Backtracking
NFA 引擎最重要的性质是,它会依次处理各个子表达式或组成元素,遇到需要在两个可能成功的可能中进行选择的时候,它会选择其一,同时记住另一个,以备稍后可能的需要。
需要做出选择的情形包括量词(决定是否尝试另一次匹配)和多选结构(决定选择哪个多选分支,留下哪个稍后尝试)。
不论选择那一种途径,如果它能匹配成功,而且正则表达式的余下部分也成功了,匹配即告完成。如果正则表达式中余下的部分最终匹配失败,引擎会知道需要回溯到之前做出选择的地方,选择其他的备用分支继续尝试。这样,引擎最终会尝试表达式的所有可能途径(或者是匹配完成之前需要的所有途径)。
真实世界中的例子:面包屑
A Really Crummy Analogy
回溯就像是在道路的每个分岔口留下一小堆面包屑。如果走了死路,就可以照原路返回,直到遇见面包屑标示的尚未尝试过的道路。如果那条路也走不通,你可以继续返回,找到下一堆面包屑,如此重复,直到找到出路,或者走完所有没有尝试过的路。
在许多情况下,正则引擎必须在两个(或更多)选项中做出选择——我们之前看到的分支的情况就是一例。另一个例子是,在遇到「…x?…」时,引擎必须决定是否尝试匹配「x」。对于「…x+…」的情况,毫无疑问,「x」至少尝试匹配一次——因为加号要求必须匹配至少一次。第一个「x」匹配之后,此要求已经满足,需要决定是否尝试下一个「x」。如果决定进行,还要决定是否匹配第三个「x」,第四个「x」,如此继续。每次选择,其实就是洒下一堆“面包屑”,用于提示此处还有另一个可能的选择(目前还不能确定它能否匹配),保留起来以备用。
一个简单的例子
现在来看个完整的例子,用先前的「to(nite|knight|night)」匹配字符串‘hot·tonic· tonight!’(看起来有点无聊,但是个好例子)。第一个元素「t」从字符串的最左端开始尝试,因为无法匹配‘h’,所以在这个位置匹配失败。传动装置于是驱动引擎向后移动,从第二个位置开始匹配(同样也会失败),然后是第三个。这时候「t」能够匹配,接下来的「o」无法匹配,因为字符串中对应位置是一个空格。至此,本轮尝试宣告失败。
继续下去,从…☞tonic…开始的尝试则很有意思。to匹配成功之后,剩下的3 个多选分支都成为可能。引擎选取其中之一进行尝试,留下其他的备用(也就是洒下一些面包屑)。在讨论中,我们假定引擎首先选择的是「nite」。这个表达式被分解为“「n」+「i」+「t」+「e」”,在…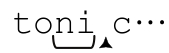 遭遇失败。但此时的情况与之前不同,这种失败并不意味着整个表达式匹配失败——因为仍然存在没有尝试过的多选分支(就好像是,我们仍然可以找到先前留下的面包屑)。假设引擎然后选择「knight」,那么马上就会遭遇失败,因为「k」不能匹配‘n’。现在只剩下最后的选项「night」,但它不能失败。因为「night」是最后尝试的选项,它的失败也就意味着整个表达式在…☞tonic…的位置匹配失败,所以传动机构会驱动引擎继续前进。
遭遇失败。但此时的情况与之前不同,这种失败并不意味着整个表达式匹配失败——因为仍然存在没有尝试过的多选分支(就好像是,我们仍然可以找到先前留下的面包屑)。假设引擎然后选择「knight」,那么马上就会遭遇失败,因为「k」不能匹配‘n’。现在只剩下最后的选项「night」,但它不能失败。因为「night」是最后尝试的选项,它的失败也就意味着整个表达式在…☞tonic…的位置匹配失败,所以传动机构会驱动引擎继续前进。
