第3章 字符串
04-13Ctrl+D 收藏本站
本章讲解了Go语言的字符串类型,以及标准库中与字符串类型相关的关键包。本章中各小节的内容包括如何写字面量字符串以及如何使用字符串操作符,如何索引和切片字符串,如何格式化字符串、数值和其他内置类型甚至是自定义类型的输出。
Go语言的高级字符串处理相关的功能几乎每天都要用到,如一个字符一个字符迭代字符串的for…range循环,strings包和strconv包中的函数以及Go语言切片字符串的功能。尽管如此,本章还会深入讲解 Go语言的字符串,包括一些底层细节,如字符串类型的内部表示。底层方面的东西非常有趣,并且有时非常有用。
一个 Go语言字符串是一个任意字节的常量序列。大部分情况下,一个字符串的字节使用UTF-8编码表示Unicode文本(详见上文中的“Unicode编码”一栏)。Unicode编码的使用意味着Go语言可以包含世界上任意语言的混合,代码页没有任何混乱与限制。
Go语言的字符串类型在本质上就与其他语言的字符串类型不同。Java的String、C++的std::string以及Python 3的str类型都只是定宽字符序列,而Go语言的字符串是一个用UTF-8编码的变宽字符序列,它的每一个字符都用一个或多个字节表示。
初次接触时可能会觉得这些其他语言的字符串类型比 Go语言的字符串类型更加方便,因为它们的字符串中的单个字符可以被字节索引,这在 Go语言中只有在字符串只包含 7 位的ASCII字符(因为它们都用一个单一的UTF-8字节表示)时才可能。但在实际情况下,这从来都不是个问题。首先,直接索引使用得不多,而Go语言支持一个字符一个字符的迭代;其次,标准库提供了大量的字符串搜索和操作函数;最后,我们随时都可以将 Go语言的字符串转换成一个Unicode码点切片(其类型为rune),而这个切片是可以直接索引的。
虽然Java或者Python两者也都有提供Unicode编码的字符串,但与这些语言的字符串类型相比,Go语言使用UTF-8 编码有更多的优点。Java使用码点序列来表示字符串,每一个字符串占用16位;2.x版本 到3.2版本的Python使用类似的方法,只是不同的方式编译的Python使用的是16位 或者32位字符。对于英文文本,这意味着Go语言使用8位来表示每一个字符,Java或者Python则至少两倍于此。UTF-8编码的另一个优点是,无需关心机器码的排列顺序,而UTF-16和UTF-32编码的字符串需要知道机器码的排列顺序以便将文本正确地解码。其次,由于UTF-8是世界上文本文件的编码标准,其他语言必须通过编码解码该文件的方式来从其内部编码格式转换过来,而Go语言能够直接读或者写这些文件。此外,有些主要的库(如GTK+)也原生使用UTF-8编码的字符串,因此Go语言无需编码解码就可以使用它们。
Unicode编码
在 Unicode编码出现之前,要在单个文件中包含多种语言的文本几乎是不可能的,比如在英文中引用某些日文或者俄文。因为每种语言使用的编码方式不一样,而一个文本文件只支持一种编码方式。
Unicode被设计成能够表示世界上各种写作系统的字符,因此一个使用Unicode编码的单一文件可以包含任意种语言的混合体,包括数学符号、“修饰符”以及其他特殊字符。
每一个 Unicode字符都有一个唯一的叫做“码点”的标识数字。目前定义了超过 10 万个 Unicode 字符,其码点的值从 0x0 到 0x10FFFF(后者在 Go语言中被定义成一个常量unicode.MaxRune),其中有一些断层和许多特殊的情况。在Unicode文档中,码点是用4个或者更多个十六进制数字以U+hhhh的形式表示的,如U+21D4表示⇔字符。
在 Go语言中,一个单一的码点在内存中以 rune的形式表示。(rune 类型是 int32类型的别名,详见2.3.1节。)
无论是在文件里还是内存里,Unicode 文本都必须用统一的编码方式表示。Unicode 标准定义了一些Unicode变体格式(编码),如UTF-8、UTF-16以及UTF-32编码。Go语言的字符串类型使用UTF-8编码。UTF-8编码是用得最广的编码,也是文本文件的标准以及XML文件和JSON文件的默认编码方式。
UTF-8编码使用1~4个字节来表示每一个码点。对于只包含7位的ASCII字符的字符串来说,字节和字符之间有一个一对一的关系,因为7位的ASCII字符正好可以用一个UTF-8字节来表示。这样表示的结果是,UTF-8存储英文文本时会非常紧凑(一个字节表示一个字符)的,另一个结果是一个用7位ASCII编码的文本与一个用UTF-8编码的文本没有区别。
在实际使用中,只要我们学会了Go语言中使用字符串的范式,会发现Go语言的字符串与其他语言中的字符串类型一样方便。
3.1 字面量、操作符和转义
字符串字面量使用双引号(")或者反引号(')来创建。双引号用来创建可解析的字符串字面量,如表 3-1 中所示的那些支持转义的序列,但不能用来引用多行。反引号用来创建原生的字符串字面量,这些字符串可能由多行组成;它们不支持任何转义序列,并且可以包含除了反引号之外的任何字符。可解析的字符串使用得最广泛,而原生的字符串字面量则用于书写多行消息、HTML以及正则表达式。这里有些例子。
text1 := "\"what's that?\", he said" // 可解析的字符串字面量
text2 := '"what's that?", he said' // 原生的字符串字面量
radicals := "√\u221A \U0000221a" // radicals == "√ √ √"
表3-1 Go语言的字符串和字符转义
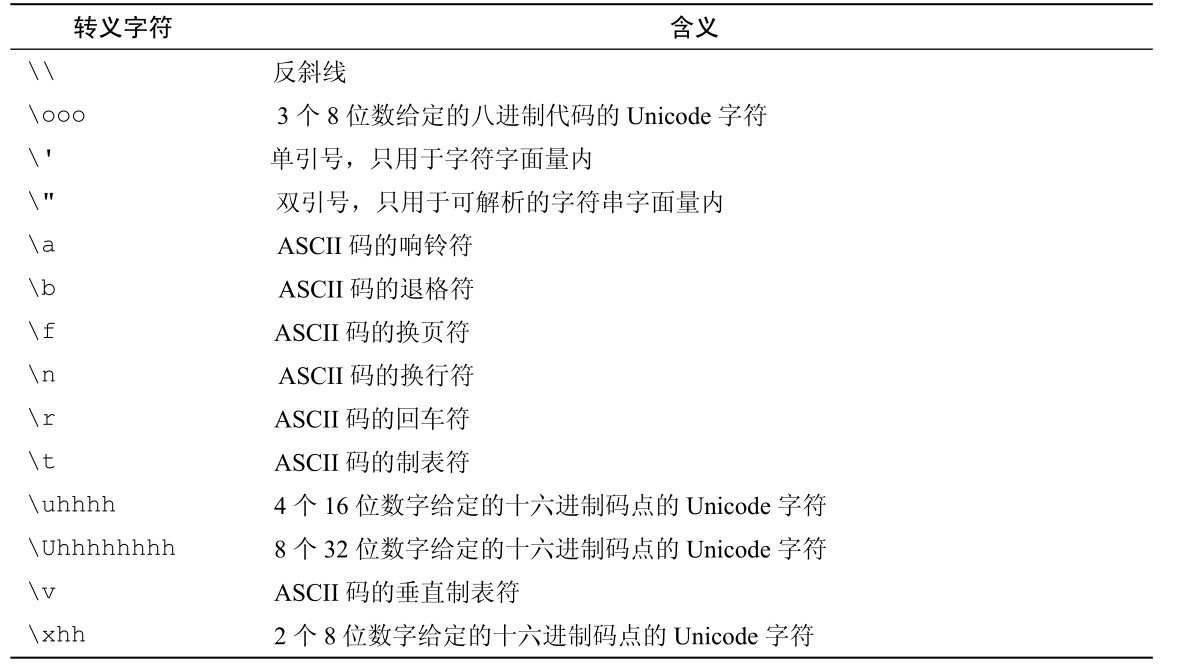
上文中创建的3个变量都是字符串类型,变量text1和变量text2包含的是完全相同的文本。由于.go文件使用的是UTF-8编码,因此我们可以包含Unicode编码字符而无需拘泥于形式。然而我们仍然可以使用Unicode的转义字符来表示第二个或者第三个√字符。但在这个特殊的例子中,我们不能使用八进制或者十六进制的转义符,因为它们的码点仅限于U+0000到U+00FF之间,对于√这个字符的码点U+221A来说太小了。
如果我们想要创建一个长的可解析字符串字面量,但又不想在代码中写同样长的一行,那么我们可以创建多个字面量片段,使用+级联符将这些片段连接起来。此外,虽然Go语言的字符串是不可变的,但它们支持+=追加操作符。如果底层的字符串容量不够大,不能适应添加的字符串,级联追加操作将导致底层的字符串被替换。这些操作符详见表3-2。字符串也可以使用比较操作符(见表2-3)来进行比较。这里有个例子使用到了这些操作符:
book := "The Spirit Level" + // 字符串级联
" by Richard Wilkinson"
book += " and Kate Pickett" // 字符串追加
fmt.Println("Josey" < "José ", "Josey" == "José ") // 字符串比较
其结果是book变量将包含文本"The Spirit Level by Richard Wilkinson and Kate Pickett",并会输出"true false"到os.Stdout。
表3-2 字符串操作符

