Strings,Character Encodings,and Modes
在深入讲解常见的各类元字符之前,还需要了解一些重要的问题:作为正则表达式的字符串,字符编码和匹配模式。
这些概念并不复杂,在理论和实践中都是如此。不过,对其中的大多数来说,因为各种实现方式之间存在细小差异,我们很难预先知道它们准确的实际使用方式。下一节涵盖了若干你将面对的常见问题,以及一些复杂的问题。
作为正则表达式的字符串
Strings as Regular Expressions
这个概念并不复杂:对除 Perl、awk、sed 之外的大多数语言来说,正则引擎接收的是以普通字符串形式提供的正则表达式,这些字符串文字类似“^From:(.*)”。对大多数程序员,尤其新入行的程序员来说,有一点难以理解:在构造作为正则表达式的字符串时,他们还需要留意编程语言定义的字符串元字符。
每种语言的字符串文字都规定了自己的元字符,有些语言甚至包含了多种字符串文字,所以不存在普适性的规则,不过背后的概念是一样的。许多语言的字符串文字能够识别转义序列,例如\t、\\和\x2A,在生成字符串对应的数据时,会正确地解释这些记号。与正则表达式相关的最常见的一点就是,在字符串文字中,必须使用两个紧挨在一起的反斜线才能表示正则表达式中的反斜线。例如,为了表示正则表达式中的「\n」,必须在字符串中使用"\\n"。
如果忘了添加反斜线,而只是使用"\n",在大多数语言中,结果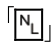 恰好等于「\n」(译注2)。不过,事实上,如果正则表达式是宽松排列格式的/x 类型,
恰好等于「\n」(译注2)。不过,事实上,如果正则表达式是宽松排列格式的/x 类型, 被解释为空,「\n」仍然留在正则表达式中,匹配一个空行。忘记这一点的程序员真该打。下面的表3-4列出了一些包括\t和\x2A(2A是‘*’符号的ASCII编码)的例子。表格中的第二对例子展示了忽略字符串文字元字符会导致的意外结果。
被解释为空,「\n」仍然留在正则表达式中,匹配一个空行。忘记这一点的程序员真该打。下面的表3-4列出了一些包括\t和\x2A(2A是‘*’符号的ASCII编码)的例子。表格中的第二对例子展示了忽略字符串文字元字符会导致的意外结果。
表3-4:关于字符串文字的若干例子

语言不同,字符串文字也不相同,不过有的差异大到连‘\’都不算元字符。例如,VB.NET的字符串文字只有一个元字符,就是双引号。下一节介绍了几种常用语言的字符串文字。无论规定如何,我们在使用时都不要忘记考虑“在编程语言的字符串处理结束之后,正则引擎接收到的是什么?”
Java的字符串
Java 的字符串跟上面提到的很类似,它们由双引号标注,反斜线是元字符。支持常见的字符组合,例如‘\t’(制表符)、‘\n’(换行符)、‘\\’(反斜线本身)。字符串中出现未获支持的反斜线转义序列会出错。
VB.NET的字符串
VB.NET中的字符串同样是由双引号标注的,不过它们与Java的字符串有很大差别。VB.NET的字符串只能识别一个元字符:两个连续的双引号,代表字符串中的双引号。例如"he said""hi""\."的值就是「he said "hi"\.」。
C#的字符串
尽管微软的.NET Framework中所有语言在内部共享同一台正则引擎,但创建正则表达式时它们有各自的规定。我们刚刚看到,Visual Basic的字符串文字非常简单。与之不同,C#语言有两种类型的字符串文字。
