。
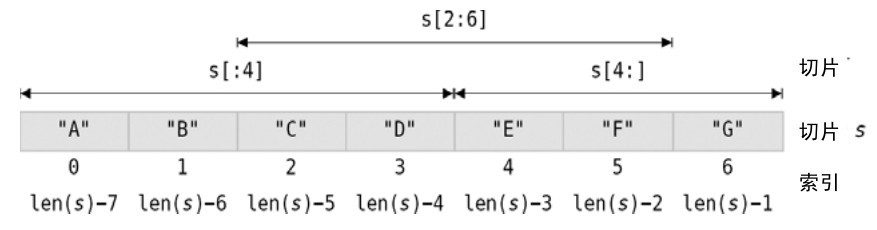
图4-4 切片剖析
与字符串不同的是,切片不支持+或者+=操作符,然而可以很容易地往切片后面追加以及插入和删除元素,我们随后将看到(参见4.2.3节)。
4.2.2 遍历切片
一个常用到的需求是遍历一个切片中的元素。如果我们想要取得切片中的某个元素而不想修改它,那我们可以使用for...range循环,如果想要修改它则可以使用带循环计数器的for循环。关于前者,这里有一个例子。
amounts := float64{237.81, 261.87, 273.93, 279.99, 281.07, 303.17,
231.47, 227.33, 209.23, 197.09}
sum := 0.0
for _, amount := range amounts {
sum += amount
}
fmt.Printf("Σ %.1f→ %.1f\n", amounts, sum)
Σ[237.8 261.9 273.9 280.0 281.1 303.2 231.5 227.3 209.2 197.1]→2503.0
for...range循环首先初始化一个从0开始的循环计数器,在本例中我们使用空白符将该值丢弃(_),然后是从切片中复制对应元素。这种复制即使对于字符串来说也是代价很小的(因为它们按引用传递)。这意味着任何作用于该项的修改都只作用于该副本,而非切片中的项。
自然地,我们可以使用切片的方式来遍历切片中的一部分。例如,如果我们想要遍历切片的前5个元素,我们可以这样写for _, amount := range amounts[:5]。
如果我们想修改切片中的项,我们必须使用可以提供有效切片索引而非仅仅是元素副本的for循环。
for i := range amounts {
amounts[i] *= 1.05
sum += amounts[i]
}
fmt.Printf("Σ %.1f→ %.1f\n", amounts, sum)
Σ[249.7 275.0 287.6 294.0 295.1 318.3 243.0 238.7 219.7 206.9]→2628.1
这里我们将切片中的每个元素值增加了5%,并将其总和累加起来。
当然,切片也可以包含自定义类型的元素。以下是包含了一个自定义方法的自定义类型。
type Product struct {
name string
price float64
}
func (product Product) String string{
return fmt.Sprintf("%s (%.2f)", product.name, product.price)
}
这里将Product类型定义为一个包含一个字符串和一个float64类型字段的结构体。我们同时也定义了String方法来控制Go语言如何使用 %v格式符输出Product的内容(我们之前介绍了打印格式符,参见3.5节。在1.5节中我们简单地引入了自定义类型和方法。第6章将提供更多的内容。)
products := *Product{{"Spanner", 3.99}, {"Wrench", 2.49},
{"Screwdriver", 1.99}}
fmt.Println(products)
for _, product := range products {
product.price += 0.50
}
fmt.Println(products)
[Spanner (3.99) Wrench (2.49) Screwdriver (1.99)]
[Spanner (4.49) Wrench (2.99) Screwdriver (2.49)]
这里我们创建了一个包含指向 Product 指针(*Product)的切片,然后立即使用 3 个*Product 来将其初始化。之所以可以这样做是因为 Go语言足够灵活能够识别出来一个*Product需要的是指向Product的指针。我们这里所写的只是products := *Product{&Product{"Spanner", 3.99}, &Product{"Wrench", 2.49}, &Product{"Scre wdriver", 1.99}}的简化版(在4.1节中,我们使用&Type{}来创建一个该类型的新值,并立即得到了一个指向它的指针)。
如果我们没有定义Product.String方法,那么格式符%v(该格式符在fmt.Println以及类似的函数中被显式地调用)输出的就是Product的内存地址,而非Product的内容。同时需注意的是Product.String 方法接收一个Product值,而非一个指针。然而这不成问题,因为Go语言足够聪明,当需要传值的地方传入的是一个指针的时候,Go会自动将其解引用[7]。
我们之前也提到for...range循环不能用于修改所遍历元素的值,然而在这里我们成功地将切片中所有产品的价格都增加了。在每一次遍历中,变量 product 被赋值为一个*Product副本,这是一个指向products所对应的底层Product的指针。因此,我们所做的修改是作用于指针所指向的值,而非*Product指针的副本。
4.2.3 修改切片
如果我们需要往切片中追加元素,可以使用内置的append函数。这个函数接受一个需要被追加的切片,以及一个或者多个需要被追加的元素。如果我们希望往一个切片中追加另一个切片,那么我们必须使用...(省略号)操作符来告诉Go语言将被添加进来的切片当成多个元素。需要添加的元素类型必须与切片类型相同。以字符串为例,我们可以使用省略号语法将字节添加进一个字节类型切片中。
s := string{"A", "B", "C", "D", "E", "F", "G"}
t := string{"K", "L", "M", "N"}
u := string{"m", "n", "o", "p", "q", "r"}
s = append(s, "h", "i", "j") // 添加单一的值
s = append(s, t...) // 添加切片中的所有值
s = append(s, u[2:5]...) //添加一个子切片
b := byte{'U', 'V'}
letters := "WXY"
b = append(b, letters...) //将一个字符串字节添加进一个字节切片中
fmt.Printf("%v\n%s\n", s, b)
[A B C D E F G h i j K L M N o p q]
UVwxy
内置的append函数接受一个切片和一个或者更多个值,返回一个(可能为新的)切片,其中包含原始切片的内容并将给定的值作为其后续项。如果原始切片的容量足够容纳新的元素(即其长度加上新元素数量的和不超过切片的容量),append函数将新的元素放入原始切片末尾的空位置,切片的长度随着元素的添加而增长。如果原始切片没有足够的容量,那么append函数会隐式地创建一个新的切片,并将其原始切片的项复制进去,再在该切片的末尾加上新的项,然后将新的切片返回,因此需要将append的返回值赋值给原始切片变量。
有时我们不仅想往切片的末尾插入项,也想往切片的前面或者中间插入项。下面这些例子使用了我们自定义的InsertStringSliceCopy函数,它接收一个我们要插入切片的参数、一个用于插入的切片以及需插入切片的索引位置。
s := string{"M", "N", "O", "P", "Q", "R"}
x := InsertStringSliceCopy(s, string{"a", "b", "c"}, 0) //At the front