直到引擎开始从…☞tonight!处开始匹配,情况又变得有趣了。这一次,多选分支「night」终于可以匹配字符串的结尾部分了(于是整体匹配成功,现在引擎可以报告匹配成功了)。
回溯的两个要点
Two Important Points on Backtracking
回溯机制的基本原理并不难理解,还是有些细节对实际应用很重要。它们是,面对众多选择时,哪个分支应当首先选择?回溯进行时,应该选取哪个保存的状态?第一个问题的答案是下面这条重要原则:
如果需要在“进行尝试”和“跳过尝试”之间选择,对于匹配优先量词,引擎会优先选择“进行尝试”,而对于忽略优先量词,会选择“跳过尝试”。
此原则影响深远。对于新手来说,它有助于解释为什么匹配优先的量词是“匹配优先”的,但还不完整。要想彻底弄清楚这一点,我们需要了解回溯时使用的是哪个(或者是哪些个)之前保存的分支,答案是:
距离当前最近储存的选项就是当本地失败强制回溯时返回的。使用的原则是LIFO(last in first out,后进先出)。
用面包屑比喻就很好理解——如果前面是死路,你只需要沿原路返回,直到找到一堆面包屑为止。你会遇到的第一堆面包屑就是最近洒下的。传统的LIFO比喻也是这样:就像堆叠盘子一样,最后叠上去的盘子肯定是最先拿下来的。
备用状态
Saved States
用NFA正则表达式的术语来说,那些面包屑相当于“备用状态(saved state)”。它们用来标记:在需要的时候,匹配可以从这里重新开始尝试。它们保存了两个位置:正则表达式中的位置,和未尝试的分支在字符串中的位置。因为它是NFA匹配的基础,我们需要再看一遍某些已经出现过的简单但详细的例子,说明这些状态的意义。如果你觉得现有的内容都不难懂,请继续阅读。
未进行回溯的匹配
来看个简单的例子,用「ab?c」匹配abc。「a」匹配之后,匹配的当前状态如下:
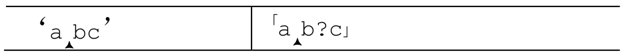
现在轮到「b?」了,正则引擎需要决定:是需要尝试「b」呢,还是跳过?因为?是匹配优先的,它会尝试匹配。但是,为了确保在这个尝试最终失败之后能够恢复,引擎会把:
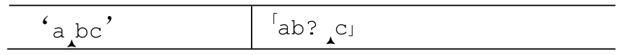
添加到备用状态序列中。也就是说,稍后引擎可以从下面的位置继续匹配:从正则表达式中的「b?」之后,字符串的b之前(也就是当前的位置)匹配。这实际上就是跳过「b」的匹配,而问号容许这样做。
引擎放下面包屑之后,就会继续向前,检查「b」。在示例文本中,它能够匹配,所以新的当前状态变为:
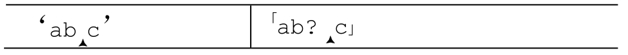
最终的「c」也能成功匹配,所以整个匹配完成。备用状态不再需要了,所以不再保存它们。
进行了回溯的匹配
如果需要匹配的文本是‘ac’,在尝试「b」之前,一切都与之前的过程相同。显然,这次「b」无法匹配。也就是说,对「…?」进行尝试的路走不通。因为有一个备用状态,这个“局部匹配失败”并不会导致整体匹配失败。引擎会进行回溯,也就是说,把“当前状态”切换为最近保存的状态。在本例中,情况就是:
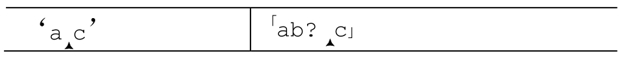
在「b」尝试之前保存的尚未尝试的选项。这时候,「c」可以匹配c,所以整个匹配宣告完成。
不成功的匹配
现在,我们用同样的表达式匹配‘abX’。在尝试「b」以前,因为存在问号,保存了这个备用状态:
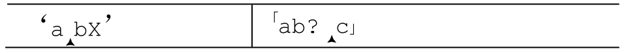