C#支持与导论中类似的常见的双引号字符串,只是用 "" 而不是\" 来表示双引号。不过,C#也支持“原生字符串(verbatim strings)”(译注3),其形式为@"…"。原生字符串不能识别反斜线序列,不过其中也有一个特殊的转义序列:一对双引号表示目标字符串中的一个双引号。也就是说,你可以使用"\\t\\x2A"或者@"\t\x2A"来生成「\t\x2A」。因为这种方式很简单,一般都用@"…"的原生字符串来表示正则表达式。
PHP的字符串
PHP也提供了两种类型的字符串,不过无一与C#中的相同。在PHP的双引号字符串中可以使用常见的反斜线序列——例如‘\n’,但也可以像 Perl 那样进行变量插值(☞77),还可以使用特殊的序列{…},把执行花括号内代码的执行结果插入字符串。
PHP 的双引号字符串的独特性在于,你可能倾向于在正则表达式中加入多余的反斜线,不过PHP的另一种特性能够缓解这种现象。对Java和C#的字符串文字来说,字符串中如果出现不能明确识别为特殊字符的反斜线序列会导致错误,而在PHP的双引号字符串中,这种序列会原封不动地从字符串中传过来。PHP的字符串能够识别\t,所以你需要用“\\t”来表示「\t」,不过如果使用“\w”,我们仍然得到「\w」,因为\w不属于PHP的字符串能够识别的转义序列。这个额外的特性,虽然有时候很顺手,也增加了PHP双引号字符串的复杂程度,所以PHP提供了更加简单的单引号字符串。
PHP的单引号字符串类似VB.NET字符串和C#的@"…"字符串,都属于“格式整齐的(unclut-tered)”字符串,不过稍有不同。在PHP的单引号字符串中,\'表示单引号,\\表示反斜线。任何其他字符(包括任何反斜线)都不会被识别为特殊字符,而会被当作字符的值。也就是说,'\t\x2A'创建「\t\x2A」。因为单引号字符串很简单,用它来表示PHP的正则表达式非常方便。
PHP的单引号字符串在第10章有详细讲解(☞445)。
Python的字符串
Python提供了好几种字符串文字。单引号和双引号都可以用来创建字符串,不过与PHP不同的是,这两种方法没有区别。Python也提供了“三重引用(triple-quoted)”的字符串,也就是'''…'''或者"""…""",它们可以包含未转义的换行符。这4 种类型都支持常用的反斜线序列,例如\n,不过和PHP一样,它们也会把不能识别的反斜线序列作为纯字符序列来对待。而在Java和C#中,这些序列会被出错。
与PHP和C#一样,Python也提供了另一种字符串文字,也就是“原字符串(raw string)”。它类似 C#中的@"…",Python 在以上 4 种表示法前添加'r'来表示纯字符串。例如,r"\t\x2A"表示「\t\x2A」。与其他语言不同的是,在 Python 的原字符串中,所有的反斜线都会保留,即使是用来转义双引号的(所以双引号可以保存在字符串中)也是如此:r"he said\"hi\"\."表示「he said\"hi\"\.」在使用正则表达式时,这并不是一个真正的问题,因为Python的正则表达式流派把「\"」识别为「"」,不过如果你喜欢,你可以忽略这些细节,使用这4种纯字符串中的任意一种:r'he said "hi"\.'。
Tcl中的字符串
Tcl与其他语言都不一样,因为它没有真正的字符串变量。相反,命令行被分解成“单词”,Tcl的命令把这些单词作为字符串、变量名和正则表达式,或者其他适合的类型。因为命令行被分解成单词,常见的反斜线序列,例如\n,能够识别和转换,而无法识别的反斜线序列则被忽略。如果愿意,你可以在单词两端添加双引号,不过这并不是必须的,除非中间存在空格。
Tcl同样也有和类似Python的纯字符串类似的原字符串类型,不过Tcl使用花括号{…},而不是r'…'。在花括号之间,除\n之外的所有内容都会原封不动地保存下来,所以{\t\x2A}表示「\t\x2A」。
