Modifying Text with Regular Expressions
到现在,我们遇到的例子都只是从字符串中“提取”信息。现在我们来看 Perl 和其他许多语言提供的一个正则表达式特性:替换(substitution,也可以叫“查找和替换(search and replace)”)。
我们已经看到,$var=~m/regex/尝试用正则表达式来匹配保存在变量中的文本,并返回表示能否匹配的布尔值。与之类似的结构$var=~s/regex/replacement/则更进一步:如果正则表达式能够匹配$var中的某段文本,则将这段匹配的文本替换为replacement。其中regex与之前m/…/的用法一样,而replacement(位于第二个和第三个斜线之间)则是作为双引号内的字符串。这就是说,在其中可以使用变量——例如$1、$2——来引用之前匹配的具体文本。
所以,使用$var=~s/…/…/可以改变$var中的文本(如果没有找到匹配的文本,也就不会有替换发生)。例如,如果$var包括Jeff·Friedl,运行:
$var=~ s/Jeff/Jeffrey/;
$var的值就变成 Jeffery·Friedl。如果再运行一次,就得到 Jeffreyrey·Friedl。要避免这种情况,也许我们需要添加表示单词分界的元字符。在第 1 章我们提到过,某些版本的egrep支持「\<」和「\>」作为“单词起始”和“单词结束”的元字符。Perl提供了统一的元字符「\b」来代表这两者:
$var=~s/\bJeff\b/Jeffrey/;
这里有个小测验:与m/…/一样,s/…/…/也可以使用修饰符,例如第47页介绍的/i(将这个修饰符放在replacement之后)。那么,这个表达式:
$var=~s/\bJeff\b/Jeff/i;
的功能是什么呢?ϖ请翻到下页查看答案。
例子:公函生成程序
Example:Form Letter
下面这个有趣的例子展示了文本替换的用途。设想有一个公函系统,它包含很多公函模板,其中有一些标记,对每一封具体的公函来说,标记部分的值都有所不同。
这里有一个例子:

对特定的接收人,变量的值分别为:
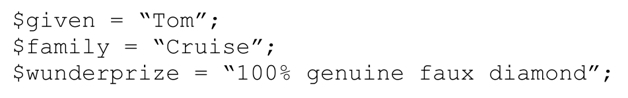
准备好之后,就可以用下面的语句“填写模板”:

其中的每个正则表达式首先搜索简单标记,找到之后用指定的文本替换它。用于替换的文本其实是 Perl 中的字符串,所以它们能够引用变量,就像上面的程序那样。例如,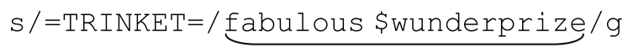 中下画线部分在程序运行时的值就是“fabulous$wunderprize”。如果只需要生成一份公函,完全可以不用变量替换,直接照需要的样子生成就是。但是,使用变量替换能够实现自动化的操作,例如可以从一个清单读入信息。
中下画线部分在程序运行时的值就是“fabulous$wunderprize”。如果只需要生成一份公函,完全可以不用变量替换,直接照需要的样子生成就是。但是,使用变量替换能够实现自动化的操作,例如可以从一个清单读入信息。
我们还没介绍过/g“全局替换”(global replacement)的修饰符。它告诉s/…/…/在第一次替换完成之后继续搜索更多的匹配文本,进行更多的替换。如果需要检查的字符串包含多行需要替换的文本,每条替换规则都对所有行生效,我们就必须使用/g。
结果是可以预见的,不过相当有趣:

举例:修整股票价格
Example:Prettifying a Stock Price
另一个例子是,我在使用 Perl 编写的股票价格软件时遇到的问题。我得到的价格看起来是这样“9.0500000037272”。这里的价格显然应该是 9.05,但是因为计算机内部表示浮点的原理,Perl有时会以没什么用的格式输出这样的结果。我们可以像温度转换例子中的那样用printf来保证只输出两位小数,但是此处并不适用。当时,股价仍然是以分数的形式给出的,如果某个价格以1/8结尾,则应该输出3位小数(“.125”),而不是两位。

我把自己的要求归结为:通常是保留小数点后两位数字,如果第三位不为零,也需要保留,去掉其他的数字。结果就是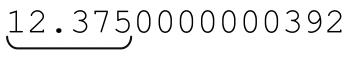 或者
或者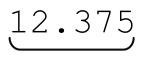 会被修正为“12.375”,而
会被修正为“12.375”,而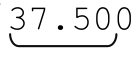 被修正为“37.50”。这就是我要的结果。
被修正为“37.50”。这就是我要的结果。
那么,我们该如何做呢?$price变量包含了需要修正字符串,让我们用这个表达式:
$price=~s/(\.\d\d[1-9]?)\d*/$1/
(提示:49页介绍了「\d」这个元字符,它用来匹配一个数字字符。)
最开始的「\.」匹配小数点。接下来的「\d\d」匹配开头的两位数字。「[1-9]?」匹配可能跟在后面的非零数字。到这里,任何匹配的文本都是我们希望保留的,所以我们用括号把它保存到$1中。然后将$1放入replacement字符串中。如果能够匹配的文本就是$1,我们就用$1替换$1——这样做没什么意义。但如果在$1的括号之外还有能够匹配的字符,因为它们没有出现在replacement字符串中,所以会被删除。也就是说,“被删除的”文本是其他多余的数字,也就是正则表达式末尾「\d*」匹配的字符。
请记住这个例子,在第 4 章我们会学习匹配过程背后的重要原理,那时候还会遇到这个例子。研究它可以学到非常有价值的知识。
自动的编辑操作
Automated Editing
写作本章时,我遇到了另一个简单但真实存在的例子。当时我需要登录到太平洋对岸的一台机器上,但是网速非常慢。按下回车得等一分多钟才能见到反应,而我只需要对某个文件进行一些小的改动,运行一个重要的程序。实际上,我要做的只是将出现的所有sysread改为read。改动的次数并不多,但因为网络太慢,使用全屏编辑器显然是不可能的。
下面是我的办法:
% perl-p-i-e's/sysread/read/g'file
这条命令中的Perl程序是 s/sysread/read/g(是的,这就是一个完整的Perl程序——参数-e 表示整个程序接在命令的后面)。参数-p 表示对目标文件的每一行进行查找和替换,而-i表示将替换的结果写回到文件。
请注意,这里没有明确写出查找和替换的目标字符串(就是说,没有 $var=~…),因为-p参数就表示对目标文件的每行文本应用这段程序。同样,因为我用了/g这个修饰符,就可以保证在一行文本中可以进行多次替换。
尽管在这里我只是对一个文件进行操作,但也很容易在命令行中列出多个文件,而 Perl 会把替换命令应用到每个文件的每一行文字。这样,只需要一条简单的命令,我就能够编辑大量的文件。这样简单的编辑方式是 Perl 独有的,但这个例子告诉我们,即使执行的是简单的任务,作为脚本语言一部分的正则表达式的功能仍然非常强大。
处理邮件的小工具
A Small Mail Utility
来看另一个小工具的例子。一个文件中保存着E-mail 信息,我们需要生成一个用于回复的文件。在准备过程中,我们需要引用原始的信息,这样就能很容易地把回复插入各个部分。在生成回复邮件的header时,我们还需要删除原始信息邮件的header中不需要的行。
下一页的补充内容是一个邮件文件的范本。header 包含了我们关心的字段:日期、主题等——但也包括了我们不关注的字段,这些字段需要删除。如果我们的脚本程序叫做mkreply,而原始的信息保留在king.in中,我们会用下面的命令来生成回复模板:
% perl-w mkreply king.in > king.out
(-w它用来打开Perl的额外警告功能,☞38)

