HTML-Related Examples
在第2章,我们曾讨论过把纯文本转换为HTML的例子(☞67),其中要使用正则表达式从文本中提取E-mail地址和http URL。本节来看一些与HTML相关的其他处理。
匹配HTML Tag
Matching an HTML Tag
最常见的办法就是用「<[^>]+>」来匹配 HTML 标签。它通常都能工作,例如下面这段用来去除标签的Perl语句:
$html=~s/<[^>]+>//g;
如果tag中含有‘>’,它就不能正常匹配了,而这样的tag明明是合乎HTML规范的:<input name=dir value=">">。虽然这种情况很少见,也不为大家推荐,但HTML语言确实容许在引号内的tag属性中出现非转义的‘<’和‘>’。这样,简单的「<[^>]+>」就无法匹配了,得想个聪明点的办法。
‘<…>’中能够出现引用文本和非引用形式的“其他文本(other stuff)”,其中包括除了‘>’和引号之外的任意字符。HTML 的引文可以用单引号,也可以用双引号。但不容许转义嵌套的引号,所以我们可以直接用「"[^"]*"」和「\'[^\']*\'」来匹配。
把这些和“其他文本”表达式「[^\'">]」合起来,我们得到:
「<("[^"]*"|\'[^\']*\'|[^\'">])*>」
这个表达式可能有点难看懂,那么加上注释,按宽松排列格式来看:

这个表达式相当漂亮,它会把每个引用部分单作为一个单元,而且清楚地说明了在匹配的什么位置容许出现什么字符。这个表达式的各部分不会匹配重复的字符,因此不存在模糊性,也就不需要担心发生前面例子中出现的,“不小心冒出来(sneaking in)”非期望匹配。
不知你是否注意到了,最开始的两个多选分支的引号中使用了「*」,而不是「+」。引用字符串可能为空(例如‘alt=""’),所以要用「*」来处理这种情况。但不要在第三个多选分支中用「*」取代「+」,因为「[^\'">]」只接受括号外的「*」的限定。给它添加一个加号得到「([^\'">]+)*」,可能导致非常奇怪的结果,我不期望读者现在就能理解,下一章(☞226)会详细讲解它。
在使用NFA引擎时,我们还需要考虑关于效率的问题:既然没有用到括号匹配的文本,我们可以把它们改为非捕获型括号(☞137)。因为多选分支之间不存在重复,如果最后的「>」无法匹配,那么回头来尝试其他的多选分支也是徒劳的。如果一个多选分支能够在某个位置匹配,那么其他多选分支肯定无法在这里匹配。所以,不保存状态也无所谓,这样做还可以更快地导致失败,如果找不到匹配结果的话。我们可以用固化分组「(?>…)」而不是非捕获型括号(或者用占有优先的星号限定)。
匹配HTML Link
Matching an HTML Link
假设我们需要从一份文档中提取URL和链接文本,例如下面的文本中标记的内容:
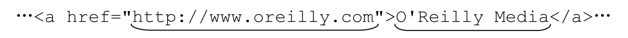
因为<A> tag 的内容可能相当复杂,我会分两步实现这个任务。第一个是提取<A> tag内部的内容,也就是链接文本,然后从<A> tag中提取URL地址。
实现第一步有个简单办法,就是在点号通配模式下应用不区分大小写的「<ab([^>]+)>(.*?)</a>」,这里使用了忽略优先量词。它会把<A>的内容放入$1,把链接文本放入$2。当然,像之前一样,我不应该用「[^>]+」,而应该使用前几节中的表达式。不过在本节,我会继续使用这个简单的形式,因为这样正则表达式更短,也更容易讲解。
<A>的内容存入字符串之后,就可以用独立的正则表达式来检查它们。其中,URL 是href=value属性的值。之前已经说过,HTML容许等号的任意一侧出现空白字符,值可以以引用形式出现,也可以以非引用形式出现。下面的 Perl 代码用来输出变量$Html 中的链接。

