Unrolling the Loop
无论系统本身支持怎样的优化,最重要的收益或许还是来自于对引擎基本工作原理的理解,和编写能够配合引擎工作的表达式。所以,既然我们已经考察了繁琐的细节,不妨登堂入室,学习我说的“消除循环”的技巧。对某些常用的表达式来说,它的加速效果很明显。举例来说,用它改造本章开头(☞226)会进行无休止匹配的表达式,能够在有限的时间内报告匹配失败,而如果能够匹配,速度也会更快。
此处说的“循环”采用的是「(this|that|…)*」之类问题中星号代表的意义。之前的无休止匹配「"(\\.|[^\\"]+)*"」其实就属于此类。如果无法匹配,这个表达式需要近乎无限的时间进行尝试,所以必须改进。
此技巧有两种不同的实现途径:
1.我们可以检查,在各种典型匹配中,「(\\.|[^\\"]+)*」中的哪个部分真正匹配成功了,这样就能留下子表达式的痕迹。再根据刚刚发现的模式,重新构建高效的表达式。这个(或许联系不那么紧密的)概念模型就是一个大球,它表示表达式「(…)*」,球在某些文本上滚动。「(…)」内的元素总是能够匹配某些文本,这样就留下了痕迹,就好像是把脏兮兮的雪球在地毯上滚过去一样。
2.另一个办法是,从更高的层面考察我们期望用于匹配的结构。然后根据我们认为的常见情形,对可能出现的目标字符串做出非正式假设。从这个角度出发构建有效的表达式。
无论采取哪种办法,得到的表达式都是一样的。我首先讲解第一种思路,然后介绍如何通过第二种思路取得同样的结果。
为了保证例子容易看懂,并尽可能广泛地使用,我会使用「(…)」来代替所有括号,如果程序支持非捕获型括号「(?:…)」能够支持,使用它们能提高效率。然后会讲解固化分组(☞139)和占有优先量词(☞142)的使用。
方法1:依据经验构建正则表达式
Method 1:Building a Regex From Past Experiences
在分析「"(\\.|[^\\"]+)*"」时,用若干具体的字符串来检验全局匹配的具体情况是很自然的做法。举例来说,如果目标字符串是‘"hi"’,那么使用的自表达式就是「"[^\\"]+"」。这说明,全局匹配使用了最开始的「"」,然后是多选分支「[^\\"]+」,然后是末尾的「"」。
如果目标字符串是:
"he said\"hi there\" and left"
对应的表达式就是 。在这个例子里以及表6-2中,我标记了对应的正则表达式,让模式更显眼。如果我们能对每个输入字符串构造特定的表达式当然很好。这不可能,但我们能够找出一些常用的模式,构造效率更高,又不失通用性的正则表达式。
。在这个例子里以及表6-2中,我标记了对应的正则表达式,让模式更显眼。如果我们能对每个输入字符串构造特定的表达式当然很好。这不可能,但我们能够找出一些常用的模式,构造效率更高,又不失通用性的正则表达式。
现在来看表6-2前面的四个例子。下画线标注的部分表示“一个转义元素,然后是更多的正常字符”。这就是关键:在每种情况下,开头是引号,然后是「[^\\"]+」,然后是若干个 。综合起来就得到
。综合起来就得到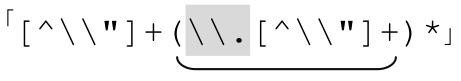 。这个特殊的例子说明,通用模式可以用来构建许多有用的表达式。
。这个特殊的例子说明,通用模式可以用来构建许多有用的表达式。
表6-2:消除循环的具体情况
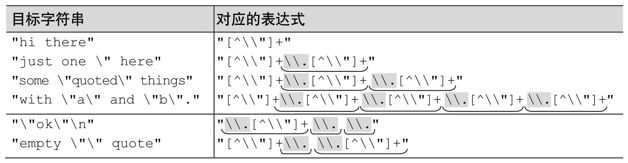
构造通用的“消除循环”解法
在匹配双引号字符串时,引号自身和转义斜线是“特殊”的——因为引号能够表示字符串的结尾,反斜线表示它之后的字符不会终结整个字符串。在其他情况下,「[^\\"]」就是普通的点号。考察它们如何组合为 ,首先它符合通用的模式
,首先它符合通用的模式 。
。
再添加两端的引号,就得到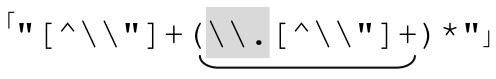 。不幸的是,表6-2中下面两个例子无法由这个表达式匹配。症结在于,目前这个正则表达式的两个「[^\\"]+」要求字符串以一个普通字符开始,然后是任何数目的特殊字符。从这个例子中我们可以看到,它并不能应付所有情况——字符串可能以转义元素开头和结尾,一行中间也可能包含两个转义元素。我们可以尝试把两个加号改成星号:
。不幸的是,表6-2中下面两个例子无法由这个表达式匹配。症结在于,目前这个正则表达式的两个「[^\\"]+」要求字符串以一个普通字符开始,然后是任何数目的特殊字符。从这个例子中我们可以看到,它并不能应付所有情况——字符串可能以转义元素开头和结尾,一行中间也可能包含两个转义元素。我们可以尝试把两个加号改成星号: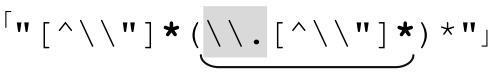 。这会达到我们期望的结果吗?更重要的是,它是否会产生负面影响?
