More About Greediness and Backtracking
NFA和DFA都具备许多匹配优先相关的特性(也从中获益)。(DFA不支持忽略优先,所以我们现在只关注匹配优先)。我将考察两种引擎共同支持的匹配优先特性,但只会用 NFA来讲解。这些内容对DFA也适用,但原因与NFA不同。DFA是匹配优先的,使用起来很方便,这一点我们只需要记住就够了,而且介绍起来也很乏味。相反,NFA 的匹配优先就很值得一谈,因为NFA是表达式主导的,所以匹配优先的特性能产生许多神奇的结果。除了忽略优先,NFA还提供了其他许多特性,比如环视、条件判断(conditions)、反向引用,以及固化分组。最重要的是NFA能让使用者直接操控匹配的过程,如果运用得当,这会带来很大的方便,但也可能带来某些性能问题(具体见第6章)。

不考虑这些差异的话,匹配的结果通常是相通的。我介绍的内容适用于两种引擎,除了使用表达式主导的NFA引擎。读完本章,读者会明白,在什么情况下两种引擎的结果会不一样,以及为什么会不一致。
匹配优先的问题
Problems of Greediness
在上例中已经看到,「.*」经常会匹配到一行文本的末尾(注6)。这是因为「.*」匹配时只从自身出发,匹配尽可能多的内容,只有在全局匹配需要的情况下才会“被迫”交还一些字符。有些时候问题很严重。来看用一个匹配双引号文本的例子。读者首先想到的可能是「".*"」,那么,请运用我们刚刚学到的关于「.*」的知识,猜一猜用它匹配下面文本的结果:
The name "McDonald's" is said "makudonarudo" in Japanese.
既然知道了匹配原理,其实我们并不需要猜测,因为我们“知道”结果。在最开始的双引号匹配之后,「.*」能够匹配任何字符,所以它会一直匹配到字符串的末尾。为了让最后的双引号能够匹配,「.*」会不断交还字符(或者,更确切地说,是正则引擎强迫它回退),直到满足为止。最后,这个正则表达式匹配的结果就是:
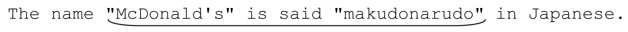
这显然不是我们期望的结果。我之所以提醒读者不要过分依赖「.*」,这就是原因之一,如果不注意匹配优先的特性,结果往往出乎意料。
那么,我们如何能够只取得"McDonald's"呢?关键的问题在于要认识到,我们希望匹配的不是双引号之间的“任何文本”,而是“除双引号以外的任何文本”。如果用「[^"]*」取代「.*」,就不会出现上面的问题。
使用「"[^"]*"」时,正则引擎的基本匹配过程跟上面是一样的。第一个双引号匹配之后,「[^"]*」会匹配尽可能多的字符。在本例中,就是 McDonald's,因为「[^"]」无法匹配之后的双引号。此时,控制权转移到正则表达式末尾的「"」。而它刚好能够匹配,所以获得全局匹配:
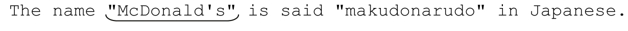
事实上,可能还存在一种出乎读者预料的情况,因为在大多数流派中,「[^"]」能够匹配换行符,而点号则不能。如果不想让表达式匹配换行符,可以使用「[^"\n]」。
多字符“引文”
Multi-Character"Quotes"
第1章出现了对HTML tag的匹配,例如,浏览器会把<B>very</B>中的“very”渲染为粗体。对<B>…</B>的匹配尝试看起来与对双引号匹配的情形很相似,只是“双引号”在这里成了多字符构成的<B>和</B>。与双引号字符串的例子一样,使用「.*」匹配多字符“引文”也会出错:
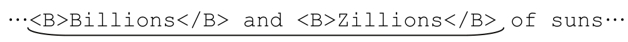
「<B>.*</B>」中匹配优先的「.*」会一直匹配该行结尾的字符,回溯只会进行到「</B>」能够匹配为止,也就是最后一个</B>,而不是与匹配开头的「<B>」对应的「</B>」。