y := InsertStringSliceCopy(s, string{"x", "y"}, 3) // In the middle
z := InsertStringSliceCopy(s, string{"z"}, len(s)) // At the end
fmt.Printf("%v\n%v\n%v\n%v\n", s, x, y, z)
[M N O P Q R]
[a b c M N O P Q R]
[M N O x y P Q R]
[M N O P Q R z]
自定义的InsertStringSliceCopy函数创建了一个新的切片(这也是为什么在输出的时候切片s没有被改变的原因),使用内置的copy函数来复制第一个切片,并插入第二个切片。
func InsertStringSliceCopy(slice, insertion string, index int)string{
result := make(string, len(slice)+len(insertion))
at := copy(result, slice[:index])
at += copy(result[at:], insertion)
copy(result[at:], slice[index:])
return result
}
内置的copy函数接受两个包含相同类型元素的切片(这两个切片也可能是同一个切片的不同部分,包括重叠的部分)。该函数将第二个切片(源切片)的元素复制到第一个切片(目标切片),并返回所复制元素的数量。如果源切片为空,那么copy函数将安全地什么都不做。如果目标切片的长度不够来容纳目标切片中的项,那么那些无法容纳的项将被忽略。如果目标切片的容量比其长度大,我们可以在复制之前通过语句slice = slice[:cap(slice)]来将其长度增加至容量值。
传入copy函数的两个切片的类型必须相同(例外情况是当第一个切片(目标切片)的类型为byte时,第二个切片(源切片)可以是byte类型或者字符串类型)。如果源切片是一个字符串,那么会将其字节码拷入第一个参数。(关于这类用法的一个例子将在第6章6.3节讲解。)
在自定义的函数InsertStringSliceCopy函数开始处,我们首先创建一个新的切片(result),其容量足够容纳所传入的两个切片的项。然后将第一个切片到索引位置处的子切片复制到result切片中。接下来我们将所需插入的切片复制到result切片的末尾,其位置从我们上次复制子切片时所到达的位置开始。然后再将第一个切片中剩下的子切片复制到result 切片中,其位置也从我们上次复制子切片时所到达的位置开始。对于最后一次复制,函数copy的返回值被忽略,因为我们不再需要它了。最后,返回result切片。
如果所传入的索引位置为0,那么第一条语句中的slice[:index]为slice[:0],因此无需进行复制。类似地,如果所传入的索引位置大于等于切片的长度,则最后一条复制语句为slice[len(slice):](即一个空切片),因此也无需复制。
以下这个函数的功能与之前的InsertStringSliceCopy函数类似,但是更加简短。不同点在于,InsertStringSlice函数会更改原始切片(也可能修改需插入的切片),然而InsertStringCopy函数不会修改这些切片。
func InsertStringSlice(slice, insertion string, index int) string {
return append(slice[:index], append(insertion, slice[index:]...)...)
}
InsertStringSlice函数将原始切片从索引位置处到末尾处的子切片追加到插入切片中,并将得到的切片插入到原始切片从开始处到索引位置处的子切片末尾。其返回值为被叠加后的原始切片。(回忆下,append函数接受一个切片和一个或者多个值,因此我们必须使用省略号语法来将一个切片转换成它的多个元素值,而本例中我们必须这样做两次。)
使用Go语言的标准切片语法可以将元素从切片的开头和末尾处删除,但是将其从中间删除就费点事。我们接下来首先看看如何在原地从一个切片的头和尾删除一个元素,然后是从中间删除。之后再看看如何复制一个从原始切片删除了部分元素后得到的切片,但原始切片保持不变。
s := string{"A", "B", "C", "D", "E", "F", "G"}
s = s[2:] // 从开始处删除s[:2]子切片
fmt.Println(s)
[C D E F ]
通过使用再切片,可以轻易地从一个切片的开头删除元素。
s := string{"A", "B", "C", "D", "E", "F", "G"}
s = s[:4] // 从末尾处删除s[4:]子切片
fmt.Println(s)
[A B C D]
从一个切片的末尾处删除元素使用的也是再切片方法,与从切片的开头处删除元素一样。
s := string{"A", "B", "C", "D", "E", "F", "G"}
s = append(s[:1], s[5:]...) // 从中间删除s[1:5]
fmt.Println(s)
[A F G]
从中间取得元素非常简单。例如,要取得切片 s 中间的3 个元素,我们可以使用表达式s[2:5]。但是要从切片的中间删除元素就略微需要一点点技巧。这里我们使用 append函数来将需要删除元素的前后两部分连接起来,并将其赋值回给s。
明显地,使用append函数并且将新切片赋值回给原始切片来删除元素这样的做法会改变原始切片。以下几个例子使用了自定义的RemoveStringSliceCopy函数,它会返回原始切片的副本,但删除了其开始和结尾索引位置处之间的元素。
s := string{"A", "B", "C", "D", "E", "F", "G"}
x := RemoveStringSliceCopy(s, 0, 2) // 从头部删除s[:2]
y := RemoveStringSliceCopy(s, 1, 5) // 从中间删除s[1:5]
z := RemoveStringSliceCopy(s, 4, len(s)) // 从结尾处删除s[4:]
fmt.Printf("%v\n%v\n%v\n%v\n", s, x, y, z)
[A B C D E F G]
[C D E F G]
[A F G]
[A B C D]
由于RemoveStringSliceCopy函数首先复制了原始切片的元素,因此原始切片保持完整。
func RemoveStringSliceCopy(slice string, start, end int)string{
result := make(string, len(slice)-(end-start))
at := copy(result, slice[:start])
copy(result[at:], slice[end:])
return result
}
在RemoveStringSliceCopy函数中,我们首先创建一个新切片(result),并保证其容量足够大。然后我们将原始切片中从开头到start索引位置处的子切片拷进result切片中。接下来我们再将原始切片中从索引位置处到结尾处的子切片追加到result切片中。最后,我们返回result切片。
当然我们也可以创建一个更加简单的工作于原始切片的RemoveStringSlice函数,而不是创建一个副本。
func RemoveStringSlice(slice string, start, end int) string{
return append(slice[:start], slice[end:]...)