。这会达到我们期望的结果吗?更重要的是,它是否会产生负面影响?
就期望的结果来说,很容易看到所有的例子都能匹配。事实上,即使是"\"\"\""这样的字符串都能匹配。这当然很不错。不过,我们还需要确认,这样重大的改变,是否会导致预料之外的结果。格式不对的引号字符串能否匹配呢?格式正确的引号字符串是否可能无法匹配呢?效率又如何呢?
仔细看看 。开头的「"[^\\"]*」只会应用一次,这没有问题:它匹配开头必须出现的引号,以及之后的任何普通字符。这没有问题。接下来的「(\\.[^\\"]*)*」是由星号限定的,所以不匹配任何字符也能够成功。也就是说,去掉这一部分仍然会得到一个合法的表达式。这样我们就得到「"[^\\"]*"」,这显然没有问题——它代表了常见的,也就是没有转义元素的情形。
。开头的「"[^\\"]*」只会应用一次,这没有问题:它匹配开头必须出现的引号,以及之后的任何普通字符。这没有问题。接下来的「(\\.[^\\"]*)*」是由星号限定的,所以不匹配任何字符也能够成功。也就是说,去掉这一部分仍然会得到一个合法的表达式。这样我们就得到「"[^\\"]*"」,这显然没有问题——它代表了常见的,也就是没有转义元素的情形。
另一方面,如果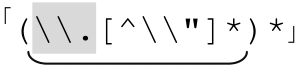 部分匹配了一次,其实就等价于
部分匹配了一次,其实就等价于 。即使结尾的「[^\\"]*」没有匹配任何文本(其实就是
。即使结尾的「[^\\"]*」没有匹配任何文本(其实就是 ),也没有问题。照这样分析下去(如果没记错的话,这就是高中代数中的“照此类推(by induction)”),我们发现,这样的改动其实是没有任何问题的。
),也没有问题。照这样分析下去(如果没记错的话,这就是高中代数中的“照此类推(by induction)”),我们发现,这样的改动其实是没有任何问题的。
所以,我们最后得到的,用来匹配包括转义引号的引号字符串的正则表达式就是:

真正的“消除循环”解法
The Real"Unrolling-the-Loop"Pattern
综合起来,匹配包括转义引号的双引号字符串正则表达式就是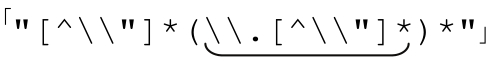 。这和原来的表达式能够匹配的结果是完全一致的。但是循环消除之后,表达式能够在有限的时间内结束匹配。不但效率高得多,并且避免了无休止匹配。
。这和原来的表达式能够匹配的结果是完全一致的。但是循环消除之后,表达式能够在有限的时间内结束匹配。不但效率高得多,并且避免了无休止匹配。
消除循环常用的解法是:
「opening normal*(special normal*)*closing」
避免无休止匹配
避免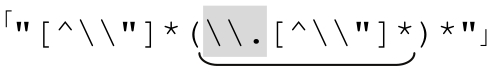 中的无休止匹配,有三点很重要:
中的无休止匹配,有三点很重要:
1)special部分和normal部分匹配的开头不能重合。
special 和 normal 部分的子表达式不能从同一位置开始匹配。在上例中,normal 部分是「[^\\"]」,special 部分是「\\.」,显然它们不能匹配同样的字符,因为后者要求以反斜线开头,而前者不容许出现开头的反斜线。
另一方面,「\\.」和「[^"]」都能够从‘"Hello☞\n"’开始匹配,所以它们不符合这种解法。如果二者能够从字符串中的同一位置开始匹配,就无法确定该使用哪一个,这种不确定就会造成无休止匹配。‘ ’的例子说明了这一点(☞227)。如果无法匹配(或是POSIX NFA引擎在任何情况下的匹配),就必须尝试所有的可能性。这非常糟糕,因为改进这个表达式的首要原因就是为了避免这种情况。
