A Few Short Examples
匹配连续行(续前)
Continuing with Continuation Lines
继续前一章中匹配连续行的例子(☞178),我们发现(在传统型NFA中使用「^\w+=.*(\\\n.*)*」并不能匹配下面的两行文本:

问题在于,第一个「.*」一直匹配到反斜线之后,这样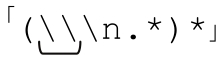 就不能按照预期匹配反斜线了。所以,本章出现的第一条经验就是:如果不需要点号匹配反斜线,就应该在正则表达式中做这样的规定。我们可以把每个点号替换成「[^\n\\]」(请注意,\n包含在排除性字符组中。你应该记得,原来的正则表达式的假设之一就是,点号不会匹配换行符,我们也不希望它的替代品能够匹配换行符☞119页)。
就不能按照预期匹配反斜线了。所以,本章出现的第一条经验就是:如果不需要点号匹配反斜线,就应该在正则表达式中做这样的规定。我们可以把每个点号替换成「[^\n\\]」(请注意,\n包含在排除性字符组中。你应该记得,原来的正则表达式的假设之一就是,点号不会匹配换行符,我们也不希望它的替代品能够匹配换行符☞119页)。
于是,我们得到:
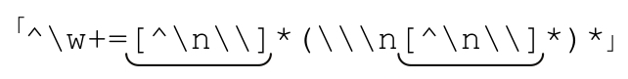
它确实能够匹配连续行,但因此也产生了一个新的问题:这样反斜线就不能出现在一行的非结尾位置。如果需要匹配的文本中包含其他的反斜线,这个正则表达式就会出问题。现在我们假设它会包含,所以需要继续改进正则表达式。
迄今为止,我们的思路都是,“匹配一行,如果还有连续行,就继续匹配”。现在换另一种思路,这种思路我觉得通常都会奏效:集中关注在特定时刻真正容许匹配的字符。在匹配一行文本时,我们期望匹配的要么是普通(除反斜线和换行符之外)字符,要么是反斜线与其他任何字符的结合体。在点号通配模式中,「\\.」能匹配反斜线加换行符的结合体。
所以,正则表达式就变成了「^\w+=([^\n\\]|\\.)*」,在点号通配模式下。因为开头是「^」,如果需要,可能得使用增强的文本行锚点匹配模式(☞112)。
但是,这个答案仍然不够完美——我们会在下一章讲解效率问题时再次看到它(☞270)。
匹配IP地址
Matching an IP Address
来看个复杂点的例子,匹配一个IP(Internet Protocol,因特网协议)地址:用点号分开的四个数,例如1.2.3.4。通常情况下,每个数都有三位,例如001.002.003.004。你可能会想到用「[0-9]*\.[0-9]*\.[0-9]*\.[0-9]*」从文本中提取一个IP地址,但是这个表达式显然不够精致,它甚至会匹配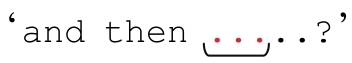 ’。仔细看看就会发现,这个表达式甚至不需要匹配任何数字——它只需要三个点号(当然也可能包括其间的数字)。
’。仔细看看就会发现,这个表达式甚至不需要匹配任何数字——它只需要三个点号(当然也可能包括其间的数字)。
为解决这个问题,我们首先把星号改成加号,因为我们知道,每一段必须有至少一位数字。为确保整个字符串的内容就是一个IP地址,我们可以在首尾加上「^...$」,于是我们得到:
「^[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+$」
如果用「\d」替换「[0-9]」,就得到「^\d+\.\d+\.\d+\.\d+$」,这样可能更好看一些(注1),但是,这个表达式仍然会捕获一些并非IP地址的数据,例如‘1234.5678.9101112.131415’(IP地址的每个字段都在0-255以内)。那么,你可以强行规定每个字段必须包含三位数字,就是「^\d\d\d\.\d\d\d\.\d\d\d\.\d\d\d$」,但这样未免太不灵活(too specific)了。即使某个字段只有一位或者两位数字(例如 1.234.5.67),也应该匹配。如果流派支持区间量词{min,max},就可以这么写「^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}$」。如果不支持,则可以用「\d\d?\d?」或者「\d(\d\d?)?」。这两种方式略有不同,但都能匹配一到三个数字。