}
这是对之前所给出的使用append函数从切片中间删除元素的例子的通用化修改。其返回的切片为原始切片中将从start位置处到(但不包括)end位置处的项删除后的切片。
4.2.4 排序和搜索切片
标准库中的sort包提供了对整型、浮点型和字符串类型切片进行排序的函数,检查一个切片是否排序好的函数,以及使用二分搜索算法在一个有序切片中搜索一个元素的函数。同时提供了通用的sort.Sort和sort.Search函数,可用于任何自定义的数据。这些函数在表4-2中有列出。
表4-2 sort包中的函数
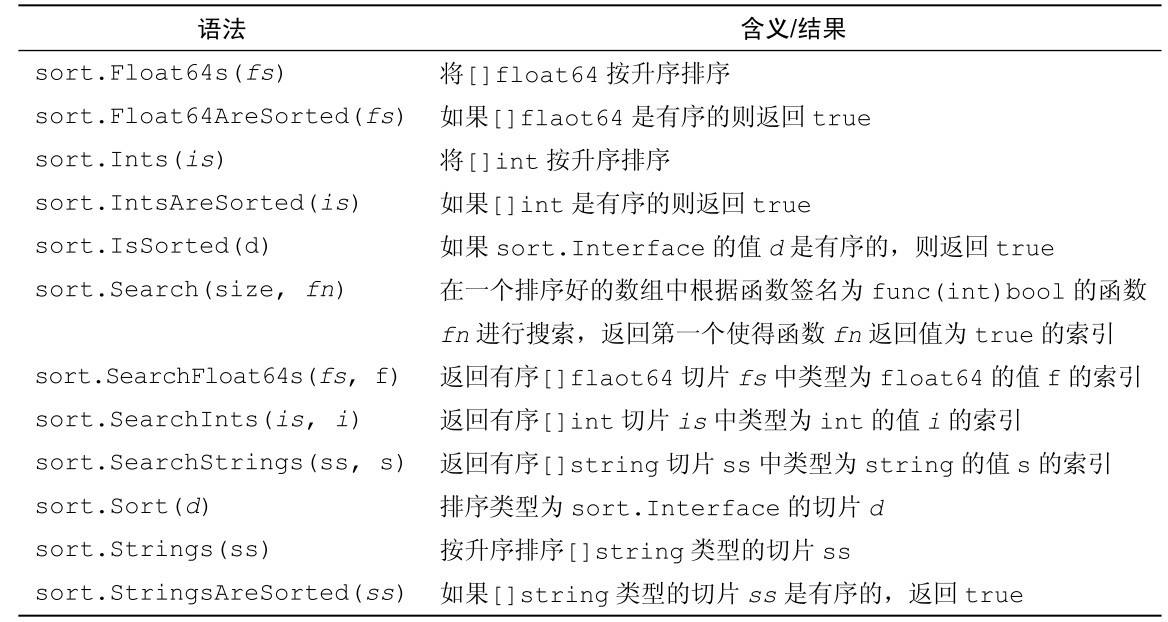
正如我们在之前章节中所看到的,Go语言对数值的排序方式并不奇怪。然而,字符串的排序完全是字节排序,这点我们在前面章节中已讨论过(参见3.2节)。这也意味着字符串的排序是区分大小写的。这里给出了一些字符串排序例子以及它们输出的结果。
files := string{"Test.conf", "uitl.go", "Makefile", "misc.go", "main.go"}
fmt.Printf("Unsorted: %q\n", files)
sort.Strings(files) // 标准库中的排序函数
fmt.Printf("Underlying bytes: %q\n", files)
SortFoldedStrings(files) // 自定义排序函数
fmt.Printf("Case insensitive: %q\n", files)
Unsorted: ["Test.conf" "util.go" "Makefile" "misc.go" "main.go"]
Underlying bytes:["Makefile" "Test.conf" "main.go" "misc.go" "util.go"]
Case insensitive:["main.go" "Makefile" "misc.go" "Test.conf" "util.go"]
标准库中的sort.Strings函数接受一个string 切片,并将该字符串按照它们底层的字节码在原地以升序排序。如果字符串使用的是同样的字符到字节映射的编码方案(例如,它们都是在本程序中创建的,或者是由其他Go程序创建的),该函数会按码点排序。自定义的函数SortFoldedStrings功能与此类似,不同的是它使用sort包中通用的sort.Sort函数来对字符串进行大小写无关的排序。
sort.Sort函数能够对任意类型进行排序,只要其类型提供了sort.Interface接口中定义的方法,即只要这些类型根据相应的签名实现了Len、Less和Swap等方法。我们创建了一个自定义类型FoldedStrings,提供了这些方法。下面是SortFoldedStrings函数、FoldedString类型以及相应方法的实现。
func SortFoldedStrings(slice string) {
sort.Sort(FoldedStrings(slice))
}
type FoldedStrings string
func (slice FoldedStrings) Len int { return len(slice) }
func (slice FoldedStrings) Less(i, j int) bool {
return strings.ToLower(slice[i]) < strings.ToLower(slice[j])
}
func (slice FoldedStrings) Swap(i, j int) {
slice[i], slice[j] = slice[j], slice[i]
}
SortFoldedStrings函数简单地使用标准库中的sort.Sort函数来完成工作,即使用Go语言的标准转换语法将给定的string类型的值转换成FoldedStrings类型的值。通常,当我们基于一个内置类型创建自定义的类型时,我们可以通过这样的类型转换方法将内置的类型转换提升为自定义类型(自定义类型相关的内容将在第6章讲解)。
FoldedStrings类型实现了3个方法以对应sort.Interface接口。这几个方法都比较小巧,Less方法通过使用strings.ToLower函数来达到大小写无关(如果我们要以逆序排序,可以简单地将Less方法中的小于操作符 < 改成大于操作符 >)。
正如我们在前面章节(参见3.2节)中所讨论的一样,对于7位ASCII编码(英语)的字符串而言,SortFoldedStrings函数的实现非常完美,但是对于其他非英语语言来说却不一定能够得到完美的排序结果。对 Unicode 编码的字符串进行排序不是个简单的任务,相关的详细描述在Unicode排序算法的文档中有解释(unicode.org/reports/tr10)。
files := string{"Test.conf", "util.go", "Makefile", "misc.go", "main.go"}
target := "Makefile"
for i, file := range files {
if file == target {
fmt.Printf("found \"%s\" at files[%d]\n", file, i)
break
}
}
found "Makefile" at files[2]
对于无序数据来说,使用这样的简单的线性搜索是唯一的选择,而这对于小切片(大至上百个元素)来说效果也不错。但是对于大切片特别是如果我们需要进行重复搜索的话,线性搜索就会非常低效,平均每次都需要让一半的元素相互比较。
Go提供了一个使用二分搜索算法的sort.Search方法:每次只需比较log2n个元素(其中n为切片中的元素总数)。从这个角度看,一个含1 000 000个元素的切片线性搜索平均需要500 000次比较,最坏时需要1 000 000次比较。而二分搜索即便是在最坏的情况下最多也只需要20次比较。
sort.Strings(files)
fmt.Printf("%q\n", files)
i := sort.Search(len(files),
func(i int) bool {return files[i] >= target })
if i < len(files) && files[i] == target {
fmt.Printf("found \"%s\" at files[%d]\n", files[i], i)
}
["Makefile" "Test.conf" "main.go" "misc.go" "util.go"]
found "Makefile" at files[0]
sort.Search函数接受两个参数:所处理的切片的长度和一个将目标元素与有序切片的元素相比较的函数,如果该有序切片是升序排序的则使用 >= 操作符,如果逆序排序则使用 <=操作符。该函数必须是一个闭包,即它必须创建于该切片的作用域内。因为它必须将切片当成是其自身状态的一部分。(闭包将在5.6.3节中讲解。)sort.Search函数返回一个int型的值。只有当该值小于切片的长度并且在该索引位置的元素与目标元素相匹配时,我们才能够确定找到了需要找的元素。