注:*这种转换总是成功的。非法数字被转换成Unicode编码的替换符U+FFFD,看起来像“?”。
3.2 比较字符串
如前所述,Go语言字符串支持常规的比较操作(<、<=、==、!=、>和>=),这些操作符在表 2-3 中已给出。这些比较操作符在内存中一个字节一个字节地比较字符串。比较操作可以直接使用,如比较两个字符串的相等性,也可以间接使用,例如在排序string时使用 < 操作符来比较字符串。遗憾的是,执行比较操作时可能会产生3个问题。这3个问题困扰每种使用Unicode字符串的编程语言,都不局限于Go语言。
第一个问题是,有些Unicode编码的字符可以用两个或者多个不同的字节序列来表示。例如,字符Å可以是Ångström中的字符,也可以只是一个A上面加了一个小环,这两者通常不能区分。Ångström字符的Unicode编码是U+212B,但是一个A上面加了一个小圈的字符使用Unicode编码U+00C5来表示,或者使用两个编码U+0041(A)以及U+030A(°,将小圈放到上面)来表示。Ångström中的Å在UTF-8中表示成字节[0xE2, 0X84, 0XAB],字符Å则表示成字节[0XC3, 0X85],而一个带有°的A字符则表示成[0X41, 0XCC, 0X81]。当然,从用户的角度看,字符Å应该在比较和排序时都是相等的,无论其底层字节如何表示。
第一个问题并不是我们想象的那样严重,因为所有Go语言中的UTF-8字节序列(即字符串)使用的都是同样的码点到字节的映射。这也意味着,Go语言中的é字符在字符或者字符串字面量中使用同样的字节进行表示。同时,如果我们只关心ASCII字符(即英语),这个问题也就不存在。即便是要处理非ASCII字符,这个问题也仅仅在以下情况下才存在:当我们有两个看起来一样的字符时,或者当我们从一个外部来源中读取UTF-8字节时,这个来源的码点到字节的映射是合法的UTF-8但又不同于Go语言的映射。如果这真的是一个问题,那么也可以写一个自定义的标准化函数来保证不出错。例如,写一个函数使得é总是使用字节[0xC3, 0xA9](Go语言原生支持这种表示)来表示,而非字节[0x65, 0xCC, 0x81](即是一个e和一个 ´ 组合起来的字符)。Unicode标准格式文档(unicode.org/reports/tr15)中对如何标准化Unicode编码字符有详细解释。撰写本文时,Go语言的标准库有一个实验性的标准化包(exp/norm)。
由于第一个问题只有当字符串来自于外部源时才可能引起,并且只有当它们使用不同于Go语言的码点到字节的映射时才发生,这个可以通过隔离接收外部字符串的代码来解决。隔离的代码可以在将接收到的字符串提供给程序之前将其标准化。
第二个问题是,有些情况下用户可能会希望把不同的字符看成相同的。例如,我们可能写一个程序来为用户提供文本搜索功能,而用户可能输入单词“file”。通常,用户可能希望搜索所有包含“file”的地方,但用户也可能希望输入所有与“file”(即一个紧跟着“le”的“fi”字符)匹配的地方。类似地,用户可能希望搜索“5”的时候能够匹配“5”、“5”、“5”,甚至是“○5”。与第一个问题一样,这也可以使用一些标准化形式来解决。
第三个问题是,有些字符的排序是与语言相关的。其中一个例子是,瑞典语中的ä在排序时排z之后,但在德国的电话本中排序时拼成ae,而在德国的字典上则被拼成a。另一个例子是,虽然在英文中我们在排序时将其排成 o,但在丹麦语和挪威语中,它往往排在 z 之后。这方面有许许多多的规则,并且由于有时应用程序被不同国家的人使用(因此期望不同的排序规则),有时字符串中混杂着各种语言(如一些西班牙语和英语),有些字符(如箭头、修饰符以及数学符号)根本上就没有实际的排序索引意义,这些规则可能很复杂。
从有利的方面讲,Go语言对字符串按字节比较的方式相当于英文的ASCII 排序方式。并且,如果将要比较的字符串转成全部小写或者全部大写,我们可以得到一个更加自然的英语语言顺序,我们将在后面的例子中看到(参见4.2.4节)。
3.3 字符和字符串
在 Go语言中,字符使用两种不同的方式(可以很容易地相互转换)来表示。一个单一的字符可以用一个单一的rune(或者int32)来表示。从现在开始,我们交替使用术语“字符”、“码点”、“Unicode字符”以及“Unicode码点”来表示保存一个单一字符的rune(或者int32)。Go语言的字符串表示一个包含0个或者多个字符序列的串。在一个字符串内部,每个字符都表示成一个或者多个UTF-8编码的字节。
我们可以使用Go语言的标准转换语法(string(char))将一个字符转换成一个只包含单个字符的字符串。这里有一个例子。
æs := ""
for _, char := range rune{'æ', 0xE6, 0346, 230, '\xE6', '\u00E6'} {
fmt.Printf("[0x%X '%c'] ", char, char)
æs += string(char)
}
这段程序会输出一个行,其中包含6个重复的“[0XE6 'æ']”文本。最后,字符串æ会包含文本 ææææææ。(马上我们会看到使用字符串的+= 操作符通过循环来写成的一个更高效的解决方案。)
一个字符串可以使用语法 chars := rune(s)转换成一个 rune(即码点)切片,其中S是一个字符串类型的值。变量chars的类型为int32,因为rune是int32的同义词。这在我们需要逐个字符解析字符串,同时需要在解析过程中能查看前一个或后一个字符时会有用。相反的转换也同样简单,其语法为S:=string(chars),其中chars的类型为rune或者int32,得到的S的类型为字符串。这两个转换都不是无代价的,但这两个转换理论上都比较快(时间代价为O(n),其中n是字节数,看下文中的“大O详解”)。更多关于字符串转换的示例请看表3-2。关于数字到字符串的转换情况见表3-8和表3-9。
虽然方便,但是使用+= 操作符并不是在一个循环中往字符串末尾追加字符串最有效的方式。一个更好的方式(Python程序员可能非常熟悉)是准备好一个字符串切片(string),然后使用strings.Join函数一次性将其中所有字符串串联起来。但在Go语言中还有一个更好的方法,其原理类似于Java中的StringBuilder。这里有个例子。
var buffer bytes.Buffer
for {
if piece, ok := getNextValidString; ok {
buffer.WriteString(piece)
} else {
break
}
}
fmt.Print(buffer.String, "\n")
我们开始时创建了一个空的bytes.Buffer 类型值。然后使用 bytes.Buffer.WriteString方法将我们需要串联起来的字符串写入到 buffer 中(当然,我们也可以在每个字符串之间写入一个分隔符)。最后,bytes.Buffer.String方法可以用于取回整个级联的字符串(后面我们会看到bytes.Buffer类型的强大功能)。
将一个bytes.Buffer类型中的字符串累加起来可能比 += 操作符在节省内存和操作符方面高效得多,特别是当需要级联的字符串数量很大时。
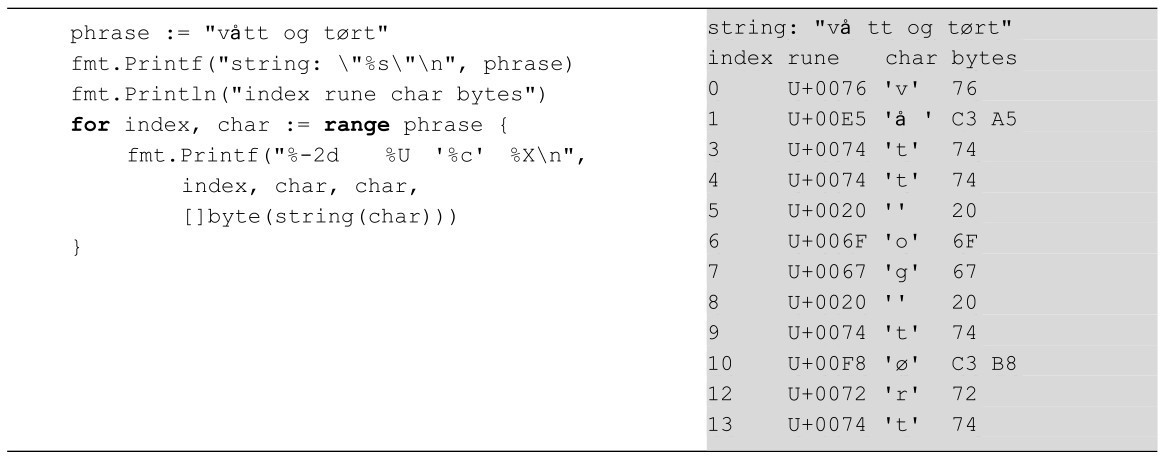
Go语言的for...range循环(参见5.3节)可以用于一个字符一个字符的迭代字符串,每次迭代都产生一个索引位置和一个码点。下面是一个例子,旁边为其输出。
大O表示法
大O表示法O(…)在复杂性理论中是为特定算法所需的处理器和内存消耗给出一个近似边界。大多数都是以n的比例来衡量,其中n为需要处理的项的数量,或者该项的长度。它们可以用来衡量内存消耗或者处理器的时间消耗。
O(1)意味着常量时间,也就是说,无论n的大小为何,这都是最快的可能。O(log n)意味着对数时间,速度很快,与log n成正比。O(n) 意味着线性时间,速度也很快,并且与n成正比。O(n2)(n的2次方)意味着二次方时间,速度开始变慢,并且与n的平方成正比。O(nm) (n的m次方),意味着多项式时间,随着n的增长,它很快就变得很慢,特别是当m≥3时。O(n!)意味着阶乘时间,即使是对于小的n值,这在实际使用中也会非常慢。
本书在很多地方都使用大O表示法来方便地解释处理程序的代价,例如,将字符串转换成rune的代价。
上面程序先创建 phrase 字符串字面量,然后在下一行的一个标题之后将其输出。然后我们迭代字符串中的每一个字符。Go语言的for...range循环在迭代时将UTF-8字节解码成Unicode码点(rune类型),因此我们不必关心其底层实现。对于每一个字符,我们将其索引位置、码点的值(使用Unicode表示法)、它所表示的字符以及对应的UTF-8字节编码等信息输出。