现在,正则表达式中的匹配精度可能已经满足需求了。如果要更精确,就必须考虑到,「\d{1,3}」能够匹配999,而它超过了255,所以它不是一个合法的IP地址。
我们有好几种办法来匹配0和255之间的数字。最笨的办法就是「0|1|2|3|…253|254|255」。不过这又不能处理以0开头的数字,所以必须写成「0|00|000|1|01|001…」,这样一来,正则表达式就长得过分了。对于DFA引擎来说,问题还只是它太长太繁杂——但匹配的速度与其他等价正则表达式是一样的。但对于NFA引擎,太多的多选分支简直就是效率杀手。
实际的解决办法是,关注字段中什么位置可以出现哪些数字。如果一个字段只包含一个或者两个数字,就无需担心这个字段的值是否合法,所以「\d|\d\d」就能应付。也不比担心那些以0或者1开头的三位数,因为000-199都是合法的IP地址。所以我们加上「[01]\d\d」,得到「\d|\d\d|[01]\d\d」。你可能觉得这有点像第1章里匹配时间的例子(☞28),和前一章中匹配日期的例子(☞177)。
继续看这个正则表达式,以 2开头的三位数字,如果小于 255就是合法的,所以第二位数字小于5就代表整个数也是合法的。如果第二位数字是5,第三位数字就必须小于6。这可以表示为「2[0-4]\d|25[0-5]」。
现在这个正则表达式有点看不懂了,但分析之后还是能够理解其中包含的思路。结果就是「\d|\d\d|[01]\d\d|2[0-4]\d|25[0-5]」。其实我们可以合并前面三个多选分支,得到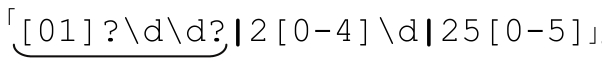 。在NFA中,这样做的效率更高,因为任何多选分支匹配失败都会导致回溯。请注意,第一个多选分支中用的是「\d\d?」,而不是「\d?\d」,这样,如果根本不存在数字,NFA 会更快地报告匹配失败。我把这个问题的分析留给读者——通过一个简单的验证就能发现二者的区别。我们还可以做些修改进一步提高这个表达式的效率,不过这要留待下一章讨论了。
。在NFA中,这样做的效率更高,因为任何多选分支匹配失败都会导致回溯。请注意,第一个多选分支中用的是「\d\d?」,而不是「\d?\d」,这样,如果根本不存在数字,NFA 会更快地报告匹配失败。我把这个问题的分析留给读者——通过一个简单的验证就能发现二者的区别。我们还可以做些修改进一步提高这个表达式的效率,不过这要留待下一章讨论了。
现在这个表达式能够匹配0 到255 之间的数,我们用括号把它包起来,用来取代之前表达式中的「\d{1,3}」,就得到:
「^([01]?\d\d?|2[0-4]\d|25[0-5])\.([01]?\d\d?|2[0-4]\d|25[0-5])\.([01]?\d\d?|2[0-4]\d|25[0-5])\.([01]?\d\d?|2[0-4]\d|25[0-5])$」
这可真叫复杂!需要这么麻烦吗?这得根据具体需求来决定。这个表达式只会匹配合法的IP地址,但是它也会匹配一些语意不正确的IP地址,例如0.0.0.0(所有字段都为零的IP地址是非法的)。使用环视功能(☞133)可以在「^」后添加「(?!0+\.0+\.0+\.0+$)」,但是某些时候,处理各种极端情形会降低成本/收益的比例。某些情况下,更合适的做法就是不依赖正则表达式完成全部工作。例如,你可以只使用「^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}$」,用括号把每个字段括起来,把数字变成程序中的$1、$2、$3、$4,这样就可以用其他程序来验证了。
确定应用场合(context)