以下是这个函数的一个变形,它从一个不区分大小写的有序string切片中搜索一个小写的目标字符串。
target := "makefile"
SortFoldedStrings(files)
fmt.Printf("%q\n", files)
caseInsensitiveCampare := func(i int) bool {
return strings.ToLower(files[i]) > = target
}
i := sort.Search(len(files), caseInsensitiveCampare)
if i <= len(files) && strings.EqualFold(files[i], target) {
fmt.Printf("found \"%s\" at files[%d]\n", files[i], i)
}
["main.go" "Makefile" "misc.go" "Test.conf" "util.go"]
found "Makefile" at files[1]
这里我们除了调用sort.Search函数之外创建了一个比较函数。注意,与前面的例子一样,该比较函数也必须是创建于切片作用域范围内的闭包。我们本可以使用代码 strings.ToLower(files[i]) == target 来做比较,但是这里我们使用了更为方便的strings.EqualFold函数来不区分大小写地比较字符串。
Go语言的切片是一种非常强大、方便,且功能非常方便的数据结构,难以想像会有哪个不太小的Go程序不需要用到它。我们将在本章后面看到实际的使用案例(参见4.4节)。
虽然切片足以满足大多数数据结构的使用案例,但有些情况下我们不得不将数据保存为“键值”对来按键进行快速查找。这个功能由Go语言中的映射类型提供,也是本书下一节的主题。
4.3 映射
Go语言中的映射(map)是一种内置的数据结构,保存键-值对的无序集合,它的容量只受到机器内存的限制[8]。在一个映射里所有的键都是唯一的而且必须是支持==和!=操作符的类型,大部分Go语言的基本类型都可以作为映射的键,例如,int、float64、rune、string、可比较的数组和结构体、基于这些类型的自定义类型,以及指针。Go语言的切片和不能用于比较的数组和结构体(这些类型的成员或者字段不支持==或者!=操作)或者基于这些的自定义类型则不能作为键。指针、引用类型或者任何内置类型的值、自定义类型都可以用做值,包括映射本身,所以它可以创建任意复杂的数据结构。表4-3列出了Go语言中映射支持的操作。
表4-3 映射的操作

因为映射属于引用类型,所以不管一个映射保存了多少数据,传递都是很廉价的(在64 位机器上只需要8个字节,在32位机器上只需要4字节)。映射的查询很快,甚至比线性搜索还快。从非正式的实验结果来看[9],尽管映射的查找比数组或者切片里的直接索引慢两个数量级左右(即100倍),但在需要用到映射的地方来说,这仍然是非常快的了,实际使用中几乎不大可能出现性能问题。图4-5展示了一个map[string]float64类型的映射示意图。
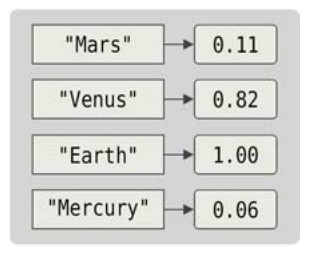
图4-5 一个键为string类型、值为float64类型的映射的剖析
由于byte是一个切片,不能作为映射的键,但是我们可以先将byte转换成字符串,例如string(byte),然后作为映射的键字段,等有需要的时候再转换回来,这种转换并不会改变原有切片的数据。
映射里所有键的数据类型必须是相同的,值也必须如此,但键和值的数据类型可以不同(通常都不相同)。但是如果值的类型是接口类型,我们就可以将一个满足这个接口定义的值作为映射的值,甚至我们可以创建一个值为空接口(interface{})的映射,这就意味着任意类型的值都可以作为这个映射的值。不过当我们需要访问这个值的时候,需要使用类型开关和类型断言获得这个接口类型的实际类型,或者也可以通过类型检视(type introspection)来获得变量的实际类型。(接口会在第6章介绍,反射会在第9章介绍。)
映射的创建方式如下:
make(map[KeyType]ValueType, initialCapacity)
make(map[KeyType]ValueType)
map[KeyType]ValueType{}
map[KeyType]ValueType{key1: value1, key2: value2,..., keyN: valueN}
Go语言内置的make函数可用来创建切片、映射和通道。当用make来创建一个映射时,实际上得到一个空的映射,如果指定容量(initialCapacity)就会预先申请到足够的内存,并且随着加入的项越来越多,映射会自动扩容。第二种写法和第三种写法是完全一样的,最后两种写法使用的是复合语法,实际编程中这是非常方便的,比如创建一个空的映射或者具有某些初始值的映射。
4.3.1 创建和填充映射
我们来创建一个映射结构,并往里面填充一些数据,键为string类型,值是float64类型。
massForPlanet := make(map[string]float64) // 与map[string]float64{}相同
massForPlanet["Mercury"] = 0.06
massForPlanet["Venus"] = 0.82
massForPlanet["Earth"] = 1.00
massForPlanet["Mars"] = 0.11
fmt.Println(massForPlanet)
map[Venus:0.82 Mars:0.11 Earth:1 Mercury:0.06]
对于一些比较小的映射,我们没必要考虑是否要指定它们的初始容量,但如果这个映射比较大,指定恰当的容量可以提高性能。通常如果你知道它的容量的话最好就指定它,即使是近似的也好。
映射和数组或切片一样可以使用索引操作符,但和数组或切片不同的是,映射的键类型不必是int型的,例如我们现在用的是string类型的键。
我们使用了 fmt.Println函数打印映射,这个函数使用%v 格式符将映射中每项内容都以“键:值”的形式打印出,并且项与项之间以空格分开,因为映射里面的项都是无序的,所以在其他机器上打印出来的结果顺序可能和本书的不一样。
之前提过,映射的键可以是一个指针,我们下面将会看到一个例子,它的键的类型是*Point,Point定义如下:
type Point struct{ x, y, z int }
func (point Point) String string {
return fmt.Sprintf("(%d,%d,%d)", point.x, point.y, point.z)
}
Point类型里有了3个int类型的变量,还有一个String的方法,这样就确保了当我们打印一个*Point时Go语言会调用它的String方法而不是简单地输出Point的内存地址。
顺便说一句,我们可以使用%p格式符来强制Go语言打印出内存地址,格式符此前介绍过(参见3.5.6节)。
triangle := make(map[*Point]string, 3)
triangle[&Point{89, 47, 27}] = "α"
triangle[&Point{86, 65, 86}] = "β"
triangle[&Point{7, 44, 45}] = "γ"