为了得到一串字节码,我们将码点(rune 类型的字符)转换成字符串(它包含一个由一个或者多个 UTF-8 编码字节编码而成的字符)。然后,我们将该单字符的字符串转换成一个byte切片,以便获取其真实的字节码。其中的byte(string)转换非常快(O(1)),因为在底层byte 可以简单地引用字符串的底层字节而无需复制。同样,其逆向转换string(byte)的原理也类似,其底层字节也无需复制,因此其代价也是O(1)。表3-2列出了Go语言的字符串与字节码之间的相互转换。
我们会马上解释程序中的%-2d、%U、%c以及%X格式化声明符(参见3.5节)。如你所见,当 %X 声明符用于数字时,它输出该数字的十六进制,当其用于byte 时,它输出一个含两个十六进制数字的序列,一个数字代表一个字节。这里我们通过在格式声明符中加入空格来声明其输出结果需以空格分隔。
在实际的编程中,通过与strings包和fmt包(以及少数情况下来自于strconv、unicode、unicode/utf8的包)中的函数相配合,使用for...range循环来迭代字符串中的字符为处理和操作字符串提供了方便而强大的功能。此外字符串类型还支持切片(因为在底层一个字符串实际上就是一个增强的byte切片),这非常有用,只要我们小心不将一个多字节的字符切片成一半。
3.4 字符串索引与切片
正如表3-2所示,Go语言支持Python中字符串分割语法的一个子集。我们将在第4章看到,这个语法可以用于任意类型的切片。
由于Go语言的字符串将其文本保存为UTF-8编码的字节,因此我们必须非常小心地只在字符边界处进行切片。这在我们的文本中所包含的字符是7位的ASCII编码字符的情况下非常简单,因为一个字节代表一个字符,但是对于非ASCII文本将更有挑战,因为这些字符可能用一个或者多个字节表示。通常我们完全不需要切片一个字符串,只需使用for...range循环将其一个字符一个字符地迭代,但是有些情况下我们确实需要使用切片来获得一个子字符串。有个能够确定能按字符边界进行切片得到索引位置的方法是,使用Go语言的strings包中的函数如strings.Index或者strings.LastIndex。strings包的函数已列在表3-6和表3-7中。
我们将从不同的角度解析字符串。索引位置(即字符串的UTF-8编码字节的位置)从0开始,直到该字符串的长度减1。当然也可以使用从len(s)-n这样的索引形式来从字符串切片的末尾开始往前索引,其中n为从后往前数的字节数。例如,给定一个赋值s := "naïve",如图3-1给出了其Unicode字符、码点、字节以及一些合法的索引位置和一对切片。
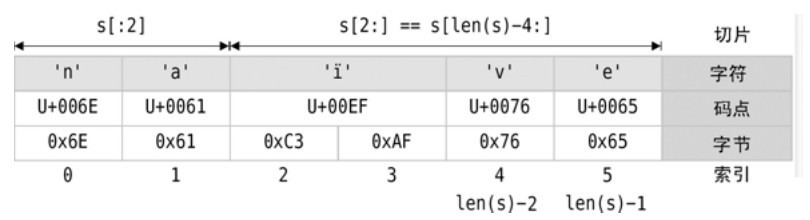
图3-1 字符串剖析
图3-1所示的每一个位置索引都可以用索引操作符来返回其对应的ASCII字符(以字节的形式)。例如,s[0] == 'n'和s[len(s)-1] == 'e'。ï字符的起始索引位置为2,但如果我们使用s[2]我们只能够得到编码ï字符(0xC3)的第一个UTF-8字节,而这并不是我们想要的。
对于只包含7位ASCII字符的字符串,我们可以使用s[0]这样的语法来取得其第一个字符(以字节的形式),也可以使用s[len(s)-1]的形式来取得其最后一个字符。然而,通常而言,我们应该使用 utf8.DecodeRuneInString来获得第一个字符(作为一个 rune,与UTF-8字节数字一起表示该字符),而使用utf8.DecodeLastRuneInString来获得其最后一个字符(详见表3-10)。
如果我们确实需要索引单个字符,也有许多可选的方法。对于只包含7位ASCII字符的字符串,我们只需简单地使用索引操作符,该查找非常的快速(O(1))。对于包含非 ASCII 字符组成的字符串,我们可以将其转换成rune再使用索引操作符。这也提供了非常快速的查找性能(O(1)),其代价在于一次性的转换耗费了CPU和内存(O(n))。
在我们的例子中,如果我们这样写chars := rune(s),那么chars变量将被创建为一个包含5个码点的rune(即int32)切片,而非图3-1中所示的6个字节。同时,我们也讲过可以使用string(char)语法很容易地将任何rune类型转换成一个包含一个字符的字符串。
对于任意字符串(即那些可能含有非 ASCII 字符的字符串),通过索引来提取其字符通常不是正确的方法。更好的方法是使用字符串切片,它可以很方便地返回一个字符串而非一个字节。为了安全地切片任意字符串,最好使用表3-6和表3-7中介绍的strings包中的函数来获得我们需要切片的索引位置。
以下等式对于任意字符串切片都成立,事实上,对于任意类型的切片都成立:
s == s[:i] + s[i:] // s是一个字符串,i是一个整型,0 <= i <= len(s)
现在让我们看一个实际的切片例子,其中使用的方法很原始。假设我们有一行文本,并且想从该文本中提取该行的第一个和最后一个字。一个简单的方式是这样写代码:
line := "røde og gule sløjfer"
i := strings.Index(line, " ") // 获得第一个空格的索引位置
firstWord := line[:i] // 从第一个字开始时切片直到第一个空格
j := strings.LastIndex(line, " ") // 获得最后一个空格
lastWord := line[j+1:] // 从最后一个空格开始切片到最后一个字
fmt.Println(firstWord, lastWord) // 输出:røde sløjfer
字符串类型的变量firstWord被赋值为字符串line中的从索引位置0(第一个字节)开始到索引位置i-1(第一个空格之前的字节)之间的字符串,因为字符串切片返回从开始到其结束位置处的字符串,但不包含该结束位置。类似地,lastWord 被赋值为字符串 line 中从索引位置j+1(最后一个空格后面的字节)到line结尾处(即到索引位置为len(line)-1处)的字符串。
虽然这个实例可以用于处理空格以及所有 7 位的ASCII 字符,但是却不适于处理任意的Unicode空白字符如U+2028(行分隔符)或者U+2029(段落分隔符)。
下面这个例子在以任意空白符分隔字的情况下都可以找出其第一个字和最后一个字。
line := " år tørt\u2028vær"
i := strings.IndexFunc(line, unicode.IsSpace) // i == 3
firstWord := line[:i]
j := strings.LastIndexFunc(line, unicode.IsSpace) // j == 9
_, size := utf8.DecodeRuneInString(line[j:]) // size == 3
lastWord := line[j+size:] // j + size == 12
fmt.Println(firstWord, lastWord) // 打印:rå vær
如图3-2所示,字符串line以字符、码点以及字节的形式给出。该图也给出了其字节索引位置以及上文代码片段中使用到的切片。
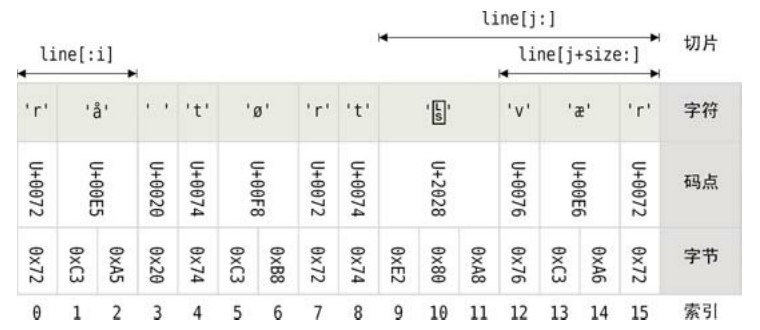
图3-2 带空白符的字符串剖析
strings.IndexFunc函数返回作为第一个参数传入的字符串中对于作为第二个参数传入的函数(其签名为 func(rune)bool)返回 true 时的字符索引位置。函数 stirngs.LastIndexFunc与此类似,只不过它适于从字符串的结尾处开始工作并返回当函数返回true时的最后一个字符索引位置。这里我们传入unicode包的IsSpace函数作为其第二个参数,该函数接受一个Unicode码点(其类型为rune)作为其唯一的参数,如果该码点是一个空白符则返回true(详见表3-11)。一个函数的名字是该函数的引用,因此可以用于传递给另一个需要函数参数的地方,只要该命名函数(即所引用的函数)的签名与声明的参数相符合(参见4.1节)。
使用 strings.IndexFunc函数来找到第一个空白符,并从头开始到该空白符索引位置的前一位将字符串切片,就可以很容易地得到字符串的第一个字。但是在搜索最后一个空白符的时候就得小心点,因为有些空白符被编码成不止一个 UTF-8 字节。我们可以通过使用utf8.DecodeRuneInString函数解决这个问题,这个函数可以告诉我们字符串切片中起始位置与最后一个空格符的起始位置对应的那个字符所占字节数为多少。然后,我们将这个数字与最后一个空白符所在的索引位置相加,就能够跳过最后一个空白字符,无论用于表示空白字符的字节数为多少,这样我们就能够将最后一个字切片出来。
3.5 使用fmt包来格式化字符串
Go语言标准库中的fmt包提供了打印函数将数据以字符串形式输出到控制台、文件、其他满足io.Writer 接口的值以及其他字符串中。这些函数已在表 3-3 中列出。有些输出函数返回值为error。当将数据打印到控制台时,常常将该错误值忽略,但是如果打印到文件和网络连接等地方时,则一定要检查该错误值[1]。
表3-3 fmt包中的打印函数

