Perl\'s Regex Flavor
下一页的表7-2概要描述Perl的正则风格。以前,Perl的许多元字符是其他系统不支持的,但是经过许多年之后,其他系统接受了许多Perl的创新。这些常见的特性在第3章的概览里有描述,但是 Perl 还有专属于自己的元素,会在本章后面讲解(表 7-2 覆盖了将要讲解的各个元素)
下面是对表格的补充:
○1b只有在字符组内部才是退格符的简记法。在字符组外部,b表示单词分界符(☞133)。
八进制转义接收2到3位的数值。
「xnum」十六进制转义接收两位数字(也可以是一位数字,但是会报警)。「x{num}」能接收任意长度的十六进制数。
表7-2:Perl的正则流派概览

○2w、d、s之类完全支持Unicode。
Perl的s不能匹配ASCII的垂直制表符(☞115)。
○3 Perl的Unicode支持针对的是Unicode Version 4.1.0。
Unicode字母表也能支持。字母表和属性名可以有‘Is’前缀,但并非必须(☞125)。区块名可以有‘In’前缀,但只有在区块和字母表的名字发生冲突时才必须使用。
Perl也支持「p{L&}」、「p{Any}」、「p{All}、「p{Assigned}」和「p{Unassigned}」属性。Perl 支持例如「p{Letter}」的长属性名。名字的各个单词之间可能是空格、下画线,或者什么也没有,(例如「p{Lowercase_Letter}」,也可能写作「p{Lowercase Letter}」)或者是「p{Lowercase·Letter}」),为了前后一致,我推荐使用第123页表格中的长命名。
「p{^…}」等价于「P{…}」。
○4 单词分界符完全支持Unicode。
○5 顺序环视可能包含捕获型括号。
逆序环视中的子表达式必须匹配固定长度的文本。
○6/x修饰符只能识别ASCII空白字符。/m只对换行符有影响,而且不是所有的Unicode
换行符。
/i能够在Unicode中正常工作。
所有的元字符并不是生而平等的。“正则元字符”没有得到正则引擎的支持,但Perl的正则文字预处理机制能对付。
正则运算符和正则文字
Regex Operands and Regex Literals
表7-2最下面的条目标注有“专属于正则文字”。正则文字(regex literal)就是m/regex/部分中的“regex”,虽然平时称其为“正则表达式”,但在‘/’分隔符之间的部分是有自己的解析规则。用Perl的行话来说,正则文字就是“表示正则含义的双引号字符串(regex-aware double-quoted string)”,及处理之后传递给正则引擎的结果。正则文字处理机制提供了特殊的功能来构建正则表达式。
举例来说,正则文字提供了变量插值功能。如果变量$num的值是20,代码m/:.{$num}:/得到的就是「:.{20}:」。这样可以根据需要即时构建正则表达式。正则文字的另一功能是大小写自动切换展开,U…E 可以保证其中的字母均为大写。比如,m/abcUxyzE/得到正则表达式「abcXYZ」。这个例子有点做作,如果需要使用「abcXYZ」,应该直接输入m/abcXYZ/,但是这种功能结合变量插值就很有用:如果变量$tag 包含字符串“title”,则代码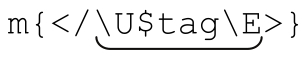 得到
得到 。
。
除正则文字之外还有什么呢?我们可以把字符串(或者任何表达式)当作正则运算元,比如:

当$MatchField用作=~的运算元时,它的值就被解释(interpreted)为正则表达式。这里只能“解释”普通的正则表达式,所以不支持只作用于正则文字的变量插值和「Q…E」。
下面的例子值得思考,如果把:
$text=~$MatchField
替换为:
$text=~m/$MatchField/
结果完全一样。这里的正则文字只包含一个元素——变量$MatchField。正则文字中插值变量的值不会被当作正则文字处理,所以变量内的U…E和$var之类不会被识别(第292页说明了正则文字的处理细节)。
如果正则表达式在程序的执行期间需要多次用到,那么正则运算元采用字符串或变量插值的效率差距就很明显。第348页讨论了这个问题。
正则文字支持的特性
正则文字提供下面的特性:
●变量插值 正则表达式中以$和@开头的变量会被替换为实际变量的值。$变量插入一个简单的纯量值(scalar value)。以@开头的插入数组或者数组的一部分,以空格分隔各个元素(其实是以$"变量作分隔符,它的默认值是空格)。
在Perl中,‘%’引入一个散列变量(hash variable),但是在字符串中插入一个散列变量并没有太大的意义,所以Perl不支持%插值。
●命名的Unicode字符 如果程序中包含“use charnames\':full\';”,就可以用N{name}序列引用Unicode字符。例如,N{LATIN SMALL LETTER SHARP S}匹配“ß”。在Perl的unicore 目录下的UnicodeData.txt中可以找到Perl支持的Unicode字符列表。下面的代码能够报告文件的位置:

“use charnames\':full\';”很容易忘记,或者忘记在‘full’前面添加冒号,果真如此的话,N{…}就不能正常工作。同样,如果使用了下面介绍的正则表达式重载,N{…}也不能正常工作。
●大小写转换前缀l和u能够把后面的字符转换为小写或大写形式。通常我们使用此功能来转换插值变量的第一个字符。举例来说,如果变量$title 包含“mr.”,m/…u$title…/就能生成正则表达式「…Mr.…」。Perl 的 lcfirst()和 ucfirst()函数提供了同样的功能。
●大小写转换范围L和U能够把后面所有的字符转换为小写或大写,其作用范围一直到表达式末尾,或是E为止。同样是$title,m/…U$titleE…/会产生正则表达式「…MR.…」。Perl的lc()和uc()函数提供了同样的功能。
我们可以把这两者结合起来:无论变量$title 采用怎样的字母组合,m/…Lu$titleE…/都会得到「…Mr.…」。
●文字文本范围Q“转义(quote)”正则表达式元字符(也就是在它们之前放一个反斜线,保证它们只作为普通的字符),其作用范围直到字符串的结尾,或者直到E。它能转义正则表达式元字符,但不能转义表示变量插值的正则文字U,当然也不能转义E。奇怪的是,如果反斜线开头的字符序列不能识别——例如F或者H,反斜线也不会被转义。即使是Q…E,这样的序列也会导致“unrecognized escape”警告。
在实践中,这些限制并不是严重的缺陷,Q…E 通常用于引用插值文本,这样就可以正确转义所有的元字符。例如,如果$title包含“Mr.”,那么代码m/…Q$titleE…/就会生成正则表达式「…Mr.…」,我们要的就是这样——希望匹配的是$title中的字符,而不是$title中的正则表达式。
如果你希望在正则表达式中包含某些用户输入的数据,这非常有用。举例来说,m/Q$UserInputE/i能够对$UserInput(作为字符串,而不是正则表达式)中的字符进行不区分大小写的搜索。
Perl的函数quotemeta()提供了与Q…E等价的功能。
●重载 借助重载,用户可以使用任何期望的方式预处理正则文字的文字字符。这是概念值得讨论,但是目前的实现还有诸多限制。关于重载的细节讨论请参见第341页。
使用自己的正则表达式分隔符
Perl语法中最奇妙(也是最有用)的特性之一就是用户可以使用自己的正则文字分隔符。传统的分隔符是斜线,例如 m/…/、s/…/…/和 qr/…/,不过还可以使用除数字、字母和空格之外的字符。常用的包括:

右边四个是特殊的分隔符:
●右边的四个例子具有不同的开始-结束分隔符,而且可能嵌套(也就是说,如果开始-结束分隔符匹配恰当,表达式中容许包含与分隔符一样的字符)。因为圆括号和方括号在正则表达式中经常用到,m(…)和m[…]可能不如其他更有吸引力。使用/x修饰符时,可能出现下面的形式:
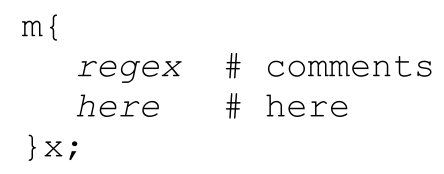
也可以使用某种组合标记 regex,另一组(如果你喜欢,也可以用同样的)标记replacement。例如:

如果这样做了,就可以在两对分隔符之间插入空格和注释。第 319 页进一步讲解了substitution运算符的replacement运算元。
●对match运算符来说,把问号作为分隔符有其特殊价值(禁止更多的匹配),这一点在下一节讲解关于match运算符时讨论(☞308)。
●288页已经提到,正则文字被解析成“表示正则含义的双引号字符串”。如果用单引号作分隔符,就无法使用这些功能。使用 m\'…\'时就不会进行变量插值,实时修改文本的结构(比如Q…E)不会生效,N{…}也无法使用。也许在使用包含多个@的正则表达式时m\'…\'很有价值,因为这样可以不需要转义。
如果进行match操作,而分隔符是斜线或者问号,可以省略m,也就是:
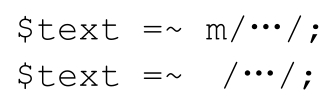
是等价的。但我更喜欢明确写上m。
正则文字的解析方式
How Regex Literals Are Parsed
大多数情况下,如果用户“只会用到”上文讲解的正则文字特性,就不需要理解 Perl 将它们转换为真正的正则表达式的具体细节。就这一点来说,Perl直观性非常方便,但是许多时候,了解细节并无坏处。下面列出了各种处理的顺序:
1.找到结束分隔符,读入修饰符(例如/i之类)。下面的处理就能判断是否采用了/x之类的模式。
2.变量插值。
3.如果使用了正则表达式重载,正则文字的每个部分都会交给重载子程序来处理。各部分由插值变量分隔;插入的值是无法重载的。
如果正则表达式没有进行重载,处理N{…}。
4.应用大小写转换结构(例如Q…E)。
5.把结果提交给正则引擎。
以上是程序员眼中的处理,但是 Perl 内部的处理其实是很复杂的。单单是第二步,就必须识别正则表达式的元字符,比如不应把「this$|that$」下画线的那部分识别为变量。
正则修饰符
Regex Modifiers
Perl的正则运算符容许在正则文字的结束分隔符之后添加正则修饰符(例如m/…/i、s/…/…/i和qr/…/i中的i)。所有运算符都支持的核心修饰符一共有5种,详见表7-3。
头四种在第 3 章已经介绍过,它们能够作为模式修饰符(☞135)或者范围模式修饰符(☞135),在正则表达式之中使用。如果正则表达式内部出现了修饰符,match运算符也用到了修饰符,则正则表达式内部的修饰符的优先级更高(从另一方面来说就是,一旦修饰符应用到正则表达式内部的某些元素,这些元素就不再受其他修饰符的影响)。
表7-3:所有正则运算符可用到的核心修饰符

第五个核心修饰符/o,与效率有很大的关系。此问题从第348页开始讨论。
如果需要使用多个修饰符,只需要把它们并排列在结束分隔符之后即可,排列的顺序是无关紧要的(注3)。请注意,斜线本身不是修饰符,你可以使用m/<title>/i、m|<title>|i,或是m{<title>}i,甚至是m<<title>>i。不过在讲解修饰符时,通行的做法是加上一个斜线,例如“修饰符/i”。