Regex-Related Perlisms
学习正则表达式,还需要掌握许多一般的Perl概念。下面几节的内容包括:
●应用场合(context)Perl 的重要概念之一就是,许多函数和运算符在不同应用场合有不同的意义。例如,Perl的 while循环希望接收一个纯量值(scalar value)作为判断条件,但对于print语句希望接收一组值(a list of value)。因为Perl容许表达式对其应用场合进行“响应”(respond),同样的表达式在不同的应用场合可能得到截然不同的结果。
●动态作用域(dynamic scope)大多数编程语言都支持本地变量和全局变量,但是 Perl还提供了另一种复杂功能,称为动态作用域。动态作用域会临时“保护”全局变量,保存一份副本,稍后自动恢复。这个复杂的概念对我们来说很重要,因为它影响到$1和其他的匹配相关变量。
表达式应用场合
Expression Context
context对Perl来说是很重要的概念,尤其对match运算符来说更是如此。一个表达式可能出现在三种context中:序列(list)、纯量值(scalar)或者空(void),它们表示表达式期望接收的参数类型。所以,list context说明表达式期望获得一个序列。scalar context说明表达式期望获得单个值。以上两者极为常见,而且对使用正则表达式非常有价值。void context说明不期望获得任何值。
看下面两个赋值:

因为$s是scalar变量(它用来保存单个的值,而不是序列),期望简单的纯量值,所以第一个表达式的应用场合为scalar context。同样,因为@a是一个数组,期望获得一个list,第二个表达式的应用场合为list context。即使这两个表达式完全等价,也可能返回完全不同的结果,产生不同的影响。具体情况依表达式而定。
举例来说,localtime函数如果用在list context中,会返回一组值,表示当前年、月、日、时。但如果用在scalar context中,则返回文本类型的当前时间,比如‘Mon Jan 20 22:05:15 2003’。
另一个例子是<MYDATA>之类的I/O运算符,在scalar context中,它返回文件的下一行,但是在list context中,返回所有(剩下的)行。
就像localtime和I/O运算符一样,许多Perl的结构会根据应用场合的不同返回不同的值,正则运算符同样如此。拿 match 运算符 m/…/来说,有时候它会简单地返回true/false 值,有时候返回一组匹配结果。所有的细节都会在本章讲解。
强转正则表达式
不是所有的正则表达式天生都能区分场合的,所以,如果某个应用场合中正则表达式无法提供期望的返回类型,就要按照 Perl 的规定处理。为了把方桩插入圆孔,Perl 会“强转(contort)”这个值。如果在list context中返回的是scalar值,Perl会生成只包含单个元素的list。这样@a=42就等于@a=(42)。
另一方面,把list转换为scalar却没有统一的规定。如果程序是这样:
$var=($this,&is,0xA,'list');
逗号运算符返回最后的元素‘list’给$var。如果给定的是一个数组,例如$var=@array,则返回数组的长度。
其他语言用不同的术语描述这种处理,例如修正(cast)、提示(promote)、强制转换(coerce)或转换(convert),但是我认为这些词都已经具有了自己的意义(有点令人讨厌),不适合描述Perl的做法,所以我使用“强转(contort)”。
动态作用域及正则匹配效应
Dynamic Scope and Regex Match Effects
Perl的变量分为两类(全局变量和私有变量),动态作用域是正确理解它们的重点,研究正则表达式时也需要关注此概念,因为它关系到匹配完成之后信息如何使用。下一节介绍了这些概念及其与正则表达式的关系。
全局和私有变量
总的来说,Perl 提供了两种变量:全局的和私有的。私有变量使用 my(…)来声明,全局变量不需要声明,在使用时会自动出现。全局变量通常在程序的任何地方都是可见的,而私有变量,按照语言的规定只有在它们所属的代码块之内才是可见的。也就是说,只有私有变量声明所在的代码块之内的Perl代码,能够访问私有变量。
全局变量的使用则很普通,只是有的特殊变量不太好理解,例如$1、$_、@ARGB 之类。普通用户的变量是全局的,除非它们以my来声明,否则即使它们“看上去”是私有的,也是全局变量。按照Perl的规定,Package Acme::Widget中的全局变量$Debug,虽然有完整的限定名$Acme::Widget::Debug,仍然是一个全局变量。如果出现了 use strict;,则所有(不包括特殊的)全局变量必须使用完整的限定名,或者通过our来声明(our声明一个名称(name),而不是一个新变量,请参考Perl的文档)。
使用动态作用域的值
动态作用域(dynamic scoping)是个值得一提的概念,很少有编程语言提供这种功能。下文会讲解它与正则表达式的关系,简单地说,动态作用域可以让Perl保存全局变量的一个副本,在某个代码块中修改此副本,退出之后自动恢复原来的值。保存副本的操作就称为生成动态作用域(creating a new dynamic scope),或者本地化(localizing)。
使用动态作用域的原因之一是为了临时改变某些保存在全局变量中的某些全局状态。举例来说,package Acme::Widget 提供了一个调试标志位(flag),我们可以修改全局变量$Acme::Widget::Debug来启用或者停用调试功能。下面的代码可以临时改变此标志位:

local函数的命名很成问题,但它生成了一个新的动态作用域。调用 local并没有创造新的变量,local是行为,而不是声明。在全局变量之前,local做了三步处理:
1.在内部保存变量值的副本;
2.把新值赋予到变量(无论是undef还是传给local的值);
3.local代码块执行结束之后,把变量恢复到之前的值。
也就是说,“local”指的是对变量的修改的持续时间。对本地化的变量来说,持续时间就是代码块执行的时间。如果代码块中调用了子程序,本地化的值仍然保留(毕竟,变量仍然是一个全局变量)。它与非本地化的全局变量的唯一区别是,在代码块执行完成之后,之前的值会被恢复。
local对全局变量的自动保存和恢复比想象的要复杂。请参考表7-4右侧,详细了解背后的处理。
为方便起见,我们也可以给本地变量赋一个值local($SomeVar),这等于把undef赋值给$SomeVar。如果不使用括号,表示强制使用scalar context。
举个实际的例子,我们需要调用一个写得很糟糕的函数,而它会产生许多“Use of uninitialized value”的警告。优秀的Perl程序员都会使用Perl的-w选项来解决这个问题,但是库的作者
表7-4:local的含义

显然没有。你对这些警告非常恼火,但是如果不能修改程序库,有什么其他简便办法来代替-w吗?这时候可以使用对$^W的调用的local,即时关闭警报(^W可以表示为两个字符,脱字符和‘W’,也就是ctrl+W)。

无论全局变量$^W是什么值,调用local保存都会为其保存一份内部副本。然后$^W被用户置为 0。上面提到的糟糕程序在执行时,Perl 检查$^W,发现其值为 0,就不会发出警报。在函数返回时,新值0仍然有效。
这样看来,不用 local 的话似乎也没有问题。不过,在子程序返回,代码块退出时,$^W会恢复到之前的值。这种改变是本地的、即时的,只在代码块内部生效。按照表7-4右侧的做法,用户可以手工生成和返回副本,达到同样的效果,但是local更为方便。
考虑在其他情况下会发生什么,比如用 my替代 local(注4)。my会新建一个变量,其初始值是undef。只有在声明的代码块中才可见(也就是说,在my和它所在的代码块结束之间)。它不会改变、修改,或以其他方式引用和影响其他变量,包括可能存在的同样名字的全局变量。新建的变量在程序的其他部分都不可见,包括在那个糟糕的程序内。这样新的$^W的确被置为0,但永远不会再使用或者引用,所以它完全是白费工夫(执行糟糕的程序时,Perl根据与其无关的全局变量$^W决定是否报警)。
更好的比喻:充分的透明度
可以这样理解 local,它对变量的修改是用户完全无法察觉的(好像是把新值投影到原变量之上)。用户(还包括能看到的任何人,例如子程序和信号处理程序)会看到这些新的值。在代码块结束之前,local的修改会取代之前的值。退出之后,这种透明特性会自动消除,也就是取消local进行的所有修改。
相比“保存一个内部副本”,这个比喻更接近现实。使用local并不会生成一个副本,而是在访问变量时,使用新设置的值(即屏蔽原来的值)。退出代码块之后会抛弃新设置的值。调用 local时,新值是手动设置的,但我们要讲解这些细节的原因在于:正则表达式的伴随效应变量(side-effect variables)会自动使用动态作用域。
正则表达式的伴随效应和动态作用域
正则表达式与动态作用域有什么关系呢?关系很大。作为伴随效应,许多变量——例如$&(引用匹配的文本)和$1(引用第一组括号内表达式匹配的文本)——会在匹配成功时自动设置。在下一节会详细讨论这些问题。在其所处的代码块中,这些变量都会自动使用动态作用域。
这种设计的好处在于,每次调用子程序都要启动新的代码块,也就是为这些变量提供了新的动态作用域范围。因为在代码块之前的值会在代码块执行完之后恢复(也就是子程序返回时),子程序不能改变调用方能看到的值。
来看个例子:

