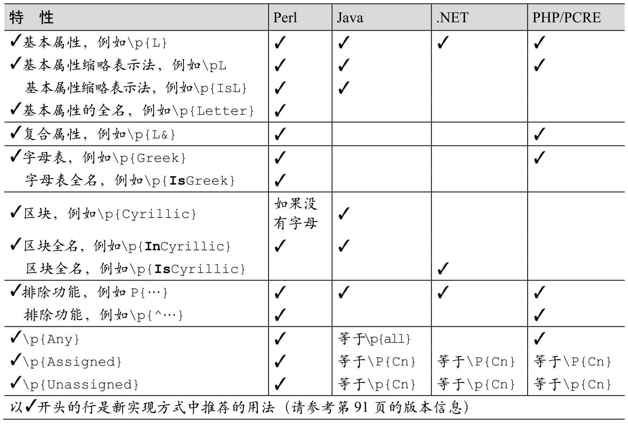
Common Metacharacters and Features
本章的其他部分——剩下大约30页的内容简要介绍下一页列出的常见正则表达式元字符和概念。这里的介绍并不是全面彻底的,不过也没有任何一种正则工具涉及其中的所有内容。
从某种意义上说,这一节只是前两章内容的总结,但同时也是为本章介绍更全面更深刻的知识做准备。读者第一次接触时,只需略读本章就可以继续阅读下面各章,以后在需要的时候可以随时回过头来查阅细节。
有的工具添加了大量的新功能,也可能毫无根据地改变某些通用表示法,以满足它们的特殊要求。尽管我有时会提到这些特殊的工具,但不会花太多的笔墨在工具的细节问题上。相反,在这一节我只希望介绍常见的元字符及其作用,以及与此相关的一些问题。我希望读者能够参考自己擅长的工具提供的使用手册。
本节介绍的结构
字符表示法
☞115字符缩略表示法:\n、\t、\a、\b、\e、\f、\r、\v、…
☞116八进制转义:\num
☞117十六进制/Unicode转义:\xnum、\x{num}、\unum、\Unum,…
☞117控制字符:\cchar
字符组及相关结构
☞118 普通字符组:[a-z]和[^a-z]
☞119 几乎能匹配任何字符的元字符:点号
☞120 单个字节:\C
☞120 Unicode组合字符序列:\X
☞120 字符组缩略表示法:\w、\d、\s、\W、\D、\S
☞121 Unicode属性、区块和分类:\p{Prop}、\P{Prop}
☞125 字符组运算符:[[a-z]&&[^aeiou]]
☞127 POSIX“字符组”方括号表示法:[[:alpha:]]
☞128 POSIX“collating序列”方括号表示法:[[.span-ll.]]
☞128 POSIX“字符等价类”方括号表示法:[[=n=]]
☞128 Emacs 语法类
锚点及其他“零长度断言”
☞129 行/字符串起点:^、\A
☞129 行/字符串终点:$、\Z、\z
☞130 本次匹配的开始位置(或者上次匹配的结束位置):\G
☞133 单词分界符:\b、\B、\<、\>,….
☞133 顺序环视 (?=…)、(?!…);逆序环视 (?<=…)、(?<!…)
注释和模式修饰词
☞135 模式修饰词:(?modifier),例如(?i)或(?-i)
☞135 模式作用范围:(?modifier:…),例如(?i:…)
☞136 注释:(?#…) 和#…
☞136 文字文本范围:\Q…\E
分组、捕获、条件判断和控制
☞137 捕获/分组括号:(…)、\1、\2,…
☞137 仅用于分组的括号:(?:…)
☞138 命名捕获:(?<Name>…)
☞139 固化分组:(?>…)
☞139 多选结构:…|…|…
☞140 条件判断:(?if then|else)
☞141 匹配优先量词:*、+、?、{num,num}
☞141 忽略优先量词:*?、+?、??、{num,num}?
☞142 占有优先量词:*+、++、?+、{num,num}+
字符表示法
Character Representations
这一组元字符能够以清晰美观的方式匹配其他方式中很难描述的某些字符。
字符缩略表示法
许多工具软件提供了表示某些控制字符的元字符,其中有一些在所有机器上都是不变的,但也有些是很难输入或观察的:
\a 警报(例如,在“打印”时扬声器发声)。通常对应ASCII中的<BEL>字符,八进
制编码007。
\b 退格 通常对应ASCII中的<BS>字符,八进制编码010。(在许多流派中,「\b」只有在字符组内部才表示这样的意义,否则代表单词分界符☞133)。
\e Escape字符 通常对应ASCII中的<ESC>字符,八进制编码033。
\f 进纸符 通常对应ASCII中的<FF>字符,八进制编码014。
\n 换行符 出现在几乎所有平台(包括Unix和DOS/Windows)上,通常对应ASCII的<LF>字符,八进制编码 012。在MacOS 中通常对应ASCII的<CR>字符,十进制编码 015。在 Java 或任意一种.NET 语言中,不论采用什么平台,都对应ASCII<LF>字符。
\r 回车 通常对应ASCII的<CR>字符。在MacOS中,对应到ASCII的<LF>字符。在
Java或任意一种.NET语言中,不论采用什么平台,都对应到ASCII的<CR>字符。\t 水平制表符 对应ASCII的<HT>字符,八进制编码011。
\v 垂直制表符 对应ASCII的<VT>字符,八进制编码013。
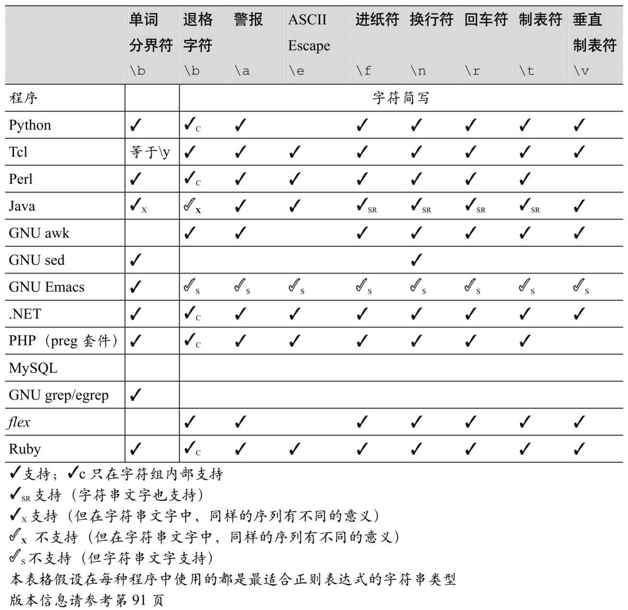
表3-6列出了几种常用的工具及它们提供的某些字符缩略表示法。之前已经说过,某些语言在支持字符串文字时已经提供了同样的字符缩略表示法。请不要忘记那一节(☞101),因为它涉及某些相关的陷阱。
会根据机器变化的字符?