fmt.Println(triangle)
map[(7,44,45):γ (89,47,27):α (86,65,86):β]
这里我们创建了一个初始存储大小为3的映射,然后往里添加指针类型的键和字符串值。使用复合语法创建每个 Point 值,然后用&操作符取得指针作为键,这样键就是一个*Point指针而不是一个Point类型的值。因为Point实现了String方法,所以打印映射的时候我们能以可读的方式看到 *Point的值。
使用指针作为映射的键意味着我们可以增加两个相同的内容,只要分别创建它们就可以获得不同的地址。但如果我们希望这个映射对任何实际上相同的内容只存储一个的话会怎么样呢?这也是很容易的,只要我们存储Point的值而不是指向Point的指针即可,要知道,Go语言允许将一个结构体作为映射的键,只要它们所有的字段都支持==和!=运算即可。下面是一个例子。
nameForPoint := make(map[Point]string) // 等同于: map[Point]string{}
nameForPoint[Point{54, 91, 78}] = "x"
nameForPoint[Point{54, 158, 89}] = "y"
fmt.Println(nameForPoint)
map[(54,91,78):x (54,158,89):y]
nameForPoint的每一个键都是唯一的Point结构,我们可以在任何时候改变它所映射的字符串。
populationForCity := map[string]int{"Istanbul": 12610000,
"Karachi": 10620000, "Mumbai": 12690000, "Shanghai": 13680000}
for city, population := range populationForCity {
fmt.Printf("%-10s %8d\n", city, population)
}
Shanghai 13680000
Mumbai 12690000
Istanbul 12610000
Karachi 10620000
这是我们这一节最后的例子了,同样,我们使用复合语法创建了整个映射结构。当用一个for...range 循环来遍历映射的时候,对于映射中的每一项都返回两个变量键和值,直到遍历完所有的键/值对或者循环被打破。如果只关心其中一个变量的话,因为映射里的项都是无序的,我们并不知道每次迭代实际返回的是哪一个,更多的时候我们只是获得所有遍历出来的项并更新它们,所以遍历出来的次序不重要。但是,如果我们想按照某种方式来遍历,如按键序,这也不难,很快我们就可以看到了(见4.3.4节)。
4.3.2 映射查询
Go语言提供了两种类似的语法用于映射查询,两种方式都是使用操作符。下面是一种最简单的方法。
population := populationForCity["Mumbai"]
fmt.Println("Mumbai's population is", population)
population = populationForCity["Emerald City"]
fmt.Println("Emerald City's population is", population)
Mumbai's population is 12690000
Emerald City's population is 0
如果我们查询的键出现在映射里面,那就返回它对应的值,如果这个键并没有在映射里,就会返回一个 0 值,但是 0 值也有可能是因为这个键不存在,所以这里我们不能简单地认为“Emerald City”这个城市的人口数就是0,或者说这个城市并不在这个映射中。Go语言还有一种语法解决了这个问题。
city := "Istanbul"
if population, found := populationForCity[city]; found {
fmt.Printf("%s's population is %d\n", city, population)
} else {
fmt.Printf("%s's population data is unavailable\n", city)
}
city = "Emerald City"
_, present := populationForCity[city]
fmt.Printf("%q is in the map == %t\n", city, present)
Istanbul's population is 12610000
"Emerald City" is in the map == false
当我们使用索引操作符来查找映射中的键的时候,我们指定两个返回变量,第一个用来获得键对应的值(如果键不存在的话会返回0值),第二个变量是一个布尔类型(键存在则为true,否则为false),这样我们就可以知道这个键是否真的在映射里。像上述代码里面的第二个查询一样,如果我们只是关心某个键是否存在的话可以使用空变量(一个下划线)来接受值。
4.3.3 修改映射
我们可以往映射里插入或者删除一项,所谓项(item),也就是一个“键/值”对,任何一项的值都可以修改,如下。
fmt.Println(len(populationForCity), populationForCity)
delete(populationForCity, "Shanghai") // 删除
fmt.Println(len(populationForCity), populationForCity)
populationForCity["Karachi"] = 11620000 // 更新
fmt.Println(len(populationForCity), populationForCity)
populationForCity["Beijing"] = 11290000 // 插入
fmt.Println(len(populationForCity), populationForCity)
4 map[Shanghai:13680000 Mumbai:12690000 Istanbul:12610000 Karachi:10620000]
3 map[Mumbai:12690000 Istanbul:12610000 Karachi:10620000]
3 map[Mumbai:12690000 Istanbul:12610000 Karachi:11620000]
4 map[Mumbai:12690000 Istanbul:12610000 Karachi:11620000 Beijing:11290000]
插入和更新一个项的语法是完全一样的,如果给定一个键对应的项不存在,那么映射默认会创建一个新的项来保存这个“键/值”对,否则,就将这个键原来的值设置成新的值。如果我们尝试去删除映射里一个不存在的项,Go语言并不会做任何不安全的事情。
对于键不能用同样的方式修改,但可以用如下这种效果相同的做法:
oldKey, newKey := "Beijing", "Tokyo"
value := populationForCity[oldKey]
delete(populationForCity, oldKey)
populationForCity[newKey] = value