因为$1 的值在进入代码块时进行了动态作用域处理,这段代码不关心也不必关心,函数DoSomeOtherStuff是否改变了$1的值。此函数对$1的任何改动都只在函数定义的代码块内部,或者函数的子代码块中生效。所以,DoSomeOtherStuff不会影响 print接收的$1的值。
自动使用动态作用域很有用,虽然有时候不那么明显:
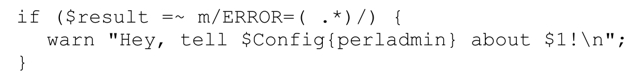
标准库模块 Config 定义了一个关联数组(associative array)%Config,其成员$Config-{perladmin}保存本地Perlmaster的E-mail地址。如果$1没有使用动态作用域,这段代码就很难理解,因为%Confg 是一个绑定变量(tied variable)。也就是说,对它的任何引用都意味着幕后的子程序调用,用$Config{…}进行正则表达式匹配时,Config 中的子程序返回对应的值。这次匹配发生在上一行的匹配和对$1的使用中间,所以如果$1没有使用动态作用域,它的值会被修改。所以,$Config{…}中对$1 的任何修改都被动态作用域安全地保护了起来。
动态作用域还是词法作用域
如果使用恰当,动态作用域能提供许多便利,但是滥用动态作用域会带来无休止的噩梦,因为阅读程序的人很难理解,分散在散落的 local、子程序和本地变量引用之间的复杂交互。
我曾说,my(…)声明会在词法范围(lexical scope)内创造一个私有变量。与私有变量的词法范围对应的是全局变量的范围,但是词法范围与动态作用域没有关系(仅有的联系是:不能对my变量调用local)。请记住,local只是行为(action),而my既是行为,又是声明,这很重要。
匹配修改的特殊变量
Special Variables Modified by a Match
成功的匹配会设置一组只读的全局变量,它们通常会自动使用动态作用域。如果匹配不成功,这些值永远也不会改变。在需要的时候,它们会设置为空字符串(不包括任何字符的字符串)或者undefind(“未定义”,一个“没有值”的值,与空字符串类似,但测试时两者不相等)。表7-5给出了若干例子。
详细地说,匹配完成之后会设置这些变量:
$&正则表达式所匹配文本的副本。从效率方面考虑(参见第356页的讨论),最好不要使用这个变量(还包括下面介绍的$ˋ 和$)。一旦匹配成功,$&就不会是未定义状态,尽管它可能是空字符串。
表7-5:匹配后特殊变量的说明
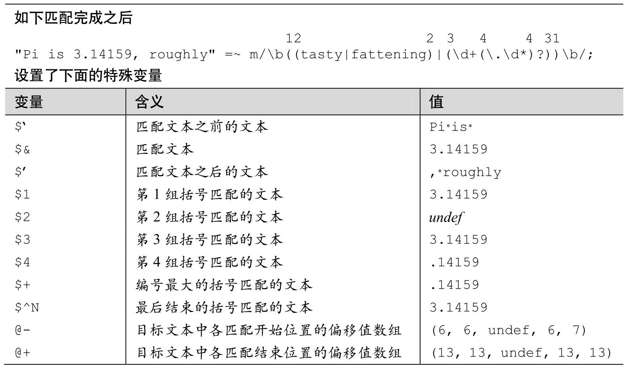
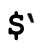 在目标文本中匹配开始之前(左边)文本的副本。如果使用/g修饰符,你可以期望$
在目标文本中匹配开始之前(左边)文本的副本。如果使用/g修饰符,你可以期望$
的起点是开始尝试位置的文本,但它每次都是从整个字符串的开始位置开始的。如果匹
配成功,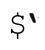 肯定不会是未定义状态。
肯定不会是未定义状态。
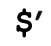 保存目标文本中匹配成功文本之后(右边)的文本的副本。如果匹配成功,
保存目标文本中匹配成功文本之后(右边)的文本的副本。如果匹配成功,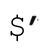 肯定不会是未定义状态。匹配成功之后,字符串
肯定不会是未定义状态。匹配成功之后,字符串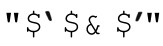 就是目标字符串的副本(注5)。
就是目标字符串的副本(注5)。
$1、$2、$3、…
对应第 1、2、3 组捕获型括号匹配的文本(请注意,这里没有$0,因为它是脚本的名字,与正则表达式无关)。如果它们对应的括号在表达式中不存在,或者没有实际参与匹配,则设置为未定义状态。
匹配之后就可以使用这些变量,在s/…/…/中的replacement也可以使用。它们还能在动态正则结构或者嵌入代码中使用(☞327)。在正则表达式中使用这些变量是没多少意义的(因为已经有了「\1」之类)。请参考第303页的“在正则表达式中使用$1”。
「(\w+)」和「(\w)+」的区别可以用来说明$1的设置方式。两个表达式都能匹配同样的文注5:事实上,即使目标字符串是未定义的,但能匹配成功(虽然不太现实,但有可能),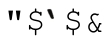
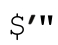 是一个空字符串,而不是未定义。只有在这种情况下,两者才不一样。
是一个空字符串,而不是未定义。只有在这种情况下,两者才不一样。
本,但是它们的区别在于括号内的子表达式匹配的内容。用这个表达式匹配字符串‘tubby’,第一个表达式的$1的内容是‘tubby’,而第二个表达式中的$1只包含‘y’:在「(\w)+」中,加号在括号外面,所以每次迭代都会重新捕获,$1保留最后的字符。
还需要注意的是「(x)?」和「(x?)」的差别。前一个表达式中括号及其捕获内容不是必然出现的,所以$1可能是‘x’,或者是未定义,但「(x?)」中括号在匹配的外面——匹配的内容不是必然出现的,但匹配必须发生。如果整个表达式匹配成功,这部分的匹配必然会发生,尽管「x?」匹配的是空字符串。所以在「(x?)」中,$1可能是‘x’或者是空字符串。下表给出了一些例子:
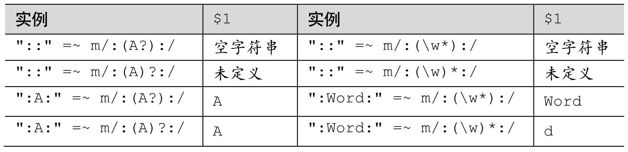
从上表可以看出,如果需要添加括号来捕获文本,如何添加取决于我们的意图。在所举的例子中,增加的括号对整体匹配没有影响(整体匹配是不变的),其中唯一的区别就是$1设置的伴随效应。
$+ 表示$1、$2等匹配过程中明确设定的,编号最大的变量的副本。在下面的情况中会有用:

如果没有$+,我们可能需要依次检查$1、$2和$3,才能找出明确设置的那个。
如果正则表达式中没有捕获型括号(或者在匹配中没有用到),则这个值为未定义。
$^N 最后结束的,在匹配中明确设定的括号匹配的文本的副本(明确设定的$1等变量中,闭括号在最后)。如果正则表达式中没有捕获型括号(或者匹配中没有用到),则其值为未定义。第344页开头有个恰当的例子。
@-和@+
表示各捕获型括号所匹配文本的起始和结束位置在目标文本中偏移值的数组。使用起来可能有点迷惑,因为它们的名字比较怪异。两个数组的第一个元素都对应整体匹配。也就是说,通过$-[0]访问到的@-的第一个元素,是整个匹配在目标字符串中的偏移值,即:

$-[0]的值为 8,代表匹配从目标字符串的第 8 个位置开始(在 Perl 中,偏移值从 0开始)。
@+的第一个元素通过$+[0]访问,表示对应匹配文本结束位置的偏移值。在上例中其值为 9,表示整体匹配结束于目标字符串的第 9 个字符之前。所以,如果$text没有变化,substr($text,$-[0],$+[0]-$-[0])就等于$&,但没有$&那样的性能缺陷(☞356),下例给出了@-的简单用法:
1 while $line=~s/\t/''x (8-$-[0]%8)/e;
它会把给定文本中的制表符(tab)替换为合适长度的空格序列(注6)。
两个数组中接下来的元素分别对应各捕获分组的开始位置和结束位置的偏移值。$-[1]和$+[1]对应$1,$-[2]和$+[2]对应$2,依次类推。
$^R 这个变量保存最近执行的嵌入代码的结果,如果嵌入代码结构作为「(?if then|else)」条件语句(☞140)中的if 部分,则不设定$^R。在正则表达式内部(即在嵌入代码或者动态正则结构☞327 中),它会自动根据匹配的各部分进行本地化处理,所以因为回溯而“交还”的代码对应的$^R的值会被放弃。换一种说法就是,它保存引擎到达当前状态的工作路径中“最近”的值。
如果正则表达式根据/g修饰符重复使用,那么每次循环都会重新设置这些变量。也就是说可以在s/…/…/g中使用$1,因为每次匹配时它的值都不一样。
在正则表达式中使用$1
Perl手册专门提到,在正则表达式外部,不能用「\1」反向引用(而应该使用$1)。变量$1对应上次成功匹配中的某个固定字符串。「\1」则是正则表达式元字符,它对应正则引擎遇到「\1」时第一组捕获型括号捕获的文本。在NFA的回溯过程中,它的值可能会变化。
与之对应的问题是,正则运算元中是否能够使用$1之类的变量。通常,在内嵌代码或者动态正则结构(☞327)中可用,在其他情况下就没什么意义。出现在运算元中“表达式部分”的$1与其他变量一样处理:在匹配或替换操作开始时插值。也就是说,对正则表达式而言,$1与当前的匹配没什么关系,它属于上一次匹配。