’的例子说明了这一点(☞227)。如果无法匹配(或是POSIX NFA引擎在任何情况下的匹配),就必须尝试所有的可能性。这非常糟糕,因为改进这个表达式的首要原因就是为了避免这种情况。
如果我们确信,special和normal部分不能匹配同样的字符,就可以将special部分用作检查点,消除normal部分在「(…)*」的各轮迭代时匹配同样文本造成的不确定性。如果我们确信special部分和normal部分永远不会匹配同样的文本,则特定目标字符串的匹配中存在唯一的special部分和normal部分的“组合序列”。检查这个序列比检查成千上万种可能要快得多,于是避免了无休止匹配。
2)normal部分必须匹配至少一个字符
第二点是,如果normal部分需要匹配字符才能成功,则它必须匹配至少一个字符。如果我们能够匹配成功,而不占用任何字符,那么下面的字符仍然必须由「(special normal*)*」的不同迭代来匹配,这样我们就回到了原来的(…*)*的问题。
选择「(\\.)*」作为special部分就违背了这条规定。 注定是个糟糕的表达式,如果用它来匹配‘"Tubby’(会失败),在得到匹配失败的结论之前,引擎必须尝试若干个「[^\\"]*」匹配‘Tubby’的每一种可能。因为special部分可以不匹配任何字符,所以它无法作为检查点。
注定是个糟糕的表达式,如果用它来匹配‘"Tubby’(会失败),在得到匹配失败的结论之前,引擎必须尝试若干个「[^\\"]*」匹配‘Tubby’的每一种可能。因为special部分可以不匹配任何字符,所以它无法作为检查点。
3)special部分必须是固化的
special 部分匹配的文本不能由该部分的多次迭代完成。如果需要匹配Pascal中可能出现的注释{…}和空白。能够匹配注释部分的正则表达式是「\{[^}]*\}」,所以整个正则表达式就是「(\{[^}]*\)|·+)*」(它永远不会终止)。或许,你会这样划分normal和special部分:

使用我们学会的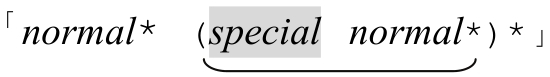 的解法,我们得到 「(\{[^]}*\})*
的解法,我们得到 「(\{[^]}*\})*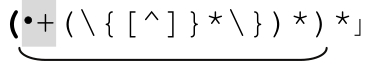 。现在来看这个字符串
。现在来看这个字符串
{comment}···{another}··
匹配连续空格的可能是单个「·+」,或多个「·+」匹配(每个匹配一个空格),或是多个「·+」的组合(每个匹配不同数目的空格)。这很像之前的‘ 的问题。
的问题。
此问题的根源在于,special部分既能够匹配很长的文本,也能通过(…)*匹配其中的部分文本。非确定性开了“多种方式匹配同样文本”的口子。
如果存在全局匹配,很可能「·+」只匹配一次,但是如果不存在全局匹配(例如把这个表达式作为另一个大的表达式的一部分),引擎就必须对每一段空格测试「(·+)*」所有的可能。这需要时间,但这对全局匹配无益。因为special部分应该作为检查点,而这里没有任何需要检查的非确定性。
解决的方法就是,保证special部分只能够匹配固定长度的空格。因为它必须匹配至少一个空格,但可能匹配更多,我们用「·」作为special部分,用「(…)*」来保证special的多重应用能匹配多个空格。
