Perl Efficiency Issues
在大多数情况下,Perl中正则表达式的效率问题与任何使用传统NFA的工具一样。第6章介绍的技巧——内部优化、消除循环,以及“开动你的大脑”,都适用于Perl。
当然,Perl也有专属于自己的问题,这一节我们就来看看:
●办法不止一种 Perl就像一个工具箱,同一种问题可以用许多办法来解决。理解了Perl的思维方式,就会明白哪些问题是钉子,但是选择合适的锤子还需要花很多工夫来编写高效而易于理解的程序。有时候,效率和易于理解似乎是不相容的,不过一旦理解深入了,就能做出更好的选择。
●表达式编译、qr/…/、/o 修饰符和效率 正则运算符的编译和插值,做得好的话能节省大量的时间。/o 修饰符还没有详细讲解,它配合 regex 对象(qr/…/),能够调控耗费时间的重编译过程。
●$&的负面影响 伴随效应设定的变量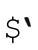 、$&和
、$&和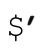 ,也许很方便,但存在不易发现的效率陷阱,哪怕只出现了一次,也可能带来麻烦。所以并不是非得使用它们——只要脚本中出现了任意一个变量,负面影响就不可避免。
,也许很方便,但存在不易发现的效率陷阱,哪怕只出现了一次,也可能带来麻烦。所以并不是非得使用它们——只要脚本中出现了任意一个变量,负面影响就不可避免。
●Study 函数 近年来,Perl 提供了 study(…)函数。按照预期,它能提高正则表达式的速度,但是似乎没有人真正知道它是否能提高速度,以及背后的原因。
●性能测试 性能测试的规矩就是,越快的程序终止得越早(你可以引用我的话)。无论小型函数、大型函数,还是处理真实数据的整个程序,性能测试都是判断速度的最终标准。尽管性能测试有各种各样的办法,Perl 中的性能测试却是简单而轻松的。我会给出我用的办法,这个办法在写作本书时做过数百次性能测试。
●正则表达式调试 Perl的正则表达式调试标识位(debug flag)可以告诉我们,正则引擎和传动装置对正则表达式进行了哪些优化。下面会讲解如何查看这些信息,以及 Perl包含了哪些秘密。
办法不只一种
"There's More Than One Way to Do It"
通常,一个问题总是有许多种解法,所以在权衡效率和可读性时,应该做的就是了解所有的办法。来看个简单的问题,修改一个IP地址,例如‘18.181.0.24’,保证每一段都包含三位数字:‘018.181.000.024’。简单的办法是:
$ip=sprintf("%03d.%03d.%03d.%03d",split(/\./,$ip));
这办法当然没错,但显然还有其他的解决办法。表7-6列出了好几种办法,比较了它们的效率(按照效率排序,最上面的效率最高)。这个例子的目的很简单,本身也没有太多价值,但是它能代表简单的文本处理任务,所以我鼓励你花一点时间理解各种办法。可能有些技巧你没见过。
如果输入格式正确的 IP,每个办法都能到正确的结果,但是如果输入别的数据则可能会出错。如果数据是不规范的,可能就需要多花点心思。除此之外,实际差别在于效率和可读性。就可读性而言,#1和#13似乎是最好理解的(尽管效率上存在巨大的差异)。同样易于理解的是#3和#4(类似#1),以及#8(类似#13)。其他解法都太过复杂了。
那么效率呢?为什么不同的解法有不同的效率?原因在于NFA的工作原理(第4章),Perl的各种正则优化措施(第 6 章),以及其他 Perl 结构的处理速度(例如 sprintf,以及substitution运算符的机制)。substitution运算符的/e修饰符,有时候虽然不可或缺,但效率低的解法似乎都使用了它。
比较#3和#4,#8和#14很有意义。这两对正则表达式的区别只是在于括号——没有括号的表达式要比有括号的稍快一点。#8使用$&来避免括号带来的高昂代价,性能测试却无法体现这一点(☞355)。
表达式编译、/o修饰符、qr/…/和效率
Regex Compilation,the/o Modifier,qr/…/,and Efficiency
Perl中与表达式效率相关的另一个重点是,程序遇到正则运算符之后,在实际应用正则表达式前,Perl必须在幕后进行预处理工作。真正的准备工作依赖于正则运算元的类型。在大多数情况下,正则运算元是正则文字,例如m/…/、s/…/…/或qr/…/。Perl必须对它们进行幕后处理,而处理需要的时间,如果可能应该尽力避免。首先,让我们来看要做的事情,然后讲解如何避免。
表7-6:填补IP地址的若干解法