fmt.Println(len(populationForCity), populationForCity)
4 map[Mumbai:12690000 Istanbul:12610000 Karachi:11620000 Tokyo:11290000]
我们先得到键的值,然后删除这个键对应的项,接着创建一个新的项用来保存新的键和原来的值。
4.3.4 键序遍历映射
当使用数据时,我们通常需要按照某种被认可的方式将这些数据显示出来,下面的例子展示了如何按字典序(严格来说,是Unicode码点的顺序)显示populationForCity里的城市数据。
cities := make(string, 0, len(populationForCity))
for city := range populationForCity {
cities = append(cities, city)
}
sort.Strings(cities)
for _, city := range cities {
fmt.Printf("%-10s %8d\n", city, populationForCity[city])
}
Beijing 11290000
Istanbul 12610000
Karachi 11620000
Mumbai 12690000
首先我们创建一个类型为string的切片,Go语言会默认将其初始化为0值,但设置了足够大的容量去保存映射里的键。然后将我们遍历映射得到的所有键(因为我们现在只会用到一个变量city,所以不需要得到完整的一个“键/值”对)追加到这个切片cities里去。下一步,对cities排序,再遍历cities(使用空变量忽略int型的索引),查询每个city对应的城市人口数量。
这个算法的思想是,创建一个足够大的切片去保存映射里所有的键,然后对切片排序,遍历切片得到键,再从映射里得到这个键的值,这样就可以实现顺序输出了。一般希望按键序来遍历一个映射都可以这样做。
另一种方法就是使用有序的数据结构,例如一个有序映射,我们在后面的章节会介绍一个例子(6.5.3节)。
按值排序也是可以的,例如将一个映射反转,下一节将提到这个方法。
4.3.5 映射反转
如果一个映射的值都是唯一的,且值的类型也是映射所支持的键类型的话,我们就可以很容易地将它反转。
cityForPopulation := make(map[int]string, len(populationForCity))
for city, population := range populationForCity {
cityForPopulation[population] = city
}
fmt.Println(cityForPopulation)
map[12610000:Istanbul 11290000:Beijing 12690000:Mumbai 11620000:Karachi]
因为 populationForCity 是 map[string]int 类型的,所以我们创建一个map[int]string类型的cityForPopulation。然后遍历populationForCity,并将得到的键和值反转,插入 cityForPopulation 里去,也就是说,原先的值将作为键,而原先的键则作为现在的值。
当然,如果原来映射的值不是唯一,反转就会失败,实质上只有最后一个不唯一的值对应的键被保存。可以通过创建一个多值的映射来解决这个问题,如在我们这个例子里,反转后的映射的类型是map[int]string(键是int类型的,值是string),很快我们就可以看到一个实际的例子(参见4.4.2节)。
4.4 例子
这一节我们来看两个小例子,第一个是关于一维或者二维切片的,第二个主要是映射,包括当映射的值不唯一时如何反转,也涉及切片和排序。
4.4.1 猜测分隔符
有时候我们可能收到很多数据文件需要去处理,每个文件每一行就是一条记录,但是不同的文件可能使用不同的分隔符(例如,可能是制表符、空白符或者“*”等)。为了能够大批量地处理这些文件我们必须能够判断每个文件所用的分隔符,这一节展示的guess_separator 例子(在文件guess_separator/guess_separator.go里)尝试去判断所有给定文件的分隔符。
运行示例如下:
$./guess_separator information.dat
tab-separated
程序从给定文件里读取前 5 行(如果文件行数小于 5 则全读取进来),然后分析所用的分隔符。我们从main函数以及它所调用的函数开始分析(除去例程),import部分略过。
func main {
if len(os.Args) == 1 || os.Args[1] == "-h" || os.Args[1] == "--help" {
fmt.Printf("usage: %s file\n", filepath.Base(os.Args[0]))
os.Exit(1)
}
separators := string{"\t", "*", "|", "•"}
linesRead, lines := readUpToNLines(os.Args[1], 5)
counts := createCounts(lines, separators, linesRead)
separator := guessSep(counts, separators, linesRead)
report(separator)
}
main函数首先检查命令行是否指定了文件,如果一个都没有,就打印一条帮助消息然后退出程序。我们创建了一个string切片来保存我们感兴趣的分隔符列表。按照惯例,对于使用空白分隔符的文件,我们当成是“”来处理(空字符串)。
第一步数据处理是从文件中读取前5行内容。这里没有显示readUpNLines函数的代码,因为我们之前就有几个这样从文件中读取行的例子。和之前例子不同的是,readUpToNLines函数只是读取一定数量的行,如果文件实际的行数比指定的小,那就全读,最后返回实际读取了的行数及每行的数据。
然后就是createCounts函数,代码如下。
func createCounts(lines, separators string, linesRead int) int {
counts := make(int, len(separators))
for sepIndex := range separators {
counts[sepIndex] = make(int, linesRead)
for lineIndex, line := range lines {
counts[sepIndex][lineIndex] =
strings.Count(line, separators[sepIndex])
}
}
return counts
}
createCounts的目的就是计算出一个保存了每一个分隔符在每行出现的次数的矩阵。
函数首先创建一个int 类型的二维切片 counts,大小和main 函数里的separators一样。如果有4个分隔符,那么counts的值是[nil nil nil nil],外围的for循环将每一个nil替换成int,用来保存每个分隔符在每一行出现的次数,所以每一个nil都被替换成了[0 0 0 0 0],注意Go语言默认总是将一个值初始化为0值。