不幸的是,因为结束tag不是单个字符,所以不能用之前的办法,也就是“排除型字符组”来解决,即我们不能期望用「<B>[^</B>]*</B>」解决问题。字符组只能代表单个字符,而我们需要的「</B>」是一组字符。请不要被「[^</B>]」迷惑,它只是表示一个不等于<、>、/、B的字符,等价于「[^/<>B]」,而这显然不是我们想要的“除</B>结构之外的任何内容”(当然,如果使用环视功能,我们可以规定,在某个位置不应该匹配「</B>」,下一节会出现这种应用)。
使用忽略优先量词
Using Lazy Quantifiers
上面的问题之所以会出现,原因在于标准量词是匹配优先的。某些NFA支持忽略优先的量词(☞141),*?就是与 * 对应的忽略优先量词。我们用「<B>.*?</B>」来匹配:
…<B>Billions</B> and <B>Zillions</B> of suns…
开始的「<B>」匹配之后,「.*?」首先决定不需要匹配任何字符,因为它是忽略优先的。于是,控制权交给后面的「<」符号:

此时「<」无法匹配,所以控制权交还给「.*?」,因为还有未尝试过的匹配可能(事实上能够进行多次匹配尝试)。它的匹配尝试是步步为营的(begrudgingly),先用点号来匹配…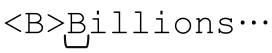 中带下画线的B。此时,*?又必须选择,是继续尝试匹配,还是忽略?因为它是忽略优先的,会首先选择忽略。接下来的「<」仍然无法匹配,所以「.*?」必须继续尝试未匹配的分支。在这个过程重复 8 次之后,「.*?」最终匹配了 Billions,此时,解下来的「<」(以及整个「</B>」)都能匹配:
中带下画线的B。此时,*?又必须选择,是继续尝试匹配,还是忽略?因为它是忽略优先的,会首先选择忽略。接下来的「<」仍然无法匹配,所以「.*?」必须继续尝试未匹配的分支。在这个过程重复 8 次之后,「.*?」最终匹配了 Billions,此时,解下来的「<」(以及整个「</B>」)都能匹配:
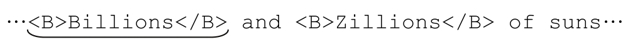
所以我们知道了,星号之类的匹配优先量词有时候的确很方便,但有时候也会带来大麻烦。这时候,忽略优先的量词就能派上用场了,因为它们做到其他办法很难做到(甚至无法做到)的事情。当然,缺乏经验的程序员也可能错误地使用忽略优先量词。事实上,我们刚刚做的或许就不正确。如果用「<B>.*?</B>」来匹配:
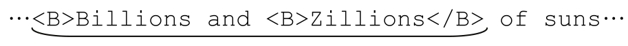
结果如上图,虽然我假设匹配的结果取决于具体的需求,但我仍然认为,这种情况下的结果不是用户期望的。不过,「.*?」必然会匹配Zillions左边的<B>,一直到</B>。
这个例子很好地说明了,为什么通常情况下,忽略优先量词并不是排除类的完美替身。在「".*"」的例子中,使用「[^"]」替换点号能避免跨越引号的匹配——这正是我们希望实现的功能。
如果支持排除环视(☞133),我们就能得到与排除型字符组相当的结果。比如,「(?!<B>)」这个测试,只有当<B>不在字符串中的当前位置时才能成功。这也是「<B>.*?</B>」中的点号期望匹配的内容,所以把点号改为「((?!<B>).)」得到的正则表达式,就能准确匹配我们期望的内容。把这些综合起来,结果有点儿难看懂,所以我选用带注释的宽松排列模式(☞111)来讲解:

使用了环视功能之后,我们可以重新使用普通的匹配优先量词,这样看起来更清楚:

现在,环视功能会禁止正则表达式的主体(main body)匹配<B>和</B>之外的内容,这也是我们之前试图用忽略优先量词解决的问题,所以现在可以不用忽略优先功能了。这个表达式还有能够改进的地方,我们将在第6章关于效率的讨论中看到它(☞270)。
匹配优先和忽略优先都期望获得匹配
Greediness and Laziness Always Favor a Match