预处理正则表达式的内部机制
预处理正则运算元的机制在第6章有所涉及(241),不过Perl还有自己的处理。
Perl对正则运算符的预处理大致分为两步:
1. 正则文字处理 如果运算符是正则文字,就按照“正则文字的解析方式”(☞292)中的描
述来处理。变量插值就发生在这一步。
2. 正则编译 检查正则表达式,如果符合规则,就将其编译为适用于正则引擎实际应用的内
在状态(如果不符合规则,则报错)。
正则表达式编译完成之后,就能够实际应用到目标字符串中,参见第4到第6章。
并不是每使用一次正则运算符,就需要进行一次预处理。但是正则文字第一次使用时,必须进行预处理,但如果多次执行同样的正则文字(例如在循环中,或是调用多次的函数),Perl 有时候能够重用之前的工作。下一节说明了 Perl 如何做到这一点,以及程序员可以使用的提高效率的技巧。
减少正则编译的步骤
下面几节中我们会见到 Perl 避免某些正则文字相关预处理的两种办法:无条件缓存(unconditional caching)和按需重编译(on-demand recompilation)。
无条件缓存
如果正则文字中没有插值变量,Perl就知道这个正则表达式在两次应用之间不会变化,所以第一次编译完成之后,会保存编译的形式(“缓存”),以备将来使用。无论正则表达式会执行多少次,只需要检查和编译一次。本书中的大多数正则表达式都没有变量插值,因此从这个方面来说效率无可挑剔。
内嵌代码和动态正则结构中的变量则不属于此类,因为它们不会插值到正则表达式中,而是作为正则表达式执行的固定代码的一部分。有时候,你可能希望每次执行都解释内嵌代码中引用的my变量,请不要忘记第338页的忠告。
有一点要说清楚,缓存的持续时间与代码的执行时间相同,下次运行同样代码时不会有任何的缓存。
按需重编译
并不是所有的正则运算元都能够直接缓存,比如下面的代码:

m/^$today:/中的正则表达式需要插值,虽然在循环中使用,但每轮循环的插值结构是相同的。所以一再重复编译同样的表达式的效率很低,所以 Perl 会自动进行简单的字符串检查,比较本次和上次插值的结果。如果相同,就使用上次的缓存。如果不同,就重新编译正则表达式。所以,对比缓存值并重新插值尽可能避免了相对更耗时的编译。
这样究竟能节省多少时间呢?非常多。举例来说,我测试了第303页的$HttpUrl(使用扩展的$HostnameRegex)的三种预处理方式。设计的性能测试能准确体现预处理的开销(使用插值、字符串检查、编译,以及其他后台任务),而不是表达式应用的整体开销,因为在任何情况下这种应用的时间都是一样的。
结果非常有意思。我运行了没有插值的版本(整个正则表达式都硬编码在 m/…/中),用它作为比较的基础。如果正则表达式每轮循环不会改变,比较并插值大概需要25倍的时间。完整的预处理(每轮循环都要重新编译)大概需要1 000倍的时间,这数字真惊人!
应用到实际场合就会发现,完整的预处理即使比静态正则文字预处理要慢1 000倍,在我的机器上也只需要大约0.00026秒(测试的速度是每秒3 846次,相反,静态正则文字预处理的速度是每秒370万次)。当然,不使用插值能够节省的时间非常可观,不进行重编译节省的时间显然也很可观。下面几节,我们会考察如何在更多情况下使用这些技巧。
表示“一次性编译”的/o修饰符
简单地说,如果正则文字运算元中使用了/o修饰符,它就会只会检查和编译一次,而无论是否包含插值。如果没有插值,添加/o不会有任何改变,因为没有插值的表达式总是会自动缓存。但如果使用了插值,程序执行第一次遇到正则文字时,会进行正常的完整的预处理,但因为/o的存在,内在状态会存储下来。如果之后又遇到这个正则运算元,就会直接调用缓存。
下面这个例子之前也出现过,只是现在添加了/o:

这个表达式要快得多,因为从第二次开始的每轮循环中,正则表达式都忽略了$today。不需要插值,也不需要预处理和重新编译正则表达式,能够节省大量的时间,而这是 Perl 无法自动完成的,因为使用了变量插值,$today可能会变化,所以为了安全,Perl必须每次都检查。使用/o就告诉 Perl,在第一次预处理和编译完成之后“锁定”这个表达式。因为我们知道,插值变量是不变的,即使变化了,也不希望使用新值,所以这样做完全没问题。
/o的潜在“陷阱”
在使用/o时,有个重要的“陷阱”必须要注意。例如下面这个函数:

记住,/o表示正则运算元只需要编译一次。第一次调用CheckLogfileForToday()时,代表当天日期的正则运算元就锁定在其中。如果过了一段时间再次调用这个函数,即使$today变化了,也不会重新检查;在程序执行过程中,每次使用的都是最开始锁定在其中的正则表达式。
这个问题很严重,不过下一节中,regex对象提供了两全其美的解决办法。
用regex对象提高效率
迄今为止,我们看到的所有关于预处理的讨论都适用于正则文字。其目的在于花尽可能少的工夫获得编译好的正则表达式。达到此目的的另一个办法是使用regex对象,把编译好的正则表达式封装在变量内部供程序使用。可以使用qr/…/创建regex对象(☞303)。
下面是使用regex对象的例子:

每调用一次函数,就会创建一个新的regex对象,但是之后它只是直接用于log文件的每一行。如果regex对象用做运算元,它不会进行前面介绍的任何预处理。预处理是在regex对象创建而不是使用时进行的。可以把regex 对象想象为“自动设定的正则缓存”,这个编译好的表达式可以在任何地方使用。
这个办法兼具了两方面的优点:它效率高,因为只有在每次函数调用(而不是log文件的每一行)时才会编译,但是,与之前错误使用/o的例子不同,即使多次调用CheckLogfile-ForToday(),也没有问题。
需要弄清楚的是,这个例子中出现了两个正则运算元。正则运算元qr/…/并不是一个regex对象,但能从接收的正则文字创建 regex 对象。然后这个对象用作循环中 match 运算符=~的运算元。
regex对象配合m/…/
这段程序:
if ($_=~$RegexObj) {
也可以这样写:
if (m/$RegexObj/) {
此时已经不是普通的正则文字了,尽管看上去没有区别。“正则文字”的内容就是regex 对象,它与直接使用regex 对象一样。这种做法的好处在于:m/…/更为常见,更容易使用。也不用明确指定目标字符串$_,方便与其他使用同样默认变量的运算符结合。最后一个原因是,这样我们能够对regex对象使用/g。
/o配合qr/…/
/o修饰符可以配合qr/…/,但在这里你肯定不希望如此。就像用/o配合其他任何正则运算符一样,qr/…/o在第一次使用正则表达式时就会进行锁定,所以如果这样写,无论$today如何变化,每次调用这个函数$RegexObj使用的都是同样的 regex 对象。这与第 352 页的m/…/o的问题一样。
依靠默认表达式提高效率
正则运算符的默认表达式(☞308)可以提高效率,尽管使用 regex 对象可能更划算。不过我还是会简要介绍一番。例如:

使用默认正则表达式的关键在于,只有匹配成功才会设置默认值,所以$today设置之后还有长长的代码。你已经看到,这相当不美观,所以我不推荐这么做。
理解“原文”副本
Understanding the"Pre-Match"Copy
在匹配和替换时,Perl 有时必须动用额外的空间和时间来保存目标字符串在匹配之前的副本。我们会看到,有时这个副本会用于支持重要特性,有时则不会。应该尽量避免不会用到的副本,提高效率,尤其是在目标字符串很长,或者速度非常重要的情况下更是如此。
下一节我们会讲解何时以及为什么 Perl 可能会保存目标字符串的原文副本,什么时候用到副本,以及在效率极端重要时,如何取消这个副本来提高效率。
通过原文副本支持$1、$&、$'、$+…
对于match或者substitution操作的目标字符串,Perl会生成一个原文副本,以支持$1、$&之类匹配后的变量(☞299)。每次匹配完成之后,Perl不会实际生成这些变量,因为许多变量(还有可能是所有)根本不会被程序用到。相反,Perl只是保存原始字符串的副本,记住各种匹配发生在原来文本中的位置,在使用$1之类变量时通过位置来引用。这种办法不错,工作量小,因为多数情况下都不会用到某些甚至全部的匹配后的变量。这种“延迟求值(lazy evaluation)”能避免许多不必要的工作。
尽管延迟创建$1之类的变量能够节省工作量,但保存目标字符串的副本仍然需要成本。而这是必要的吗?为什么不能直接使用原来的文本?请参考:
$Subject=~s/^(?:Re:\s*)+//;
这样,$&正确地引用了$Subject 中删除的文本,但因为它已经从$Subject 中删除,在后面用到$&时,Perl不能从$Subject中引用这段文本。下面的代码情况相同:

引用$1时,原来的$Subject已经删除了。所以,Perl必须保存原文副本。
原文副本并非时时必须
在实践中,原文副本的主要“用户”是$1、$2、$3之类的变量。但是如果正则表达式不包含捕获型括号呢?那样就不必担心$1之类了,所以完全不必考虑如何支持它们。所以至少,不包含捕获型括号的正则表达式可以不必保存拷贝?答案是未必。
不宜使用的变量:
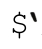 、$&和$
、$&和$
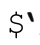 、$&、
、$&、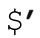 这三个变量与捕获型括号无关。它们分别对应到匹配文本之前的部分,匹配文本和匹配之后的部分,其实可以应用于每一次match和substitution。Perl不能预先知道某个匹配中是否会用到这些变量,所以每次都必须保存原文副本。
这三个变量与捕获型括号无关。它们分别对应到匹配文本之前的部分,匹配文本和匹配之后的部分,其实可以应用于每一次match和substitution。Perl不能预先知道某个匹配中是否会用到这些变量,所以每次都必须保存原文副本。
听起来,似乎没有办法省略副本,但是 Perl 足够聪明,它能够认识到,如果这些变量不会出现在程序中,就根本没必要(甚至在任何可能用到的library之中)保存副本来提供支持。所以,如果没有用到捕获型括号,再避免出现、$&和就能省略原文副本——这是很棒的优化!只要在程序中的任何一处用到了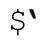 、$&和
、$&和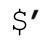 三者之一,整个优化即告失效。这可不够意思!所以,我认为这些变量是“不宜使用(naughty)”的。
三者之一,整个优化即告失效。这可不够意思!所以,我认为这些变量是“不宜使用(naughty)”的。
原文副本的代价有多高
我进行了简单的性能测试,对Perl源代码的130 000行C程序中的每一行检查m/c/。这个性能测试仅仅检测哪一行出现了字符‘c’。测试的目的是衡量原文副本的影响。我用两种方法进行测试:一种肯定没有用到原文副本,一种肯定用到了。因此,唯一的区别就在于保存副本的开销。
保存原文副本的程序所用的时间要长40%。这代表了“平均最差情况”,这样说是因为性能测试并没有进行什么实质性的操作,否则二者之间的时间相对比例会减小(甚至显得微不足道)。
另一方面,在真正的最坏情况下,额外副本可能真的占据非常重要的比重。我对同样的数据运行同样的程序,但是这次将所有超过3.5MB的数据都放在一行中,而不是长度合适的130 000行。这样就能比较单次匹配的相对表现。不使用原文副本的匹配几乎是立刻就得到了结果,因为第一个‘c’字符离开头不远,匹配之后程序就运行结束。而使用原文副本的程序运行原理差不多,只是它会首先拷贝整个字符串。它所用的时间大约是前者的7 000倍。因此我们知道,避免使用某些结构能够提高效率。
避免使用原文副本
如果 Perl 能够领会程序员的意图,只在需要的情况下保存副本,当然很好。但请记住,这些副本并不是“败笔”——Perl在幕后处理这些繁琐事务是我们选择Perl,而不是C或者汇编语言的原因。事实上,Perl最初只是为了把用户从繁杂的机制中解放出来,这样他们只需要关注问题的解决方案就好了。
永远不要使用不宜使用的变量。同样,尽可能避免额外的工作也是不错的。首先想到的就是,永远不要在代码中使用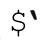 、$&和
、$&和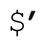 。通常,$&很容易消除——把正则表达式包围在一个捕获型括号内,然后使用$1 即可。举例来说,把 HTML tag 转换为小写时,不使用s/<\w+>/\L$&\E/g,而使用s/(<\w+>)/\L$1\E/g。
。通常,$&很容易消除——把正则表达式包围在一个捕获型括号内,然后使用$1 即可。举例来说,把 HTML tag 转换为小写时,不使用s/<\w+>/\L$&\E/g,而使用s/(<\w+>)/\L$1\E/g。
如果保存了原始目标字符串,就可以很容易地模拟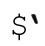 和
和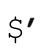 。匹配某个target字符串之后,可以按下面的规则来模拟:
。匹配某个target字符串之后,可以按下面的规则来模拟:

因为@-和@+(302)保存的是原始目标字符串中的位置,而不是确切的文本,使用它们不需要担心效率问题。
我还给出了$&的模拟。相对使用捕获型括号和$1的办法,这可能是一个更好的办法,这样完全不必使用任何捕获型括号。请记住,避免使用$&之类变量的目的就在于,如果表达式中没有出现捕获型括号,要避免保存原始副本。如果修改程序,去掉$&,再对每个匹配都增加捕获型括号,就不会节省任何时间。
不要使用不宜使用的模块。当然,避免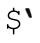 、$&、
、$&、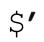 也意味着避免使用调用它们的模块。Perl的核心模块中,除English之外都没有使用它们。如果你希望使用English模块,可以这样:
也意味着避免使用调用它们的模块。Perl的核心模块中,除English之外都没有使用它们。如果你希望使用English模块,可以这样:
use English'-no_match_vars';
这样就没有问题了。如果你从 CPAN 或者其他地方下载了模块,你可能需要检查一番,看看它们是否使用了这些变量。请参考下一页的补充内容,里面有些诀窍,告诉你如何判断程序是否用到了这些变量。

Study函数
The Study Function
与优化正则表达式本身不同,study(…)优化了对特定字符串的某些检索。一个字符串在study 之后,应用到它的(一个或多个)正则表达式可以从缓存的分析数据中受益。一般是这样使用的:

study 的作用很简单,但是理解它什么情况下有价值却不简单。它不会影响到程序的任何值和任何结果,唯一的影响就是,Perl会使用更多的内存,总的执行时间可能会增加,保持不变,或者减少(这是我们预期的)。
study一个字符串时,Perl会分配时间和内存来记录字符串中的一系列位置(在大多数系统中,需要的内存是字符串大小的4倍)。在字符串修改之前,针对此字符串的每次匹配都可以从中受益。对字符串的任何修改都会导致study数据的失效,相当于study另一个字符串。
Study 能给目标字符串提供的帮助,很大程度上取决于用来匹配的正则表达式,以及 Perl能够使用的优化。例如用m/foo/检索文本,如果使用了study,速度会提升很多(如果字符串更长,甚至可能提高 10 000 倍)。但是,如果使用了/i,就不会有这种效果,因为/i不会利用study的结果(和其他优化)。
不应该使用study的情况
●如果只使用/i,或是所有正则文字都受「(?i)」或「(?i:…)」作用,就不应该对字符串使用study,因为它们不能从study中受益。
●如果目标字符串很短,也不应该使用 study。因为此时,正常的固定字符串识别优化(☞247)已经足够了。那么“短”究竟如何界定呢?字符串的长度没有确切的标准,所以具体来说,只有进行性能测试才能判断study是否有益。不过权衡利弊,我通常不使用study,除非字符串的长度为若干KB。
如果你只希望在修改之前,或是 study不同的字符串之前,对目标字符串进行少数几次匹配,请不要使用 study。如果要获得真正的性能提升,必须是多次匹配节省下来的时间长于study的时间。如果匹配次数较少,花在study身上的时间抵不上节省的时间,得不偿失。
只对期望使用包含“独立出来的”文字(☞255)的正则表达式搜索的字符串使用study。如果不知道匹配中必须出现的字符,study 就派不上用场(看了这几条,也许你会认为,study对index函数有益,但事实并非如此)。
什么时候使用study
最适合使用 study的情况就是,目标字符串很长,在修改之前会进行许多次匹配。一个简单的例子就是我在写作本书时所用的过滤器。我用自己的标记法写稿,然后用过滤器转换为SGML(再转换为troff,再转换为PostScript)。经过过滤器内部,一整章变为一个大字符串(例如,本章的大小为475KB)。在退出之前进行多项检查来保证不会漏过错误的标记。这些检查不会修改字符串,它们通常查找固定长度的字符串,所以它们很适合于study。
性能测试
Benchmarking
如果你真的关心效率,最好的办法就是进行性能测试。Perl 自带的 Benchmark模块提供了详细的文档("perldoc Benchmark")。可能是习惯使然,我更喜欢从自己动手写性能测试:
use Time::HiRes'time';
我把希望测试的内容简单包装成:

性能测试的重要问题包括,确保性能测试进行了足够多的工作,显示的时间真正有意义,尽可能多地测试希望的部分,尽可能少地测试不希望的部分。在第 6 章有详细的讲解(☞232)。找到正确的测试方法可能得花些时间,但是结果可能非常有价值,也很值得。
正则表达式调试信息
Regex Debugging Information
Perl提供了数量众多的优化措施,期望能够尽可能快地找到匹配;第6章的“常见优化措施”(☞204)介绍了基础的措施,但还有许多其他的措施。大多数优化只能应用于专门的情况,所以特定正则表达式只能从其中的某一些(甚至是没有)获益。
Perl的调试模式(debugging mode)能提供优化的信息。在正则表达式第一次编译时,Perl会选择这个正则表达式所使用的优化措施,而调试模式会显示其中的一部分。调试模式同样可以告诉我们引擎是如何应用表达式的。仔细分析这些调试信息不属于本书的范围,但我会在这里给出简要介绍。
在程序中可以通过 use re'debug';来显示调试信息,用 no re'debug';来关闭(上文曾出现过编译指示use re,根据不同的参数,启用或禁用插值变量中的内嵌代码☞337)。
如果希望在整个脚本中启用此功能,可以使用命令行参数-Mre=debug。这很适合检查单个的正则表达式的编译方法。下面是一个例子(只保留了相关的行):

在∂处从shell提示符启动perl,使用命令行参数-c(意思是检查脚本,而不是确切执行它),-w(如果Perl对代码存有疑问,就会发出警报),以及-Mre=debug启用调试。-e表示下面的参数‘m/^Subject:·(.*)/’是一段Perl代码,需要运行或者检查。
÷行报告表达式固定长度的字符串中“出现频率最低”的字符(由 Perl 猜测)。Perl 根据这一点进行某些优化(例如预查所需字符/子串☞245)。
第≠到≈行表示Perl编译好的正则表达式。因为篇幅的原因,我们在这里不会花太多的工夫。不过,即使是随便看看,第≡行也不难理解。
第…行对应大多数行为。可能显示的信息包括:
Anchored'string'at offset
它表示匹配必须包含某个字符串,此字符串在匹配中的偏移值为 offset。如果$紧跟在'String'之后,那么string是匹配结尾的元素。
floating'string'at from..to
它表示匹配必须包含某个字符串,此字符串在匹配中处于从from(开始)到to(结束)中的任意位置。如果$紧跟在'String'之后,string是匹配结尾元素。
stclass'list'
它表示匹配可能的开始字符。
anchored(MBOL),anchored(BOL),anchored(SBOL)
说明表达式以「^」开头。MBOL说明使用了/m修饰符,BOL和SBOL表示没有使用(BOL和SBOL的区别在现代Perl中没有意义。SBOL与$*变量有关,而此变量已被废弃了)。
anchored(GPOS)
说明正则表达式以「\G」开头。
implicit
说明anchored(MBOL)是由Perl隐式添加的,因为正则表达式以「.* 」开头。minlen length
代表匹配成功的最小长度。
with eval
说明表达式包含「(?{…})」或是「(??{…})」。
第|行与正则表达式无关,只有当二进制代码中的编译启用了-DDEBUGGING时才会出现。如果启用,在载入整个程序之后,Perl会报告是否启用了对$&等变量的支持(☞356)。
运行时调试信息
我们知道如何利用内嵌代码获得匹配的运行信息(☞331),但是 Perl 的正则表达式调试可以提供更多的信息。如果去掉表示“仅编译”的-c选项,Perl 会提供更多关于匹配运行细节的信息。
出现“Match rejected by optimizer,”表示某种优化措施让传动装置认识到,这个正则表达式永远无法在目标字符串中匹配,所以会忽略任何尝试,下面是一个例子:

如果启用了调试功能,用户可以看到所有用到的正则表达式的调试信息,而不只限于用户提供的正则表达式。例如:

它没有进行任何操作,只是装载了 warning模块,但是因为这个模块包含正则表达式,我们仍然会见到许多调试信息。
显示调试信息的其他办法
我已经提到,可以使用“use re'debug';”或-Mre=debug来启用正则表达式的调试。不过,如果把所有的 debug替换为 debugcolor,而终端又支持ANSI 转义控制字符(ANSI terminal control escape sequences),输出的信息就会以高亮标记,更容易阅读。
另一个办法是,如果 Perl 二进制代码在编译时启用了调试支持,可以使用命令行参数-Dr来表示-Mre=debug。