fmt包也提供了一系列扫描函数(如fmt.Scan、fmt.Scanf以及fmt.Scanln函数)用于从控制台、文件以及其他字符串类型中读取数据。其中有些函数将在第8章用到(参见8.1.3.2节)以及表8-2。扫描函数的一种替代是使用strings.Fields函数将字符串分隔为若干字段然后使用strconv包中的转换函数将那些非字符串的字段转换成相应的值(如数值),详见表3-8和表3-9。第1章中我们提到,我们可以创建一个bufio.Reader通过从os.Stdin读取数据来获得用户的输入,然后使用bufio.Reader.ReadString函数来读取用户输入的每一行(参见1.7节)。
输出值的最简单方式是使用fmt.Print函数和fmt.Println函数(输出到os.Stdout,即控制台),或者使用fmt.Fprint函数和fmt.Fprintf函数来输出到给定的io.Writer(如一个文件),或者使用fmt.Sprint函数和fmt.Sprintln函数来输出到一个字符串。
type polar struct {radius, 0 float64}
p := polar{8.32,.49}
fmt.Print(-18.5, 17, "Elephant", -8+.7i, 0x3C7, '\u03C7', "a", "b", p)
fmt.Println
fmt.Println(-18.5, 17, "Elephant", -8+.7i, 0x3C7, '\u03C7', "a", "b", p)
-18.5·17Elephant(-8+0.7i)·967·967ab{8.32·0.49}
-18.5·17·Elephant·(-8+0.7i)·967·967·a·b·{8.32·0.49}
为了清晰起见,特别是当连续输出空格的时候,我们必须在每一个显示的空格之间放入一个字符(·)。
fmt.Print函数和fmt.Fprint函数处理空白符的方式与fmt.Println函数和fmt.Fprintln函数处理空白符的方式略有不同。作为一个经验法则,前者更多地用于输出单个值,或者用于不检查错误值的情况下将某个值转换成字符串(使用 strconv 包来做更好的转换),因为它们只在非字符串的值之间输出空格。后者更适用于输出多个值,因为它们会在多个输出值之间加入空格,并在末尾添加一个换行符。
在底层,这些函数都统一使用%v格式符,并且它们都可以以各种形式打印任何内置的或者自定义的值。例如,这里的打印函数对自定义的polar类型一无所知,但仍然能够成功地打印polar的值。
在第6章中,我们将会为自定义类型提供一个String方法,这个方法允许我们将该自定义类型以我们期望的方式输出。如果我们想要对内置类型的打印也拥有类似的控制权,我们可以使用一个将格式化字符串作为第一个参数的打印函数。
用于 fmt.Errorf、fmt.Printf、fmt.Fprintf以及 fmt.Sprintf函数的格式字符串包含一个或者多个格式指令,这些格式指令的形式是%ML,其中M表示一个或者多个可选的格式指令修饰符,而 L 则表示一个特定的格式指令字符。这些格式指令已在表 3-4中列出。有些格式指令可以接收一个或者多个修饰符,这些修饰符已在表3-5中列出。
表3-4 fmt包中的格式指令