这个正则表达式必须借助锚点「^」和「$」才能正常工作,认识到这一点很重要。否则,它就可能匹配 ,如果使用传统型NFA,则可能匹配
,如果使用传统型NFA,则可能匹配 。
。
在第二个例子中,这个表达式甚至连最后的 223 都无法完整匹配。但是,问题并不在于表达式本身,因为没有东西(例如分隔符,或者末尾的锚点)强迫它匹配223。最后那个分组的第一个多选分支「[01]?\d\d?」,匹配了前面两位数字,如果末尾没有「$」,匹配到此就结束了。在前一章日期匹配的例子中,我们可以安排多选分支的次序来达到期望的目的。现在我们也把能把匹配三位数字的多选分支放在最前面,这样在匹配两位数的多选分支获得尝试机会之前,任何三位数都能完全匹配(DFA和POSIX NFA当然不需要这样安排,因为它们总是返回最长的匹配文本)。
无论是否重新排序,第一个错误仍然不可避免。“啊哈!”,你可能会想,“我可以用单词分界符锚点来解决这个问题。”不幸的是,这也不能奏效,因为这样的正则表达式仍然能够匹配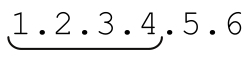 。为了避免匹配这样内嵌的文本,我们必须确保匹配文本两侧至少没有数字或者点号。如果使用环视,可以在原来表达式的首尾添加「(?<![\w.])…(?![\w.])」来保证匹配文本之前(以及之后)不出现「[\w.]」能匹配的字符。如果不支持环视,在首尾添加「(^|·)…(·|$)」也能够应付某些情况。
。为了避免匹配这样内嵌的文本,我们必须确保匹配文本两侧至少没有数字或者点号。如果使用环视,可以在原来表达式的首尾添加「(?<![\w.])…(?![\w.])」来保证匹配文本之前(以及之后)不出现「[\w.]」能匹配的字符。如果不支持环视,在首尾添加「(^|·)…(·|$)」也能够应付某些情况。
处理文件名
Working with Filenames
处理文件名和路径,例如 Unix 下的/usr/local/bin/Perl 或者 Windows 下的\Program Files\Yahoo!\Messenger,很适合用来讲解正则表达式的应用。因为“动手(using)”比“观摩(reading)”更有意思,我会同时用Perl、PHP(preg程序)、Java和VB.NET来讲解。如果你对其中的某些语言不感兴趣,不妨完全跳过那些代码——其中蕴含的思想才是最重要的。
去掉文件名开头的路径
第一个例子是去掉文件名开始的路径,例如把/usr/local/bin/gcc变成gcc。从本质层面来考虑问题是成功的一半。在本例中,我们希望去掉在最后的斜线(含)之前(在Windows中是反斜线)的任何字符。如果没有斜线最好,因为什么也不用干。我曾说过,「.* 」常常被滥用,但是此处我们需要匹配优先的特性。「^.*/」中的「.*」可以匹配一整行,然后回退(也就是回溯)到最后的斜线,来完成匹配。
下面是四种语言的代码,去掉变量f中的文件名中开头的路径。对于Unix的文件名:

正则表达式(或者说用来表示正则表达式的字符串)以下画线标注,正则表达式相关的组件则由粗体标注。
下面是处理Windows文件名的代码,Windows中的分隔符是反斜线而不是斜线,所以要用正则表达式「^.*\\」。在正则表达式中,我们需要在反斜线前再加一个反斜线,才能表示转义的反斜线,不过,在中间两段程序中添加的这个反斜线本身也需要转义:

从中很容易看出各种语言的差异,尤其是Java中那4个反斜线(☞101)。
有一点请务必记住:别忘了时常想想匹配失败的情形。在本例中,匹配失败意味着字符串中没有斜线,所以不会替换,字符串也不会变化,而这正是我们需要的。
为了保证效率,我们需要记住NFA引擎的工作原理。设想下面这种情况:我们忘记在正则表达式的开头添加「^」符号(这个符号很容易忘记),用来匹配一个恰好没有斜线的字符串。同样,正则引擎会在字符串的起始位置开始搜索。「.* 」抵达字符串的末尾,但必须不断回退,以找到斜线或者反斜线。直到最后它交还了匹配的所有字符,仍然无法匹配。所以,正则引擎知道,在字符串的起始位置不存在匹配,但这远远没有结束。