从该表可以看出,在许多工具中,\n和\r的意义是随操作系统的变化而变化的(注11),所以在使用时应格外小心。如果你需要在程序可能运行的所有平台上都能通用的“换行符”,请使用\n。如果需要一个对应特殊值的字符,例如HTTP协议定义的分隔符,请使用\012之类标准规定的字符(\012是ASCII中的换行符的八进制编码)。如果你希望匹配DOS中的行终结字符,请使用「\015\012」。如果希望同时匹配 DOS 或 Unix 的换行字符,请使用「\015?\012」(它们通常是匹配行尾的字符,如果希望匹配行的开头位置或结尾位置,请使用行锚点☞129)。
表3-6:几款工具软件及它们提供的元字符简写法
八进制转义\num
支持八进制(以8为基数)转义的实现方式通常容许以2到3位数字表示该值所代表的字节或字符。例如,「\015\012」表示ASCII 的CR/LF 序列。八进制转义可以很方便地在正则表达式中插入平时难以输入的字符。例如,在Perl中,我们可以使用「\e」作为ASCII的转义字符,但是在awk中不行。
因为awk支持八进制转义,我们可以直接使用ASCII代码来表示escape字符:「\033」。
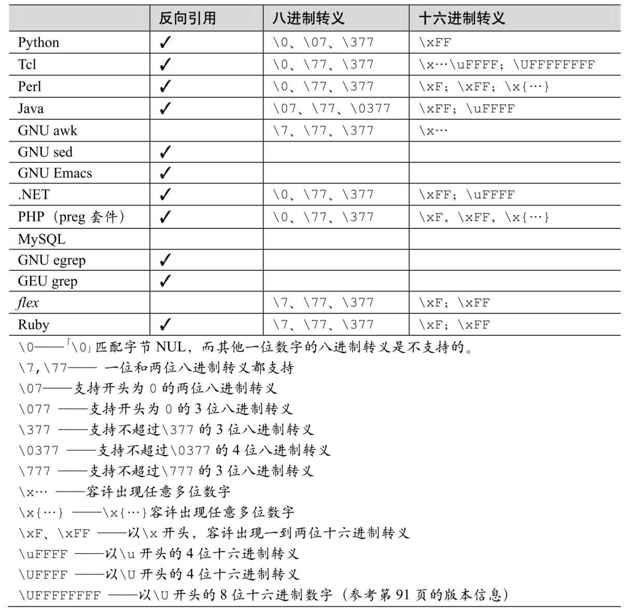
下一页的表3-7列出了部分工具支持的八进制转义。
有些实现方式很特殊,在其中「\0」能够匹配字节 NUL。有的支持一位数字的八进制转义,不过如果同时支持「\1」之类的反向引用,就不会提供这种功能。如果两者发生冲突,则反向引用一般要优先于八进制转义。有的容许出现 4 位数字的八进制转义,不过通常会要求任何八进制转义都必须以0开头(例如java.util.regex)。
你可能会想,如果遇到\565 之类超出范围的转义数值(8 位的八进制数值范围从\000 到\377)会发生什么。大约一半的实现方式将其视为多余一个字节的值(如果支持Unicode,则可能是Unicode字符),而其他实现方式会将其截断为一个字节。一般来说,最好的办法还是不要使用超过\377的八进制转义。
十六进制及Unicode转义:\xnum、\x{num}、\unum、\Unum
除了八进制转义之外,许多工具软件也支持十六进制转义(以16为基数),以\x、\u或者是\U开头。如果支持\x,则「\x0D\x0A」匹配CR/LF序列。表3-7列出了部分工具软件支持的十六进制转义。
除了知道采用的是哪种转义之外,你可能还希望知道各种转义能识别多少位的转义值,以及是否能够(或者必须)在数字两端使用花括号。对此,表3-7同样作了说明。
控制字符:\cchar
许多流派中可以用「\cchar」来匹配编码值小于32的控制字符(有些能支持更大的值)。例如,「\cH」匹配一个Control-H字符,也就是ASCII中的退格符,而「\cJ」匹配ASCII的换行符(通常使用「\n」,不过有时也使用「\r」,这取决于具体的平台☞115)。
支持此结构的系统在细节上有所不同。与这个例子一样,通常使用大写英文字母是不会有问题的。在大多数实现方式中,你也可以使用小写字母,不过也有的软件不支持它们,例如Sun的Java regex Package。流派不同,对字母和数字之外的字符的处理是非常不同的,所以我推荐在使用\c时只使用大写字母。
相关提示:GNU Emacs支持此功能,但它使用的元序列非常奇特「?\^char」(例如:「?\^H」 匹配ASCII编码中的退格字符)。
表3-7:部分工具软件及它们的正则表达式支持的八进制和十六进制转义
字符组及相关结构
Character Classes and Class-Like Constructs
现在许多流派中,都有多种方法在正则表达式的某个位置指定一组字符,不过最通行的方法还是使用普通字符组。
普通字符组:[a-z]和[^a-z]
我们已经介绍过字符组的基本概念,不过我还是要强调,元字符的规定在字符组内外是有差别的。例如,在字符组内部「*」永远都不是元字符,而「-」通常都是元字符。有些元序列,例如「\b」,在字符组内外的意义是不一样的(☞116)。
在大多数系统中,字符组内部的顺序环视是无关紧要的,而且使用范围表示法而不是列出范围内的所有字符并不会影响执行速度(例如,[0-9]与[908176354]是一样的)。相反,某些实现方式不能完全优化字符组(比如Sun提供的Java regex package),所以最好是使用范围表示法,因为如果有差别,这种表示法的速度会快一些。
字符组通常表示肯定断言(positive assertion)。也就是说,它们必须匹配一个字符。排除型字符组仍然需要匹配一个字符,只是它没有在字符组中列出而已。把排除型字符组理解为“匹配未列出字符的字符组”或许更容易一些(请务必阅读下一节中关于点号和排除型字符组的警告)。「[^LMNOP]」通常等价于「[\x00-kQ-\xFF]」,即使在规定严格的8位系统中,这仍然成立,但是在Unicode之类字符的值可能大于255(\xFF)的系统中,排除型字符组「[^LMNOP]」可能包括成千上万个字符——只是不包含L、M、N、O和P。
请务必理解使用范围表示法的基本字符组。例如,用「[a-Z]」匹配字母就很可能存在遗漏,而且在任何情况下显然都不是“所有字母”。而[a-zA-Z]则能匹配所有字母,至少对于ASCII编码来说是这样的(请参考“Unicode 属性”中的\p{L}☞121)。当然,在处理二进制数据时,字符组中的‘\x80-\xFF’范围表示法完全适用。
几乎能匹配任何字符的元字符:点号
在某些工具软件中,点号用来缩略表示可以匹配任何字符的字符组,而在其他工具中,点号能匹配除了换行符之外的任何字符。这差别很细微,但如果所用的工具能够处理包含多个逻辑行的目标文本(或者是文本编辑器中的多个逻辑行的文本),它就非常重要。关于点号,需要注意的有:
●在Sun的Java regex package之类的支持Unicode的系统中,点号不能匹配Unicode的行终结符(☞109)。
●匹配模式(☞111)会改变点号的匹配规则。
●POSIX规定,点号不能匹配NUL(值为0的字符),尽管大多数脚本语言容许文本中出现NULL(而且可以用点号来匹配)。
点号,还是排除型字符组
如果所使用的工具能够在多行文本中进行搜索,请务必注意点号,它在通常情况下不能匹配换行符,而排除型字符组「[^"]」通常都可以。如果把「".*"」替换为「"[^"]*"」,可能会带来意想不到的效果。点号的匹配规定一般可以通过变换匹配模式来更改——请参考第 111页的“点号通配模式”。
单个字节
Perl 和 PCRE(也包括 PHP)支持用\C匹配单个字节,即使该字节位于某个多字节编码的字符之中(相反,其他功能都是基于字符的)。这个功能很危险,如果运用不当,可能会导致内部错误,所以只有在清楚自己所作所为的情况下,才能使用它。我找不到恰当运用的例子,所以下文不再提及。
Unicode组合字符序列:\X
Perl 和PHP 支持用\X缩略表示「\P{M}\p{M}*」,它可以视为点号的扩展。它匹配一个基本字符(除\p{M}之外的任何字符),之后可能有任意数目的组合字符(除\p{M}之外)。
之前已经介绍过(☞107),Unicode体系包括基本字符和组合字符,二者可以合成“看起来”的单个字符,例如à(‘a’的编码是U+0061,读音符号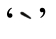 的编码是U+0300)。有的字符可能包含不止一个的组合字符。例如,