回忆一下第2章中显示价格的例子(☞51)。我们会在本章的多个地方仔细检查这个例子,所以我先重申一下基本的问题:因为浮点数的显示问题,“1.625”或者“3.00”有时候会变成“1.62500000002828”和“3.00000000028822”。为解决这个问题,我使用:
$price=~s/(\.\d\d[1-9]?)\d*/$1/;
来保存$price小数点后头两到三位十进制数字。「\.\d\d」匹配最开始两位数字,而「[1-9]?」用来匹配可能出现的不等于零的第三个数字。
然后我写道:
到现在,我们能够匹配的任何内容都是希望保留的,所以用括号包围起来,作为$1捕获。然后就能在replacement字符串中使用$1。如果这个正则表达式能够匹配的文本就等于$1,那么我们就是用一个文本取代它本身——这没有多少意义。然而,我们继续匹配$1括号之外的部分。在替代字符串中它们并不出现,所以结果就是它们被删掉了。在本例中,“要删掉”的文本就是任何多余的数字,也就是正则表达式中末尾的「\d*」匹配的部分。
到现在看起来一切正常,但是,如果$price的数据本身规范格式,会出现什么问题呢?如果$price是27.625,那么「\.\d\d[1-9]?」能够匹配整个小数部分。因为「\d*」无法匹配任何字符,整个替换就是用‘.625’替换‘.625’——相当于白费工夫。
结果当然是我们需要的,但是否存在更有效率的办法,只进行真正必要的替换(也就是,只有当「\d*」确实能够匹配到某些字符的时候才替换)呢?当然,我们知道怎样表示“至少一位数字”!只要把「\d*」替换为「\d+」就好了:
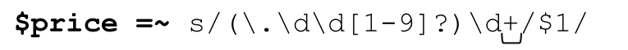
对于“1.62500000002828”这样复杂的数字,正则表达式仍然有效;但是对于“9.43”这种数字,末尾的「\d+」不能匹配,所以不会替换。所以,这是个了不起的改动,对吗?不!如果要处理的数字是27.625,情况如何呢?我们希望这个数字能够被忽略,但是这不会发生。请仔细想想27.625的匹配过程,尤其是表达式如何处理‘5’这个数字。
知道答案之后,这个问题就变得非常简单了。在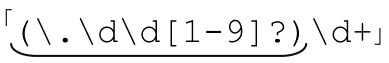 匹配
匹配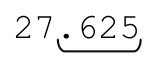 之后,「\d+」无法匹配。但这并不会影响整个表达式的匹配,因为就正则表达式而言,由「[1-9]」匹配‘5’只是可选的分支之一,还有一个备用状态尚未尝试。它容许「[1-9]?」匹配一个空字符,而把5留给至少必须匹配一个字符的「\d+」。于是,我们得到的是错误的结果:.625被替换成了.62。
之后,「\d+」无法匹配。但这并不会影响整个表达式的匹配,因为就正则表达式而言,由「[1-9]」匹配‘5’只是可选的分支之一,还有一个备用状态尚未尝试。它容许「[1-9]?」匹配一个空字符,而把5留给至少必须匹配一个字符的「\d+」。于是,我们得到的是错误的结果:.625被替换成了.62。
如果「[1-9]?」是忽略优先的又如何呢?我们会得到同样的匹配结果,但不会有“先匹配 5再回溯”的过程,因为忽略优先的「[1-9]??」首先会忽略尝试匹配的选项。所以,忽略优先量词并不能解决这个问题。
匹配优先、忽略优先和回溯的要旨
The Essence of Greediness,Laziness,and Backtracking
之前的章节告诉我们,正则表达式中的某个元素,无论是匹配优先,还是忽略优先,都是为全局匹配服务的,在这一点上(对前面的例子来说)它们没有区别。如果全局匹配需要,无论是匹配优先(或是忽略优先),在遇到“本地匹配失败”时,引擎都会回归到备用状态(按照足迹返回找到面包屑),然后尝试尚未尝试的路径。无论匹配优先还是忽略优先,只要引擎报告匹配失败,它就必然尝试了所有的可能。