续表

表3-5 fmt包中的格式指令修饰符

续表
现在让我们来看一些格式化字符串的代表性例子,以便弄清楚它们是如何工作的。在每一个案例中,我们会给出一小段代码以及该代码的输出[2]。
3.5.1 格式化布尔值
布尔值使用%t(真值,truth value)格式指令来输出。
fmt.Printf("%t %t\n", true, false)
true false
如果我们想以数值的形式输出布尔值,那么我们必须做这样的转换:
fmt.Printf("%d %d\n", IntForBool(true), IntForBool(false))
1 0
这里使用了一个小的自定义函数。
func IntForBool(b bool) int {
if b{
return 1
}
return 0
}
我们也可以使用 strconv.ParseBool函数来将字符串转换回布尔值。当然,将字符串转换成数字也有类似的函数(参见3.6.2节)。
3.5.2 格式化整数
现在让我们来看看整数的格式化,从二进制数字(基数为2)的输出开始。
fmt.Printf("|%b|%9b|%-9b|%09b|% 9b|\n", 37, 37, 37, 37, 37)
|100101|···100101|100101···|000100101|···100101|
第一个格式(%b)使用%b(二进制)格式指令,它使用尽量少的数字将一个整数以二进制的形式输出。第二个格式(%9b)声明了一个长度为9的字符(为了防止截断,可能会超出输出时所需要的长度),并且使用了默认的右对齐符。第三个格式(%-9b)使用-修饰符来左对齐。第四个格式(%09b)使用0作为填充符,第五个格式(% 9b)使用空格作为填充符。
八进制格式类似于二进制,但支持另一种格式。它使用 %o (八进制,octal)格式指令。
fmt.Printf("|%o|%#o|%# 8o|%#+ 8o|%+08o|\n", 41, 41, 41, 41, -41)
|51|051|·····051|····+051|-0000051|
使用 # 修饰符可以切换格式,从而在输出的时候以 0 打头。+ 修饰符会强制输出正号,如果没有该修饰符,正整数输出时前面没有正号。
十六进制格式使用 %x和%X格式指令,选择哪个取决于希望将16进制中的A到F字母以小写还是大写表示。
i := 3931
fmt.Printf("|%x|%X|%8x|%08x|%#04X|0x%04X|\n", i, i, i, i, i, i)
|f5b|F5B|·····f5b|00000f5b|0X0F5B|0x0F5B|
对于十六进制数字,变更格式修饰符(#)将导致输出时以0x或者0X开头。对于所有的数字,如果我们声明了一个比所需更宽的宽度,输出时会输出额外的空格以便将数字右对齐。如果所声明的宽度太小,则将整个数字输出,因此没有截断的风险。
十进制的数字使用%d(十进制,decimal)格式指令。唯一可用于当做填充符的字符是空格和0,但也容易使用自定义的函数来填充别的字符。
i = 569
fmt.Printf("|$%d|$%06d|$%+06d|$%s|\n", i, i, i, Pad(i, 6, '*'))
|$569|$000569|$+00569|$***569|
在最后一种格式中,我们使用%s(字符串,string)格式指令来输出一个字符串,因为那就是我们的Pad 函数所返回的。
func Pad(number, width int, pad rune) string {
s := fmt.Sprint(number)
gap := width - utf8.RuneCountInString(s)
if gap > 0 {
return strings.Repeat(string(pad), gap) + s
}
return s
}
utf8.RuneCountInString函数返回给定字符串的字符数。这个数字永远小于或等于其字节数。strings.Repeat函数接收一个字符串和一个计数,返回一个将该字符串重复给定次数后产生的字符串。我们选择将填充符以rune(即Unicode码点)的方式传递以防止该函数的用户传入包含不止一个字符的字符串。
3.5.3 格式化字符
Go语言的字符都是rune(即int32值),它们可以以数字或者Unicode字符的形式输出。
fmt.Printf("%d %#04x %U '%c'\n", 0x3A6, 934, '\u03A6', '\U000003A6')
934·0x03a6·U+03A6·'Φ'
这里我们以十进制和十六进制的形式输出了一个大写的希腊字母Phi(“Φ”),使用 %U格式指令来输出Unicode码点,以及使用%c(字符或者码点)格式指令来输出Unicode字符.
3.5.4 格式化浮点数
浮点数格式可以指定整体长度、小数位数,以及使用标准计数法还是科学计数法。
for _, x := range float64{-.258, 7194.84, -60897162.0218, 1.500089e-8} {
fmt.Printf("|%20.5e|%20.5f|%s|\n", x, x, Humanize(x, 20, 5, '*', ','))
}
|········-2.58000e-01|············-0.25800|************-0.25800|
|·········7.19484e+03|··········7194.84000|*********7,194.84000|
|········-6.08972e+07|·····-60897162.02180|***-60,897,162.02180|
|·········1.50009e-08|·············0.00000|*************0.00000|
这里我们使用一个for...range循环来迭代一个float64类型切片中的数字。
自定义的函数 Humanize返回一个该数字的字符串表示,该表示法包含了分组分隔符和填充符。
func Humanize(amount float64, width, decimals int, pad, separator rune) string {
dollars, cents := math.Modf(amount)
whole := fmt.Sprintf("%+.0f", dollars)[1:] // 去除"±"
fraction := ""
if decimals > 0 {
fraction = fmt.Sprintf("%+.*f", decimals, cents)[2:] // 去除"±0"
}
sep := string(separator)
for i := len(whole) - 3; i > 0; i -= 3 {
whole = whole[:i] + sep + whole[i:]
}
if amount < 0.0 {
whole = "-" + whole
}
number := whole + fraction
gap := width - utf8.RuneCountInString(number)
if gap > 0 {
return strings.Repeat(string(pad), gap) + number
}
return number
}
math.Modf函数将一个float64类型的数的整数部分和小数部分以两个float64类型的数的形式返回。为了以字符串的形式得到其整数部分,我们使用带正号格式的fmt.Sprintf函数强制输出正号,然后立即将其切片以去除正号。针对小数部分,我们也使用类似的技术,只是这次我们使用.m格式指令修饰符来声明需要使用*占位符的小数位数(因此在本例中,如果小数的值为2,那么其有效格式为 %+.2f)。对于小数部分,我们会去除其头部的−0或者+0。
组分隔符从右至左插入整个字符串中,如果数字为负值,则插入一个 − 符号。最后,我们将整个结果串联起来并返回,如果位数不够则填充。
%e、%E、%f、%g和%G格式指令既可以用于复数,也可以用于浮点数。%e和%E是科学计算法格式(指数的)格式指令,%f是浮点数格式指令,而%g和%G则是通用的浮点数格式指令。
然而,需要注意的一点是,修饰符会分别作用于复数的实部和虚部。例如,如果参数是一个复数,%6f格式产生的结果会占用至少20个字符。
for _, x := range complex128{2 + 3i, 172.6 - 58.3019i, -.827e2 + 9.04831e-3i} {
fmt.Printf("|%15s|%9.3f|%.2f|%.1e|\n",
fmt.Sprintf("%6.2f%+.3fi", real(x), imag(x)), x, x, x)
}
|····2.00+3.000i|(····2.000···+3.000i)|(2.00+3.00i)|(2.0e+00+3.0e+00i)|
|·172.60-58.302i|(··172.600··-58.302i)|(172.60-58.30i)|(1.7e+02-5.8e+01i)|
|··-82.70+0.009i|(··-82.700···+0.009i)|(-82.70+0.01i)|(-8.3e+01+9.0e-03i)|
对于第一组复数,我们希望小数点后输出不同数量的数字。为此,我们需要使用 fmt.Sprintf分别格式化复数的实部和虚部部分,然后以%15s格式将结果以字符串的形式输出。对于其他组的复数,我们直接使用%f和%e格式指令,它们总会在输出的复数两边加上圆括号。
3.5.5 格式化字符串和切片
字符串输出时可以指定一个最小宽度(如果字符串太短,打印函数会以空格填充)或者一个最大输出字符数(会将太长的字符串截断)。字符串可以以 Unicode 编码(即字符)、一个码点序列(即rune)或者表示它们的UTF-8字节码的形式输出。
slogan := "End Ó ré ttlæti♥"
fmt.Printf("%s\n%q\n%+q\n%#q\n", slogan, slogan, slogan, slogan)
End Ó ré ttlæti♥
"End Ó ré ttlæti♥"
"End \u00d3r\u00e9ttl\u00e6ti\u2665"
'End Ó ré ttlæti♥'
%s格式指令用于输出字符串,我们将很快提到它。%q(引用字符串)格式指令用于以Go语言的双引号形式输出字符串,其中会直接将可打印字符的可打印字面量输出,而其他不可打印字符则使用转义的形式输出(见表3-1)。如果使用了+号修饰符,那么只有 ASCII 字符(从U+0020到U+007E)会直接输出,而其他字符则以转义字符形式输出。如果使用了#修饰符,那么只要在可能的情况下就会输出Go原始字符串,否则输出以双引号引用的字符串。
虽然通常与一个格式指令相对应的变量是一个兼容类型的单一值(例如int型值相对应的%d或者%x),该变量也可以是一个切片数组或者一个映射,如果该映射的键与值与该格式指令都是兼容的(比如都是字符串或者数字)。
chars := rune(slogan)
fmt.Printf("%x\n%#x\n%#X\n", chars, chars, chars)
[45·6e·64·20·d3·72·e9·74·74·6c·e6·74·69·2665]
[0x45·0x6e·0x64·0x20·0xd3·0x72·0xe9·0x74·0x74·0x6c·0xe6·0x74·0x69·0x2665]
[0X45·0X6E·0X64·0X20·0XD3·0X72·0XE9·0X74·0X74·0X6C·0XE6·0X74·0X69·0X2665]
这里我们使用%x和%X格式指令以十六进制数字序列的形式打印了一个rune类型的切片,在本例中是一个码点切片,一个十六进制数字对应一个码点。
对于大多数类型,该类型的切片被输出时都会以方括号包围并以空格分隔。其中有个例外, byte只有在使用%v格式指令时才会输出方括号和空格。
bytes := byte(slogan)
fmt.Printf("%s\n%x\n%X\n% X\n%v\n", bytes, bytes, bytes, bytes, bytes)
End·Óréttlæti♥
456e6420c39372c3a974746cc3a67469e299a5
456E6420C39372C3A974746CC3A67469E299A5
45·6E·64·20·C3·93·72·C3·A9·74·74·6C·C3·A6·74·69·E2·99·A5
[69·110·100·32·195·147·114·195·169·116·116·108·195·166·116·105·226·153·165]
一个字节切片(这里是表示字符串的UTF-8 字节)可以以十六进制两位数序列的形式输出,其中一个数字表示一个字节。如果我们使用%s 格式指令,则字节切片会被假设为 UTF-8 编码的Unicode,并且以字符串的形式输出。虽然bytes类型没有可选的十六进制格式,但这些数字可以像上面倒数第二行所输出的那样使用空格分隔。格式指令%v 以一个方括号包围并以空格分隔的十进制值的形式输出bytes类型的值。
Go语言默认是居右对齐,我们可以使用-修饰符来将其居左对齐。当然,我们可以为像下面的例子所示范的那样,指定一个最小的域宽以及一个最大的字符数。
s := "Dare to be naive"
fmt.Printf("|%22s|%-22s|%10s|\n", s, s, s)
|······Dare·to·be·naï ve|Dare·to·be·naï ve······|Dare·to·be·naive|
在这段代码中,第三个格式(%10s)指定了最小域宽为10个字符,但因为字符串的长度比这个域宽要长(该域宽为最小值),所以字符串被完整打印出来。