的编码是U+0300)。有的字符可能包含不止一个的组合字符。例如,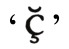 就包括‘c’,然后是变音符
就包括‘c’,然后是变音符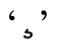 ,最后是短音符
,最后是短音符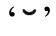 (Unicode编码分别是U+0063、U+0327和U+0306)。
(Unicode编码分别是U+0063、U+0327和U+0306)。
如果希望匹配“francais”或者“franÇais”,仅仅使用「fran.ais」或者「fran[cÇ]ais」还不够保险,因为此方法假设‘Ç’用单个Unicode代码点U+00C7表示,而不是‘c’加上变音符(U+0063加上U+0327)。如果需要专门处理,可以使用「fran(c,?|Ç)ais」,不过在这里,用「fran\Xais」取代「fran.ais」是个好办法。
除了能够匹配结尾的组合字符之外,\X与点号还有两个差别。其一是,\X始终能匹配换行符和其他Unicode行终结符(☞109),而点号只有在点号通配模式(☞111),或者工具软件提供的其他匹配模式下才可以。另一点是,点号通配模式下的点号无论什么情况下都能匹配任何字符,而「\X」不能匹配以组合字符开头的字符。
字符组简记法:\w、\d、\s、\W、\D、\S
通常支持的简记法有:
\d 数字 等价于「[0-9]」,如果工具软件支持Unicode,能匹配所有的Unicode数字。
\D 非数字字符 等价于「[^\d]」。
\w 单词中的字符 一般等价于「[a-zA-Z0-9_]」。某些工具软件中「\w」不能匹配下画线,而另一些工具软件的「\w」则能支持当前locale(☞87)中的所有数字和字符。如果支持Unicode,「\w」通常能表示所有数字和字符,而在java.util.regex和PCRE (也包括PHP)中,「\w」严格等价于「[a-zA-Z0-9_]」。
\W 非单词字符 等价于「[^\w]」。
\s 空白字符 在支持ASCII的系统中,它通常等价于「[·\f\n\r\t\v]」。在支持Unicode的系统中,有时包含 Unicode 的“换行”控制字符 U+0085,有时包含“空白(whitespace)”属性\p{Z}(参见下一节的介绍)。
\S 非空白字符 等价于「[^\s]」。
87 页已经介绍过,POSIX 的 locale 设定会影响这些简记符号的含义(尤其是\w)。支持Unicode的程序中,\w通常能匹配更多的字符,例如\p{L}(下一节介绍)和下画线。
Unicode属性,字母表和区块:\p{Prop}、\P{Prop}
表面上看,Unicode只是一套字符映射规则(☞106),其实Unicode标准远远不止这些。它还定义了每个字符的性质(qualities),例如“这个字符是小写字母”,“这个字符是从右往左看的”,“这个字符是标记字符(mark),它必须与其他字符一同使用”等等。
不同的正则表达式系统对这些属性的支持也不相同,但是许多支持Unicode的程序能够通过「\p{quality}」和「\P{quality}」支持其中的一部分。比如「\p{L}」就是个简单的例子,这里‘L’的意思是“字母(letter)”(相对于数字number、标点punctuation和口音accent,之类)。‘L’是一种普通属性(general property,也称为分类category)。我们马上会了解到,可以用「\p{…}」和「\P{…}」来测试其他“属性”,当然支持最广泛的还是常见的属性。
常见的属性请见表3-8。每个字符(实际上是代码点,包括那些目前没有对应字符的代码点)都可以用一个普通属性匹配。普通属性的名字是单个字符(例如‘L’表示字母letter,‘S’表示符号 symbol,等等),但是某些系统中可以用多个字母表述属性(例如‘Letter’和‘Symbol’),比如Perl就支持这样。
在某些系统中,单字母属性名可能不需要花括号(例如,用\pL 而不是\p{L})。有的系统可能要求(或者是容许)使用‘In’或‘Is’前缀(例如\p{IsL})。讲解扩展属性(additional qualities)时,我们会见到要求使用Is/In前缀的例子(注12)。
按照表 3-9,每个用单字符表示的普通属性可以进一步分为多个双字母表示的子属性(sub-property),例如“字母(letter)”又可以分为“小写字母”、“大写字母”、“标题首字母(titlecase letter)”、“修饰符字母”和“其他字母”。每个代码点能且只能属于一种子属性。
表3-8:基本的Unicode属性分类

要补充的是,某些实现方式支持特殊的复合子属性,例如用\p{L&}表示“分大小写的(cased)”字母,也就是说「[\p{Lu}\p{Ll}\p{Lt}]」。
表3-9还给出了某些实现方式支持的属性名的全称(例如,“Lowercase_Letter”,而不是“Ll”)。按照 Unicode 的标准,各种形式都应该能够接受(例如‘LowercaseLetter’、‘LOWERCASE_LETTER’、‘Lowercase·Letter’、‘lowercase-letter’),不过,为了保持一致,我推荐使用表3-9中的形式)。
字母表(Scripts)有的系统能够按照字母表(书写系统 writing system)的名字以「\p{…}」来匹配。例如,用\p{Hebrew}匹配希伯来文独有的字符(但不包含其他书写系统中常见的字符,例如空格和标点)。
某些字母表是基于语言的(例如印度古哈拉地语、泰国语、切罗基语,等等)。有的覆盖了多种语言(例如拉丁文、西里尔文),还有些语言包含多种字母表,例如日语的字符就来自平假名、片假名、汉语和拉丁语。请读者参考自己系统的文档获取完整的信息。
字母表不会包含特定的书写系统中的所有字符,而只包含独属于(或者几乎独属于)此书写系统中的字符。常见的字符,例如空格和标点不属于任何字母表,而是属于通用的IsCommon伪字母表(pseudo-script),用「\p{IsCommon}」匹配。还有一个伪字母表Inherited,它包括从其所属的字母表中基本字符继承而来的组合字符。
表3-9:基本的Unicode子属性
区块(Block)。区块类似(但是比不上)字母表,区块表示Unicode字符映射表中一定范围内的代码点。例如,Tibetan区块表是从U+0F00到U+0FFF的256个代码点。其中的字符,在 Perl 和 java.util.regex 中可以用\p{InTibetan}来匹配,在.NET 中可以用\p{IsTibetan}来匹配(细节见后文)。
区块有许多种,包括对应大多数书写系统的区块(希伯来、泰米尔、基本拉丁语、西里尔文等等),以及特殊的字符组型(货币、箭头、文本框、印刷符号等)。
Tibetan 是一个典型的区块,因为其中的所有字符都是按照西藏文定义的,此区块之外不存在专属于藏语的字符。不过,区块仍然不如字母表,原因如下:
●区块可能包含未赋值的代码点。例如,Tibetan区块中大约有25%的代码点没有分配字符。
●并不是看起来与区块相关的所有字符都在区块内部。例如,在 Currency 区块中就没有通用的货币符号‘¤’,也没有常见的$、¢、£、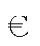 和¥(幸好,这时候我们可以用currency属性\p{Sc})。
和¥(幸好,这时候我们可以用currency属性\p{Sc})。