我们希望程序的输出结果king.out包括下面的内容:

现在我们来分析。为了生成新的 header,我们需要知道目标地址(即本例中的 [email protected],来自原始信息中的 Reply-To 字段),收件人的姓名(The King),我们自己的地址和姓名,以及主题。另外,为了生成邮件正文的导入部分(introductory line),我们还需要知道原始邮件的日期。
这些工作可以分为下面3步:
1.从原始邮件的header中提取信息;
2.生成回复邮件header;
3.打印原始邮件信息,行首用‘|>·’缩进。
这样考虑有点超前了——在没有决定程序如何读入数据之前,就关心起如何处理数据了。幸运的是,Perl提供了神奇的“<>”操作符。在应用到变量$variable时,使用“$variable=<>”,这个有趣的结构能够每次读入一行数据。输入的数据来自命令行中Perl脚本之后列出的文件名(例如上面例子中的king.in)。
请不要混淆操作符<>与Shell的重定向符号“>filename”或者是Perl的大于/小于号。Perl中的<>相当于其它语言中的getline()函数。
读入所有输入数据之后,<>很方便地返回未定义的值(作为布尔值处理),所以整个文件可以这样处理:

我们会用类似的办法来处理邮件,但是邮件本身的性质决定了我们必须对邮件 header 特殊处理。第一个空行之前的信息是header,之后的则是正文部分。为了只读入header,我们可以使用下面这段代码。

我们用「^\s*$」来检查表示邮件header结束的空行。这个正则表达式检查的是,当前的文本行是否有一个行开头(其实每一行都有,由脱字符匹配),然后跟着任意数目的空白字符(尽管我们并不期望有任何空白字符),然后字符串结束(注3)。关键词last会跳出while循环,停止处理header。
所以,在循环内部,在空行检测之后,我们能够按照自己的想法来处理 header 的每一行。在本例中,我们希望提取信息,例如邮件的主题和时间。
要提取主题,我们可以使用一个常见的技巧:

这段代码尝试匹配一个以‘Subject:·’开头,但不区分Subject大小写的字符串。如果能够匹配,后面的「.*」匹配这一行的其他部分。因为「.*」在括号中,所以之后我们能用$1 来访问邮件的主题。在这个例子中,我们希望把它保存到变量$subject中。当然,如果正则表达式无法匹配这个字符串(大多数情况下都不能),结果就是 if语句返回结果为false,$subject变量没有变化。

我们可以用同样的办法来处理Date和Reply-To字段:

From:所在的行稍微麻烦一点。首先,我们需要找到以‘From:’开头的行,而不是以‘From·’开头的第一行。我们需要的是:
From:[email protected] (The King)
它包含了邮件的发送地址,发送者的姓名在括号内,我们要提取的是姓名(译注1)。
我们用「^From:·(\S+)」来提取发送地址。你可能猜到了,「\S」匹配的是所有的非空白字符(☞49),所以「\S+」匹配第一个空白之前的文本(或者目标文本末尾之前的所有字符)。在本例中,就是邮件的发送地址。匹配之后,我们希望匹配括号内的文字。显然,此处也需要匹配括号本身。我们用「\(」和「\)」来匹配,转义之后的括号不再具有特殊的含义。在括号内,我们希望匹配任何字符——除了括号之外的任何字符,所以采用「[^()]*」。记住,字符组的元字符不同于正则表达式的“普通”元字符,在字符组内部,括号不再具有特殊含义,因此也不需要转义。
综合起来,我们得到:
「^From:·(\s+)·\(([^]*)\)」
其中的括号有点多,初看起来不太好懂,图2-4解释得更清楚:
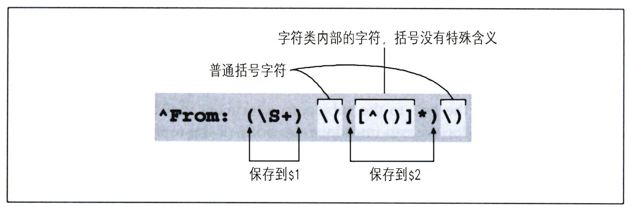
图2-4:嵌套的括号,$1和$2
如果图2-4的正则表达式能够匹配,我们可以通过$2得到发送者的姓名,从$1得到可能的回复地址。

并非所有的E-mail信息都包含Reply-To字段,所以我们把$1暂定为回复地址。如果之后出现了$Reply-To字段,我们会重设$reply_address。综合起来就得到:

这段程序检查header的每一行,如果某个正则表达式能够匹配,则设置相应的变量。header的许多行无法由这些正则表达式匹配,所以会被忽略。
while循环结束之后,我们就能够生成回复邮件的header了(注4):

请注意,我们在主题之前加上了 Re:,表示这是一封回复邮件。最后,在 header 之后,我们列出原始邮件的内容:
print "On $date $from_name wrote:\n";
对于其他的输入信息(也就是原始邮件的正文部分),我们在每一行之前添加‘|>·’提示符:
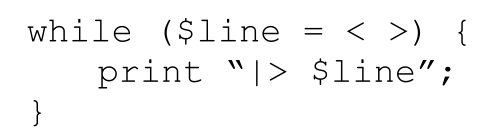
有意思的是,这段程序也可以用另一种方法,使用正则表达式来加入引用提示符:
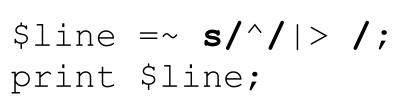
这条替换命令寻找「^」,在每个字符串的起始位置匹配。这条替换命令把字符串开头那个“不存在的字符”“替换”为‘|>·’,其实并没有替换任何字符,只是在字符串的开头加入‘|>·’。在本例中这样做有点滥用的嫌疑了,但是我们将在本章中看到类似(但更有用)的例子。
真实世界的问题,真实世界的解法
既然摆出了一个真实世界的例子,就应该指出这个解法在真实世界中的缺憾。我已经说过,这些例子的目的在于展示正则表达式的使用方法,而 Perl 程序不过是展示的手段。我使用的 Perl 程序并不一定使用了最有效或者最好的解法,但是,我希望它能说明正则表达式的用法。
同样,真实世界的邮件信息比这个简单问题中的邮件信息复杂很多。From:这一行就可能有许多种格式,而我们的程序只能处理一种。如果真正的From:这一行无法匹配我们的模式,则$from_name变量就不会设置,使用时保持在未定义的状态(也就是“没有值”的值的一种)。理想的解决办法是修改这个正则表达式,让它能够处理各种不同的邮件地址/姓名格式,不过,作为第一步,在检查原始邮件之后(生成回复模板之前),我们可以这样:

Perl的defined函数检查一个变量是否设置了值,而die函数用来发出错误信息,退出程序。
另一点需要考虑的是,程序假设 From:这一行出现在 Reply-To:之前。如果 From:出现在之后,就会覆盖从Reply-To取得的$reply_address。
“真正的”真实世界
发送电子邮件的程序有许多类,每类程序对标准的理解都不一样,所以处理电子邮件并不是件简单的事情。我曾经想用 Pascal 程序来处理电子邮件,但我发现,如果没有正则表达式,处理起来极其困难,困难到我决定先用Pascal写一个类似Perl的正则表达式包,再来做其他事情。进入没有正则表达式的世界之后才发现,自己已经习惯正则表达式的功能和便捷了,而我显然不希望在没有正则表达式的世界呆太久。
用环视功能为数值添加逗号
Adding Commas to a Number with Lookaround
大的数值,如果在其间加入逗号,会更容易看懂。下面的程序:
print "The US population is $pop\n";
可能输出“The US population is 298444215”,但对大多数说英语的人来说,“298,444,215”看起来更加自然。用正则表达式该如何做呢?
动脑子想想这个问题,我们应该从这个数的右边开始,每次数 3 位数字,如果左边还有数字的话,就加入一个逗号。如果我们能把这种思路直接用到正则表达式中当然很好,可惜正则表达式一般都是从左向右工作的。不过梳理一下思路就会发现,逗号应该加在“左边有数字,右边数字的个数正好是3的倍数的位置”,这样,使用一组相对较新的正则表达式特性——它们统称为“环视(lookaround)”——轻松地解决这个问题。
环视结构不匹配任何字符,只匹配文本中的特定位置,这一点与单词分界符「\b」、锚点「^」和「$」相似。但是,环视比它们更加通用。
一种类型的环视叫“顺序环视(lookahead)”,作为表达式的一部分,顺序环视顺序(从左至右)查看文本,尝试匹配子表达式,如果能够匹配,就返回匹配成功信息。肯定型顺序环视(positive lookahread)用特殊的序列「(?=…)」来表示,例如「(?=\d)」,它表示如果当前位置右边的字符是数字则匹配成功。另一种环视称为逆序环视,它逆序(从右向左)查看文本。它用特殊的序列「(?<=…)」表示,例如「(?<=\d)」,如果当前位置的左边有一位数字,则匹配成功(也就是说,紧跟在数字后面的位置)。
环视不会“占用”字符
在理解顺序环视和其他环视功能时需要特别注意一点,即在检查子表达式能否匹配的过程中,它们本身不会“占用”任何文本。这可能有点难懂,所以我准备了下面的例子。正则表达式「Jeffrey」匹配:
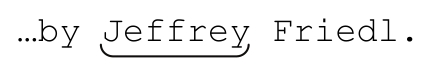
但同样的正则表达式,如果使用顺序环视功能,即「(?=Jeffrey)」,则匹配标记的位置:
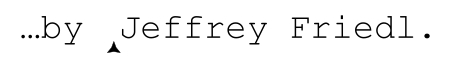
顺序环视会检查子表达式能否匹配,但它只寻找能够匹配的位置,而不会真正“占用”这些字符。不过,把顺序环视和真正匹配字符的部分——例如「Jeff」——结合起来,我们能得到比单纯的「Jeff」更精确的结果。结合之后的正则表达式是「(?=Jeffrey)Jeff」,下一页的图说明,它只能匹配“Jeffrey”这个单词中的“Jeff”。它能够匹配:
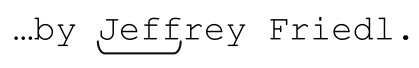
在此处它的匹配和单纯的「Jeff」一样,但是下面的情况不会 匹配:
…by Thomas Jefferson
「Jeff」自己能够匹配这一行,但是因为不存在「(?=Jeffrey)」能够匹配的位置,整个表达式就无法匹配。现在环视的好处还看得不是很明显,但是请不用担心,现在我们只需要关心顺序环视的原理——我们很快会遇到能够充分展现其价值的例子,。
受此启发,你或许会发现「(?=Jeffrey)Jeff」和「Jeff(?=rey)」是等价的(能够发现这一点的读者很了不起)。它们都能匹配“Jeffrey”这个单词中的“Jeff”。
我们还需要认识到,它们结合的顺序非常重要。「Jeff(?=Jeffrey)」不会匹配上面的任何一个例子,而只会匹配后面紧跟有“Jeffrey”的“Jeff”。
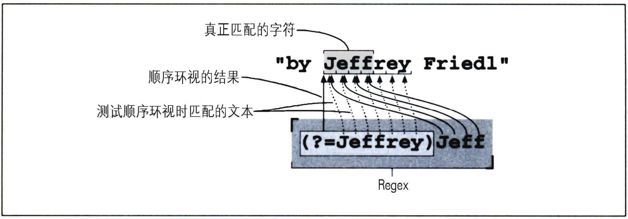
图2-5:「(?=Jeffrey)Jeff」的匹配
还有一点很重要,即环视结构使用特殊的表示法。就像45页介绍的非捕获型括号“(?:…)”一样,它们使用特殊的字符序列作为自己的“开括号”。这样的“开括号”序列有许多种,但它们都以两个字符“(?”开头。问号之后的字符用来标志特殊的功能。我们曾经看到过“分组但不捕获”的“(?:…)”、顺序环视的“(?=…)”,以及逆序环视的“(?<=…)”结构,下面还会看到更多。
再来几个顺序环视的例子
我们马上就要在数字间插入逗号了,不过现在先多看几个环视的例子。首先我们要把所有格“Jeffs”替换为“Jeff’s”。不使用环视也能很容易做到这一点,即s/Jeffs/Jeff's/g(记住,/g 表示“全局替换”,☞51)。更好的办法是添加单词分界符锚点:s/\bJeffs\b/Jeff's/g。
我们也可以使用更复杂的表达式,例如s/\b(Jeff)(s)\b/$1'$2/g,但是这样简单的任务似乎不值得这么麻烦,所以我们暂时仍然使用 s/\bJeffs\b/Jeff's/g。现在来看另一个正则表达式
s/\bJeff(?=s\b)/Jeff'/g
两者唯一的区别在于,最后的「s\b」现在位于顺序环视结构。下一页的图2-6说明了这个正则表达式的匹配情况。正则表达式变化之后,replacement字符串中的‘s’也相应地被删去了。
「Jeff」匹配之后,接下来尝试的就是顺序环视。只有当「s\b」在此位置能够匹配时(也就是‘Jeff’之后紧跟一个‘s’和一个单词分界符)整个表达式才能匹配成功。但是,因为「s\b」只是顺序环视子表达式的一部分,所以它匹配的‘s’不属于最终的匹配文本。记住,「Jeff」确定匹配文本,而顺序环视只是“选择”一个位置。在此处使用顺序环视的唯一好处在于,它保证表达式不会匹配任意的情况。或者从另一个角度来说就是,它容许我们在只匹配「Jeff」之前检查整个「Jeffs」。
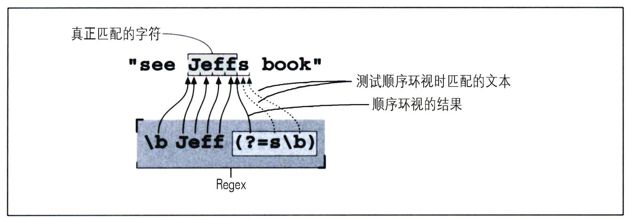
图2-6:「\bJeff(?=s\b)」的匹配
为什么不在最终匹配的结果中包含顺序环视匹配过的文本呢?通常,这是因为我们希望在表达式的后面部分,或者在稍后应用正则表达式时,再次检测这段文本。过几页,当我们真正开始解决在数值中加入逗号的问题时,就会明白它的作用。但是在上面的例子中,使用顺序环视的原因在于:我们希望检查整个「Jeffs」,因为这是我们希望加入撇号的地方,但是如果匹配的只是‘Jeff’,就能减小replacement字符串的长度。因为‘s’不再是最终匹配结果的一部分,也就不再是replacement的一部分,所以我们可以从replacement字符串中去掉它。
所以,尽管这两种办法所用的正则表达式和replacement字符串各不相同,它们的结果却是一样的。现在看起来,这些应用正则表达式的技巧都有些花架子的味道,但是我这么做是有目的的,请继续往下看。
比较上面的两个例子,最后的「s」从“主(main)”表达式中移到了顺序环视部分中。如果我们把开头的「Jeff」照样搬到逆序环视中呢?结果是「(?<=\bJeff)(?=s\b)」,它的意思是,找到这样一个位置,它紧接在‘Jeff’之后,在‘s’之前。这正好就是我们希望插入撇号的地方。所以,我们这样替换:
s/(?<=\bJeff)(?=s\b)/'/g
这个表达式很有意思,它实际上并没有匹配任何字符,只是匹配了我们希望插入撇号的位置。在这种情况下,我们并没有“替换”任何字符,而只是插入了一个撇号。图2-7作了说明。在几页以前,我们看到过这样的替换,使用s/^/|>·/在行首加入‘|>·’。
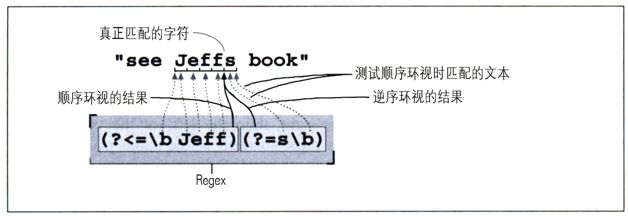
图2-7:「(?<=\bJeff)(?=s\b)」的匹配
如果我们把两个环视结构调换位置,这个正则表达式的功能会改变吗?也就是说,s/(?=s\b)(?<=\bJeff)/'/g的结果如何?ϖ请翻到下一页查看答案。
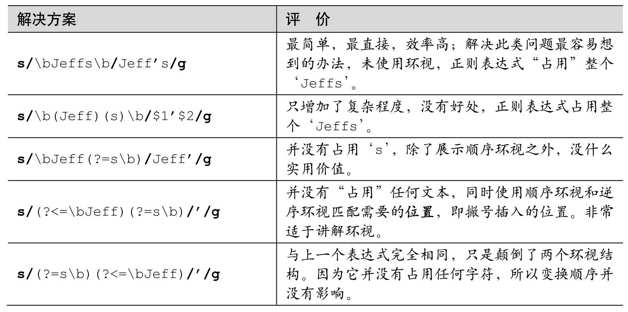
“Jeffs”匹配总结 表2-1总结了我们见过的把Jeffs替换为Jeff’s的几种办法。
表2-1:解决“Jeffs”问题的几种办法
回到“在数值中加入逗号”之前,我先提一个关于这些表达式的问题。如果我希望找到不区分大小写的“Jeffs”,在替换之后仍然保持原来的大小写,使用/i能实现这个目标吗?