i := strings.Index(s, "n")
fmt.Printf("|%.10s|%.*s|%-22.10s|%s|\n", s, i, s, s, s)
|Dare·to·be|Dare·to·be·|Dare·to·be············|Dare·to·be·naive|
这里,第一个格式(%.10s)声明了最多打印字符串的10个字符,因此这里输出的字符串被截断成指定的宽度。第二个格式(%.*s)希望输入两个参数——所打印字符个数的最大值和一个字符串,这里我们使用了字符串的第n个字符的索引位置来作为最大值,这意味着其索引位置小于该值的字符都将被打印出来。第三个格式(%-22.10s)同时声明了最小域宽度为22 个字符和最大输出字符个数为10字符,这也意味着在一个宽为22字符的域中最多只输出该字符串的前10个字符,由于其域宽比要打印的字符数大,因此该域使用空格填充,同时使用 - 修饰符来将其居左对齐。
3.5.6 为调试格式化
%T(类型)格式指令用于打印一个内置的或者自定义值的类型,而%v格式指令则用于打印一个内置值的值。事实上,%v 也可以打印自定义类型的值,对于没有定义String方法的值使用默认的格式,对于定义了String方法的值则使用该方法打印。
p := polar{-83.40, 71.60}
fmt.Printf("|%T|%v|%#v|\n", p, p, p)
fmt.Printf("|%T|%v|%t|\n", false, false, false)
fmt.Printf("|%T|%v|%d|\n", 7607, 7607, 7607)
fmt.Printf("|%T|%v|%f|\n", math.E, math.E, math.E)
fmt.Printf("|%T|%v|%f|\n", 5+7i, 5+7i, 5+7i)
s := "Relativity"
fmt.Printf("|%T|\"%v\"|\"%s\"|%q|\n", s, s, s, s)
|main.polar|{-83.4·71.6}|main.polar{radius:-83.4,·θ:71.6}|
|bool|false|false|
|int|7607|7607|
|float64|2.718281828459045|2.718282|
|complex128|(5+7i)|(5.000000+7.000000i)|
|string|"Relativity"|"Relativity"|"Relativity"|
上面这个例子给出了如何使用%T和%v来输出任意值的类型和值。如果满足%v格式指令的格式,那么我们可以简单地使用fmt.Print或者类似的使用%v作为默认格式的函数。与%v一起使用可选的格式化格式指令修饰符 #只对结构体类型起作用,这使得结构体输出它们的类型名字和字段名字。对于浮点数,%v格式更像%g格式指令而非%f格式指令。%T格式在调试方面非常有用,对于自定义类型可以包含其包名(本例中是main)。对字符串使用%q格式指令可以将它们放入引号中方便调试。
Go语言中有两种类型是同义的:uint8和byte,int32和rune。处理int不能处理的32位有符号整数(例如读写二进制文件)时使用int32,处理Unicode码点时使用rune(字符)。
s := "Alias↔Synonym"
chars := rune(s)
bytes := byte(s)
fmt.Printf("%T: %v\n%T: %v\n", chars, chars, bytes, bytes)
int32: [65 108 105 97 115 8596 83 121 110 111 110 121 109]
uint8: [65 108 105 97 115 226 134 148 83 121 110 111 110 121 109]
如上例说明的那样,%T格式指令总是输出其原始类型名,而非其同义词。由于字符串中包含一个非ASCII的字符,因此很明显可以发现我们创建了一个rune切片(码点)和一个UTF-8编码的字节切片。
我们也可以使用%p格式指令来输出任意值的地址。
i := 5
f := -48.3124
s := "Tomá s Bretón"
fmt.Printf("|%p→ %d|%p→ %f|%#p→ %s|\n", &i, i, &f, f, &s, s)
|0xf840000300·→·5|0xf840000308·→·-48.312400|f840001990·→·Tomás·Bretón|
&地址操作符将在下一章介绍(参见4.1节)。如果我们使用%p格式指令和#修饰符,则会将地址开头处的0x剔除掉。这样输出的地址对于调试非常有帮助。
Go语言的输出切片和映射的功能对调试非常有用,正如输出通道的功能一样,也就是说我们可以输出该通道支持发送和接收的类型以及该通道的内存地址。
fmt.Println(float64{math.E, math.Pi, math.Phi})
fmt.Printf("%v\n", float64{math.E, math.Pi, math.Phi})
fmt.Printf("%#v\n", float64{math.E, math.Pi, math.Phi})
fmt.Printf("%.5f\n", float64{math.E, math.Pi, math.Phi})
[2.718281828459045·3.141592653589793·1.618033988749895]
[2.718281828459045·3.141592653589793·1.618033988749895]
float64{2.718281828459045,·3.141592653589793,·1.618033988749895}
[2.71828·3.14159·1.61803]
使用未修饰的%v格式指令,切片可以以方括号包围并将每一项以空格分隔的形式输出。通常我们使用类似fmt.Print和fmt.Sprint这样的函数将其输出,但如果我们使用一个格式化的输出函数,那么其常用的格式指令是%v或者%#v。然而,我们也可以使用一个类型兼容的格式指令,如用于浮点数的%f和用于字符串的%s。
fmt.Printf("%q\n", string{"Software patents", "kill", "innovation"})
fmt.Printf("%v\n", string{"Software patents", "kill", "innovation"})
fmt.Printf("%#v\n", string{"Software patents", "kill", "innovation"})
fmt.Printf("%17s\n", string{"Software patents", "kill", "innovation"})
["Software·patents"·"kill"·"innovation"]
[Software·patents·kill·innovation]
string{"Software·patents",·"kill",·"innovation"}
[·Software·patents··············kill········innovation]
当字符串中包含空格时,使用%q格式指令来输出字符串切片非常有用,因为这使得每个单个的字符串都是可识别的。使用%v格式指令无法做到这点。
最后一个输出初看起来可能有误,因为它占用了 53 个字符(不包括两边的方括号)而非51个(3个17字符的字符串,都不大)。这个明显的差异在于输出的每一个切片项目之间的空格分隔符。
为了更好地调试,使用%#v格式指令可以以编程的形式输出Go语言代码。
fmt.Printf("%v\n", map[int]string{1: "A", 2: "B", 3: "C", 4: "D"})
fmt.Printf("%#v\n", map[int]string{1: "A", 2: "B", 3: "C", 4: "D"})
fmt.Printf("%v\n", map[int]int{1: 1, 2: 2, 3: 4, 4: 8})
fmt.Printf("%#v\n", map[int]int{1: 1, 2: 2, 3: 4, 4: 8})
fmt.Printf("%04b\n", map[int]int{1: 1, 2: 2, 3: 4, 4: 8})
map[4:D·1:A·2:B·3:C]
map[int]·string{4:"D",·1:"A",·2:"B",·3:"C"}
map[4:8·1:1·2:2·3:4]
map[int]·int{4:8,·1:1,·2:2,·3:4}
map[0100:1000·0001:0001·0010:0010·0011:0100]
映射的输出内容以关键字“map”开头,然后是该映射的“键/值”对(以任意的顺序,因为映射是无序的)。正如切片一样,它也可以使用除%v 之外的格式指令输出,但只限于其键和值与该格式指令相兼容的情况,正如本例中最后一条语句中那样。(映射和切片将在第4章详细阐述。)
fmt包的输出函数功能非常丰富,并且可以用于输出任意我们想要的东西。该包唯一没有提供的功能是以某种特定的字符串进行填充(而非 0 或者空格),但正如我们所看到的Pad (参见3.5.2节)和Humanize(参见3.5.4节)函数一样,要做到这些也非常简单。
3.6 其他字符处理相关的包
Go语言处理字符串的强大之处不仅限于对索引和切片的支持,也不限于fmt的格式化功能。strings包提供了非常强大的功能,此外strconv、unicode/utf8、unicode等也提供了大量实用的函数,这一节出现的就不少。这本书有好几个地方都用到了regexp提供的正则表达式,本节后面也有介绍。
除此之外,标准库里还有很多其他的包同样提供了字符串相关的功能,其中有一些在我们这本书的例子和习题里经常用到。
3.6.1 strings包
一个常见的字符串处理场景是,我们需要将一个字符串分隔成几个字符串后再做其他处理(例如转换成数字或者过滤空格等)。
为了让大家知道怎么去使用strings包里的函数,我们来看一些非常简单的使用示例。表3-6和表3-7里列出了strings包里所有的函数。首先,我们从分隔一个字符串开始:
names := "Niccolò•Noël•Geoffrey•Amélie••Turlough•José"
fmt.Print("|")
for _, name := range strings.Split(names, "•") {
fmt.Printf("%s|", name)
}
fmt.Println
|Niccolò|Noël|Geoffrey|Amélie||Turlough|José|
names 是一个使用圆点符号分隔的名字列表(注意,有一个名字是空的)。我们使用strings.Split函数来切分它,这个函数可以将一个字符串按照指定的分隔符全部切分开,使用strings.SplitN可以指定切的次数(从左到右)。如果使用strings.SplitAfter函数的话输出结果是这样的:
|Niccolò•|Noël•|Geoffrey•|Amélie•|•|Turlough•|José|
函数strings.SplitAfter 执行的操作和strings.Split是一样的,但是保留了分隔符。同理,strings.SplitAfterN函数可以指定切割的次数。
如果我们想按两个或更多字符进行切分,可以使用strings.FieldsFunc函数。
for _, record := range string{"László Lajtha*1892*1963",
"Édouard Lalo\t1823\t1892", "José Ángel Lamas|1775|1814"} {
fmt.Println(strings.FieldsFunc(record, func(char rune) bool {
switch char {
case '\t', '*', '|':
return true
}
return false
}))
}
[László·Lajtha·1892·1963]
[Édouard·Lalo·1823·1892]
[José·Ángel·Lamas·1775·1814]
strings.FieldsFunc 函数有两个参数,一个字符串(这个例子里是record变量),一个签名为func(rune) bool的函数引用。因为这个函数很小而且只用在这个地方,所以我们直接在调用它的地方创建了一个匿名函数(用这种方式创建的函数称之为闭包,不过在这里我们并没有用到引用环境,参见 5.6.3 节)。strings.FieldsFunc函数遍历字符串并将每一个字符作为参数传递给函数引用,如果该函数返回true则执行切分操作。从上面的代码我们可以看出,程序在遇到缩进符号、星号或者竖线的地方进行切分。(Go语言的switch语句在5.2.2节介绍。)
使用 strings.Replace函数,我们可以将在一个字符串中出现的某个字符串全部替换成另一个,例如:
names = " Antônio\tAndré\tFriedrich\t\t\tJean\t\tÉlisabeth\tIsabella \t"
names = strings.Replace(names, "\t", " ", -1)
fmt.Printf("|%s|\n", names)
|·Antônio·André··Friedrich···Jean··Élisabeth·Isabella··|
strings.Replace的参数有原字符串、被替换的字符串、用来替换的字符串,还有一个指定要替换(从左到右)的次数(−1 表示没有限制),返回一个完成替换的字符串(替换结果不会相互交叠)。
表3-6 strings包里的函数列表 #1