「b」能够匹配,但这条路往下却走不通了,因为「c」无法匹配X。于是引擎会回溯到之前的状态,“交还”b给「c」来匹配。显然,这次测试也失败了。如果还有其他保存的状态,回溯会继续进行,但是此时不存在其他状态,在字符串中当前位置开始的整个匹配也就宣告失败。
事情到此结束了吗?没有。传动装置会继续“在字符串中前行,再次尝试正则表达式”,这可能被想象为一个伪回溯(pseudo-backtrack)。匹配重新开始于:
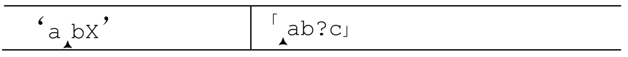
从这里重新开始整个匹配,如同之前一样,所有的道路都走不通。接下来的两次(从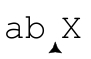 到
到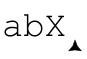 )都告失败,所以最终会报告匹配失败。
)都告失败,所以最终会报告匹配失败。
忽略优先的匹配
现在来看最开始的例子,使用忽略优先匹配量词,用「ab??c」来匹配‘abc’。「a」匹配之后的状态如下:
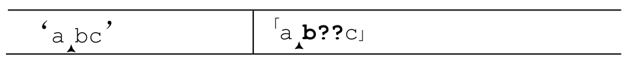
接下来轮到「b??」,引擎需要进行选择:尝试匹配「b」,还是忽略?因为??是忽略优先的,它会首先尝试忽略,但是,为了能够从失败的分支中恢复,引擎会保存下面的状态:
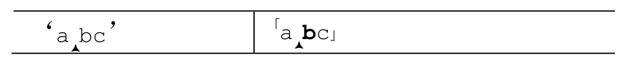
到备用状态列表中。于是,引擎稍后能够用正则表达式中的「b」来尝试匹配文本中的 b(我们知道这能够匹配,但是正则引擎不知道,它甚至都不知道是否会要用到这个备用状态)。状态保存之后,它会继续向前,沿着忽略匹配的路走下去:
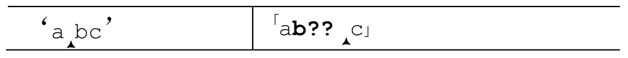
「c」无法匹配‘b’,所以引擎必须回溯到之前保存的状态:
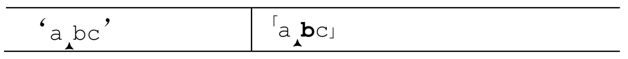
显然,此时匹配可以成功,接下来的「c」匹配‘c’。于是我们得到了与使用匹配优先的「ab?c」同样的结果,虽然两者所走的路不相同。
回溯与匹配优先
Backtracking and Greediness
如果工具软件使用的是NFA正则表达式主导的回溯引擎,理解正则表达式的回溯原理就成了高效完成任务的关键。我们已经看到「?」的匹配优先和「??」的忽略优先是如何工作的,现在来看星号和加号。
星号、加号及其回溯
如果认为「x*」基本等同于「x?x?x?x?x?x?…」(或者更确切地说是「(x(x(x(x…?)?)?)?)?)」) (注 5),那么情况与之前没有大的差别。每次测试星号作用的元素之前,引擎都会保存一个状态,这样,如果测试失败(或者测试进行下去遭遇失败),还能够从保存的状态开始匹配。这个过程会不断重复,直到包含星号的尝试完全失败为止。
所以,如果用「[0-9]+」来匹配‘a·1234·num’,「[0-9]」遇到4之后的空格无法匹配,而此时加号能够回溯的位置对应了四个保存的状态:
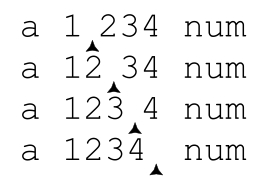
也就是说,在每个位置,「[0-9]」的尝试都代表一种可能。在「[0-9]」遇到空格匹配失败时,引擎回溯到最近保存的状态(也就是最下面的位置),选择正则表达式中的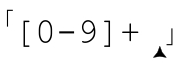 和文本中的