测试路径的先后顺序,在匹配优先和忽略优先的情况下是不同的(这就是两者存在的理由),但是,只有在测试完所有可能的路径之后,才会最终报告匹配失败。
相反,如果只有一条可能的路径,那么使用匹配优先量词和忽略优先量词的正则表达式都能找到这个结果,只是他们尝试路径的次序不同。在这种情况下,选择匹配优先还是忽略优先,并不会影响匹配的结果,受影响的只是引擎在达到最终匹配之前需要尝试的次数(这是关于效率的问题,第6章将会谈到)。
最后,如果存在不止一个可能的匹配结果,那么理解匹配优先、忽略优先和回溯的读者,就明白应该如何选择。「".*"」有3个可能的匹配结果:
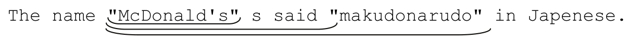
我们知道,使用匹配优先星号的「".*"」匹配最长的结果,而使用忽略优先星号的「".*?"」匹配最短的结果。
占有优先量词和固化分组
Possessive Quantifiers and Atomic Grouping
上一页中‘.625’的例子展示了关于NFA匹配的重要知识,也让我们认识到,针对这个具体的例子,考虑不仔细就会带来问题。针对某些流派提供了工具来帮助我们,但是在接触它们以前,必须彻底弄明白“匹配优先、忽略优先和回溯的要旨”这一节。如果读者还有不明白的地方,请务必仔细阅读上一节。
那么,仍然来考虑‘.625’的例子,想想我们真正的目的。我们知道,如果匹配能够进行到「(\.\d\d[1-9]?)☞\d+」中标记的位置,我们就不希望进行回溯。也就是说,我们希望的是,如果可能,「[1-9]」能够一个字符,果真如此的话,我们不希望交还这个字符。或者说的更直白一些就是,如果需要的话,我们希望在「[1-9]」匹配的字符交还之前,整个表达式就匹配失败。(这个正则表达式匹配‘.625’时的问题在于,它不会匹配失败,而是进行回溯,尝试其他备用状态)。
那么,如果我们能够避免这些备用状态呢(也就是在[1-9]进行尝试之前,放弃「?」保存的状态,)?如果没有退路,「[1-9]」的匹配就不会交还。而这就是我们需要的!但是,如果没有了这个备用状态会发生什么?如果我们用这个表达式来匹配‘.5000’呢?此时「[1-9]」不能匹配,就确实需要回溯,放弃「[1-9]」,让之后的「\d+」能够匹配需要删除的数字。
听起来,我们有两种相反的要求,但是仔细考虑考虑就会发现,我们真正需要的是,只有在某个可选元素已经匹配成功的情况下才抛弃此元素的“忽略”状态。也就是说,如果「[1-9]」能够成功匹配,就必须抛弃对应的备用状态,这样就永远也不会回退。如果正则表达式的流派支持固化分组「(?>…)」(☞139),或者占有优先量词「[1-9]?+」(☞142),就可以这么做。首先来看固化分组。
用(?>…)实现固化分组
具体来说,使用「(?>…)」的匹配与正常的匹配并无差别,但是如果匹配进行到此结构之后(也就是,进行到闭括号之后),那么此结构体中的所有备用状态都会被放弃。也就是说,在固化分组匹配结束时,它已经匹配的文本已经固化为一个单元,只能作为整体而保留或放弃。括号内的子表达式中未尝试过的备用状态都不复存在了,所以回溯永远也不能选择其中的状态(至少是,当此结构匹配完成时,“锁定(locked in)”在其中的状态)。
所以,让我们来看「(\.\d\d(?>[1-9]?))\d+」。在固化分组内,量词能够正常工作,所以如果「[1-9]」不能匹配,正则表达式会返回「?」留下的备用状态。然后匹配脱离固化分组,继续前进到「\d+」。在这种情况下,当控制权离开固化分组时,没有备用状态需要放弃(因为在固化分组中没有创建任何备用状态)。
如果「[1-9]」能够匹配,匹配脱离固化分组之后,「?」保存的备用状态仍然存在。但是,因为它属于已经结束的固化分组,所以会被抛弃。匹配‘.625’或者‘.625000’时就会发生这种情况。在后一种情况下,放弃那些状态不会带来任何麻烦,因为「\d+」匹配的是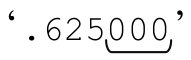 ,到这里正则表达式已经完成匹配。但是对于‘.625’来说,因为「\d+」无法匹配,正则引擎需要回溯,但回溯又无法进行,因为备用状态已经不存在了。既然没有能够回溯的备用状态,整体匹配也就失败,‘.625’不需要处理,而这正是我们期望的。