在花括号之内,你可以按自己的意愿添加多组括号。非嵌套的括号必须用反斜线转义,不过反斜线会保留在字符串之中。
Perl的正则表达式文字
至今为止,我们曾看到过的Perl的例子中,正则表达式都是以文字方式提供的(“正则表达式文字(regular expression literals)”)。不过,我们也可以用字符串变量提交正则表达式,例如:
$str=~m/(\w+)/;
也可以这样:

或者是这样
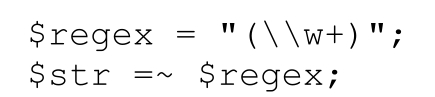
(不过,使用字符串可能会大大降低效率,☞242,348)。
对于以文字方式提交的正则表达式,Perl会提供一些额外的特性,包括:
●变量插值(把变量的值写入正则表达式)。
●通过「\Q…\E」(☞113)支持文字文本。
●能够(optional)支持\N{name}结构,这样就能通过正式的Unicode名来指定字符。例
如,「\N{INVERTED EXCLAMATION MARK}Hola!」能够匹配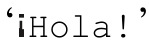 。
。
在Perl中,正则表达式文字会作为特殊的字符串进行解析。实际上,这些特性在Perl双引号字符串中也有提供。必须说明的一点是,这些特性不是由正则引擎提供的。因为 Perl 中使用的绝大多数正则表达式都是作为正则表达式文本的,许多人认为「\Q…\E」属于 Perl 的正则表达式语言,不过如果你用正则表达式从一个配置文件(或者命令行)读入数据,知道哪些特性是由语言的哪些部分提供的就很重要了。
更多细节,请参考第7章第288页。
字符编码
Character-Encoding Issues
字符编码是一种写明的共识,它规定不同数值的字节应该如何解释。在 ASCII 编码中,值为十进制110的字节代表字符‘n’,不过在EBCDIC编码中代表‘>’。为什么会这样?因为这是由不同的人规定的,没有明确的标准判断各种编码的优劣。字节的值是一样的,不一样的是解释。
ASCII只定义了单个字节能够代表的所有数值的一半,ISO-8859-1编码(通常称为“Latin-1编码”)填补了下面的空间,其中增加了读音字符(accented character)和特殊符号,因而能够被更多的语言所使用。对这种编码来说,值为十进制数 234 的字节被解释为e^,而在ASCII中没有定义。
对我们来说,重要的问题在于:如果我们期望使用某种特定编码的数据,程序是否会这样做?例如,如果我们使用Latin-1编码中值分别为234、116、101和115的4个字节(表示法语单词“êtes”),我们期望使用正则表达式「^\w+$」或者「^\b」来匹配。如果程序中的\w或者\b能够支持Latin-1字符,就可以正常工作,否则不行。
编码的支持程度
编码有许多种,当你需要关注一种具体的编码时,你需要考虑的重要问题包括:
●程序能够识别这种编码吗?
●程序如何决定采用哪种编码来处理这些数据?
●正则表达式对这种编码的支持程度如何?
编码的支持程度包括若干重要的问题:
● 是否能够支持多字节字符?点号和[^x]之类的表达式是匹配单个字符,还是单个字节?
●\w、\d、\s、\b之类的元字符,是否能识别编码中的所有字符?例如,虽然ê也是一个字符,\w和\b能处理吗?
●程序是否会扩展对字符组的解释?[a-z]能否匹配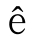 ?
?
●不区分大小写的匹配是否能对所有字符有效?例如,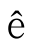 和
和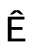 是否一样?
是否一样?