这个例子很适合讲解,但是实际应用起来,效率更高的办法可能是交换 special 和 normal表达式:
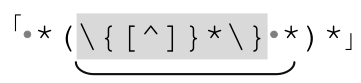
因为我估计Pascal程序的注释不会比空格少,而且对常见情况来说更有效的办法是用normal部分匹配常见的文本。
寻找通用套路
如果你真正掌握了这些规则(可能需要反复阅读和一些实践),你就能把这几条推广开来,作为指导规则,用来识别可能造成无休止匹配的正则表达式。如果有若干个量词存在于不同的层面,例如「(…*)*」,我们就必须小心对待,但是许多这样的表达式却是完全没有问题的。例如:
●「(Re:·*)*」用来匹配任意数目的‘Re:’序列(可以用来清除邮件主题中的‘Subject:·Re:·Re:·Re:·hey’)。
●「(·*\$[0-9]+)*」用来匹配美元金额,可能有空格作分隔。
●「(.*\n)+」用来匹配一行或多行文本。(事实上,如果点号不能匹配换行符,而这个子表达式之后又有别的元素导致匹配失败,就会造成无休止匹配)。
这些表达式都没有问题,因为每一个都有检查点,也就不会产生“多种方式匹配同样文本”的问题。在第一个里面是「Re:」,第二个里面是「\$」,第三个(如果点号不能匹配换行符)是「\n」。
方法2:自顶向下的视角
Method 2:A Top-Down View
还记得吗?我说过,“消除循环”有两种办法。如果采用第二种办法,开始只匹配目标字符串中最常见的部分,然后增加对非常见情况的处理。让我们来看会造成无休止匹配的表达式「(\\.|[^\\"]+)*」期望匹配的文本以及它可能应用的场合。我认为,通常情况下引用字符串中的普通字符会比转义字符更多,所以「 [^\\"]+」承担了大部分工作。「\\.」只需要用来处理偶然出现的转义字符。我们可以使用多选结构来应付两种情况,但糟糕的是,为了处理少部分(决不可能是大部分)转义字符,这样做会降低效率。
如果我们认为「[^\\"]+」能够匹配字符串中的绝大部分字符,就知道如果匹配停止,大概是遇到了闭引号或者是转义字符。如果是转义字符,后面容许出现更多的字符(无论是什么),然后开始「[^\\"]+」的新一轮匹配。每次[^\\"]+的匹配终止,我们都回到相同的处境:期望出现一个闭引号或者是另一个转义。
我们可以很自然地用一个表达式来表达它,得到与方法1同样的结果:

我们知道,匹配每次进行到☞标记的位置时,应该出现一个反斜线或者闭双引号。如果反斜线能匹配,就匹配它,然后是被转义的字符,然后是更多的字符,直到下一次到达“闭引号或者反斜线”的位置。
和之前一样,最开始的非引用内容或是引号内的文本可能为空。我们可以把两个加号改成星号,这样就得到与264页相同的表达式。
方法3:匹配主机名
Method 3:An Internet Hostname
上面介绍了两种消除循环的办法,不过我还愿意介绍另一种办法。在用正则表达式匹配如www.yahoo.com这样的主机名时,它令我震惊。主机名主要是用点号分隔的子域名的序列,准确地划定子域名的匹配规范很麻烦(☞203),为了保证清晰,我们使用「[a-z]+」来匹配子域名。
如果子域名是「[a-z]+」,我们希望得到点号分隔的子域名序列,首先要匹配第一个子域名。之后其他的子域名以点号开头。用正则表达式来表示,就是「[a-z]+(\.[a-z]+)*」。现在,如果我希望添加上前面出现的各种标记,就得到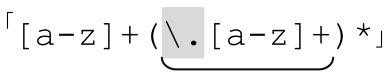 ,显然它看起来非常熟悉,对吗?
,显然它看起来非常熟悉,对吗?