续表
表3-7 strings包里的函数列表#2

续表

通常,当我们接收到一些用户输入或者是外部输入的数据时,需要处理一下字符串中出现的空白,比如说去掉首尾的空白字符,还有将中间出现的空白用一个简单的空格符来代替等,可以这么做:
fmt.Printf("|%s|\n", SimpleSimplifyWhitespace(names))
|Antônio·André·Friedrich·Jean·Élisabeth·Isabella|
函数SimpleSimplifyWhitespace 实际上只有一行代码。
func SimpleSimplifyWhitespace(s string) string {
return strings.Join(strings.Fields(strings.TrimSpace(s)), " ")
}
其中,strings.TrimSpace返回一个去掉首尾空白的字符串。strings.Fields在字符串空白上进行分隔,返回一个字符串切片。而函数 strings.Join则将一个字符串切片重新拼凑成一个字符串,并用指定的分隔符隔开(分隔符可以为空,这里我们用了一个空格)。这3个函数的组合使用,就可以实现规范字符串空白的效果。
当然,我们还可以用bytes.Buffer来实现一种更加高效的空白处理方法。
func SimplifyWhitespace(s string) string {
var buffer bytes.Buffer
skip := true
for _, char := range s {
if unicode.IsSpace(char) {
if !skip {
buffer.WriteRune(' ')
skip = true
}
} else {
buffer.WriteRune(char)
skip = false
}
}
s = buffer.String
if skip && len(s) > 0 {
s = s[:len(s)-1]
}
return s
}
从上面的代码我们可知,函数SimplifyWhitespace 遍历输入字符串的每一个字符,使用unicode.IsSpace函数(见表3-11)跳过字符串开头所有的空白,然后将其他字符累加到 bytes.Buffer 里去,对于中间出现的所有空白处都用一个简单的空格符替换,原字符串结尾处的空白也会被去掉(算法允许结尾最多只有一个空格),最后返回需要的字符串。后面还有一种使用正则表达式来处理的版本,更加简单(参见3.6.5节)。
strings.Map函数可以用来替换或者去掉字符串中的字符。它需要两个参数,第一个是签名为func(rune) rune的映射函数,第二个是字符串。对字符串中的每一个字符,都会调用映射函数,将映射函数返回的字符替换掉原来的字符,如果映射函数返回负数,则原字符会被删掉。
asciiOnly := func(char rune) rune {
if char > 127 {
return '?'
}
return char
}
fmt.Println(strings.Map(asciiOnly, "JérômeÖsterreich"))
J?r?me·?sterreich
在这里我们没有像之前的例子 strings.FieldsFunc 那样直接在调用它的地方创建一个匿名函数,而是将一个匿名函数赋值给一个变量asciiOnly(相当于一个函数的引用)。然后我们将变量asciiOnly和一个待处理的字符串作为参数来调用strings.Map。最后打印返回的的字符串,把原字符串中所有的非ASCII字符都替换为“?”。当然了,我们也可以在直接调用映射函数的地方创建它,但是如果函数太长或者我们需要在多个地方用到它的话,分离它可以提高代码的复用程度。
要把非ASCII编码的字符删除掉然后输出下面这样的结果也是很容易的:
Jrme·sterreich
实现的方法就是修改映射函数,对于非ASCII编码的字符返回“−1”而不是“?”即可。
我们之前提到过可以用for...range循环(循环语句在5.3节介绍)以Unicode码点的形式来遍历一个字符串中所有的字符。从实现了ReadRune方法的类型中读取数据时可以得到类似的效果,例如bufio.Reader类型。
for {
char, size, err := reader.ReadRune
if err != nil { // 如果读者正在读文件可能发生
if err == io.EOF { // 没有事故结束
break
}
panic(err) // 出现了一个问题
}
fmt.Printf("%U '%c' %d: % X\n", char, char, size, byte(string(char)))
}
U+0043·'C'·1:·43
U+0061·'a'·1:·61
U+0066·'f'·1:·66
U+00E9·'é'·2:·C3·A9
这段代码读取一个字符串,输出每个字符的码点、字符本身和这个字符占用了多少个UTF-8字节,还有用来表示这个字符的字节序列。通常情况下reader是对文件进行操作,因此我们可能会假设reader变量是通过基于一个os.Open调用返回的reader调用bufio.NewReader而创建。我们曾在第一章的americanise 示例中见过这种用法(参见 1.6 节)。不过在本例中reader被创建用于操作一个字符串:
reader := strings.NewReader("Café")
strings.NewReader 返回的*strings.Reader实现了bufio.Reader的部分功能,包括 strings.Reader.Read、strings.Reader.ReadByte、strings.Reader.ReadRune、strings.Reader.UnreadByte、strings.Reader.UnreadRune等。这种能够操作具有某个特定接口(例如,这个类型实现了 ReadRune方法)的值而不是某个特定类型的值的能力,是Go语言一个非常强大和灵活的特性,这在第6章会有更详尽的介绍。
3.6.2 strconv包
strconv包提供了许多可以在字符串和其他类型的数据之间进行转换的函数。所有的函数都在表3-8和表3-9里(也可以看一下fmt包的打印和扫描函数,分别在3.5节和8.2节有介绍)。我们先来看一个简单的例子。
一种常见的需求是将真值的字符串表示转换成一个 bool。这可以使用 strconv.ParseBool函数来实现。
for _, truth := range string{"1", "t", "TRUE", "false", "F", "0", "5"} {
if b, err := strconv.ParseBool(truth); err != nil {
fmt.Printf("\n{%v}", err)
} else {
fmt.Print(b, " ")
}
}
fmt.Println
true·true·true·false·false·false
{strconv.ParseBool:·parsing·"5":·invalid·syntax}
表3-8 strconv包函数列表 #1

表3-9 strconv包函数列表 #2

所有的strconv转换函数返回一个结果和error变量,如果转换成功的话error为nil。
x, err := strconv.ParseFloat("-99.7", 64)
fmt.Printf("%8T %6v %v\n", x, x, err)
y, err := strconv.ParseInt("71309", 10, 0)
fmt.Printf("%8T %6v %v\n", y, y, err)
z, err := strconv.Atoi("71309")
fmt.Printf("%8T %6v %v\n", z, z, err)
·float64··-99.7·<nil>
···int64··71309·<nil>
·····int··71309·<nil>
上述代码中的strconv.ParseFloat、strconv.ParseInt、strconv.Atoi (ASCII 转换成 int)这 3 个函数可以做的事情比我们想象的多。strconv.Atoi(s)和strconv.ParseInt(s, 10, 0)的作用是一样的,就是将字符串形式表示的十进制数转换成一个整形值,唯一不同的是Atoi返回int型而ParseInt返回int64类型。顾名思义, strconv.ParseUint函数可以将一个无符号整数转换成字符串,字符串不能以负号开头,否则会转换失败。还要注意的是,当字符串开始处或者结尾处包含空白的话,所有的这些函数都会返回失败,但是我们可以使用 strings.TrimSpace函数来避免这种情况,或者使用fmt包里的扫描函数(表8-2中)。此外,浮点数转换还能处理包含数学标记或者指数符号的字符串,例如"984"、"424.019"、"3.916e-12"等。
s := strconv.FormatBool(z > 100)
fmt.Println(s)
i, err := strconv.ParseInt("0xDEED", 0, 32)
fmt.Println(i, err)
j, err := strconv.ParseInt("0707", 0, 32)
fmt.Println(j, err)
k, err := strconv.ParseInt("10111010001", 2, 32)
true
57069·<nil>
455·<nil>
1489·<nil>
strconv.FormatBool函数根据给定的布尔变量true或者false返回一个表示布尔表达式的字符串。strconv.ParseInt函数将一个字符串表示的整数转换成int64值。第二个参数是用来指定进制大小的,为 0的话表示根据字符串前缀来判断,如"0x"、"0X"表示十六进制,"0"表示八进制,其他都是十进制。在上面的例子里,我们根据字符串的前缀自动判断和转换了一个十六进制和一个八进制数,并以明确指定进制为2的方式转换了一个二进制数。进制大小在2到36之间,如果进制大于10则用A或a来表示10,其他以此类推。函数第三个参数是位大小(为0则默认是int大小),所以虽然函数总是返回int64,但是只有在真正能够转换成指定大小的整数时才会返回成功。
i := 16769023
fmt.Println(strconv.Itoa(i))
fmt.Println(strconv.FormatInt(int64(i), 10))
fmt.Println(strconv.FormatInt(int64(i), 2))
fmt.Println(strconv.FormatInt(int64(i), 16))
16769023
16769023
111111111101111111111111
ffdfff
函数strconv.Itoa(函数名是“Integer to ASCII”的缩写)将int型的整数转换成以十进制表示的字符串。而函数 strconv.FormatInt则可以将其转换成任意进制形式的字符串(进制参数一定要指定,必须在2~36这个范围内)。
s = "Alle ønsker å være fri."
quoted := strconv.Quote(s)
fmt.Println(quoted)
fmt.Println(strconv.Unquote(quoted))
"Alle·\u00f8nsker·\u00e5·v\u00e6re·fri."
Alle·ønsker·å·være·fri.·<nil>
函数 strconv.Quote 返回一个字面量字符串,首尾增加了双引号,并对所有不可打印的ASCII字符和非ASCII字符进行转义(Go语言的转义参见表3-1)。strconv.Unquote函数接受的参数为一个双引号字符串或者使用反引号的原生字符串,或者单引号括起来的字符,返回去除引号后的字符串和一个error变量(成功则为nil)。
3.6.3 utf8包
unicode/utf8 有几个很有用的函数,主要用来查询和操作UTF-8 编码的字符串或者字节切片,参见表 3-10。之前我们已经知道如何使用 utf8.DecodeRuneString函数和utf8.DecodeLastRuneInString 函数来获得一个字符串的首尾字符。
表3-10 utf8包

续表
3.6.4 unicode包
unicode包主要提供了一些用来检查Unicode码点是否符合主要标准的函数,例如,判断一个字符是否是一个数字或者小写字母。表3-11列出了一些常用的函数。除了unicode.ToLower和unicode.IsUpper等,还有一个通用的函数 unicode.Is,检查一个字符是否属于一个特定的Unicode分类。
fmt.Println(IsHexDigit('8'), IsHexDigit('x'), IsHexDigit('X'),
IsHexDigit('b'), IsHexDigit('B'))
true·false·false·true·true
表3-11 unicode包
续表
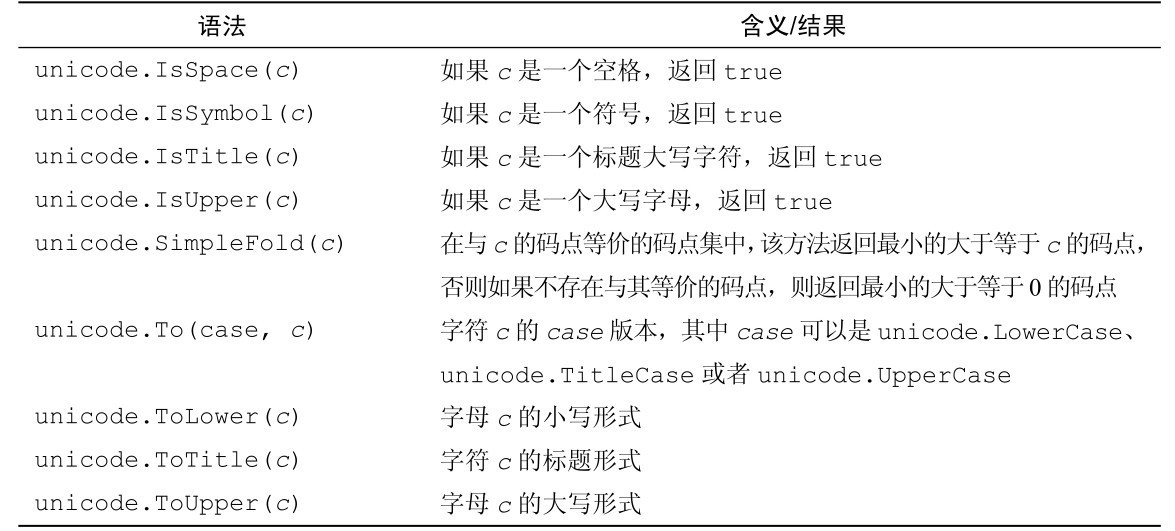
unicode 包里有 unicode.IsDigit 这样的函数,可以用来检查一个字符是否是一个十进制数字,但是并没有类似的函数可以检查十六进制数,所以这里用了一个自己实现的IsHexDigit函数。
func IsHexDigit(char rune) bool {
return unicode.Is(unicode.ASCII_Hex_Digit, char)
}
这个函数很简单,只用了一个 unicode.Is函数检查给定的字符是否在 unicode.ASCII_Hex_Digit范围内,以此来判断这是否是一个十六进制数。我们还可以创建类似的函数来测试其他Unicode字符。
3.6.5 regexp包
这一节的表很多,主要是列举了regexp包里的函数和支持的正则表达式语法,还包含一些示例。在开始讲这一节之前,我们假设大家都有一定的正则表达式基础[3]。
regexp包是Russ Cox的RE2正则表达式引擎的Go语言实现[4]。这个引擎非常快而且是线程安全的。RE2引擎并不使用回溯,所以能够保证线性的执行时间O(n),n是匹配字符串的长度,那些使用回溯的引擎的时间复杂度很容易达到指数级别O(2n)(参见3.3 节的大 O 表示法)。获取出色性能的代价是不支持搜索时的反向引用,不过通常只要合理利用regexp的API就能绕开这些限制。
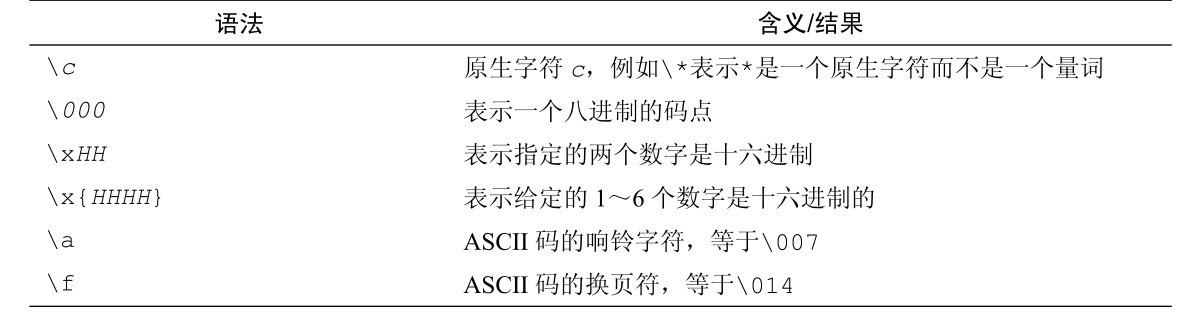
表3-12列出了regexp包里的函数,有4个可以创建一个*regexp.Regexp类型的值,表3-18和表3-19列出了*regexp.Regexp提供的方法。RE2引擎支持表3-13列出的转义序列、表3-14列出的字符类别、表3-15列出的零宽断言、表3-16列出的数量匹配,还有表3-17列出的标识。
regexp.Regexp.ReplaceAll方法和regexp.Regexp.ReplaceAllString方法都支持按编号或者名字进行替换。编号对应于正则表达式中的括号括起来的捕获组,而名字则对应已命名的捕获组。尽管我们可以直接使用数字或名字引用来进行替换,例如$2 或者$filename 等,但最好将数字和名字用大括号括起来,如${2}和${filename}等,如果替换的字符串中包含$字符,要使用$$来进行转义。
表3-12 regexp包函数列表