有时候事情不像看起来那么简单。例如,java.util.regex包的\b能够正确识别Unicode中所有与单词相关的字符,\w则不能(它只能匹配ASCII中的字符)。我们会在本章的其他部分看到更多的例子。
Unicode
Unicode
Unicode究竟是什么,似乎存在许多误解。从最基本的意义上说,Unicode是一组字符设定,或者是从数字和字符之间的逻辑映射的概念编码。例如,韩语字符 对应数字 49,333。这个数值,称为一个“代码点(code point)”,通常用十六进制来表示,以“U+”开头。49,333换算成十六进制是C0B5,所以
对应数字 49,333。这个数值,称为一个“代码点(code point)”,通常用十六进制来表示,以“U+”开头。49,333换算成十六进制是C0B5,所以 的代码就是U+C0B5。针对许多字符,Unicode还定义了一组属性,例如3是一个数字,而
的代码就是U+C0B5。针对许多字符,Unicode还定义了一组属性,例如3是一个数字,而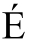 是与
是与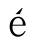 对应的大写字母。
对应的大写字母。
目前,我们还没有谈到这些数值在计算机上是如何编码为数据的。这样的编码方式有许多,包括UCS-2编码(所有的字符都占用两个字节),UCS-4编码(所有字符占用4个字节),UTF-16(大部分字符都占用两个字节,有一些字符占用4个字节),以及UTF-8编码(用1到6个字节来编码字符)。具体的程序内部到底使用哪种编码通常不需要用户来关心。用户只需要关心如何将外部数据(例如从文件读入的数据)从已知的编码(ASCII、Latin-1、UTF-8等)转换给具体的程序。支持Unicode的程序通常提供了多种编码和解码程序来进行这些转换。
支持Unicode的程序中的正则表达式通常支持\unum元序列,用来匹配一个具体的Unicode字符(☞117)。这个数值通常是一个4位的十六进制数,所以\uC0B5表示 。一定要弄清楚的是,\uC0B5的意思是“匹配编号为U+C0B5的Unicode字符”,而没有说具体需要比较哪些字节,因为具体的字节是由代表这个Unicode代码点的编码方式在内部决定的。如果程序内部使用的是UTF-8编码,这个字符就用3个字节表示。不过使用支持Unicode程序的用户,并不需要关心这个(也有时候需要,例如使用PHP的preg套件和模式修饰符u☞447)。
。一定要弄清楚的是,\uC0B5的意思是“匹配编号为U+C0B5的Unicode字符”,而没有说具体需要比较哪些字节,因为具体的字节是由代表这个Unicode代码点的编码方式在内部决定的。如果程序内部使用的是UTF-8编码,这个字符就用3个字节表示。不过使用支持Unicode程序的用户,并不需要关心这个(也有时候需要,例如使用PHP的preg套件和模式修饰符u☞447)。
还有一些你或许需要知道的相关知识……
字符,还是组合字符序列
一般人眼里的“字符”(character)并不都会被 Unicode 或者支持 Unicode 的程序(或者正则引擎)看作一个字符。例如,有人或许认为 à是一个字符,但是在 Unicode 中,它可能由两个代码点构成,U+0061(a)和钝重音(grave accent)U+0300 (')。Unicode提供了许多组合字符(combining character),用来修饰(结合)一个基本字符。这会给正则引擎带来些麻烦,例如,点号是应该匹配单个代码点呢,还是整个U+0061和U+0300?