,到这里正则表达式已经完成匹配。但是对于‘.625’来说,因为「\d+」无法匹配,正则引擎需要回溯,但回溯又无法进行,因为备用状态已经不存在了。既然没有能够回溯的备用状态,整体匹配也就失败,‘.625’不需要处理,而这正是我们期望的。
固化分组的要旨
从第168页开始的“匹配优先、忽略优先和回溯的要旨”这一节,说明了一个重要的事实,即匹配优先和忽略优先都不会影响需要检测路径的本身,而只会影响检测的顺序。如果不能匹配,无论是按照匹配优先还是忽略优先的顺序,最终每条路径都会被测试。
然而,固化分组与它们截然不同,因为固化分组会放弃某些可能的路径。根据具体情况的不同,放弃备用状态可能会导致不同的结果:
●毫无影响 如果在使用备用状态之前能够完成匹配,固化分组就不会影响匹配。我们刚刚看过‘.625000’的匹配。全局匹配在备用状态尚未起作用之前就已经完成。
●导致匹配失败 放弃备用状态可能意味着,本来有可能成功的匹配现在不可能成功了。‘6.25’的例子就是如此。
●改变匹配结果 在某些情况下,放弃备用状态可能得到不同的匹配结果。
●加快报告匹配失败的速度 如果不能找到匹配对象,放弃备用状态可能能让正则引擎更快地报告匹配失败。先做个小测验,然后我们来谈这点。
ϖ 小测验:「(?>.*?)」是什么意思?它能匹配什么文本?请翻到下页查看答案。
某些状态可能保留 在匹配过程中,引擎退出固化分组时,放弃的只是固化分组中创建的状态。而之前创建的状态依然保留,所以,如果后来的回溯要求退回到之前的备用状态,固化分组部分匹配的文本会全部交还。
使用固化分组加快匹配失败的速度 我们一眼就能看出,「^\w+:」无法匹配‘Subject’,因为‘Subject’中不含冒号,但正则引擎必须经过尝试才能得到这个结论。
第一次检查「:」时,「\w+」已经匹配到了字符串的结尾,保存了若干状态——「\w」匹配的每个字符,都对应有“忽略”的备用状态(第一个除外,因为加号要求至少匹配一次)。「:」无法匹配字符串的末尾,所以正则引擎会回溯到最近的备用状态:
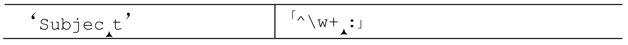
此处的字符是‘t’,「:」仍然无法匹配。于是回溯-测试-失败的循环会不断发生,最终退回开始的状态:
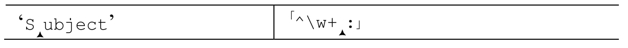
此处仍然无法匹配成功,所以报告整个表达式无法匹配。

我们只消看一眼就能知道,所有的回溯都是白费工夫。如果冒号无法匹配最后的字符,那么它当然无法匹配「+」交还的任何字符。
既然我们知道,「\w+」匹配结束之后,从任何备用状态开始测试都不能得到全局匹配,就可以命令正则引擎不必检查它们:「^(?>\w+)」。我们已经全面了解了正则表达式的匹配过程,可以使用固化分组来控制「\w+」的匹配,放弃备用的状态(因为我们知道它们没有用),提高效率。如果存在可以匹配的文本,那么固化分组不会有任何影响,但是如果不存在能够匹配的文本,放弃这些无用的状态会让正则引擎更快地得出无法匹配的结论(先进的实现也许能够自动进行这样的优化,☞251)。
我们将在第6章看到(第269页),固化分组非常有价值,我怀疑它可能会成为最常用的技巧。
占有优先量词,?+、*+、++和{m,n}+
Possessive Quantifiers,?+,++,++,and{m,n}+
占有优先量词与匹配优先量词很相似,只是它们从来不交还已经匹配的字符。我们在「^\w+」的例子中看到,加号在匹配结束之前创建了很少的备用状态,而占有优先的加号会直接放弃这些状态(或者,更形象地说,并不会创造这些状态)。