●区块通常包含不相关的字符。例如¥(表示“元”)属于Latin_1_Supplement区块。
● 属于某个字母表的字符可能同时包含于多个区块。例如,希腊字符同时出现在 Greek和Greek_Extended区块中。
对区块的支持比对字母表的支持更普遍。不过这两者很容易混淆,因为在命名上存在许多重叠(例如,Unicode同时提供了Tibetan字母表和Tibetan区块)。
此外,按照下页的表3-10所示,这些命名本身也没有统一的标准。在Perl和 java.util.regex中,Tibetan区块表示为「\p{InTibetan}」,但是在.NET中又表示为\p{IsTibetan}(更糟糕的是,在Perl中这是Tibetan字母表的另一种表示法)。
其他属性(Other properties/qualities)上面介绍的知识并不是通用的。表3-10详细介绍了它们的适用情况。
要补充的是,Unicode还定义了许多能够通过「\p{…}」结构访问的属性,其中包括字符的书写顺序环视(从左至右还是从右至左,等等)、与字符相关的元音,以及其他属性。有些实现方式还容许用户根据需要临时创建属性。请参考具体的程序提供的文档了解细节。
表3-10:属性/字母表/区块的支持情况
简单的字符组减法:[[a-z]-[aeiou]]
.NET提供的字符组“减法”容许我们在字符组中进行减法运算。例如,「[[a-z]-[aeiou]]」匹配的字符就是「[a-z]」能够匹配字符的减去「[aeiou]」能够匹配的字符,也就是ASCII编码中小写的非元音字母。
另一个例子是「[\p{P}-[\p{Ps}\p{Pe}]]」,它能够匹配\p{P}中除「[\p{Ps}\p{Pe}]」之外的字符,也就是说,它能匹配除了》和(之类成对的符号之外的所有标点符号。
完整的字符组集合运算:[[a-z]&&[^aeiou]]
Sun的Java regex package中的字符组能够进行完整的集合运算(并、减、交)。它的语法有别于前一节中简单的字符组减法(尤其是,在Java中匹配小写非元音字母的字符组[[a-z]&&[^aeiou]])。在详细介绍减法之前,我们先来看两个简单的集合运算:OR和AND。
OR容许用户以字符组方式在字符组中添加字符:[abcxyz]也可以表示为[[abc][xyz]]、[abc[xyz]]或 [[abc]xyz]等等。OR用来把多个集合合并为新的集合。从概念上说,它有点像多种语言提供的“按位或”运算符:‘|’或是‘or’。在字符组中,OR 只不过是一种简记法,尽管包括排除型字符组在某些情况下更方便。
AND对两个集合进行概念上的“与”运算,只保留同时属于两个字符组的字符。它的写法是在两个字符组中添加特殊的字符组元字符&&。例如[\p{InThai}&&\P{Cn}],它通过对\p{InThai}和\P{Cn}进行交运算(只保留同时属于两个集合的字符),匹配Thai区块中所有已经赋值的代码点。\P{…}中的‘P’是大写,匹配不具备此属性的字符,所以\P{Cn}匹配的就是除未赋值的代码点之外的代码点,也就是已经赋值的代码点(要是 Sun 能够识别已赋值属性(Assigned quality),就可以用\p{Assigned}替换\P{Cn})。
请不要混淆OR和AND。它们的含义取决于用户的看法。例如[[this][that]]读作“[this]或者[that]匹配的字符”,其实它的真正意思是“[this]和[that]能够匹配的所有字符”,这只是对同一个问题的两种看法。
相比之下,AND要清楚一些:[\p{InThai}&&\P{Cn}]读作“只匹配在\p{InThai}和\P{Cn}中出现的字符”,尽管它有时候也读作“匹配属于\p{InThai}和\P{Cn}的交集中的字符。”
看法的不同可能会造成混乱:我叫做 OR 和 AND 的运算,某些人可能叫做 AND 和INTERSECTION。
以集合运算符进行字符组的减法\P{Cn}可以写作[^\p{Cn}],所以在匹配“Thai block中已经赋值的字符”时,[\p{InThai}&&\P{Cn}]也可以写作[\p{InThai}&&[^\p{Cn}]]。这样的改变并没有多少意义,只是它有助于说明一个通用的模式:“Thai block中已赋值字符”比“所有 Thai block 中的字符,减去未赋值的字符”更好理解,于是我们知道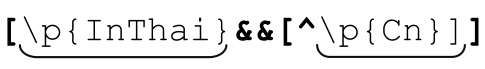 表示“
表示“ 减去
减去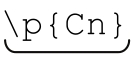 ”。
”。
这样就回到了本节开头「[[a-z]&&[^aeiou]]」的例子,现在我们知道如何进行字符组的减法了。其模式为:「[this&&[^that]]」表示“[this]减去[that]”。我发现用&&和[^…]进行双重否定很难记忆,所以记住模式「[…&&[^…]]」就够了。
通过环视功能模拟字符组的集合运算 如果所使用的程序不支持字符组集合运算,但支持环视功能(☞133),则可以自己模拟集合运算。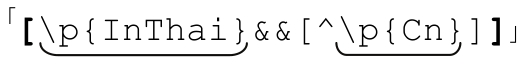 可以用环视功能写成
可以用环视功能写成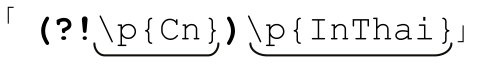 (注13)。尽管它并不如内建的集合运算有效率,环视仍然是非常方便的做法。这个例子可以用4种不同的方式来实现(在.NET中需要以 IsThai替换InThai☞125)。
(注13)。尽管它并不如内建的集合运算有效率,环视仍然是非常方便的做法。这个例子可以用4种不同的方式来实现(在.NET中需要以 IsThai替换InThai☞125)。

POSIX“字符组”方括号表示法
我们通常所说的字符组,在POSIX标准中称为方括号表达式(bracket expression)。POSIX中的术语“字符组”指的是在方括号表达式(注 14)内部使用的一种特殊的功能(special feature),而我们可以认为它们是Unicode的字符属性的原型。
POSIX字符组是POSIX方括号表达式使用的几种特殊元字符序列之一。比如[:lower:]表示当前locale(☞87)中的所有小写字母。对英文文本来说,[:lower:]等于 a-z。因为整个序列只有在方括号表达式内才是有效的,所以对应的完整的字符组应该是「[[:lower:]]」。这种表示法的确很难看。但是,它比「[a-z]」更好用,因为它能包含 ö,ñ 之类当前 locale中定义的“小写字母”。
POSIX字符组的详细列表根据locale的变化而变化,但是下面这些通常都能支持:
[:alnum:] 字母字符和数字字符。
[:alpha:] 字母。
[:blank:] 空格和制表符。
[:cntrl:] 控制字符。
[:digit:] 数字。
[:graph:] 非空字符(即空白字符,控制字符之外的字符)。
[:lower:] 小写字母。
[:print:] 类似[:graph:],但是包含空白字符。
[:punct:] 标点符号。
[:space:] 所有的空白字符([:blank:]、换行符、回车符及其他)。
[:upper:] 大写字母。
[:xdigit:] 十六进制中容许出现的数字(例如0-9a-fA-F)。
支持Unicode属性(☞121)的系统可能会在Unicode支持中加入这些POSIX结构。Unicode属性结构更为强大,所以如果可能,这些结构应该有提供。
POSIX“collating序列”方括号表示法:[[.span-ll.]]