接下来传动装置开始工作,从在目标字符串的第 2 个字符开始,依次尝试匹配整个正则表达式。事实上,它需要在字符串的每个位置(从理论上说)进行扫描-回溯。文件名通常很短,因此这不是一个问题,但原理确实如此。如果字符串很长,就可能存在大量的回溯(当然,DFA不存在这个问题)。
在实践中,经过合理优化的传动装置能够认识到,对几乎所有以「.*」开头的正则表达式来说,如果在某个字符串的起始位置不能匹配,也就不能在其他任何位置匹配,所以它只会在字符串的起始位置(☞246)尝试一次。不过,在正则表达式中写明这一点更加明智,在例子中我们正是这样做的。
从路径中获取文件名
另一种办法是忽略路径,简单地匹配最后的文件名部分。最终的文件名就是从最后一个斜线开始的所有内容:「[^/]*$」。这一次,锚点不仅仅是一种优化措施,我们确实需要在结尾设置一个锚点。现在我们可以这样做,以Perl来说明:

你也许注意到了,这里并没有检查这个正则表达式能否匹配,因为它总是能匹配。这个表达式的唯一要求就是,字符串有$能够匹配的结束位置,而即使是空字符串也有一个结束位置。因此,我用$1来引用括号内的表达式匹配的文本,因为它必定包括某些字符(如果文件名以斜线结尾,结果就是空字符)。
这里还需要考虑到效率:在NFA中,「[^/]*$」的效率很低。仔细想想NFA引擎的匹配过程,你会明白它包括了太多的回溯。即使是短短的‘/usr/local/bin/perl’,在获得匹配结果之前,也要进行四十多次回溯。考虑从 开始的尝试。「[^/]*」一直匹配到第二个l,之后匹配失败,然后对l、a、c、o、l的存储状态依次尝试「$」(都无法匹配)。如果这还不够,又会从
开始的尝试。「[^/]*」一直匹配到第二个l,之后匹配失败,然后对l、a、c、o、l的存储状态依次尝试「$」(都无法匹配)。如果这还不够,又会从 开始重复这个过程,接着从
开始重复这个过程,接着从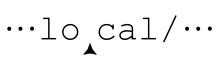 开始,不断重复。
开始,不断重复。
这个例子不应该消耗我们太多的精力,因为文件名一般都很短(40 次回溯几乎可以忽略不计——4 000万次回溯才真正要紧)。再一次,重要的是理解问题本身,这样才能选择合适的通用规则来解决具体的问题。
需要指出的是,纵然本书是关于正则表达式的,但正则表达式也不总是最优解。例如,大多数程序设计语言都提供了处理文件名的非正则表达式函数。不过为了讲解正则表达式,我仍会继续下去。
所在路径和文件名
下一步是把完整的路径分为所在路径和文件名两部分。有许多办法做到这一点,这取决于我们的要求。开始,你可能想要用「^(.*)/(.*)$」的$1和$2来提取这两者。看起来这个正则表达式非常直观,但知道了匹配优先量词的工作原理之后,我们知道第一个「.*」会首先捕获所有的文本,而不给「/」和$2留下任何字符。第一个「.*」能交还字符的唯一原因,就是在尝试匹配「/(.*)$」时进行的回溯。这会把“交还的”部分留给后面的「.*」。因此,$1 就是文件所在的路径,$2就是文件的名字。
需要注意的是,我们依靠开头的「(.*)/」来确保第二个「(.*)」不会匹配任何斜线。理解匹配优先之后,我们知道这没问题。如果要做的更精确,可以使用「[^/]*」来捕捉文件名。于是我们得到「^(.*)/([^/]*)$」。这个表达式准确地表达了我们的意图,一眼就能看明白。
这个表达式有个问题,它要求字符串中必须出现一个斜线,如果我们用它来匹配file.txt,因为无法匹配,所以没有结果。如果我们希望精益求精,可以这样:

匹配对称的括号
Matching Balanced Sets of Parentheses