你也许会想,占有优先量词和固化分组关系非常紧密。像「\w++」这样的占有优先量词与「(?>\w+)」的匹配结果完全相同,只是写起来更加方便而已(注 7)。使用占有优先量词,「^(?>\w+):」可以写作「^\w++:」,「(\.\d\d(?>[1-9]?))\d+」写做「(\.\d\d[1-9]?+)^\d+」。请务必区分「(?>M)+」和「(?M+)」。前者放弃「M」创建的备用状态,因为「M」不会制造任何状态,所以这样做没什么价值。而后者放弃「M+」创造的未使用状态,这样做显然有意义。
比较「(?>M)+」和「(?>M+)」,显然后者就对应于「M++」,但如果表达式很复杂,例如「(\\"|[^"])*+」,从占有优先量词转换为固化分组时大家往往会想到在括号中添加‘?>’得到「 (?>\\"|[^"])*」。这个表达式或许有机会实现你的目的,但它显然不等于那个使用占有优先量词的表达式;它就好像是把「M++」写作「(?>M)+」一样。正确的办法是,去掉表示占有优先的加号,用固化分组把余下的部分包括起来:「(?>(\\"|[^"])*)」。
环视中的回溯
The Backtracking of Lookaround
初看时并不容易认识到,环视(见第 2 章,☞59)与固化分组和占有优先量词有紧密的联系。环视分为 4 种:肯定型(positive)和否定型(negative),顺序环视与逆序环视。它们只是简单地测试,其中表达式能否在当前位置匹配后面的文本(顺序环视),或者前面的文本(逆序环视)。
深入点看,在NFA的世界中包含了备用状态和回溯,环视是怎么实现的?环视结构中的子表达式有自己的世界。它也会保存备用状态,进行必要的回溯。如果整个子表达式能够成功匹配,结果如何呢?肯定型环视会认为自己匹配成功;而否定环视会认为匹配失败。在任何一种情况下,因为关注的只是匹配存在与否(在刚才的例子中,的确存在匹配),此匹配尝试所在的“世界”,包括在尝试中创造的所有备用状态,都会被放弃。
如果环视中的子表达式无法匹配,结果如何呢?因为它只应用到这个“世界”中,所以回溯时只能选择当前环视结构中的备用状态。也就是说,如果正则表达式发现,需要进一步回溯到当前的环视结构的起点以前,它就认为当前的子表达式无法匹配。对肯定型环视来说,这就意味着失败,而对于否定型环视来说,这意味着成功。在任何一种情况下,都没有保留备用状态(如果有,那么子表达式的匹配尝试就没有结束),自然也谈不上放弃。
所以我们知道,只要环视结构的匹配尝试结束,它就不会留下任何备用状态。任何备用状态和例子中肯定环视成功时的情况一样,都会被放弃。我们在其他什么地方看到过放弃状态?当然是固化分组和占有优先量词。
用肯定环视模拟固化分组
如果流派本身支持固化分组,这么做可能有点多此一举,但如果流派不支持固化分组,这么做就很有用:如果所使用的工具支持肯定环视,同时可以在肯定环视中使用捕获括号(大多数风格都支持,但也有些不支持,Tcl 就是如此),就能模拟实现固化分组和占有优先量词。「(?>regex)」可以用「(?=(regex))\1」来模拟。举例来说,比较「(?>\w+):」和「^(?=(\w+))\1:」。
环视中的「\w+」是匹配优先的,它会匹配尽可能多的字符,也就是整个单词。因为它在环视结构中,当环视结束之后,备用状态都会放弃(和固化分组一样)。但与固化分组不一样的是,虽然此时确实捕获了这个单词,但它不是全局匹配的一部分(这就是环视的意义)。这里的关键就是,后面的「\1」捕获的就是环视结构捕获的单词,而这当然会匹配成功。在这里使用「\1」并非多此一举,而是为了把匹配从这个单词结束的位置进行下去。
这个技巧比真正的固化分组要慢一些,因为需要额外的时间来重新匹配「\1」的文本。不过,因为环视结构可以放弃备用状态,如果冒号无法匹配,它的失败会来得更快一些。
多选结构也是匹配优先的吗
Is Alternation Greedy?