内部的for循环是用来计算counts矩阵的。每一行里每一个分隔符出现的次数都会被统计下来并相应地更新 counts的值,strings.Count函数返回它的第二个参数指定的字符串在第一个参数指定的字符串里出现的次数。
例如,对于一个使用制表符分隔的文件,其中某些字段包含圆点符号、空格和星号,我们可能得到这样一个counts矩阵:[[3 3 3 3 3] [0 0 4 3 0] [0 0 0 0] [1 2 2 0 0]]。counts里的每一项都是int类型的切片,保存了每一个分隔符(制表符、星号、竖杠、圆点)在每一行里出现的次数。从这个数字看来每一行里都出现了3个制表符,有两行出现星号(一行3个,一行4个),有3行出现圆点,没有一行出现竖杠。对我们来说很明显制表符是分隔符,当然程序必须得自己发现这个,它是用guessSep函数来完成这个功能的。
func guessSep(counts int, separators string, linesRead int) string {
for sepIndex := range separators {
same := true
count := counts[sepIndex][0]
for lineIndex := 1; lineIndex < linesRead; lineIndex++ {
if counts[sepIndex][lineIndex] != count {
same = false
break
}
}
if count > 0 && same {
return separators[sepIndex]
}
}
return ""
}
guessSep是这样处理的:如果某个分隔符在每一行出现的次数都是相同的(但不能是0值),就认为文件使用的就是这个分隔符。外部的for循环检查每一个分隔符,内部for循环检查分隔符在每行出现的次数。same变量初始化为true,默认是假设当前分隔符在每行出现的次数都是一样的,count为当前分隔符在第一行出现的次数。然后内循环开始,如果发现有一行的次数和count不一样,same的值变为false,内循环退出,然后尝试下一个分隔符。如果内循环没有将false赋值给same变量,而且count的值大于0,就表示已经找到我们想要的分隔符了,并立即返回它。最后如果没有找到分隔符,返回一个空的字符串,也就是说所有的行都是以空白符分隔的,或者完全没有分隔。
func report(separator string) {
switch separator {
case "":
fmt.Println("whitespace-separated or not separated at all")
case "\t":
fmt.Println("tab-separated")
default:
fmt.Printf("%s-separated\n", separator)
}
}
report这个函数不怎么重要,只是显示文件所用的分隔符是什么。
我们从这个例子了解到两种切片的典型用法,一维的和二维的(separators、lines, 还有counts),下一个例子我们将会看到映射、切片还有排序。
4.4.2 词频统计
文本分析的应用很广泛,从数据挖掘到语言学习本身。这一节我们来分析一个例子,它是文本分析最基本的一种形式:统计出一个文件里单词出现的频度。
频度统计后的结果可以以两种不同的方式显示,一种是将单词按照字母顺序把单词和频度排列出来,另一种是将频度按照有序列表的方式把频度和对应的单词显示出来。wordfrequency 程序(在文件wordfrequency/wordfrequency.go里)生成两种输出,如下所示。
$./wordfrequency small-file.txt
Word Frequency
ability 1
about 1
above 3
...
years 1
you 128
Frequency→Words
1 ability, about, absence, absolute, absolutely, abuse, accessible,...
2 accept, acquired, after, against, applies, arrange, assumptions,...
...
128 you
151 or
192 to
221 of
345 the
即使是很小的文件,单词的数量和不同频度的数量都可能会非常大,篇幅有限,我们只显示部分结果。
第一种输出是比较直接的,我们可以使用一个map[string]int类型的结构来保存每一个单词的频度。但是要得到第二种输出结果我们需要将整个映射进行反转,但这并不是那么容易,因为很可能具有相同的频度的单词不止一个,解决的方法就是反转成多值类型的映射,如map[int]string,也就是说,键是频度而值则是所有具有这个频度的单词。
我们将从程序的main函数开始,从上到下分析,和通常一样,忽略掉import部分。
func main {
if len(os.Args) == 1 || os.Args[1] == "-h" || os.Args[1] == "--help" {
fmt.Printf("usage: %s <file1> [<file2> [...<fileN>]]\n",
filepath.Base(os.Args[0]))
os.Exit(1)
}
frequencyForWord := map[string]int{} // 与make(map[string]int)相同
for _, filename := range commandLineFiles(os.Args[1:]) {
updateFrequencies(filename, frequencyForWord)
}
reportByWords(frequencyForWord)
wordsForFrequency := invertStringIntMap(frequencyForWord)
reportByFrequency(wordsForFrequency)
}
main函数首先分析命令行参数,之后再进行相应处理。
我们使用复合语法创建一个空的映射,用来保存从文件读到的每一个单词和对应的频度。接着我们遍历从命令行得到的每一个文件,分析每一个文件后更新frequencyForWord的数据。
得到第一个映射之后,我们就输出第一个报告:一个按照字母表顺序排序的单词列表和对应的出现频率。然后我们创建一个反转的映射,输出第二个报告:一个排序的出现频率列表和对应的单词。
func commandLineFiles(files string) string {
if runtime.GOOS == "windows" {
args := make(string, 0, len(files))
for _, name := range files {
if matches, err := filepath.Glob(name); err != nil {
args = append(args, name) // 无效模式
} else if matches != nil { // 至少有一个匹配
args = append(args, matches...)