有几点需要注意:
●我们为匹配值的每个多选结构都添加了括号,来捕获确切的文本。
●因为我使用了某些括号来捕获文本,在不需要捕获的地方我使用非捕获型括号,这样做既清楚又高效。
●“其他字符”部分排除了空白字符,也排除了引号和‘>’。
●因为需要捕获整个 href的值,这里使用了「+」来限制“其他文本”多选分支。这是否会和第200页对其他字符应用「+」一样导致“非常奇怪的结果”呢?不会,因为这外面没有直接作用于整个多选结构的量词。其中的细节同样会在下一章讨论。
根据具体文本的不同,最后,URL 可能保存在$1、$2 或者$3 中。此时其他捕获型括号就为空或是未定义。Perl提供了特殊变量$+,代表$1、$2之类中编号最靠后的捕获文本。在本例中,这就是我们真正需要的URL。
Perl 中的$+很方便,其他语言也提供了其他办法来选择捕获的 URL。常用的程序语言结构就可以检查捕获型括号,找到需要的内容。如果能够支持,命名捕获(☞138)最适用于干这个,就像204页的VB.NET的例子那样(幸亏.NET提供了命名捕获,因为它的$+有问题,☞424)。
检查HTTP URL
Examining an HTTP URL
现在我们得到了 URL 地址,来看看它是否是 HTTP URL,如果是,就把它分解为主机名(hostname)和路径(path)两部分。因为已经有了URL,任务就比从随机文本中识别URL要简单许多,识别的程序要难许多,这将在后文介绍。
所以,如果拿到一个URL,我们需要能够将它拆分为各个部分。主机名是「^http://」之后和第一个反斜线(如果有的话)之前的内容,而路径就是除此之外的内容:「^http://([^/]+)(/.*)?$」。
URL 中有可能包含端口号,它位于主机名和路径之间,以一个冒号开头:「^http://([^/:]+)(:(d+))?(/.*)?$」。
下面是一个分解URL的Perl代码:

验证主机名
Validating a Hostname
在上面的例子中,我们用「[^/:]+」来匹配主机名。不过,在第 2 章中(☞76)我们使用的是更复杂的「[-a-z]+(.[-a-z]+)*.(com|edu|…|info)」。做同样的事情,复杂程度为什么会有这么大的差别?
而且,虽然二者都用来“匹配主机名”,方法却大不相同。从已知文本(例如,从现成的URL中)中提取一些信息是一回事,从随机文本中准确提取同样信息是另一回事。
而且,在上例中我们假设,‘http://’之后就是主机名,所以用「[^/:]+」来匹配就是理所当然的。但是在第 2 章的例子中,我们使用正则表达式从随机文本中寻找主机名,所以它必须更加复杂。
现在从另外一个角度来看主机名的匹配,我们可以用正则表达式来验证主机名。也就是说,我们需要知道,一串字符是否是形式规范、语意正确的主机名。按规定,主机名由点号分隔的部分组成,每个部分可以包括 ASCII 字符、数字和连字符,但是不能以连字符作为开头和结尾。所以,我们可以在不区分大小写的模式下使用这个正则表达式:「[a-z0-9]|[a-z0-9][-a-z0-9]*[a-z0-9]」。结尾的后缀部分(‘com’、‘edu’、‘uk’等)只有有限多个可能,这在第 2 章的例子中提到过。结合起来,下面的正则表达式就能够匹配一个语意正确的主机名:


因为存在长度的限制,能够由这个正则表达式匹配的可能并不是合法的主机名:每个部分不能超过63个字符。也就是说,「[-a-z0-9]*」应该改为「[-a-z0-9]{0,61}」。
还需要做最后的改动。按规定,只包括后缀的主机名同样是语意正确的。但实践证明,这些“主机名”不存在,但是对于两个字母的后缀来说情况可不是如此。例如,安哥拉的域名‘ai’就有一个Web服务器http://ai/。我见过其他这样的链接:cc、co、dk、mm、ph、tj、tv和tw。
如果希望匹配这些特殊情况,应该把中间的「(?:…)+」改为「(?:…)*」:

现在它可以用来验证包含主机名的字符串了。因为这是我们想出的与主机名相关的三个正则表达式中最复杂的,你也许会想,不要这些锚点,可能比之前那个从随机文本中提取主机名的表达式更好。但情况并非如此。这个正则表达式能匹配任意双字母单词,正因为如此,第 2 章中不那么精妙的正则表达式的实际效果更好。但是在下一节我们会看到,某些情况下它仍然不够完善。
在真实世界中提取URL
Plucking Out a URL in the Real World
供职于Yahoo!Finance时,我曾写过处理收录的财经新闻和数据的程序。新闻通常是以纯文本格式提供的,我的程序将其转化为HTML格式以便于显示(如果你在过去10年中曾经在http://finance.yahoo.com浏览过财经新闻,没准看过我处理过的新闻)。
因为接受的数据的“格式”(其实是无格式)很杂乱,从纯文本中识别(recognize)出hostname和URL又比验证(validate)它们困难得多,这任务就很不轻松。前面的内容并没有体现这一点,在本节,你会看到我在Yahoo!用来解决这个问题的程序。
这个程序从文本中提取几种类型的URL——mailto、http、https和ftp。如果我们在文本中找到‘http://’,就知道这肯定是一个URL的开头,所以我们可以直接用「http://[-w]+(.w[-w]*)+」来匹配主机名。我们知道,要处理的文本肯定是ASCII编码的英文字母,所以完全可以用「-w」来取代「-a-z0-9」。「w」同样可以匹配下画线,在某些系统中,它还可以匹配所有的Unicode字符,但是我们知道,这个程序在运行时不会遇到这些问题。
不过,URL通常不是以http://或者mailto:开头的,例如:
…visit us at www.oreilly.com or mail to [email protected]…
在这种情况下,我们需要加倍小心。我在Yahoo!使用的正则表达式与前面那节的非常相似,只是有一点点不同:

在这个正则表达式中,我们用「(?i:…)」和「(?-i:…)」用来规定正则表达式的某个部分是否区分大小写(☞135)。我们希望匹配‘www.OReilly.com’,但不是‘NT.TO’这样的股票代码(NT.TO是北电网络在多伦多证券交易市场的代号,因为要处理的是财经新闻和数据,这样的股票代码很多)。按规定,URL的结尾部分(例如‘.com’)可能是大写的,但我不准备处理这些情况。因为我需要保持平衡——匹配期望的文本(尽可能多的URL),忽略不期望的文本(股票代码)。我希望「(?-i:...)」只包括国家代码,但是在现实中,我们没有遇到大写的URL地址,所以不必这么做。
下面是从纯文本中查找URL的框架,我们可以在其中添加匹配主机名的子表达式:

我还没有谈论过正则表达式的 path(路径)部分,它接在主机名后面(例如 http://www. 中的划线部分)。path是最难正确匹配的文本,因为它需要一些猜测才能做得很漂亮。我们在第 2 章说过,通常出现在 URL 之后的文本也能被作为URL的一部分。例如:
中的划线部分)。path是最难正确匹配的文本,因为它需要一些猜测才能做得很漂亮。我们在第 2 章说过,通常出现在 URL 之后的文本也能被作为URL的一部分。例如:
Read his comments at http://www.oreilly.com/ask_tim/index.html.He...我们观察之后就会发现,在‘index.html’之后的句号是一个标点,不应该作为URL的一部分,但是‘index.html’中的点号却是URL的一部分。
肉眼很容易分辨这两种情况,但程序做起来却很难,所以必须想些聪明的办法来尽可能好地解决问题。第2章的例子使用逆序环视来确保URL不会以句末的句号结尾。我在Yahoo!Finance写程序时还没有逆序环视,所以我用的办法要复杂的多,不过效果是一样的。代码在下一页。
示例5-1:从财经新闻中提取URL

这里用到的办法与第2章第75页用到的办法有很多不同,比较起来也很有意思。下一页里使用此表达式的Java程序详细介绍了它的构造。
在实际生活中,我怀疑自己是否会写这样繁杂的正则表达式,但是作为取代,我会建立一个正则表达式“库(library)”,需要时取用。这方面一个简单的例子就是第 76 页的$HostnameRegex,以及下面的补充内容。