多选分支的工作原理非常重要,因为在不同的正则引擎中它们是迥然不同的。如果遇到的多个多选分支都能够匹配,究竟会选择哪一个呢?或者说,如果不只一个多选分支能够匹配,最后究竟应该选择哪一个呢?如果选择的是匹配文本最长的多选分支,有人也许会说多选结构也是匹配优先的;如果选择的是匹配文本最短的多选分支,有人也许会说它是忽略优先的?那么(如果只能是一个的话)究竟是哪个?
让我们看看Perl、PHP、Java、.NET以及其他语言使用的传统型NFA引擎。遇到多选结构时,这种引擎会按照从左到右的顺序检查表达式中的多选分支。拿正则表达式「^(Subject|Date):·」来说,遇到「Subject|Date」时,首先尝试的是「Subject」。如果能够匹配,就转而处理接下来的部分(也就是后面的「:·」)。如果无法匹配,而此时又有其他多选分支(就是例子中的「Date」),正则引擎会回溯来尝试它。这个例子同样说明,正则引擎会回溯到存在尚未尝试的多选分支的地方。这个过程会不断重复,直到完成全局匹配,或者所有的分支(也就是本例中的所有多选分支)都尝试穷尽为止。
所以,对于常见的传统型NFA引擎,用「tour|to|tournament」来匹配‘three·tournaments· won’时,会得到什么结果呢?在尝试到‘three·☞tournaments·won’时,在每个位置进行的匹配尝试都会失败,而且每次尝试时,都会检查所有的多选分支(并且失败)。而在这个位置,第一个多选分支「tour」能够匹配。因为这个多选结构是正则表达式中的最后部分,「tour」匹配结束也就意味着整个表达式匹配完成。其他的多选分支就不会尝试了。
因此我们知道,多选结构既不是匹配优先的,也不是忽略优先的,而是按顺序排列的,至少对传统型NFA来说是如此。这比匹配优先的多选结构更有用,因为这样我们能够对匹配的过程进行更多的控制——正则表达式的使用者可以用它下令:“先试这个,再试那个,最后试另一个,直到试出结果为止”。
不过,也不是所有的流派都支持按序排列的多选结构。DFA和POSIX NFA确实有匹配优先的多选结构,它们总是匹配所有多选分支中能匹配最多文本的那个(也就是本例中的「tournament」)。但是,如果你使用的是Perl、PHP、.NET、java.util.regex,或者其他使用传统型NFA的工具,多选结构就是按序排列的。
发掘有序多选结构的价值
Taking Advantage of Ordered Alternation
回过头来看第167页「(\.\d\d[1-9]?)\d*」的例子。如果我们明白,「\.\d\d[1-9]?」其实等于「\.\d\d」或者「\.\d\d[1-9]」,我们就可以把整个表达式重新写作「(\.\d\d|\.\d\d[1-9])\d*」。(这并非必须的改动,只是举例说明)。这个表达式与之前的完全一样吗?如果多选结构是匹配优先的,那么答案就是肯定的,但如果多选结构是有序的,两者就完全不一样。