对称的圆括号、方括号之类的符号匹配起来非常麻烦。在处理配置文件和源代码时,经常需要匹配对称的括号。例如,解析 C 语言代码时可能需要处理某个函数的所有参数。函数的参数包含在函数名称之后的括号里,而这些参数本身又有可能包含嵌套的函数调用或是算式中的括号。我们先不考虑嵌套的括号,你或许会想到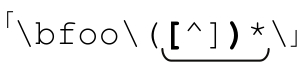 ,但这行不通。
,但这行不通。
秉承 C 的光荣传统,我把示范函数命名为 foo。表达式中的标记部分是用来捕获参数的。对于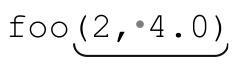 和
和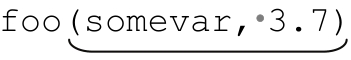 之类的参数,这个表达式完全没问题。但是,它也可以匹配
之类的参数,这个表达式完全没问题。但是,它也可以匹配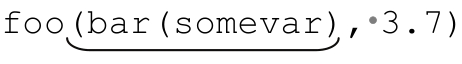 ,这可不是我们需要的。所以要用到比「[^)]*」更聪明的办法。
,这可不是我们需要的。所以要用到比「[^)]*」更聪明的办法。
为了匹配括号部分,我们可以尝试下面的这些正则表达式:
1.\(.*\)括号及括号内部的任何字符。
2.\([^)]*\)从一个开括号到最近的闭括号。
3.\([^()]*\)从一个开括号到最近的闭括号,但是不容许其中包含开括号。
图5-1显示了对一行简单代码应用这些表达式的结果。
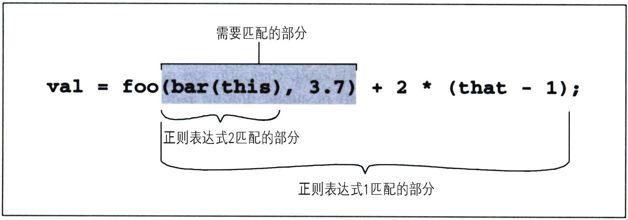
图5-1:三个表达式的匹配位置
我们看到,第一个正则表达式匹配的内容太多(注2),第二个正则表达式匹配的内容太少,第三个正则表达式无法匹配。孤立地看,第三个正则表达式能够匹配‘(this)’,但是因为表达式要求它必须紧接在foo之后,所以无法匹配。所以,这三个表达式都不合格。
真正的问题在于,大多数系统中,正则表达式无法匹配任意深度的嵌套结构。在很长的时间内,这是放之四海而皆准的规则,但是现在Perl、.NET和PCRE/PHP都提供了解决的办法(参见第328、436、475页)。但是,即使不用这些功能,我们也可以用正则表达式来匹配特定深度的嵌套括号,但不是任意深度的嵌套括号。处理单层嵌套的正则表达式是:
「\[^]*(\([^]*\)[^]*)*\)」
这样类推下去,更深层次的嵌套就复杂得可怕。但是,下面的 Perl 程序,在指定嵌套深度$depth之后,生成的正则表达式可以匹配最大深度为$depth的嵌套括号。它使用的是Perl的“string x count”运算符,这个运算符会把string重复count次:
$regex='\('.'(?:[^()]|\('x $depth.'[^()]*'.'\))*'x $depth.'\)';这个表达式留给读者分析。
防备不期望的匹配
Watching Out for Unwanted Matches
有个问题很容易忘记,即,如果待分析的文本不符合使用者的预期,会发生什么。假设你需要编写一个过滤程序,把普通文本转换为 HTML,你希望把一行连字符号转换为 HTML中代表一条水平线的<HR>。如果使用搜索-替换命令 s/-*/<HR>/,它能替换期望替换的文本,但只限于它们在行开头的情况。很奇怪吗?事实上,s/-*/<HR>/会把<HR>添加到每一行的开头,而无论这些行是否以连字符开头。
请记住,如果某个元素的匹配没有硬性规定任何必须出现的字符,那么它总能匹配成功。「-*」从字符串的起始位置开始尝试匹配,它会匹配可能的任何连字符。但是,如果没有连字符,它仍然能匹配成功,这完全符合星号的定义。
在某位我非常尊重的作者的作品中出现过类似的例子,他用这个例子来讲解正则表达式匹配一个数,或者是整数或者是浮点数。在它的正则表达式中,这个数可能以负数符号开头,然后是任意多个数字,然后是可能的小数点,再是任何多的数字。他的正则表达式是「-?[0-9]*\.?[0-9]*」。
确实,这个正则表达式可以匹配1、-272.37、129238843.、.191919,甚至是-.0这样的数。这样看来,它的确是个不错的正则表达式。