Local可以包含对应的collating序列,用来决定其中的字符如何排序。例如,在西班牙语中,按照惯例,ll两个字母在排序时作为一个逻辑字符(例如在tortilla中),排在l和m之间,日尔曼语字母ß位于s和t中间,但是排序时类似它等价于两个字母ss。这些规则可能用collating序列命名来表示,例如,span-ll和eszet。
collating序列会把多个实体字符映射到单个逻辑字符,在span-ll的例子中,ll被视为“一个字符”,来保持与POSIX正则引擎的兼容。也就是说,「[^abc]」能够匹配‘ll’两个字母。
collating 序列的元素可以包含在方括号表达式中,使用[.….]表示法:「torti[[.span-ll.]]a」匹配tortilla。单个collating序列可以匹配组合而成的字符。此种情况下,方括号表达式可以匹配多个实体字符。
POSIX“字符等价类”方括号表示法:[[=n=]]
有的locale定义了字符等价类,表示某些字符在进行排序之类的操作时应视为等价。例如,某locale可能定义了这样一个等价类‘n’,包含n和ñ,或者是另一个等价类‘a’,包含a、á和à。等价类的表示法类似[:…:],但是用等号取代冒号,我们可以在方括号表达式中引用这些等价类:「[[=n=][=a=]]」能够匹配刚才出现的任意一个字符。
如果一个字符等价类的名称只包含一个字母,但没有在locale中定义,则它默认就等于同样名字的collating序列。local通常包含作为collating序列的普通字符[.a.]、[.b.]、[.c.]之类——如果没有定义特殊的等价类,「[[=n=][=a=]]」就等于「[na]」。
Emacs语法类
GNU Emacs不支持传统的「\w」、「\s」之类;相反,它使用特殊的序列来引用“语法类(syntax classes)”:
\schar 匹配Emacs语法类中char描述的字符。
\Schar 匹配不在Emacs语法类中的字符。
「\sw」匹配“构成单词(word constituent)”的字符,而「\s-」匹配“空白字符”。在其他系统中,它们分别写作「\w」和「\s」。
Emacs 的特殊之处在于,在 Emacs 中,这些字符组包含的字符是可以临时更换的,所以,构成单词的字符组中的字符可以根据所编辑文本的变化而变化。
锚点及其他“零长度断言”
Anchors and Other"Zero-Width Assertions"
锚点和其他“零长度断言”并不会匹配实际的文本,而是寻找文本中的位置。
行/字符串的起始位置:^、\A
脱字符「^」匹配需要搜索的文本的起始位置,如果使用了增强的行锚点匹配模式(☞112),它还能匹配每个换行符之后的位置。在某些系统中,增强模式下「^」还能匹配Unicode的行终结符(☞109)。
如果可以使用,则无论在什么匹配模式下,「\A」总是能够匹配待搜索文本的起始位置。
行/字符串的结束位置:$、\Z和\z
从下一页的表格3-11可以看出,“行结束位置(end of line)”的概念比行开头位置要复杂。在不同的工具软件中,「$」的意义也不同,不过最常见的意思是匹配目标字符串的末尾,也可以匹配整个字符串末尾的换行符之前的位置。后一种情况更为常见,它容许「s$」(匹配“以
s结尾的行”)来匹配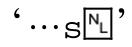 ,即以s和换行符结尾的行。
,即以s和换行符结尾的行。
「$」的另两种常见的意思是,只匹配目标文本的结束位置,或是匹配任何一个换行符之前的位置。在某些Unicode系统中,这些规则中的换行符会被替换为Unicode的行终结符(☞109) (Java为了处理Unicode的行终结符,为「$」设定了非常复杂的语意☞370)。
匹配模式(☞112)可以改变「$」的意义,匹配字符串中的任何换行符(或者是Unicode中的行终结符)。
如果支持,「\Z」通常表示“未指定任何模式下”「$」匹配的字符,通常是字符串的末尾位置,或者是在字符串末尾的换行符之前的位置。作为补充,「\z」只匹配字符串的末尾,而不考虑任何换行符。表3-11中列出了少数例外。
表3-11:脚本语言中的行锚点
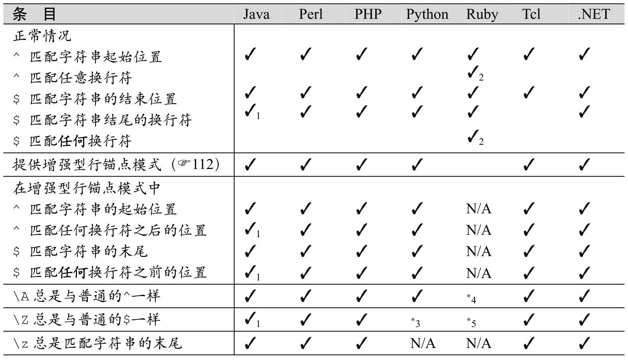
注:
在这些情况下,Sun的Java regex package支持Unicode的行终结符(☞109)。
Ruby的$和^能匹配字符串中的换行符,但是\A和\Z则不能。
Python的\Z只能匹配字符串的结束位置。
Ruby的\A与^不同,只能匹配字符串的起始位置。
Ruby的\Z与$不同,可以匹配字符串的结尾位置,或是字符串结尾的换行符之前的位置。
(请参考第91页的版本信息)
匹配的起始位置(或者是上一次匹配的结束位置):\G
「\G」首先出现在Perl中。在使用/g(☞51)的匹配中,\G对迭代操作非常有用,它能够匹配上一次匹配结束的位置。在第一次迭代时,「\G」匹配字符串的开头,与「\A」一样。
如果匹配不成功,「\G」的匹配会重新指向字符串的起始位置。这样,如果重复应用某个正则表达式,例如进行Perl的「s/…/…/g」操作,或者在其他语言中调用“找出所有匹配(match all)”函数,在匹配失败的同时,「\G」也会指向字符串的开头位置,这样以后进行其他类型的匹配操作便不受影响。
根据我的观察,Perl的「\G」有3个值得注意而且很有用的方面:
●「\G」的指向位置是每个目标字符串的属性,而不是设定这些位置的正则表达式的属性。也就是说,多个正则表达式可以依次对同一个字符串进行匹配,都使用上一轮匹配设定的「\G」。
●Perl 的正则运算符有一个选项(Perl 的/c修饰符☞315),它规定了,如果匹配失败,不要重新设定「\G」,而只是保持之前的值不变化。如果结合上面那一点,就可以从某个位置开始尝试用多个正则表达式进行匹配,直到匹配能够成功,然后在下面的文本中继续寻找匹配。
●「\G」对应的属性可以用与正则表达式无关的结构(Perl的pos函数☞313)来检查和修改。可能有人希望设定这个位置来“规定”从什么位置开始寻找匹配,以及只从那个位置开始的匹配。同样,如果语言支持本条功能,而没有直接提供上一条功能,我们可以用本条功能来模拟。
下页的补充内容中有个例子展示了这些特性的用法。除了这些便捷之外,Perl的「\G」还存在一个问题,即它必须出现在正则表达式的开头,这样才能正常工作。不过幸运的是,这似乎是最自然的用法。
之前匹配的结束位置,还是当前匹配的开始位置?