我们来看多选结构有序的情形。首先选择和测试的是第一个多选分支,如果能够匹配,控制权就转移到紧接的「\d*」那里。如果还有其他的数字,「\d*」能够匹配它们,也就是任何不为零的数字,它们是原来问题的根源(如果读者还记得,当时的问题就在于,这位数字我们只希望在括号里匹配,而不通过括号外面的「\d*」)。所以,如果第一个多选分支无法匹配,第二个多选分支同样无法匹配,因为二者的开头是一样的。即使第一个多选结构无法匹配,正则引擎仍然会对第二个多选分支进行徒劳的尝试。
不过,如果交换多选分支的顺序,变成「(\.\d\d[1-9]|\.\d\d)\d*」,它就等价于匹配优先的「(\.\d\d[1-9]?)\d*」。如果第一个多选分支结尾的「[1-9]」匹配失败,第二个多选分支仍然有机会成功。我们使用的仍然是有序排列的多选结构,但是通过变换顺序,实现了匹配优先的功能。
第一次拆分「[1-9]?」成两个多选分支时,我们把较短的分支放在了前面,得到了一个不具备匹配优先功能的「?」。在这个具体的例子中,这么做没有意义,因为如果第一个多选分支不能匹配,第二个肯定也无法匹配。我经常看到这样没有意义的多选结构,对传统型 NFA来说,这肯定不对。我曾看到有一本书以「a((ab)*|b*)」为例讲解传统型NFA 正则表达式的括号。这个例子显然没有意义,因为第一个多选分支「(ab)*」永远也不会匹配失败,所以后面的其他多选分支毫无意义。你可以继续添加:

这个正则表达式的意义都不会有丝毫的改变。要记住的是,如果多选分支是有序的,而能够匹配同样文本的多选分支又不只一个,就要小心安排多选分支的先后顺序。
有序多选结构的陷阱
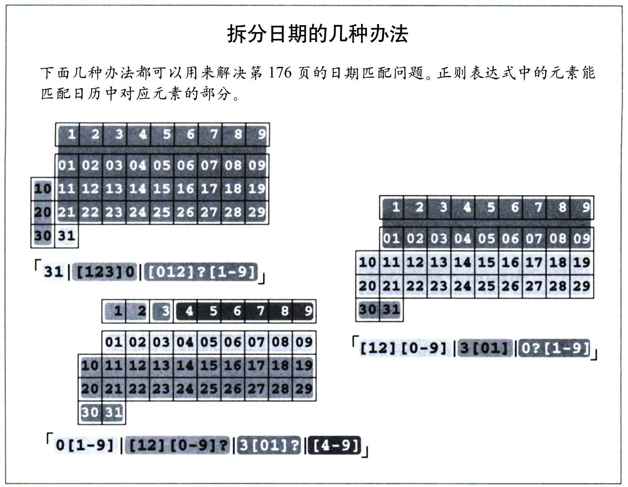
有序多选分支容许使用者控制期望的匹配,因此极为便利,但也会给不明就里的人造成麻烦。如果需要匹配‘Jan 31’之类的日期,我们需要的就不是简单的「Jan·[0123][0-9]」,因为这样的表达式能够匹配‘Jan·00’和‘Jan·39’这样的日期,却无法匹配‘Jan·7’。
一种办法是把日期部分拆开。用「0?[1-9]」匹配可能以0开头的前九天的日期。用「[12][0-9]」处理十号到二十九号,用「3[01]」处理最后两天。把上面这些连起来,就是「Jan· (0?[1-9]|[12][0-9]|3[01])」。
如果用这个表达式来匹配‘Jan 31 is Dad's birthday’,结果如何呢?我们希望获得的当然是‘Jan 31’,但是有序多选分支只会捕获‘Jan 3’。奇怪吗?在匹配第一个多选分支「0?[1-9]」时,前面的「0?」无法匹配,但是这个多选分支仍然能够匹配成功,因为「[1-9]」能够匹配‘3’。因为此多选分支位于正则表达式的末尾,所以匹配到此完成。
如果我们重新安排多选结构的顺序环视,把能够匹配的数字最短的放到最后,这个问题就解决了:「Jan·([12][0-9]|3[01]|0?[1-9])」。
另一种办法是使用「Jan·(31|[123]0|[012]?[1-9])」。但这也要求我们仔细地安排多选分支的顺序避免问题。还有一种办法是「Jan·(0[1-9]|[12][0-9]?|3[01]?|[4-9])」,这样不论顺序环视如何都能获得正确结果。比较和分析这 3 个不同的表达式,会有很多发现(我会给读者一些时间来想这个问题,尽管下一页的补充内容会有所帮助)。