表3-13 regexp包支持的转义符号
续表

表3-14 regexp包支持的字符类
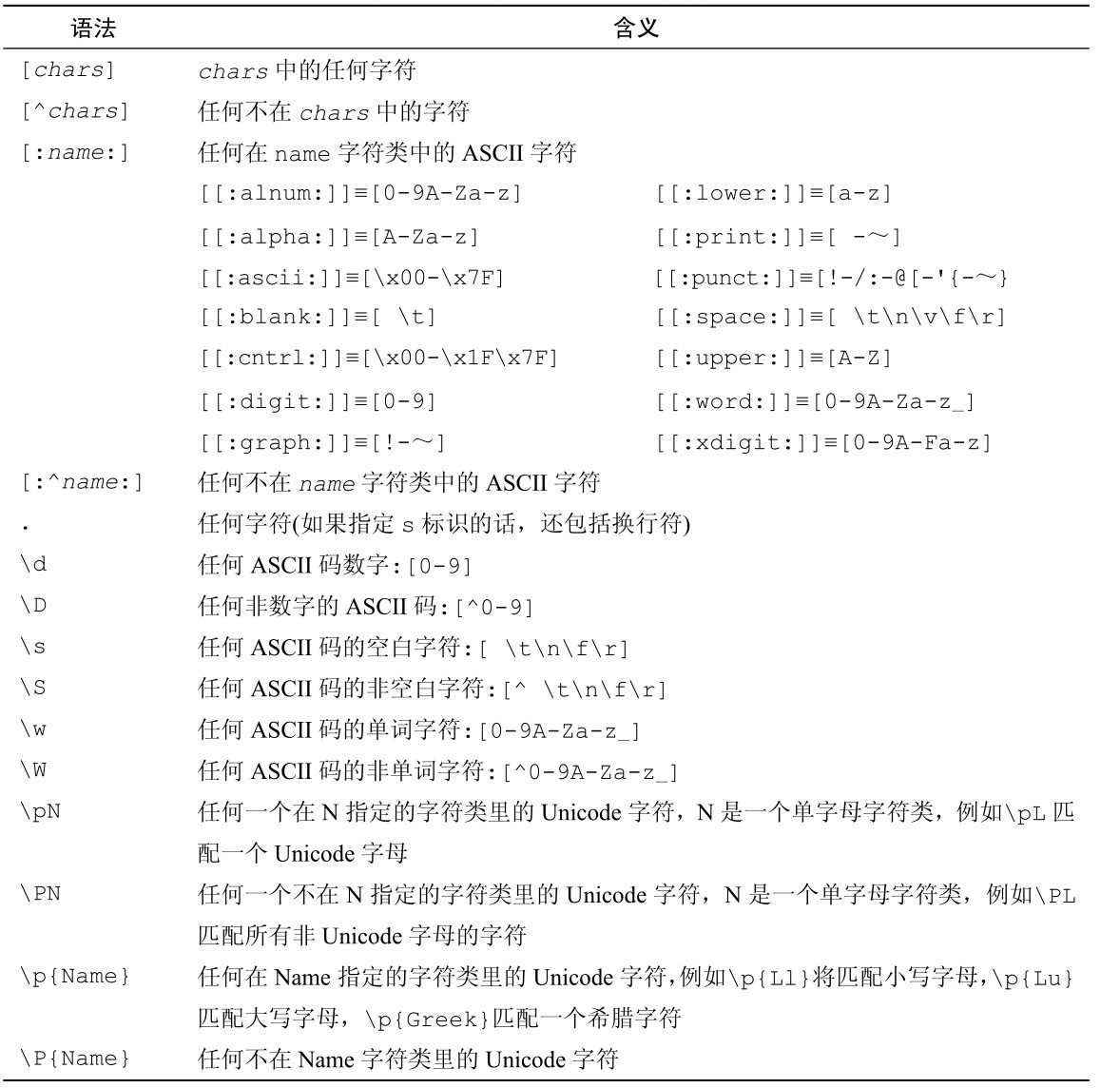
表3-15 regexp包的零宽断言

表3-16 regexp包的数量匹配

表3-17 regexp包的标识和分组

表3-18 *regexp.Regexp类型的方法 #1

续表
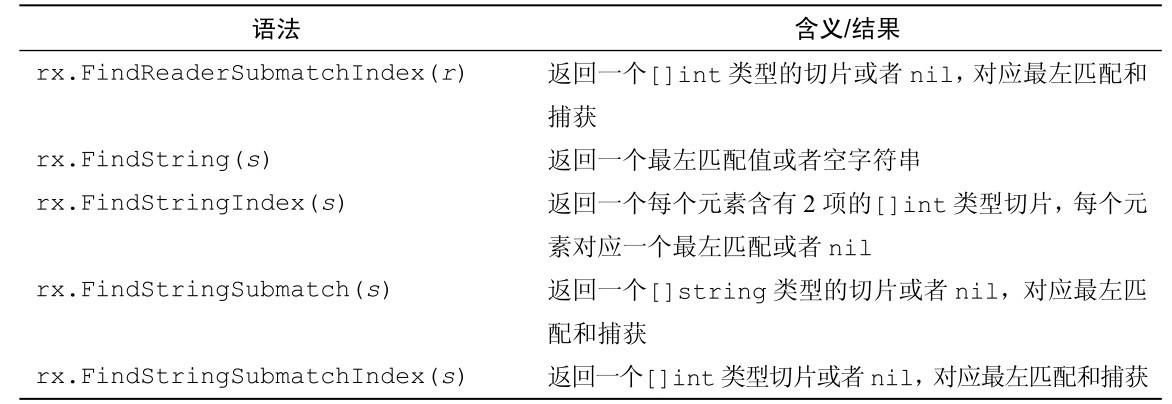
表3-19 *regexp.Regexp类型的方法 #2

续表

一个典型的替换例子就是,假如我们有一个形式如“forname1 … fornameN surname”格式的名字列表,现在我们想把它们转换成“surname, forname1 … fornameN”。看看我们是如何使用regexp包来实现这个功能且正确处理重音符号和其他的非英文字符。
nameRx := regexp.MustCompile(' (\pL+\.?(?:\s+\pL+\.?)*)\s+(\pL+)')
for i := 0; i < len(names); i++ {
names[i] = nameRx.ReplaceAllString(names[i], "${2}, ${1}")
}
变量names是一个字符串切片,保存了原来的名字列表。循环结束后names变量将被更新为修改后的名字列表。
这个正则表达式匹配一个或多个用空白分隔开的名字,每个名字由一个或者多个Unicode字母组成(名字后面可能有句号),然后紧接着空白和姓,姓也由一个或者多个Unicode字母组成。
根据数字编号来替换可能引入后期代码维护问题,例如,如果我们在中间插入一个捕获组,则至少有一个数字是错误的。解决的办法就是使用显式命名的方式执行替换,而不是依赖于数字型顺序。
nameRx := regexp.MustCompile(
'(?P<forenames>\pL+\.?(?:\s+\pL+\.?)*)\s+(?P<surname>\pL+)')
for i := 0; i < len(names); i++ {
names[i] = nameRx.ReplaceAllString(names[i],"${surname}, ${forenames}")
}
这里我们给两个捕获组指定了有意义的名字,使得正则表达式和替换字符串更容易被理解。
在Python或者Perl里,如果要匹配一个重复的单词,可以这样写“\b(\w+)\s+\1\b”,但是这种正则语法需要依赖于反向引用,而这个恰好是Go语言里regexp引擎所不支持的,为了实现相同的效果,我们还得多写点代码才行。
wordRx := regexp.MustCompile('\w+')
if matches := wordRx.FindAllString(text, -1); matches != nil {
previous := ""
for _, match := range matches {
if match == previous {
fmt.Println("Duplicate word:", match)
}
previous = match
}
}
这个正则表达式贪婪匹配一个或者多个单词,函数regexp.Regexp.FindAllString 返回一个不重叠的匹配结果,为string类型。如果至少存在一个匹配(matches不为nil),我们就遍历这个字符串切片,通过比较当前的单词和上一个单词,打印出所有重复的单词。
另一个常用的正则表达式是用来匹配一个配置文件里的“键:值”行,下面是一个例子,匹配指定的行并将其填充到map里面去。
valueForKey := make(map[string]string)
keyValueRx := regexp.MustCompile('\s*([[:alpha:]]\w*)\s*:\s*(.+)')
if matches := keyValueRx.FindAllStringSubmatch(lines, -1); matches != nil {
for _, match := range matches {
valueForKey[match[1]] = strings.TrimRight(match[2], "\t ")
}
}
这个正则表达式是说跳过所有字符串开始处的空白,然后匹配一个键,键必须是以英文字母开头后面可接着0个或者多个字母、数字、下划线,然后是冒号和值,注意键和冒号之间或者值和冒号之间可以允许存在空白,值可以是任何字符但不包括换行符和字符串结束符。这里顺便提及,我们可以使用更短一点的[A-Za-z]替换[[:alpha:]],或者如果我们想支持Unicode编码的键的话,可以使用(\pL[\pL\p{Nd}_]*),表示一个Unicode字母后面紧接着0个或者多个Unicode字母、数字或者下划线。因为.+ 表达式不能匹配换行符,所以这个正则表达式能够处理连续包含多个“键:值”的字符串。
得益于贪婪匹配(默认),这个正则表达式能够除掉所有在值之前的空白。但我们必须使用裁剪函数除掉在值后面的空白,因为.+ 表达式的贪婪性意味着在其后跟随\s*将无效。我们也无法使用惰性匹配(例如.+?),因为这样的话只会匹配值的第一个单词,实际情况是值可能包含多个由空白分隔开的单词。
使用regexp.Regexp.FindAllStringSubmatch 函数我们可以获得一个字符串切片的切片(string)或者nil,-1表示尽可能多的匹配(不能重叠)。在我们这个例子里,每一个匹配都会产生包含3个字符串的切片,第一个字符串包含整个匹配,第二个字符串为键,第三个字符串为值。键和值都必须至少有一个字符,因为它们的最小数量是1。
尽管使用Go语言提供的xml.Decoder包来分析XML是最好的方法,但有时候我们只是简单地想得到XML文件里的属性值,格式通常为name="value" 或者name='value' 这样的字符串,这种情况下,用一个简单的正则表达式更加高效。
attrValueRx := regexp.MustCompile(regexp.QuoteMeta(attrName) + '=(?:"([^"]+)"|'([^']+)')')
if indexes := attrValueRx.FindAllStringSubmatchIndex(attribs, -1); indexes != nil {
for _, positions := range indexes {
start, end := positions[2], positions[3]
if start == -1 {
start, end = positions[4], positions[5]
}
fmt.Printf("'%s'\n", attribs[start:end])
}
}
attrValueRx 表达式匹配一个已经被转义了属性名后面紧随着一个等号和一个单双引号括起来的字符串。为"|"线正常工作而添加的一对括号也会捕获匹配的表达式,但因为我们不希望捕获引号,所以我们将这一对括号设置为非捕获状态((?:))。为了展示它是怎么完成的,我们遍历得到匹配的索引而不是实际匹配的字符串,在这个例子里有3对索引,第一对索引是整个匹配的,第二对索引是双引号值的,第三对索引是单引号值的。当然,实际上只有一个值会被匹配,其他两个值都是−1。
和刚才的例子一样,我们这里也是匹配字符串里所有不重叠的匹配,然后得到一个int类型的索引位置(或者为 nil)。对于每一个 int 类型的positions 切片,完整的匹配是切片attribs[positions[0]:positions[1]]。引号包含的字符串是 attribs[positions[2]:positions[3]]或者attribs[positions[4]:positions[5]],这取决于你配置文件里引号的类型,上面这段代码默认为我们的配置文件使用的是双引号,但如果不是的话(如start == -1),那它就读取单引号的位置。
之前我们见过怎么去写一个SimplifyWhitespace函数(参见3.6.1节),下面的代码使用正则表达式和strings.TrimSpace函数来完成同样的功能。
simplifyWhitespaceRx := regexp.MustCompile('[\s\p{Zl}\p{Zp}]+')
text = strings.TrimSpace(simplifyWhitespaceRx.ReplaceAllLiteralString(text, " "))
这个正则表达式对于字符串开头的空白只是做简单的跳过处理,对于结尾处的空白则使用strings.TrimSpace函数来处理,这两部分的组合并没有做太多工作。函数regexp.Regexp.ReplaceAllLiteralString将字符串中所有的匹配都给替换掉(regexp.Regexp.ReplaceAllString和regexp.Regexp.ReplaceAllLiteralString不同的是前者会对$标识的变量进行展开,但后者不会)。所以,现在这种情况是,任何一个或多个的空白字符(ASCII编码的空格和Unicode行以及段落分隔符)都被替换成一个简单的空格。
下面是我们最后一个关于正则表达式的例子,我们来看看如何使用一个函数来执行具体的替换操作。
unaccentedLatin1Rx := regexp.MustCompile(
'[ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖØÙÚÛÜÝàáâãäåæçèéêëìíîïñðòóôõöøùúûüýÿ]+')
unaccented := unaccentedLatin1Rx.ReplaceAllStringFunc(latin1, UnaccentedLatin1)
这个正则表达式简单地匹配一个或者多个重音拉丁字母。只要存在一个匹配,regexp.Regexp.ReplaceAllStringFunc函数都会调用作为第二个参数传入的函数(函数必须是 func (string) string类型的),这个函数接受匹配的字符串,该匹配的字符串将被该函数返回的字符串(可以是一个空字符串)替代。
func UnaccentedLatin1(s string) string {
chars := make(rune, 0, len(s))
for _, char := range s {
switch char {
case 'À', 'Á', 'Â', 'Ã', 'Ä', 'Å':
char = 'A'
case 'Æ':
chars = append(chars, 'A')
char = 'E'
//...
case 'ý', 'ÿ':
char = 'y'
}
chars = append(chars, char)
}
return string(chars)
}
这个函数简单地将所有重音的拉丁字符替换成它们的非重音形式,也会将连字æ (在一些语言里这是一个全字符)替换为 a和e。当然,这个例子有些刻意为之,因为这里为执行转换其实我们只需写成unaccented := UnaccentedLatin1(latin1)。
现在我们完成了对正则表达式例子的介绍。注意在表3-18和表3-19中,每个处理对象为字符串的函数都有一个对应处理对象为bytes上的函数。书中还有一些其他例子也用到了正则表达式(例如1.6节和7.2.4.1节)。
现在我们已将Go语言的strings和相关的包都介绍完了,我们将用一个使用了一些Go语言string函数的例子来结束整章所学的内容,后面照常会有一些练习。
3.7 例子:m3u2pls
这一节我们介绍一个短小精悍的程序,它从命令行输入读取任意后缀名为.m3u的音乐播放列表文件并输出一个等同的.pls播放列表文件。程序里使用了很多strings包里的函数,还有一些这两章接触过的东西,同时还会介绍一些新的东西。
下面是一个.m3u文件解开的内容,中间一大部分用省略号替代了。
#EXTM3U
#EXTINF:315,David Bowie - Space Oddity
Music/David Bowie/Singles 1/01-Space Oddity.ogg
#EXTINF:-1,David Bowie - Changes
Music/David Bowie/Singles 1/02-Changes.ogg
...
#EXTINF:251,David Bowie - Day In Day Out
Music/David Bowie/Singles 2/18-Day In Day Out.ogg
文件的开始内容是一个字符串常量 #EXTM3U。每一首歌用两行来表示。第一行以字符串#EXTINF:开始,紧跟着是歌曲的持续时间(以秒为单位),然后是一个逗号,接着就是歌曲名。如果持续时间是−1的话意味着歌曲的长度是未知的(或者是未知格式)。第二行是保存歌曲的路径。这里我们使用开源且非专利保护的音频压缩格式并采用Ogg封装格式(www.vorbis.com),以及Unix风格的路径分隔符。
下面是一个等同的.pls文件的释放内容,同样使用省略号省略歌曲的大部分。
[playlist]
File1=Music/David Bowie/Singles 1/01-Space Oddity.ogg
Title1=David Bowie - Space Oddity
Length1=315
File2=Music/David Bowie/Singles 1/02-Changes.ogg
Title2=David Bowie - Changes
Length2=-1
...
File33=Music/David Bowie/Singles 2/18-Day In Day Out.ogg
Title33=David Bowie - Day In Day Out
Length33=251
NumberOfEntries=33
Version=2
.pls文件格式相比.m3u格式稍微可读一点,文件以字符串[playlist]开始,每一首歌用3个“键/值”条目分别来表示文件名、标题和持续时间(以秒为单位)。实际上.pls 文件格式相当于是一种特殊的.ini文件(Windows系统的配置文件格式),在ini里每一个键(在一个中括号表示的节里面)必须是唯一的,因此我们用数字来进行区分。最后文件以两行元数据结束。
m3u2pls程序(在文件m3u2pls/m3u2pls.go里)在运行时需要在命令行提供一个后缀名为.m3u的文件,他会将一个对应的.pls文件写到标准输出(即控制台)。我们可以使用重定向将.pls数据输出到一个实际的文件。下面是这个程序用法的一个例子。
$./m3u2pls Bowie-Singles.m3u > Bowie-Singles.pls
这里我们让程序从 Bowie-Singles.m3u 文件读取数据,然后利用控制台的重定向功能将.pls版本格式的数据写到Bowie-Singles.pls文件里(当然,如果你能用其他的方式来转换,那就更好了,正好这也是我们这一节后面的练习所要求的)。
后面我们会介绍差不多整个程序的代码,除了一些import语句。
func main {
if len(os.Args) == 1 || !strings.HasSuffix(os.Args[1], ".m3u") {
fmt.Printf("usage: %s <file.m3u>\n", filepath.Base(os.Args[0]))
os.Exit(1)
}
if rawBytes, err := ioutil.ReadFile(os.Args[1]); err != nil {
log.Fatal(err)
} else {
songs := readM3uPlaylist(string(rawBytes))
writePlsPlaylist(songs)
}
}
main函数首先会检查命令行是否指定了包含.m3u 后缀名的文件。函数 strings.HasSuffix输入两个字符串,如果第一个字符串是以第二个字符串结束的话返回true。如果没有指定.m3u文件的话就打印使用帮助信息并退出程序。函数filepath.Base返回给定路径的基名(例如文件名),还有os.Exit函数会在退出前清理所有的资源,例如,停止所有的goroutine和关闭所有打开的文件,然后将它的参数返回给操作系统。
如果我们从命令行读取到一个.m3u 文件,我们就尝试用 ioutil.ReadFile函数将整个文件的数据读取出来,这个函数返回文件的所有的字节流(用byte 类型保存)和一个error变量。如果读取过程中没发生任何错误的话error的值为nil,否则(例如文件不存在或者不可读),我们用log.Fatal 函数往控制台(实际上是os.Stderr)输出错误信息,然后以退出码1退出整个程序。
如果我们成功读取了一个文件,我们将原始的字节流转换成字符串,这里假定这些字节均表示一个7位的ASCII码或者UTF-8编码的Unicode字符,然后立即将这个字符串作为参数传递给自定义函数readM3uPlaylist,这个函数返回一个Song切片(Song类型),然后我们用函数writePlsPlaylist 将这些歌曲写到标准输出。
type Song struct {
Title string
Filename string
Seconds int
}
这里我们定义了一个Song类型的结构体(关于结构体的说明参见6.4节),方便用来单独保存和文件格式无关的歌曲信息。
func readM3uPlaylist(data string) (songs Song) {
var song Song
for _, line := range strings.Split(data, "\n") {