在实践中,许多程序似乎把“字符”和“代码点”视为等价,也就是说,点号可以匹配单个的代码点,无论是基本字符还是组合字符。所以,à(U+0061加上U+0300)能够由「^..$」匹配,而不是「^.$」。
Perl和PCRE(以及PHP的preg套件)支持\X元序列,这样点号(“匹配单个字符”)就能够匹配一个结合了组合字符的基本字符。详见第120页。
在支持Unicode的编辑器中输入正则表达式时,一定要记住组合字符的概念。如果一个带音调的字符,例如 Å,被正则表达式当作‘A’和‘。’,很可能无法匹配字符串中单个代码点表示的 Å(下一节讨论单代码点的情况)。同样,对正则引擎来说它是两个不同的字符,所以「[…Å…]」在字符组中添加了两个字符,等于「[…A。…]」 。
同样,如果两个代码点的字符——例如Å——后面跟有一个量词,量词作用的其实是第二个代码点,也就是「A°+」。
用多个代码点表示同一个字符
从理论上说,Unicode应该是代码点和字符之间的一一映射(译注4),不过在许多情况下,一个字符可能有多种表现方式。前一节中我们看到à可以表示为U+0061加上U+0300。不过,它也可以用单个代码点U+00E0。为什么会出现这种情况?是为了保证Unicode和Latin-1之间转换的简易性。如果我们有需要转换为Unicode的Latin-1文本,à可能被转换为U+00E0。不过,也可以转换为U+0061和U+0300的组合。通常,这种转换是自动的,用户无法干预,不过Sun的java.util.regex包提供了一种特殊的匹配符,CANON_EQ,保证能够匹配“在规则中等价(canonically equivalent)”的字符,无论它们在 Unicode 中使用什么存储方式(☞368)。
与此相关的问题是,不同的字符可能无法从外观上区分,如果需要检查生成的文本,这会带来混乱。例如,罗马字母Ⅰ(U+0049)可能与I,也就是希腊字母Iota(U+0399)混淆。这个字符添加希腊语冒号之后得到Ï或者Ï,编码也增加到4种(U+00CF;U+03AA;U+0049 U+0308;U+0399 U+0308)。也就是说,如果需要匹配Ï,你可能需要手动指定这4种可能。类似的例子还有许多。
还有许多单个字符看起来不只一个字符。例如 Unicode 定义了一个叫做“SQUARE HZ”(U+3390)的字符。这很像两个普通字符Hz的组合(U+0048 U+007A)。
尽管Hz之类的特殊字符的用途在目前非常有限,但在将来,它们的应用肯定会增加文本处理程序的复杂性,所以在处理Unicode时不应忘记这些问题。用户可能会期望,处理这样的数据时,必须能够处理正常空格(U+0020)和非换行空格(no-break spaces)(U+00A0),或许还需要包括Unicode中其他的成打的空白字符之中的任意一个。
Unicode 3.1+和U+FFFF之后的代码点
Unicode Version 3.1诞生于2001年中期,增加了U+FFFF之后的代码点(之前版本的Unicode也支持这些代码点,但是在Version 3.1以前,它们都是没有定义的)。例如,代表音乐谱号C(Clef)的字符对应代码点 U+1D121。之前那些仅支持低于 U+FFFF字符的程序无法处理这种情况。大多数程序的\unum只能支持最多4位十六进制数值。
能够处理这类新字符的程序通常提供了\x{num}序列,num可以为任意多位数字(这是为了增强只支持4位数字的\unum表示法)。你可以使用\x{1D121}来匹配这类“谱号C”之类的字符。
Unicode中的行终止符
Unicode定义了多个用于表示行终止符的字符(以及一个双字符序列),详见表3-5。
表3-5:Unicode行终止符
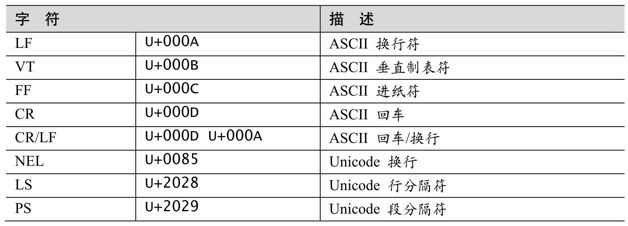
如果行终止符获得了完全的支持,它会影响文本行从文件(在脚本语言中,还包括程序读取的文件)读入的方式。在使用正则表达式时,它们影响点号(☞111),以及「^」、「$」和「\Z」的匹配(☞112)。
正则模式和匹配模式
Regex Modes and Match Modes