提示:至少有两个表达式无法做到这一点。ϖ请思考这个问题,答案见下页。
回到逗号的例子…
你可能已经意识到了“Jeffs”的例子和插入逗号的例子之间存在某种联系,因为它们都需要通过正则表达式寻找到某个位置,然后插入文本。
我们已经知道我们希望插入逗号的位置必须满足“左边有数字,右边数字的个数正好是 3的倍数”。第二个要求用逆序环视很容易解决,左边只要有一位数字就能够满足“左边有数字”的要求,这就是「(?<=\d)」。
现在来看“右边数字的个数正好是3 的倍数”。3 位数字当然可以表示为「\d\d\d」,我们可以用「(…)+」来表示(3的)“若干倍”,再添加一个「$」来确保这些数字后面不存在其他字符(保证“正好”)。孤立的「(\d\d\d)+$」匹配从字符串末尾向前数的 3x 位数字,但是加入「(?=…)」的环视结构之后,它就能匹配“右边数字的个数正好是 3 的倍数的位置”,例如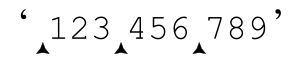 中的标记位置。实际上并不是所有这些位置都符合要求——我们不希望在第一个数字之前加入逗号——所以我们添加「(?<=\d)」来限定匹配的位置。
中的标记位置。实际上并不是所有这些位置都符合要求——我们不希望在第一个数字之前加入逗号——所以我们添加「(?<=\d)」来限定匹配的位置。
代码段如下:
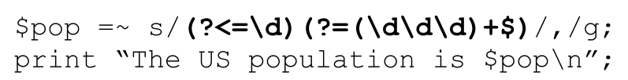
确实输出了我们期望的“The US population is 298,444,215”。不过,有点奇怪的是,「\d\d\d」两边的括号是捕获型括号。但是在这里,我们只用它来分组,把加号作用于 3 位数字,所以不需要把它们捕获的文本保存到$1中。
我可以使用第 45 页补充内容介绍的非捕获型括号:「(?:…)」,得到「(?<=\d)(?=(?:\d\d\d)+$)」。这样做的好处在于,见到这个正则表达式的人不会担心与捕获型括号关联的$1是否会被用到;而且它的效率更高,因为引擎不需要记忆捕获的文本。另一方面,即使是「(…)」也有点难以看懂,更不用说「(?…)」了,所以我在这里选择更清晰的表达方式。构建正则表达式时,经常需要权衡这两个因素。从我个人来说,我愿意在适用的所有地方使用「(?:…)」,但是在讲解其他知识时选择更清晰的表达方式(也是本书中的常见情况)。
单词分界符和否定环视
现在假设,我们希望把这个插入逗号的正则表达式应用到很长的字符串中,例如:

很显然程序没有结果,因为「$」要求字符串以3的倍数位数字结尾。我们不能只去掉这里的「$」,因为这样会从左边第一位数字之后,右边第三位数字之前的每一个位置插入逗号——结果是“…of 2,9,8,4,4,4,215…”!
可能初看起来这问题有些棘手,但我们可以用单词分界符「\b」来替换「$」。尽管我们处理的只是数字,Perl的“单词”概念也能够解决这个问题。就像「\w」(☞49)一样,Perl和其他语言都把数字、字母和下画线当作单词的一部分。结果,单词分界符的意思就是,在此位置的一侧是单词(例如数字),另一侧不是(例如行的末尾,或者数字后面的空格)。
这个“一侧如此这般,另一侧如此那般”听起来很耳熟,对吗?因为这正是我们在“Jeffs”例子中所做的。区别之一在于,有一侧必须使用否定的匹配。这样看来,迄今为止我们用到的顺序环视和逆序环视应该被称作肯定顺序环视(positive lookahead)和肯定逆序环视(positive lookbehind)。因为它们成功的条件是子表达式在这些位置能够匹配。表2-2告诉我们,正则表达式还提供了相对应的否定顺序环视和否定逆序环视。从名字就能看出,它们成功的条件是子表达式无法匹配。

表2-2:四种类型的环视

所以,如果单词分界符的意思是:一侧是「\w」而另一侧不是「\w」,我们就能用「(?<!\w)(?=\w)」来表示单词起始分界符,用「(?<=\w)(?!\w)」表示单词结束分界符。把两者结合起来,「(?<!\w)(?=\w)|(?<=\w)(?!\w))」就等价于「\b」。在实践中,如果语言本身支持\b(\b更直接,效率也更高),这样做有点多此一举,但是可能的确有地方需要用到这两个单独的多选分支(☞134)。
对我们的逗号插入问题来说,我们真正需要的是「(?!\d)」来标记3位数字的起始计数位置。我们用它来取代「\b」或者「$」,得到:
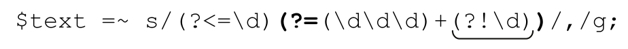
这个表达式在处理类似“…tone of 12345Hz”的文本时效果很好;不幸的是,它同样会匹配“…the 1970s…”中的年份。实际上,我们根本不希望这里的正则表达式能够匹配“…in1970…”。所以,我们必须知道期望用正则表达式处理的文本,以及开发的程序适合解决什么样的问题(如果数据包含年份信息,这个正则表达式可能就不适合)。
在关于单词分界符和不希望匹配的字符的讨论中,我们使用了否定顺序环视,「(?!\w)」或「(?!\d)」。你可能还记得第49页出现的表示“非数字”的字符「\D」,认为它可以取代「(?!\d)」。这并不正确。记住,「\D」的意思是,“某个不是数字的字符”,“某个字符”是必须的,只是它不能为数字。如果在搜索的文本中,数字之后没有字符,「\D」是无法匹配的(在第 12 页的补充内容中我们见到过类似的情况)。
不通过逆序环视添加逗号
逆序环视和顺序环视一样,所获的支持十分有限(使用也不广泛)。顺序环视比逆序环视早出现几年,尽管 Perl 现在两者都支持,许多其他语言却不是这样。所以,想一想不用逆序环视来解决添加逗号的问题可能更有意义。来看下面的表达式:
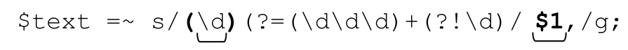
它与之前的表达式的差别在于,开头的「\d」所处的肯定逆序环视变成了捕获型括号,replacement字符串则在逗号之前加入了相应的$1。
如果我们连顺序环视也不用呢?我们可以用「\b」取代「(?!\d)」,但这个消除逆序环视的技巧是否对剩下的顺序环视有效呢?也就是说,下面的办法可行吗?
$text=~s/(\d)((\d\d\d)+\b)/$1,$2/g;
ϖ 请翻到下页查看答案。
Text-to-HTML转换
Text-to-HTML Conversion
现在我们写一个把 Text(纯文本)转换为 HTML(超文本)的小工具,如果要处理所有的情况,程序将非常难写,所以现在我们只写一个用于教学的小工具。
在目前我们看过的所有例子中,作为正则表达式应用对象的变量都只包含一行文本。对这个例子来说,把我们需要转换的所有文本放在同一个字符串中比较方便。在 Perl 中,我们可以很容易地这样做:


如果我们的样本文件包含3个短行:

变量$text的内容就是:
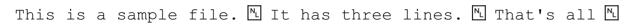
在某些平台上,也可能是:

这是因为大多数系统采用换行符作为一行的终结符,而某些系统(主要是 Windows)使用回车/换行的结合体。我们会确保这个简单的工具能应付这两种情况。
处理特殊字符
首先我们需要确保原始文本中的‘&’、‘<’和‘>’字符“不会出错”,把它们转换为对应的HTML编码,分别是‘&’、‘<’和‘>’。在HTML中这些字符有特殊的含义,编码不正确可能会导致显示错误。我称这种简单的转换为“为HTML而加工(cooking the text for HTML)”,它的确非常简单:

请注意,我们使用了/g来对所有的目标字符进行替换(如果不用/g,就只会替换第一次出现的特殊字符)。首先转换&是很重要的,因为这三者的replacement中都有‘&’字符。
分隔段落
接下来我们用HTML tag中表示分段的<p>来标记段落。识别段落的简单办法就是把空行作为段落之间的分隔。搜索空行的办法有很多,最容易想到的是:
$text=~s/^$/<p>/g;
它可以匹配“行末尾紧随行开头的位置”。确实,我们已经在第10页看到,在egrep之类的工具中这样行得通,因为其中被检索的文本通常只包含逻辑上的一行文本。在 Perl 中也同样有效,对于之前看到过的E-mail的例子,我们知道每一个字符串只包含一个逻辑行。
但是,我已经在第55页的脚注中提到过,「^」和「$」通常匹配的不是逻辑行的开头和结尾,而是整个的字符串的开头和结束位置(注 5)。所以,既然目标字符串中有多个逻辑行,就需要采取不同的办法。
幸好,大多数支持正则表达式的语言提供了一个简单的办法,即“增强的行锚点”(enhanced line anchor)匹配模式,在这种模式下,「^」和「$」会从字符串模式切换到本例中需要的逻辑行模式。在Perl中,使用/m修饰符来选择此模式:
$text=~s/^$/<p>/mg;
请注意这里同时使用了/m和/g(你可以以任何顺序排列需要使用的多个修饰符)。在下一章,我们会看到其他语言是如何处理修饰符的。
所以,如果我们从$text的‘…chapter. Thus…’开始,会得到期望的‘…chapter.
Thus…’开始,会得到期望的‘…chapter. <p>
<p> Thus…’。
Thus…’。
不过,如果在“空行”中包含空格符或者其他空白字符,这么做就行不通。为了处理空白字符,我们使用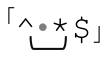 ,或者是
,或者是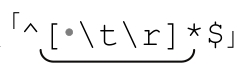 来匹配某些系统在换行符之前的空格符、制表
来匹配某些系统在换行符之前的空格符、制表
符或者回车符。这两个表达式与「^$」是完全不同的,因为它们确实匹配了一些字符,而「^$」只匹配位置。不过,因为在本例中我们不需要这些空格符、制表符和回车符,匹配(然后用分段tag来替换)这些字符不会带来任何问题。
如果你还记得第47页的「\s」,你可能会想到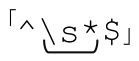 ,就像我们在第55页E-mail的例子中所用的那样。如果用「\s」取代「[·\t\r]」,因为「\s」能够匹配换行符,所以整个表达式的意义就不再是“寻找空行及只包括空白字符的行”,而是“寻找连续、空行和只包括空白字符的行的结合”。也就是说,如果我们找到多个连续的这样的文本行,一个「^\s*$」就能够匹配它们。这样的好处在于,只会留下一个<p>,而不是像以前那样有多少空行就留下多少<p>。所以,如果$text有这样的字符串:
,就像我们在第55页E-mail的例子中所用的那样。如果用「\s」取代「[·\t\r]」,因为「\s」能够匹配换行符,所以整个表达式的意义就不再是“寻找空行及只包括空白字符的行”,而是“寻找连续、空行和只包括空白字符的行的结合”。也就是说,如果我们找到多个连续的这样的文本行,一个「^\s*$」就能够匹配它们。这样的好处在于,只会留下一个<p>,而不是像以前那样有多少空行就留下多少<p>。所以,如果$text有这样的字符串:

我们用:
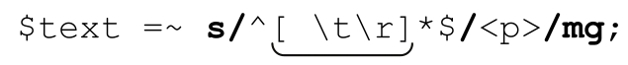
结果就是

不过,如果我们用:
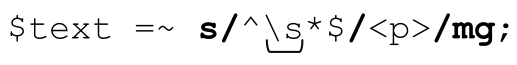
结果要更好看一些:

所以,在最终的程序中,我们会使用「^\s*$」。
将E-mail地址转换为超链接形式
Text-to-HTML 转换的下一步是识别出 E-mail 地址,然后把它们转换为“mailto”链接。例如,[email protected] 会被转换为<a·href=“mailto:[email protected]”>[email protected]</a>。
用正则表达式来匹配或者验证E-mail地址是常见的情况。E-mail地址的标准规范异常繁杂,所以很难做到百分之百的准确,但是一些简单的正则表达式就可以应付遇到的大多数E-mail地址。E-mail地址的基本形式是username@hostname。在思考该用怎样的表达式来匹配各个部分之前,我们先看看这个正则表达式的具体应用环境:
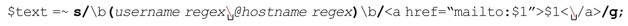
需要注意的一点是其中两个用下画线标注的反斜线,第一个在正则表达式(‘\@’)中,另一个在replacement字符串的末尾。使用这两个反斜线的理由各不相同。我会在稍后讨论\@(☞77),现在我们只需要知道,Perl规定作为文本字符的@符号必须转义。
先介绍replacement字符串中在‘/’之前的反斜线比较好。我们已经看到,Perl中查找替换的基本形式是s/regex/replacement/modifier,用斜线来分隔。所以,如果我们需要在某个部分中使用斜线,就必须使用转义,否则反斜线会被识别为分隔符,作为字符串的一部分。也就是说,如果我们希望在replacement字符串中使用</a>,就必须写作<\/a>。
这么做当然可以,但不太好看,所以Perl容许用户自定义分隔符。例如s!regex!string!modifier,或者s{regex}{string}modifier。无论采用哪种形式,因为replacement字符串中的斜线不再与分隔符有冲突,也就不需要转义。第二种形式的分隔符非常明显,所以从现在开始我们采用这种形式。
回到程序中来,请注意整个地址是处于「\b…\b」之间的。添加这些单词分界符能够避免不完整匹配的情况,例如 ’。尽管遭遇这种无意义的字符串的几率很小,但使用单词分界符来避免此类匹配一点也不麻烦,所以我会这么做。请注意我是如何用括号包围整个 E-mail 地址的,这样我们就能使用 replacement 字符串‘<a·href=“mailto:$1”>$1</a>’。
’。尽管遭遇这种无意义的字符串的几率很小,但使用单词分界符来避免此类匹配一点也不麻烦,所以我会这么做。请注意我是如何用括号包围整个 E-mail 地址的,这样我们就能使用 replacement 字符串‘<a·href=“mailto:$1”>$1</a>’。
匹配用户名和主机名
现在我们来看匹配邮件地址所需要的用户名和主机名的正则表达式。主机名,例如regex.info 或者 www.oreilly.com,它们由点号分隔,以‘com’、‘edu’、‘info’、‘uk’或者其他事先规定的字符序列结尾。匹配E-mail地址的最简单的办法是「\w+\@\w+(\.\w+)+」,用「\w+」来匹配用户名,以及主机名的各个部分。不过,实际应用起来,我们需要考虑得更周到一些。用户名可以包含点号和连字符(虽然用户名不会以这两种字符开头)。所以,我们不应该使用「\w+」,而应该用「\w[-.\w]*」。这就保证用户名以「\w」开头,后面的部分可以包括点号和连字符。(请注意,我们在字符组中把连字符排在第一位,这样就确保它们被作为连字符,而不是用来表示范围。对许多流派来说,.-\w表示的范围肯定是错误的,它会产生一个随机的字母、数字和标点符号的集合,具体取决于程序和计算机所用的字符编码。Perl能够正确处理.-\w,但是使用连字符时多加小心是个好习惯。)
主机名的匹配要复杂一些,因为点号只能作分隔符,也就是说两个点号之间必须有其他字符。所以在前面那个简单的正则表达式中,主机名部分用「\w+(\.\w+)+」而不是「[\w.]+」。后者会匹配‘..x..’。但是,即使是前者,也能够匹配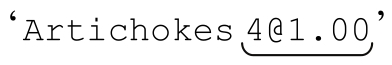 ,所以我们需要更细心一些。
,所以我们需要更细心一些。
一个办法是给出末尾部分的可能序列,跟在「\w+(\.\w+)*\.(com|edu|info)」之后(实际上,多选分支应该是 com|edu|gov|int|mil|net|org|biz|info|name|museum|coop|aero|[a-z][a-z],不过为了简洁起见,我在这里只列出几项)。这样就能容许开头的「\w+」部分,然后是可能出现的「\.\w+」部分,最后才是我们指定的可能结尾。
实际上「\w」也不是很合适。「\w」能够匹配ASCII字母和数字,这没有问题,但有些系统中「\w」能够匹配非ASCII字母,例如à、ç、Ξ、Æ。在大多数流派中,下画线也是可以的。但这些字符都不应该出现在主机名中。所以,我们或许应该用「[a-zA-Z0-9]」,或者是「[a-z0-9]」加上/i 修饰符(进行不区分大小写的匹配)。主机名可能包括连字符,所以我们用「[-a-z0-9]」(再次注意,连字符应该放在第一位)。于是我们得到用来匹配主机名的「[-a-z0-9]+(\.[-a-z0-9]+)*\.(com|edu|info)」。
无论使用什么正则表达式,记住它们应用的情境都是很重要的。「[-a-z0-9]+(\.[-a-z0-9]+)*\.(com|edu|info) 」这个正则表达式本身,可以匹配‘run C:\\ ’,但是把它置入程序运行的环境中,我们就能确认,它会匹配我们期望的文本,而忽略不期望的内容。实际上,我会把它放入之前提到的。
’,但是把它置入程序运行的环境中,我们就能确认,它会匹配我们期望的文本,而忽略不期望的内容。实际上,我会把它放入之前提到的。
$text=~s{\b(username regex\@hostname regex)\b}{<a href=“mailto:$1”>$1</a>}gi;(这里用了s{…}{…}分隔符,以及/i),但这样就必须折行。当然,Perl不关心这个问题,也不关心表达式是否美观,但我关心。所以我要介绍/x修饰符,它容许我们重新编排这个表达式:

啊哈,现在看起来大不一样了。语句末尾出现了/x(在/g和/i之后),它对这个正则表达式做了两件简单但有意义的事情。首先,大多数空白字符会被忽略,用户能够以“宽松排列(free-format)”编排这个表达式,增强可读性。其次,它容许出现以#开头标记的注释。
要指出的是,加上/x之后,表达式中的大部分空格符变为“忽略自身”元字符(“ignore me”metacharacter),而#的意思是“忽略该字符及其之后第一个换行符之前的所有字符”(☞111)。它们不是作为字符组内部的元字符(也就是说,即便使用了/x,这些字符组也不是“随意编排”的)来对待的,而且,同其他元字符一样,如果希望把它们作为普通字符来处理,也可以对它们加以转义。当然,「\s」总是能够匹配空白字符,例如m/<a\s+href=…>/x。
请注意,/x只能应用于正则表达式本身,而不是replacement字符串。同样,即使我们现在使用的是s{…}{…}的格式,修饰符接在最后的‘}’之后(例如‘}x’),但是在文中我们仍然使用“/x”代表“修饰符x”。
综合起来
现在,我们可以把用户名、主机名的部分,以及之前的开发成果结合起来,得到相对完整的程序:

所有的正则表达式都应用于同一个包含多行文本的字符串,需要注意的是,只有用于划分段落的正则表达式才使用/m修饰符,因为只有那个正则表达式用到了「^」和「$」。对其他正则表达式使用/m并不会产生影响(只会令看程序的人迷惑)。
把HTTP URL转换为链接形式
最后,我们需要识别HTTP URL,将它变为链接形式。也就是说把“http://www.yahoo.com”转变为<a·href=http://www.yahoo.com/>http://www.yahoo.com/</a>。
HTTP URL的基本形式是http://hostname/path,其中的/path部分是可选的。于是我们得到下面的形式:

主机部分的匹配可以使用在E-mail例子中用过的子表达式。URL的path部分可以包括各种字符,在前一章中我们使用的是「[-a-z0-9_:@&?=+,.!/~*'%$]*」(☞25),它包括了除空白字符、控制字符和<>(){}之外的大多数ASCII字符。
在使用 Perl 解决这个问题之前,我们必须对@和$进行转义。同样,我会在稍后讲解原因(☞77)。现在,我们来看hostname和path部分:

你可能注意了,在path之后没有「\b」,因为URL之后通常都是标点符号,例如本书在O’Reilly的URL是:
http://www.oreilly.com/catalog/regex3/
如果末尾有「\b」,就不能匹配。
也就是说,在实际中,我们需要对表示URL结束的字符做一些人为的规定。比如下面的文本:

现在正则表达式能够匹配标注出的文本了,当然末尾的标点显然不应该作为URL的一部分。在匹配英文文本中的URL时,末尾的「[.,?!]」是不应该作为URL的一部分的(这并不是什么规定,而是我的经验,而且大多数时候都有效)。这很简单,只需要在表达式的末尾添加一个表示“除「[.,?!]」之外的任何字符”的否定逆序环视,「(?<![.,?!])」即可。结果就是,在我们匹配到作为URL匹配的文本之后,逆序环视会反过头来看一眼,保证最后的字符符合要求。如果不符合要求,引擎就会重新检查作为URL的字符串,直到最终符合要求为止。也就是强迫去掉最后的标点,让最后的逆序环视匹配成功(在第 5 章我们会看到另一个解决办法☞206)。
插入之后,我们得到了完整的程序:

构建正则表达式库
请注意,在这两个例子中,我们使用同样的正则表达式来匹配主机名,也就是说,如果要修改匹配主机名的表达式,我们希望这种修改会同时对两个例子生效。我们可以在程序中多次使用变量$HostnameRegex,而不是把这个表达式写在各处,杂乱无绪:

第一行使用了Perl的qr操作符。它与m和s操作符类似,接收一个正则表达式(例如,使用qr/…/,类似使用m/…/和s/…/…/),但并不马上把这个正则表达式应用到某段文本中进行匹配,而是由这个表达式生成为一个“regex对象(regex object)”,作为变量保存。之后我们就能使用这个对象。(在本例中,我们用变量$HostnameRegex 来保存这个变量,供后面两个正则表达式使用。)这样做非常方便,因为程序看起来非常清楚。此外,我们的匹配主机名的正则表达式只存在一个“主源(main source)”,这样无论在哪里需要匹配主机名,都可以直接使用它。第6章(☞277)还有关于构建这种“正则表达式库”的例子,具体讲解见第7章(☞303)。
其他的语言也提供了创建正则表达式对象的方法,下一章我们会简要介绍若干语言,而Java和.NET则在第8和第9章详细讲解。
为什么有时候$和@需要转义
你可能注意到了,‘$’符号既可以作为表示字符串结束的元字符,又可以用来标记变量。通常,‘$’的意思是很明确的,但如果在字符组内部,情况就有些麻烦,因为此时它不能用来表示字符串的结束位置,只能在转义之后,用来标记变量。在转义之后,‘$’就只是字符组的一部分。而这正是我们所要的,所以我们需要在URL匹配的正则表达式中对它进行转义。
@的情况与之类似。Perl 用@表示数组名,而 Perl 中的字符串或正则表达式中也容许出现数组变量。如果我们希望在正则表达式中使用@字符,就需要进行转义,避免把它作为数组名。一些语言(Java、VB.NET、C、C#、Emacs、awk等)不支持变量插值(variable interpolation)。有些语言(例如Perl、PHP、Python、Ruby和Tcl)支持变量插值,但是方法各有不同。我们会在下一章详细讲解(☞101)。
回到单词重复问题
That Doubled-Word Thing
我希望第 1 章提到的单词重复问题能够引发读者对于正则表达式的兴趣。在本章的开头我给出了一堆难懂的代码,将其作为解法之一:

对 Perl 有了些了解之后,我希望读者至少能够看懂常规的正则表达式应用——其中的<>,三个s/…/…/,以及print。不过,其他的部分仍然很难。如果你关于Perl的知识全部来自本章(而且关于正则表达式的知识都来自之前的章节),这个例子可能会超出你的理解能力。不过,如果细致考察起来,我认为这个正则表达式并不复杂。在重读程序之前,我们不妨回过头看看第1页的程序规格要求,并尝试运行一次:

先来看这个Perl的解法,然后我们会看到一个Java的解法,接触另一种使用正则表达式的思路。现在列在下面的程序使用了s{regex}{replacement}modifier的替换形式,同时使用了/x 修饰符来提高清晰程度(空间更充裕的时候,我们使用更易懂的‘next unless’替换‘next if!’)。除去这些,它与本章开头的程序其实就是一模一样的。
示例2-3:用Perl处理重复单词

这小段程序中出现了许多我们没见过的东西。下面我会简要地介绍它们以及背后的逻辑,不过我建议读者查看Perl的man page了解细节(如果是正则表达式相关的细节,可以查阅第7章)。在下面的描述中,“神奇”(magic)的意思是“这里用到了读者可能不熟悉的Perl的特性”。
∂ 因为单词重复问题必须应付单词重复位于不同行的情况,我们不能延续在E-mail的例子中使用的普通的按行处理的方式。在程序中使用特殊变量$/(没错,这确实是一个变量)能使用一种神奇的方式,让<>不再返回单行文字,而返回或多或少的一段文字。返回的数据仍然是一个字符串,只是这个字符串可能包含多个逻辑行。
● 你是否注意到,<>没有值赋给任何变量?作为while中的条件使用时,<>的神奇之处在于,它能够把字符串的内容赋给一个特殊的默认变量(注 6)。该变量保存了 s/…/…/和print作用的默认字符串。使用这些默认变量能够减少冗余代码,但Perl新手不容易看明白,所以我还是推荐,在你习惯之前,把程序写得更清楚一些。
÷如果没有进行任何替换,那么替换命令之前的 next unless会导致 Perl 中断处理当前字符串(转而开始下一个字符串)。如果在当前字符串中没有找到单词重复,也就不必进行下一步的工作。
≠ replacement字符串包含的就是“$1$2$3”,加上插入的ANSI转义序列,把两个重叠的词标记为高亮,中间的部分则不标记高亮。转义序列\e[7m用于标注高亮的开始,\e[m用于标注高亮的结束(在Perl的正则表达式和字符串中,\e用来表示ASCII的转义字符,该字符表示之后的字符为ANSI转义序列)。
仔细看看正则表达式中的那些括号,你会发现“$1$2$3”表示的完全就是匹配的文本。所以,除了添加转义序列之外,整个替换命令并没有进行任何实质修改。
我们知道$1 和$3 匹配的是同样的文本(这也是整个程序的意义所在!),所以在replacement 中只用一个也是可以的。不过,因为这两个单词的大小写可能有区别,我用了两个变量。
≡ 这个字符串可能包括多个逻辑行,不过在替换命令标记了所有的重复单词之后,我们希望只保留那些包含转义字符的逻辑行。去掉不包含转义字符的逻辑行之后,留下的就是字符串中我们需要处理的行。因为我们在替换中使用的是增强的行锚点匹配模式(/m修饰符),正则表达式「^([^\e]*\n)+」能够找出不包含转义字符的逻辑行。用这个表达式来替换掉所有不需要处理的行。结果留下的只是包含转义字符的逻辑行,也即那些包含单词重复的行(注7)。
≈ 变量$ARGV 提供了输入文件的名字。结合/m 和/g,这个替换命令会把输入文件名加到留下的每一个逻辑行的开头。多酷!
最后,print会输出字符串中留下的逻辑行以及转义字符。while循环对输入的所有字符串重复处理(每次处理一段)。
更深入一点:运算符、函数和对象
我之前已经强调过,在本章我以 Perl 作为工具来讲解概念。Perl 的确是一种有用的工具,但我想要强调的是,这个问题利用其他语言的正则表达式解决起来也很容易。
同样,因为 Perl 具有与其他高级语言不同的独特风格,讲解这些概念更加容易。这种独特风格就是,正则表达式是“基础级别(first-class)”的。也就是说,基本的运算符可以直接作用于正则表达式,就好像+和-作用于数字一样。这样减轻了使用正则表达式的“语法包袱”(syntactic baggage)。
其他许多语言并没有这样的特性。因为第3章中提到的原因(☞93),许多现代语言坚持提供专用的函数和对象来处理正则表达式。例如,可能有一个函数接收表示正则表达式的字符串,以及用于搜索的文本,然后根据正则表达式能否匹配该文本,返回真值或假值。更常见的情况是,这两个功能(首先对一个作为正则表达式的字符串进行解释(interpretion),然后把它应用到文本当中)被分割为两个或更多分离的函数,就像下一页的Java代码一样。这些代码使用Java1.4以后作为标准的java.util.regex包。
在程序的上部我们看到,在 Perl 中使用的 3 个正则表达式在 Java 中作为字符串传递给Pattern.compile程序。通过比较我们发现,Java版本的正则表达式包含了更多的反斜线,原因是Java要求正则表达式必须以字符串方式提供。正则表达式中的反斜线必须转义,以避免Java在解析字符串时按照自己的方式处理它们。
我们还应该注意到,正则表达式不是在程序处理文本的主体部分出现,而是在开头的初始化部分出现的。Pattern.compile 函数所作的仅仅是分析这些作为正则表达式的字符串,构建一个“已编译的版本(compiled version)”,将其赋给Pattern变量(例如regex1)。然后,在处理文本的主体部分,已编译的版本通过 regex1.matcher(text)应用到文本之上,得到的结果用于替换。同样,我们会在下一章探究其中的细节,在这里我们只需要了解,在学习任何一门支持正则表达式的语言时,我们需要注意两点:正则表达式的流派,以及该语言运用正则表达式的方式。
示例2-4:用Java解决重复单词的问题