但是,你想过这个表达式如何匹配‘this·has·no·number’‘nothing·here’或是空字符串吗?仔细看看这个正则表达式——每一个部分都不是匹配必须的。如果存在一个数,如果正则表达式从在字符串的起始位置开始,的确能够匹配,但是因为匹配没有任何必须元素。此正则表达式可以匹配每个例子中字符串开头的空字符。实际上它甚至可以匹配‘num·123’开头的空字符,因为这个空字符比数字出现得更早。
所以,把真正意图表达清楚是非常重要的。一个浮点数必须要有至少一位数字,否则就不是一个合法的值。我们首先假设,在小数点之前至少有一位数字(之后我们会去掉这个条件)。如果是,我们需要用加号来控制这些数字「-?[0-9]+」。
如果要用正则表达式来匹配可能存在的小数点(及其后的数字),就必须认识到,小数部分必须紧接在小数点之后。如果我们简单地用「\.?[0-9]*」,那么无论小数点是否存在,「[0-9]*」都可能匹配。
解决的办法还是厘清我们的意图:小数点(以及之后的数字)是可能出现的:「(\.[0-9]*)?」。这里,问号限定(也可以叫“统治governs”或者“控制controls”)的不再是小数点,而是小数点和后面的小数部分。在这个结合体内部,小数点是必须出现的,如果没有小数点,「[0-9]*」根本谈不上匹配。
把它们结合起来,就得到「-?[0-9]+(\.[0-9]*)?」。这个表达式不能匹配‘.007’,因为它要求整数部分必须有一位数字。如果我们作些修改,容许整数部分为空,就必须同时修改小数部分,否则这个表达式就可以匹配空字符(这是我们一开始就准备解决的问题)。
解决的办法是为无法覆盖的情况添加多选分支: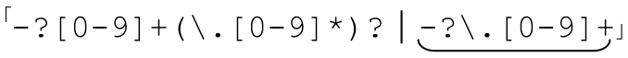 。这样就能匹配以小数点开头的小数(小数点是必须的)。仔细看看,仔细看看。你注意到了吗?第二个多选分支同样能够匹配负数符号开头的小数?这很容易忘记。当然,你也可以把「-?」提出来,放到所有多选结构的外面:「-?([0-9]+(\.[0-9]*)?|\.[0-9]+)」。
。这样就能匹配以小数点开头的小数(小数点是必须的)。仔细看看,仔细看看。你注意到了吗?第二个多选分支同样能够匹配负数符号开头的小数?这很容易忘记。当然,你也可以把「-?」提出来,放到所有多选结构的外面:「-?([0-9]+(\.[0-9]*)?|\.[0-9]+)」。
虽然这个表达式比最开始的好得多,但它仍然会匹配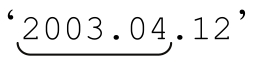 这样的数字。要想真正匹配期望的文本,同时忽略不期望的文本,求得平衡,就必须了解实际的待匹配文本。我们用来提取浮点数的正则表达式必须包含在一个大的正则表达式内部,例如用「^…$」或者「num\s*=\s*…$」。
这样的数字。要想真正匹配期望的文本,同时忽略不期望的文本,求得平衡,就必须了解实际的待匹配文本。我们用来提取浮点数的正则表达式必须包含在一个大的正则表达式内部,例如用「^…$」或者「num\s*=\s*…$」。
匹配分隔符之内的文本
Matching Delimited Text
匹配用分隔符(以某些字符表示)之类的文本是常见的任务,之前的匹配双引号内的文本和IP地址只是这类问题中的两个典型例子。其他的例子还包括:
●匹配‘/*’和‘*/’之间的C语言注释。
●匹配一个HTML tag,也就是尖括号之内的文本,例如<CODE>。
●提取HTML tag标注的文本,例如在HTML代码‘a<I>super exciting</I>offer!’中的‘super exciting’。
●匹配.mailrc文件中的一行内容。这个文件的每一行都按下面的数据格式来组织:
alias 简称 电子邮件地址
例如 ‘alias jeff [email protected]’(在这里,分隔符是每个部分之间的空白和换行符)。