许多正则引擎都支持多种不同的模式,它们规定了正则表达式应该如何解释和应用。我们已经看过Perl的/x修饰符(容许自由空格和注释的正则模式☞72)和/i修饰符(进行不区分大小写匹配的模式☞47)。
在许多流派中,模式可以完全作用于整个表达式,也可以单独应用于某个子表达式。整体应用是通过修饰符或者选项(options)来决定的,例如 Perl 的/i,PHP 的模式修饰符 i (☞446),和java.util.regex的Pattern.CASE_INSENSITIVE标志(☞99)。如果支持,应用到目标字符串中部分文本的模式是通过一个正则结构来实现的,例如用「(?i)」来开启不区分大小写的匹配,「(?-i)」来停用该匹配。有的流派也支持「(?i:…)」和「(?-i:…)」来启用或者停用对括号内的子表达式进行不区分大小写匹配的功能。
本章后面部分会介绍(☞135)如何在正则表达式中设置这些模式。在本节,我们只看看大多数系统提供的常见模式。
不区分大小写的匹配模式
此模式很常见,它在匹配过程中会忽略字母的大小写,所以「b」可以匹配‘b’和‘B’。此功能也必须依赖于正确的字符编码支持,所以之前我们提到的注意事项对它都适用。
在历史上,不区分大小写的匹配支持一直不太令人满意,被 bug 困扰,好在如今大部分已经修正了。不过,Ruby不区分大小写的匹配仍然不能处理八进制和十六进制的转义字符。不区分大小写的匹配存在特殊的与Unicode相关的问题(在Unicode中称为“粗略匹配(loose matching)”)。简单地说,就是并非所有的ASCII字母和数字字符都存在大小写形式,而某些字符在作为单词首字母时会有单独的标题格式(title case)。有时候在大写和小写之间并没有明显的一对一映射。常见的例子是希腊字母西格马Σ,它有两个小写形式ζ和σ,在不区分大小写的模式中,这三者应该是等价的。根据我的测试,只有Perl和Java的java.util.regex能够正确处理它们。
另一个问题是,有时候单个字符会对应到一组字符。常见的例子是大写的 ß 是两个字符的组合“SS”。这种情况只有Perl能够正确处理。
Unicode还带来了一些问题。例如单字符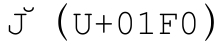 没有对应的大写形式的单字符。相反,
没有对应的大写形式的单字符。相反,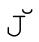 需要使用组合字符(☞107),U+004A和U+030C。而
需要使用组合字符(☞107),U+004A和U+030C。而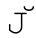 和
和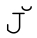 应该在不区分大小写的模式中是等价的。类似的还有一对三的例子。幸好,这些都不是常用字符。
应该在不区分大小写的模式中是等价的。类似的还有一对三的例子。幸好,这些都不是常用字符。
宽松排列和注释模式
此模式会忽略字符组外部的所有空白字符。字符组内部的空白字符仍然有效(java.util.regex是例外),#符号和换行符之间的内容视为注释。我们已经见过Perl(☞72)、Java(☞98)和VB.NET(☞99)中相应的例子。
不过,在java.util.regex中,字符组之外的所有空白字符并非都会被忽略,而是作为一个“无意义元字符(do-noting metacharacter)”。在理解「\12·3」时,这种区分很重要,因为它表示「3」接在「\12」之后,而不是有些人以为的「\123」。
当然,“空白字符”的定义取决于所采用的字符编码的定义,以及此编码对空白字符的支持程度。大多数程序只能识别ASCII的空白字符。
点号通配模式(dot-match-all match mode,也叫“单行模式”)
通常,点号是不能匹配换行符的。最初的Unix正则表达式工具是逐行处理的,直到sed和lex出现之后,才提出匹配换行符的要求。那时候,人们常用「.*」来匹配“本行中的其他内容(the rest of the line)”,为了保证一致,新的语法不能修改「.*」的定义(注9)。所以,能够处理多行文本的工具(例如文本编辑器)通常不容许点号匹配换行符。