不同的实现方式之间存在一个区别,「\G」匹配的到底是“当前匹配的起始位置”还是“前一次匹配的结束位置”。在绝大多数情况下,这两者是等价的,所以大多数时候这个问题并不要紧。但也有些不常见的情况下,它们是有区别的。215页有个例子说明了这种情况,不过最容易的还是用一个专门的例子来理解:把「x?」应用到‘abcde’。这个表达式能够在‘☞abcde’匹配成功,但其实它没有匹配任何文本。在进行全局查找-替换时,正则表达式会重复应用,每次处理上一次操作之后的文本,除非传动装置会做些特别的处理,“上次匹配完成的位置”总是它开始的位置。为了避免无穷循环,在这种情况下传动装置会强行前进到下一个字符(☞148),如果对‘abcde’应用s/x?/!/g,结果就是‘!a!b!c!d!e!’。
传动装置这样处理会带来一个问题:“上一次匹配的终点”不等于“本次匹配的起点”。如果是这样,问题就来了:「\G」匹配哪个位置呢?在 Perl 中,对‘abcde’应用 s/\Gx?/!/g得到‘!abcde’,所以我们知道,在Perl中,「\G」只匹配上一次匹配的结束位置。如果传动装置自行驱动,Perl的\G肯定无法匹配。
另一方面,在其他某些工具软件中使用同样的查找-替换命令,会得到‘!a!b!c!d!e!’,也就是说\G是在每次匹配的起始位置匹配成功,然后由传动装置进行驱动。
关于「\G」的匹配,也不能完全相信文档,微软的.NET和Sun的Java文档,在我通知这两家公司之前,都是错误的(然后他们才修正)。现在的状态就是,PHP和Ruby中的「\G」指向当前匹配的开头位置,而Perl、java.util.regex和.NET匹配上一次匹配的结束位置。

单词分界符:\b、\B、\<、\>…
单词分界符的作用与行锚点一样,也是匹配字符串中的某些位置。单词分界符可以分为两类,一类中单词起始位置分界符和结束位置分界符是相同的(通常是\<和\>),另一类则以统一的分界符来匹配(通常是\b)。两类都提供了非单词分界符序列(通常是\B)。表 3-12给出了一些例子。如果所使用的工具软件没有提供单独的起始位置和结束位置分界符,但支持环视功能,用户也可以用它来模拟那两种单词分界符。在下面的表格中,如果程序本身没有提供分开的单词分界符,我会列出实践中的做法。
单词分界符通常可以这样理解,这个位置的一边是“单词字符(word character)”,另一边则不是。每种工具软件对“单词字符”的理解都不一样,对单词边界的理解也是这样。如果单词分界符等于\w当然好办,但很多时候事实并非如此。例如,在PHP和java.util.regex 中,\w 只能匹配 ASCII 字符,而不是 Unicode 字符,所以在表格中我会使用带有Unicode单词属性\pL(这是「\p{L}」的缩略表示法☞121)的环视功能。
无论单词分界符怎么定义“单词字符”,单词分界符的测试通常只是简单的字符相邻测试。所有的正则引擎都不会对单词进行语意分析:它们认为“NE14AD8”是一个单词,而“M.I.T.”不是。
顺序环视(?=…)、(?!…);逆序环视(?<=…)、(?<!…)
在前一章“使用环视功能在数值中插入逗号”(☞59)的例子中,我们已经介绍过顺序环视和逆序环视结构(统称为环视)。但关于它们还有很重要的一点没有介绍,那就是环视结构中能够出现什么样的表达式。大多数实现方式都限制了逆序环视中的表达式的长度(但是顺序环视则没有限制)。
Perl 和 Python 的限制是最严格的,逆序环视只能匹配固定长度的文本。使用(?<!\w)和(?<!this|that)不会出错,但是 (?<!books?)和(?<!^\w+:)则不行,因为它们匹配的文本的长度是不确定的。某些情况下,(?<!books?)可以重写为「(?<!book)(?<!books)」,尽管第一眼看上去它并不好理解。
表3-12:若干工具软件中使用的单词分界符元字符
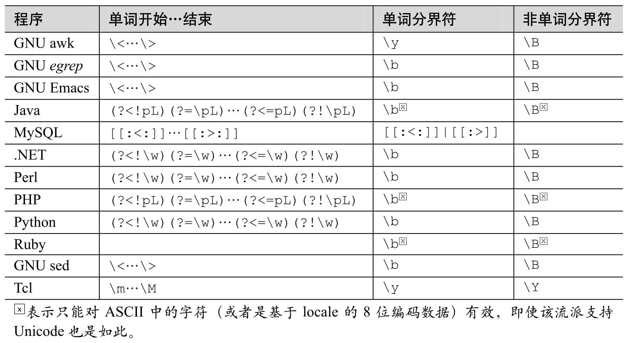
(请参考第91页的版本信息)
更高一层次的支持容许逆序环视中出现不同长度的多选分支,所以(?<!books?)可以写作(?<!book|books)。PCRE(因此也包括PHP中的preg套件)支持此功能。
最高层次的支持可以匹配任意长度的文本,只是其长度不能为无限。「(?<!books?)」可以直接使用,但是(?<!^\w+:)则不行,因为\w+能够匹配的长度没有限制。Sun 的 Java regex package支持这样。
就问题本身来说,这三级支持其实是一样的,因为它们都表达同样的意思,尽管有的表达方式可能不太好看,而且对匹配的长度进行了严格的限制。中间一级只不过是“语法(syntactic sugar)”,表达方式更美观而已。而第四级支持容许逆序环视结构中的子表达式匹配任意长度的文本,甚至包括「(?<!^\w+:)」。微软的.NET就支持这一级,它无疑是最棒的,但是如果运用不当,也可能带来严重的效率问题(如果逆序环视能够匹配任意长度的文本,引擎必须从字符串的起始位置开始检查逆序环视表达式,如果逆序环视是从长字符串的尾端开始的,这样就会浪费许多工夫)。
注释和模式修饰符
Comments and Mode Modifiers
在许多流派中,使用下面的结构,就能够在正则表达式内部,切换使用之前介绍的正则表达式模式和匹配模式(☞110)。
模式修饰符:(?modifier),例如(?i)和(?-i)
现在,有许多流派容许在正则表达式中设定匹配模式(☞110)。常见的就是「(?i)」,它会启用不区分大小写的匹配,而「(?-i)」会停用此功能。例如,「<B>(?i)very(?-i)</B>」会对中间的「very」进行不区分大小写的匹配。而两端的 tag 仍然必须为大写。它可以匹配‘<B>VERY</B>’ 和‘<B>Very</B>’,但不能匹配‘<b>Very</b>’。
这个例子在大多数支持「(?i)」的系统中都可以运行,例如Perl、PHP、java.util.regex、Ruby(注15)和.NET。在Python和Tcl中则不行,因为它们不支持「(?-i)」。
除Python之外,大多数实现方式中,「(?i)」的作用范围都只限于括号内部(也就是说,在闭括号之后就失效)。所以,我们可以拿掉「(?-i)」,将整个不需要区分大小写的部分放在一个括号里,把「(?i)」放在最前面:「<B>(?:(?i)very)</B>」。
模式修饰符中能够出现的不只有‘i’。在大多数系统中,我们至少可以使用表3-13列出的修饰符。有的系统还提供了更多的选项。比如 PHP 就提供了少数其他选项(☞446),Tcl也是如此(请参考文档)。
表3-13:常见模式修饰符字母

模式作用范围:(?modifier:…),例如(?i:…)