和文本中的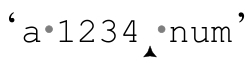 ’。当然,到此整个正则表达式已经结束,所以我们知道,整个匹配宣告完成。
’。当然,到此整个正则表达式已经结束,所以我们知道,整个匹配宣告完成。
请注意,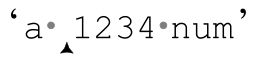 ’并不在列表中,因为加号限定的元素至少要匹配一次,这是必要条件。那么,如果正则表达式是
’并不在列表中,因为加号限定的元素至少要匹配一次,这是必要条件。那么,如果正则表达式是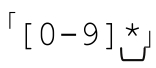 ,这个状态会保存吗?(提示:这个问题得动点脑筋)。要知道答案,ϖ请翻到下一页。
,这个状态会保存吗?(提示:这个问题得动点脑筋)。要知道答案,ϖ请翻到下一页。
重新审视更完整的例子
有了更详细的了解之后,我们再来看看第 152 页的「^.*([0-9][0-9])」的例子。这一次,我们不是只用“匹配优先”来解释为什么会得到那样的匹配结果,我们能够根据NFA的匹配机制做出精确解释。
以‘CA·95472·USA’为例。在「.*」成功匹配到字符串的末尾时,星号约束的点号匹配了13个字符,同时保存了许多备用状态。这些状态表明稍后的匹配开始的位置:在正则表达式中是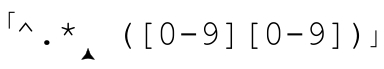 ,在字符串中则是点号每次匹配时保存的备用状态。
,在字符串中则是点号每次匹配时保存的备用状态。
现在我们已经到了字符串的末尾,并把控制权交给第一个「[0-9]」,显然这里的匹配不能成功。没问题,我们可以选择一个保存的状态来进行尝试(实际上保存了许多的状态)。现在回溯开始,把当前状态设置为最近保存的状态,也就是「.*」匹配最后的 A 之前的状态。忽略(或者,如果你愿意,可以使用“交还”)这个匹配,于是有机会用「[0-9]」匹配这个A,但这同样会失败。
这种“回溯-尝试”的过程会不断循环,直到引擎交还2为止,在这里,第一个「[0-9]」可以匹配。但是第二个「[0-9]」仍然无法匹配,所以必须继续回溯。现在,之前尝试中第一个「[0-9]」是否匹配与本次尝试并无关系了,回溯机制会把当前的状态中正则表达式内的对应位置设置到第一个「[0-9]」以前。我们看到,当前的回溯同样会把字符串中的位置设置到7以前,所以第一个「[0-9]」可以匹配,而第二个「[0-9]」也可以(匹配2)。所以,我们得到一个匹配结果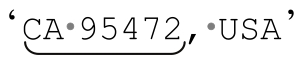 ’,$1得到72。
’,$1得到72。
需要注意的是:第一,回溯机制不但需要重新计算正则表达式和文本的对应位置,也需要维护括号内的子表达式所匹配文本的状态。在匹配过程中,每次回溯都把当前状态中正则表达式的对应位置指向括号之前,也就是「^.*☞([0-9][0-9])」。在这个简单的例子中,所以它等价于 ,因此我说“使用第一个[0-9]之前的位置”。然而,回溯对括号的这种处理,不但需要同时维护$1的状态,也会影响匹配的效率。
,因此我说“使用第一个[0-9]之前的位置”。然而,回溯对括号的这种处理,不但需要同时维护$1的状态,也会影响匹配的效率。
最后需要注意的一点也许读者早就了解:由星号(或其他任何匹配优先量词)限定的部分不受后面元素影响,而只是匹配尽可能多的内容。在我们的例子中,「.*」在点号匹配失败之前,完全不知道,到底应该在哪个数字或者是其他什么地方停下来。在「^.*([0-9]+)」的例子中我们看到,「[0-9]+」只能匹配一位数字(☞153)。