●匹配引文字符串(quoted string),但是容许其中包含转义的引号,例如‘a passport needs a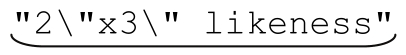 of the holder’。
of the holder’。
●解析CSV(逗号分隔值,comma-separated values)文件。
总的来说,处理这些任务的步骤是:
1.匹配起始分隔符(opening delimiter)。
2.匹配正文(main text,即结束分隔符之前的所有文本)。
3.匹配结束分隔符。
我曾经说过,如果结束分隔符不只一个字符,或者结束分隔符能够出现在正文中,这种任务就很难完成。
容许引文字符串中出现转义引号
来看2\"x3\"的例子,这里的结束分隔符是一个引号,但正文也可能包含转义之后的引号。匹配开始和结束分隔符很容易,诀窍就在于,匹配正文的时候不要超越结束分隔符。
仔细想想正文里能够出现的字符,我们知道,如果一个字符不是引号,也就是说如果这个字符能由「[^"]」匹配,那么它肯定属于正文。不过,如果这个字符是一个引号,而它前面又有一个反斜线,那么这个引号也属于正文。把这个意思表达出来,使用环视(☞133)功能来处理“如果之前有反斜线”的情况,就得到「"([^"]|(?<=\\)")*"」,这个表达式完全能够匹配2\"x3\"。
不过,这个例子也能用来说明,看起来正确的正则表达式如何会匹配意料之外的文本,它虽然看起来正确,但不是任何情况下都正确。我们希望它匹配下面这个无聊的例子中的划线部分:
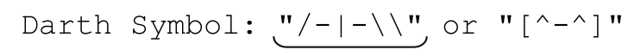
但它匹配的是:
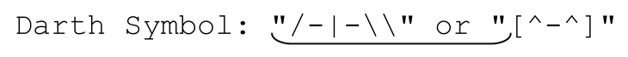
这是因为,第一个闭引号之前的确存在一个反斜线。但这个反斜线本身是被转义的,它不是用来转义之后的双引号的(也就是说这个引号其实是表示引用文本的结束)。而逆序环视无法识别这个被转义的反斜线,如果在这个引号之前有任意多个‘\\’,用逆序环视只会把事情弄得更糟。原来的表达式的真正问题在于,如果反斜线是用来转义引号的,在我们第一次处理它时,不会认为它是表示转义的反斜线。所以,我们得用别的办法来解决。
仔细想想我们想要匹配的位于开始分隔符和结束分隔符之间的文本,我们知道,其中可以包括转义的字符(「\\.」),也可以包括非引号的任何字符「[^"]」。于是我们得到「"(\\.|[^"])*"」。不错,现在这个问题解决了。不幸的是,这个表达式还有问题。不期望的匹配仍然会发生,比如对这个文本,它应该是无法匹配的,因为其中没有结束分隔符。
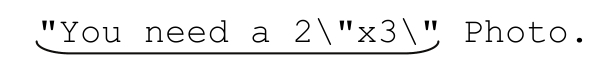
为什么能匹配呢?回忆一下“匹配优先和忽略优先都期望获得匹配”(☞167)。即使这个表达式一开始匹配到了引号之后的文本,如果找不到结束的引号,它就会回溯,到达

从这里开始,「[^"]」匹配到反斜线,之后的那个引号被认为是一个结束的引号。
这个例子给我们的重要启示是:
如果回溯会导致不期望,与多选结构有关的匹配结果,问题很可能在于,任何成功的匹配都不过是多选分支的排列顺序造成的偶然结果。
实际上,如果我们把这个正则表达式的多选分支反过来排列,它就会错误地匹配任何包含转义双引号的字符串。真正的问题在于,各个多选分支能够匹配的内容发生了重叠。
那么,应该如何解决这个问题呢?就像第186页的那个连续行的例子一样,我们必须确保,这个反斜线不能以其他的方式匹配,也就是说把「[^"]」改为「[^\\"]」。这样就能识别双引号和文本中的“特殊”反斜线,必须根据情况分别处理。结果就是「"(\\.|[^\\"])*"」,它工作得很好(尽管这个正则表达式能够正常工作,但对于NFA引擎来说,仍然有提升效率的改进,我们会在下一章更详细地看这个例子,☞222)。
这个例子告诉我们一条重要的原理:
不应该忘记考虑这样的“特殊”情形:例如针对“糟糕(bad)”的数据,正则表达式不应该能够匹配。