如果所使用的系统支持模式修饰范围,这样前一节的例子可以更加简化。「(?i:…)」表示模式修饰符的作用范围只有在括号内有效。这样,「<B>(?:(?i)very)</B>」就可以化简为「<B>(?i:very)</B>」。
如果支持,这种格式一般可以应用于所有的模式修饰符字母。Tcl 和 Python 都支持「(?i)」格式,但是不支持「(?i:…)」格式。
注释:(?#…)和#…
某些流派支持用「(?#…)」添加注释。实际上,如果流派支持宽松排列和注释模式(☞111),就很少使用这种功能。不过,如果在字符串文字中很难插入换行符,用这种格式加入注释就非常方便,例如VB.NET就是如此(☞99,420)。
文字文本范围:\Q…\E
\Q…\E是由Perl引入的,它会消除其中除\E之外所有元字符的特殊含义(如果没有\E,就会一直作用到正则表达式末端)。其中的所有字符都会被当成普通文字文本来对待。如果在构建正则表达式时包含变量,此功能就非常有用。
举例来说,为了响应Web检索,我们可能希望把用户输入的内容保存在$query中,然后使用m/$query/i。但是,如果$query包含某些字符,例如‘C:\WINDOWS\’,结果是运行时错误,因为这不是一个合法的正则表达式(最后有一个单独的反斜线)。
「\Q…\E」可以解决这个问题。如果在Perl中使用m/\Q$query\E/i,则$query就从‘C:\WIN-DOWS\’变成「C\:\\WINDOWS\\」,结果能找到用户期望的‘C:\WINDOWS\’。
但是在面向对象和程序式处理(☞95)中,这个特性的用处要打折扣。在构建需要用在正则表达式中的字符串时,有很方便的函数对这个值“上保险”,以便用在正则表达式中。例如,在VB中,我们可以使用Regex.Escape(☞432);PHP提供了preg_quote函数(☞470),Java有quote方法(☞395)。
就我所知,支持「\Q…\E」的引擎只有java.util.regex和PCRE(也包括PHP的preg套件)。请注意,我刚刚提到,这个功能是在Perl中引入的(而且我给出了Perl的例子),你可能觉得很奇怪,为什么刚刚没有提到Perl。Perl支持正则文字中的\Q…\E(也就是直接出现在程序中的正则表达式),但是不能在可能使用插值的内容和变量上使用。细节问题请参考第 7章(☞290)。
在低于1.6.0 的Java 中,java.util.regex对字符组中的「\Q…\E」支持是不可靠的,不建议使用。
分组,捕获,条件判断和控制
Grouping,Capturing,Conditionals,and Control
捕获/分组括号:(…)和\1,\2,…
普通的无特殊意义的括号通常有两种功能:分组和捕获。普通括号常见的形式是「(…)」,但有的流派中使用「\(…\)」,例如GNU Emacs、sed、vi和grep。
如41、43 和 57 页的图所示,捕获型括号的编号是按照开括号出现的次序,从左到右计算的。如果提供了反向引用,则这些括号内的子表达式匹配的文本可以在表达式的后面部分用「\1」、「\2」来引用。
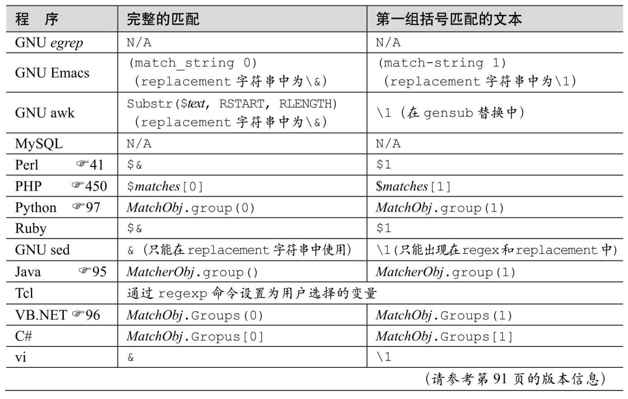
括号的常用功能之一是从字符串中提取数据。括号中的子表达式匹配的文本(也可以称为“括号匹配文本(the text matched by the parentheses)”)在不同的程序中可以通过不同的方式来引用,例如Perl的$1和$2(常见的错误是在正则表达式之外使用「\1」,这种形式只在sed和vi中能用)。下一页的表3-14说明了各种程序中,匹配完成之后访问文本的方法。它还说明了访问整个表达式匹配的文本,或者某一组捕获型括号所匹配文本的做法。
仅用于分组的括号:(?:…)
仅用于分组的括号「(?:…)」不能用来提取文本,而只能用来规定多选结构或者量词的作用对象。它们不会按照$1、$2之类编号。在「(1|one)(?:and|or)(2|two)」匹配之后,$1包含‘1’或者‘one’,$2包含‘2’或者‘two’。只用于分组的括号也叫非捕获型括号(non-capturing parentheses)。
非捕获型括号的价值体现在好几个方面。它们能够把复杂的表达式变得清晰,这样读者不会担心在其他地方用到$1会产生混乱。而且它们还有助于提高效率。如果正则引擎不需要记录捕获型括号匹配的内容,速度会更快,所用的内存也更少(第6章详细讲解效率问题)。
非捕获型括号的另一个用途是利用多个成分构建正则表达式。在第76页的例子中,$Host-nameRegex保存的是用来匹配主机名的正则表达式。如果使用它来提取主机名两端的空白,在Perl中是m/(\s*)$HostnameRegex(\s*)/。然后$1和$2分别保存开头和结尾的空白,但结尾的空白其实是保存在$4中的,因为$HostnameRegex包含两组捕获型括号。
$HostnameRegex=qr/[-a-z0-9]+(\.[-a-z0-9]+)*\.(com|edu|info)/i;
表3-14:若干工具软件及其中访问捕获文本的方法
如果这两组括号是非捕获型的,我们就可以按照直观的方式使用$HostnameRegex。另一种办法是使用命名捕获,尽管Perl没有提供这种功能,我们还是会介绍它。
命名捕获:(?<Name>…)
Python和PHP的preg引擎,以及.NET引擎,都能够为捕获内容命名。Python和PHP使用的语法是「(?P<name>…)」,而.NET使用「(?<name>…)」。我更喜欢.NET的语法。下面是一个.NET的例子:
「\b(?<Area>\d\d\d\)-(?<Exch>\d\d\d)-(?<Num>\d\d\d\d)\b」
在Python/PHP中是这样:
「\b(?P<Area>\d\d\d\)-(?P<Exch>\d\d\d)-(?P<Num>\d\d\d\d)\b」
这个表达式会用美国电话号码的各个部分“填充”Area、Exch和Num命名的内容。然后我们可以通过名称来访问各个括号捕获的内容,例如在VB.NET和大多数.NET语言中,可以使用RegexObj.Groups("Area"),在C#中使用RegexObj.Groups["Area"],在Python中使用RegexObj.group("Area"),在PHP 中使用$matches["Area"]。这样程序看起来更清晰。
如果要在正则表达式内部引用捕获的文本,.NET中使用「\k<Area>」,Python和PHP中使用「(?P=Area)」。
在Pyhon和.NET(但不包括PHP)中,可以在同一个表达式中多次使用同样的命名。例如美国电话号码的区号部分的形式是‘(###)’或者‘###-’,为了匹配,我们可以使用(用.NET语法):「…(?:\((?<Area>\d\d\d)\)|(?<Area>\d\d\d)-)…」。无论哪一组匹配成功,都会把3位的区号保存到Area中。
固化分组:(?>…)