}
}
return args
}
return files
}
因为在Unix类系统(如Linux或Mac OS X等)的shell默认会自动处理通配符(也就是说,*.txt能匹配任意后缀为.txt的文件,如README.txt和INSTALL.txt等),而Windows平台的shell程序(cmd.exe)不支持通配符,所以如果用户在命令行输入,如 *.txt,那么程序只能接收到 *.txt。为了保持平台之间的一致性,我们使用commandLineFiles函数来实现跨平台的处理,当程序运行在Windows平台时,我们自己把文件名通配功能给实现了。(另一种跨平台的办法就是不同的平台使用不同的.go文件,这在9.1.1.1节有描述。)
func updateFrequencies(filename string, frequencyForWord map[string]int) {
var file *os.File
var err error
if file, err = os.Open(filename); err != nil {
log.Println("failed to open the file: ", err)
return
}
defer file.Close
readAndUpdateFrequencies(bufio.NewReader(file), frequencyForWord)
}
updateFrequencies 函数纯粹就是用来处理文件的。它打开给定的文件,并使用defer让函数返回时关闭文件句柄。这里我们将文件作为一个*bufio.Reader(使用bufio.NewReader函数创建)传给readAndUpdateFrequencies函数,因为这个函数是以字符串的形式一行一行地读取数据的而不是读取字节流。可见,实际的工作都是在readAndUpdate Frequencies函数里完成的,代码如下。
func readAndUpdateFrequencies(reader *bufio.Reader, frequencyForWord map[string]int) {
for {
line, err := reader.ReadString('\n')
for _, word := range SplitOnNonLetters(strings.TrimSpace(line)) {
if len(word) > utf8.UTFMax || utf8.RuneCountInString(word) > 1 {
frequencyForWord[strings.ToLower(word)] += 1
}
}
if err != nil {
if err != io.EOF {
log.Println("failed to finish reading the file: ", err)
}
break
}
}
}
第一部分的代码我们应该很熟悉了。我们用了一个无限循环来一行一行地读一个文件,当读到文件结尾或者出现错误(这种情况下我们将错误报告给用户)的时候就退出循环,但我们并不退出程序,因为还有很多其他的文件需要去处理,我们希望做尽可能多的工作和报告我们捕获到的任何问题,而不是将工作结束在第一个错误上面。
内循环就是处理结束的地方,也是我们最感兴趣的。任意一行都可能包括标点、数字、符号或者其他非单词字符,所以我们逐个单词地去读,将每一行分隔成单词并使用SplitOnNonLetters函数忽略掉非单词的字符。而且我们一开始就过滤掉字符串开头和结束处的空白。
如果我们只关心至少两个字母的单词,最简单的办法就是使用只有一条语句的if 语句,也就是说,如果utf8.RuneCountInString(word)> 1,那这就是我们想要的。
刚才描述的那个简单的if 语句可能有一点性能损耗,因为它会分析整个单词。所以在这个程序里我们用了一个两个分句的if 语句,第一个分句用了一个非常高效的方法,它检查这个单词的字节数是否大于utf8.UTFMax(它是一个常量,值为4,用来表示一个UTF-8字符最多需要几个字节)。这是最快的测试方法,因为Go语言的strings知道它们包含了多少个字节,还有Go语言的二进制布尔操作符号总是走捷径的(2.2节)。当然,由4个或者更少字节组成的单词(例如7位的ASCII码字符或者一对2个字节的UTF-8字符)在第一次检查时可能失败,不过这不是问题,还有第二次检查(rune的个数)也很快,因为它通常只有 4 个或者不到4 个字符需要去统计。在我们这个情况里需要用到两个分句的if语句吗?这就取决于输入了,越多的字符需要的处理时间就越长,就有更多可能优化的地方。唯一可以明确知道的办法就是使用真实或者典型的数据集来做基准测试。
func SplitOnNonLetters(s string) string {
notALetter := func(char rune) bool { return !unicode.IsLetter(char) }
return strings.FieldsFunc(s, notALetter)
}
这个函数在非单词字符上对一个字符串进行切分。首先我们为 strings.FieldsFunc函数创建一个匿名函数notALetter,如果传入的是字符那就返回false,否则返回true。然后我们返回调用函数strings.FieldsFunc的结果,调用的时候将给定的字符串和notALetter作为它的参数。(我们在之前在3.6.1节里讨论过strings.FieldsFunc函数。)
func reportByWords(frequencyForWord map[string]int) {
words := make(string, 0, len(frequencyForWord))
wordWidth, frequencyWidth := 0, 0
for word, frequency := range frequencyForWord {
words = append(words, word)
if width := utf8.RuneCountInString(word); width > wordWidth {
wordWidth = width
}
if width := len(fmt.Sprint(frequency)); width > frequencyWidth {
frequencyWidth = width
}
}
sort.Strings(words)
gap := wordWidth + frequencyWidth - len("Word") - len("Frequency")
fmt.Printf("Word %*s%s\n", gap, " ", "Frequency")
for _, word := range words {
fmt.Printf("%-*s %*d\n", wordWidth, word, frequencyWidth,
frequencyForWord[word])
}
}
一旦计算出了frequencyForWord,就调用reportByWords将它的数据打印出来。因为我们希望输出结果是按照字母顺序排列的(实际上是按照Unicode码点顺序),所以我们首先创建一个空的容量足够大的string切片来保存所有在frequencyForWord里的单词,同样我们希望能知道最长的单词和最高的频度的字符宽度(比如说,频度有多少个数字),所以我们可以以整齐的方式输出我们的结果,用wordWidth和frequencyWidth来记录这两个结果。