我们的修改是正确的,但是有意思的是,如果有占有优先量词(☞142)或者是固化分组(☞139),这个正则表达式可以重新写作「"(\\.|[^"])*+"」和「"(?>(\\.|[^"])*)"」。这两个正则表达式禁止引擎回溯到可能出问题的地方,所以它们都可以满足要求。
理解占有优先量词和固化分组解决此问题的原理非常有价值,但是我仍然要继续之前的修正,因为对读者来说它更具描述性(更直观)。其实在这个问题上,我也愿意使用占有优先量词和固化分组——不是为了解决之前的问题,而是为了效率,因为这样报告匹配失败的速度更快。
了解数据,做出假设
Knowing Your Data and Making Assumptions
现在是时候强调我曾经数次提到过的关于构建和使用正则表达式的一般规则了。知道正则表达式会在什么情况中应用,关于目标数据又有什么样的假设,这非常重要。即使简单如「a」这样的数据也假设目标数据使用的是作者预期的字符编码(☞105)。这都是一些很基本的常识,所以我一直没有过分细致地介绍。
但是,许多对某个人来说明显的常识,可能对其他人来说并不明显。例如,前一节的解决办法假设转义的换行符不会被匹配,或者会被应用于点号通配模式(☞111)。如果我们真的想要保证点号可以匹配换行符,同时流派也支持,我们应该使用「(?s:.)」。
前一节中我们还假设了正则表达式将应用的数据类型,它不能处理表示其他用途的双引号。如果用这个正则表达式来处理任何程序的源代码,就可能出错,因为注释中可能包括双引号。
对数据做出假设,对正则表达式的应用方式做出假设,都无可厚非。问题在于,假设如果存在,通常会过分乐观,也会低估了作者的意图和正则表达式最终应用间的差异。记录下这些假设会有帮助。
去除文本首尾的空白字符
Stripping Leading and Trailing Whitespace
去除文本首尾的空白字符并不难做到,这是经常要完成的任务。总的来说最好的办法是使用下面两个替换:
s/^\s+//;
s/\s+$//;
为了增加效率,我们用「+」而不是「*」,因为如果事实上没有需要删除的空白字符,就不用做替换。
出于某些考虑,人们似乎更希望用一个正则表达式来解决整个问题,所以我会提供一些方法供比较。我不推荐这些办法,但对理解这些正则表达式的工作原理及其问题所在,非常有意义。
s/\s*(.*?)\s*$/$1/s
这个正则表达式曾被用作降解忽略优先量词的绝佳例子,但现在不是了,因为人们认识到它比普通的办法慢得多(在Perl中要慢5倍)。之所以效率这么低,是因为忽略优先约束的点号每次应用时都要检查「\s*$」。这需要大量的回溯。
s/^\s*((?:.*\S)?)\s*$/$1/s
这个表达式看起来比上一个要复杂,不过它的匹配倒是很容易理解,而且所花的时间也只是普通方法的2倍。在「^\s*」匹配了文本开头的空格之后,「.*」马上匹配到文本的末尾。后面的「\S」强迫它回溯直到找到一个非空的字符,把剩下的空白字符留给最后的「\s*$」,捕获括号之外的。
问号在这里是必须的,因为如果一行数据只包含空白字符的行,必须出现问号,表达式才能正常工作。如果没有问号,可能会无法匹配,错过这种只有空白字符的行。
s/^\s+|\s+$//g
这是最容易想到的正则表达式,但它不正确(其实这三个正则表达式都不正确),这种顶极的(top-leveled)多选分支排列严重影响本来可能使用的优化措施(参见下一章)。/g这个修饰符是必须的,它容许每个多选分支匹配,去掉开始和结束的空格。看起来,用/g是多此一举,因为我们知道我们只希望去掉最多两部分空白字符,每部分对应单独的子表达式。这个正则表达式所用的时间是简单办法的4倍。
测试时我提到了相对速度,但是实际的相对速度取决于所用的软件和数据。例如,如果目标文本非常非常长,而且在首尾只有很少的空格,中间的那个表达式甚至会比简单的方法更快。不过,我自己在程序中仍然使用下面两种形式的正则表达式:
s/^\s+//;s/\s+$//;
因为它几乎总是最快的,而且显然最容易理解。