如果详细了解正则引擎的匹配原理(☞169),就很容易理解固化分组。在这里只说一点,就是一旦括号内的子表达式匹配之后,匹配的内容就固定下来(固化(atomic)下来无法改变),在接下来的匹配过程中不会变化,除非整个固化分组的括号都被弃用,在外部回溯中重新应用。下面这个简单的例子会帮助我们理解这种匹配的“固化”性质。
「¡.*!」能够匹配‘¡Hola!’,但是如果「.*」在固化分组「¡(?>.*)!」中就无法匹配。在这两种情况下,「.*」都会首先匹配尽可能多的内容 ,但是之后的「!」无法匹配,会强迫「.*」释放之前匹配的某些内容(最后的‘!’)。如果使用了固化分组,就无法实现,因为「.*」在固化分组中,它永远也不会“交还”已经匹配的任何内容。
,但是之后的「!」无法匹配,会强迫「.*」释放之前匹配的某些内容(最后的‘!’)。如果使用了固化分组,就无法实现,因为「.*」在固化分组中,它永远也不会“交还”已经匹配的任何内容。
尽管这个例子没有什么实际价值,固化分组还是有重要的用途。尤其是,它能够提高匹配的效率(☞171),而且能够对什么能匹配,什么不能匹配进行准确地控制(☞269)。
多选结构:…|…|…
多选结构能够在同一位置测试多个子表达式。每个子表达式称为一个多选分支(alternative)。符号「|」有很多称呼,不过“或(or)”和“竖线(bar)”最为常见。有的流派使用「\|」。
多选结构的优先级很低,所以「this and|or that」的匹配等价于「(this and)|(or that)」,而不是「this (and|or) that」,虽然and|or看上去是一个单位。
大多数流派都容许出现空的多选分支,例如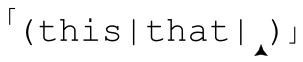 。空表达式在任何情况下都能匹配,所以这个例子等于「(this|that)?」(注16)。
。空表达式在任何情况下都能匹配,所以这个例子等于「(this|that)?」(注16)。
POSIX标准禁止出现空多选分支,lex和大多数版本的awk也是如此。我认为,考虑到空多选分支的简便和清晰,保留它不无益处。Larry Wall告诉我:“我认为,保留它就好像在数学中保留0一样有意义”。
条件判断:(?if then|else)
这个结构容许用户在正则表达式中使用 if/then/else 判断。if 部分是特殊的条件表达式(a special kind of conditional expression),下文马上会有介绍。then和else部分是普通的子表达式。如果if部分测试为真,则尝试then的表达式,否则尝试else部分(else部分也可以不出现,果真如此的话,可以省略‘|’)。
if的种类因流派的不同而不同,但是大多数实现方式都容许在其中引用捕获的子表达式和环视结构。
测试对捕获型括号的特殊引用。如果 if 部分是一个括号中的编号,而对应编号的捕获型括号参与了匹配,其值为“true”。下面的例子匹配<IMG> tag,无论是是单独出现的,或者是在<A>…</A>中出现的。代码采用带注释的宽松排列格式,条件判断结构(这里的没有else部分)以粗体标注。

「(?(1)…)」测试中的(1)会测试第一组捕获型括号是否参与了匹配。“参与匹配”不等于“实际匹配了文本”,来看个简单的例子:
下面两种办法都可以匹配可能包含在“<…>”中的单词:「(<)?\w+(?(1)>)」可以,「(<?)\w+(?(1)>)」则不行。它们之间唯一的区别在于第一个问号出现的位置。在第一种(正确的)办法中,问号作用于整个捕获型括号,所以括号(以及包含的内容)不是必须匹配的。在第二个例子中,捕获型括号不是可选的——只有其中的「<」才是,所以无论‘<’是否匹配了文本,它都“参与匹配”。也就是说,「(?(1)…)」中的if部分总是“true”。
如果能够使用命名捕获(☞138),就可以在括号中使用命名,而不是编号。
用环视做测试。完整的环视结构,例如「(?=…)」和「(?<=…)」,可以用于 if 测试。如果环视能够匹配,它返回“true”,执行then部分。否则会执行else部分。来看个专门设计的例子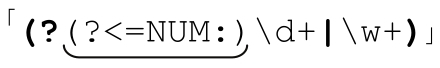 ,它会在「NUM:」之后的位置尝试匹配「\d+」,但是在其他位置尝试使用「\w+」。环视条件判断以下画线标注。
,它会在「NUM:」之后的位置尝试匹配「\d+」,但是在其他位置尝试使用「\w+」。环视条件判断以下画线标注。
条件判断的其他测试。Perl 提供了一种复杂的条件判断结构,容许在测试中使用任意 Perl代码。返回值作为测试的值,根据它来判断then或者else部分是否应该尝试。详细信息请参考第7章的第327页。
匹配优先量词:*、+、?、{num,num}
量词(星号、加号、问号,以及区间元字符,它们能够限制作用对象的匹配次数)已经有过详细介绍。不过,需要注意的是,在某些工具中使用「\+」和「\?」来取代「+」和「?」。同样,在某些更老的工具中,量词不能限定反向引用,也不能限定括号。
区间:{min,max}或者\{min,max\}
区间可以被认为是“计数量词(counting quantifier)”,因为用户可以通过区间指定匹配成功所必须的下限和上限。如果只设置了一个数值(例如「[a-z]{3}」或者「[a-z]\{3\}」,依流派决定),匹配的次数就等于这个值。它等同于「[a-z][a-z][a-z]」(尽管两者的效率可能有所不同☞251)。
需要注意的是,不要认为「X{0,0}」的意思是“X 不能出现”。「X{0,0}」没有意义,因为它的意思是“不需要匹配「X」,也就是说实际上根本不需要进行任何尝试”。它基本等于「X{0,0}」不存在——如果存在 X,它也可以被正则表达式之后出现的某些元素匹配,所以这种做法是行不通的(注17)。要实现“不容许存在”,请使用否定性环视。
忽略优先量词:*?、+?、??、{num,num}?
有的工具提供了不那么美观的量词:*?、+?、??和{min,max}?。这些是忽略优先的量词。量词在正常情况下都是“匹配优先(greedy)”的,匹配尽可能多的内容。相反,这些忽略优先的量词会匹配尽可能少的内容,只需要满足下限,匹配就能成功。其中的差异有深远的影响,详细的介绍在下一章(☞159)。
占有优先量词:*+、++、?+、{num,num}+
这些量词目前只有java.util.regex和PCRE(以及PHP)提供,但是很可能会流行开来,占有优先量词类似普通的匹配优先量词,不过他们一旦匹配某些内容,就不会“交还”。它们类似固化分组,如果理解了基本的匹配过程,就很容易理解占有优先量词。
从某种意义上来说,占有优先的量词只是些表面工夫,因为它们可以用固化分组来模拟。「.++」与「(?>.+)」的结果完全一样,只是足够智能的实现方式能对占有优先量词进行更多的优化。