对现代编程语言来说,点号能够匹配换行符的模式和不能匹配的模式同样有用。这两种模式哪个更方便,取决于具体的情况。许多程序提供了两种方法供正则表达式选择。
这种常规标准也有少数例外的情况。支持 Unicode 的系统,例如在 Sun 的正则表达式包,点号能够匹配未使用此模式时点号不能匹配的所有单字符Unicode行终止符(☞109)。在Tcl的普通模式中,点号能够匹配任何字符,但是在其特殊的“区分换行(newline-sensitive)”和“部分区分换行(partial newline-sensitive)”的匹配模式下,点号和排除型字符组都不能匹配换行符。
不幸的命名
/s修饰符对应的匹配模式第一次出现在Perl时,被称为“单行文本模式(single-line mode)”。这个不幸的命名一直是混乱的起源,因为与下一节讨论的“多行文本模式(multiline mode)”比较起来,它似乎与「^」和「$」没有关系。其实“单行文本模式”指的是,点号不受限制,可以匹配任何字符。
增强的行锚点模式(Enhanced line-anchor match mode,也叫“多行文本模式”)
增强的行锚点模式会影响到行锚点「^」和「$」的匹配。通常情况下,锚点「^」不能匹配字符串内部的换行符,而只能匹配目标字符串的起始位置。但是在此增强模式下,它能够匹配字符串中内嵌的文本行的开头位置。前一章出现了这样的例子(☞69),当时我们用Perl开发把文本内容转换为超文本内容程序。其中,所有的文本保存在一个字符串中,所以我们可以通过查找-替换功能用 s/^$/<p>/mg 来把“…tags. It’s…”转换为“…tags.
It’s…”转换为“…tags. <p>
<p> It’s…”。该替换把空“行”替换为段落tag。
It’s…”。该替换把空“行”替换为段落tag。
「$」也是这样,尽管「$」在正常情况下的匹配的基本规则比较难理解(☞129)。不过,就本节来说,我们只需要记住,「$」可以匹配字符串内部的换行符,就足够了。
支持此模式的程序通常还提供了「\A」和「\Z」,它们的作用与普通的「^」和「$」一样,只是在此模式下它们的意义不会发生变化。也就是说「\A」和「\Z」永远不会匹配字符串内部的换行符。有些实现方式中,「$」和「\Z」能够匹配字符串内部的换行符,不过它们通常会提供「\z」,唯一匹配整个字符串的结尾位置。详见129页。
对点号来说,常用标准有一些例外。在GNU Emacs之类的文本编辑器中,行锚点通常能够匹配字符串中的换行符,因为在编辑器中这样非常有意义。另一方面,lex的「$」只能匹配换行符之前的位置(其中「^」的意义与常见的一样)。
此模式下,在Sun的java.util.regex之类支持Unicode的系统中,行锚点能够匹配任何一种行终止符(☞109)。Ruby 的行锚点在正常情况下能够匹配字符串中的换行符,Python的「\Z」类似「\z」,而不是普通的「$」。
长期以来,这种模式被称为“多行模式(multiline mode)”。尽管它与“单行模式”没有什么关系,但看名字总容易觉得二者有关联。后者修改的是点号的匹配规则,前者修改的是「^」和「$」的匹配规则。另一方面,它们从不同的思路处理换行符。第一个修改了点号处理换行符的方式,从“需要特殊处理”变为“不需要特殊处理”;第二个的做法则相反,改变了「^」和「$」匹配换行符的方式,从“不需要特殊处理”变为“需要特殊处理”(注10)。
文字文本模式
“文字文本(literal text)”模式几乎不能识别任何正则表达式元字符。例如,文字文本模式下「[a-z]*」匹配字符串“[a-z]*”。完整的文字搜索(literal search)等于简单的字符串搜索(“搜索这个字符串”,而不是“搜索这个正则表达式”),支持正则表达式的程序通常也提供了普通的字符串搜索功能。正则表达式的文字文本模式之所以更有趣,是因为它可以只作用于正则表达式的一部分,举例来说,PCRE(因此也包括PHP)的正则表达式和Perl的正则表达式文本提供了特殊的序列\Q…\E,其中内容的元字符全部被忽略(当然,不包括\E)。