为了说明这种相似性,我们尝试把它对应到双引号字符串的例子。如果我们认为字符串是‘"…"’之内的文本,包括normal 部分「[^\\"]」,由special 部分「\\.」分隔,就能套用消除循环的解法,得到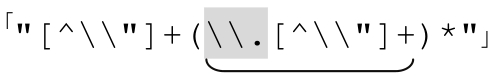 中,也就是在讨论方法1中的某个地步。也就是说,从概念上讲,我们能够把由点号分隔的主机名的问题看成双引号字符串的问题,也就是“由转义元素分隔的非转义元素构成的序列”。这可能不那么直观,但是我们可以使用前面用过的套路。
中,也就是在讨论方法1中的某个地步。也就是说,从概念上讲,我们能够把由点号分隔的主机名的问题看成双引号字符串的问题,也就是“由转义元素分隔的非转义元素构成的序列”。这可能不那么直观,但是我们可以使用前面用过的套路。
二者既存在相似性,也存在区别。在方法1中,我们改变正则表达式是为了容许normal部分和special部分之后出现空白,但是这里不容许出现空白。所以虽然这个例子与之前的并非完全相同,但也属于同一类,同样可以用来证明消除循环的技巧的强大和便捷。
子域名的例子与之前的例子有两大区别:
●域名的开始和结束没有分界符。
●子域名的normal部分不可能为空(也就是说两个点号不能紧挨在一起,点号也不能出现在整个域名的开头或结尾)。对双引号字符串来说,normal部分可以为空,即使按照我们的假设它们不太应该为空。所以我们需要把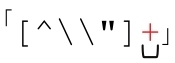 改为
改为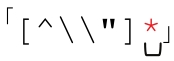 。而子域名的例子不能进行这种修改,因为special部分是分隔符,必须出现。
。而子域名的例子不能进行这种修改,因为special部分是分隔符,必须出现。
观察
Observations
回过头来看双引号字符串的例子,表达式「"[^\\"]*(\\.[^\\"]*)*"」有许多优点,也存在一些陷阱。
陷阱:
●可读性 这是最大的问题,原来的「"([^\\"]|\\.)*"」可能更容易一眼看懂,我们放弃了可读性来追求效率。
●可维护性 可维护性可能更复杂,因为任何改动都必须保持对两个[^\\"]相同。我们牺牲了可维护性来追求效率。
好处:
●速度 如果不能匹配,或是采用 POSIX NFA,这个正则表达式不会进入无休止匹配。因为进行了精心地调校,特定的文本只能以唯一的方式匹配,如果文本不能匹配,引擎会迅速发现它。
●还是速度 正则表达式“操作连续性(flow)”很好,这也是“流畅运转的正则表达式”(☞277)的主题。我对传统型 NFA 进行了检测,消除循环之后的表达式总是比之前使用多选结构的表达式要快得多。即使匹配能够成功,不会进入无休止匹配状态时,也是如此。
使用固化分组和占有优先量词
Using Atomic Grouping and Possessive Quantifiers
表达式「"(\\.|[^\\"]+)*"」之所以会进入无休止匹配的状态,问题在于,如果无法匹配,它会陷入徒劳的尝试。不过,如果存在匹配,就能很快结束,因为「[^\\"]+」能够匹配目标字符串中的大多数字符(也就是之前讨论过的normal部分)。因为「[…]+」通常会为速度优化(☞247),而且能够匹配大多数字符,外面的「(…)* 」量词的开销因此大为减少。
所以,「"(\\.|[^\\"]+)*"」的问题就在于,不会在匹配时会陷入徒劳的尝试,在我们知道毫无用处的备用状态之中不断回溯。我们知道这些状态毫无价值,因为他们只是检查同样对象的不同排列(如果「abc」不能匹配‘foo’,那么「abc」或者「abc」(以及「abc」,「abc」或者无论什么形式的「abc」)都不能匹配。如果我们能抛弃这些状态,正则表达式就能迅速报告匹配失败)。
抛弃(或者是忽略)这些状态的方法有两种:固化分组(☞139)或者占有优先量词(☞142)。
在我们着手消除回溯以前,我希望交换多选分支的顺序,把「"(\\.|[^\\"]+)*"」变为「"([^\\"]+|\\.)*"」,这样匹配“普通”文本的元素就出现在第一位。前几章中我们已经数次提到过,如果两个或两个以上的多选分支能够在同一位置匹配,排列顺序的时候就要小心,因为顺序可能影响到匹配的结果。但对于本例来说,不同多选分支匹配的是不同的文本(某个多选分支在一处能够匹配,则其他多选分支在此处就不能匹配),从正确匹配的角度来看,顺序就是无关紧要的,所以我们可以根据清晰或效率的要求来选择顺序。
使用占有优先量词避免无休止匹配
会造成无休止匹配的表达式「"([^\\"]+|\\.)*"」有两个量词。我们可以把其中一个改为占有优先量词,或者两个都改。这两者有区别吗?因为大多数回溯的麻烦源自「[…]+」留下的状态,所以把它改成占有优先是我的第一想法。这样得到的表达式,即使找不到匹配,速度也很快。不过,把外面的「(…)*」改成占有优先会抛弃括号内的所有备选状态,其中包括「[…]+」和多选结构本身的备选状态,所以如果我要从中选取一个的话,我会选取后者。
但我们并非只能选择一个,因为我们可以把两个都改为占有优先量词。具体哪种办法最快,可能取决于占有优先量词的优化情况。现在,只有Sun的Java regex package支持这种表示法,所以我的测试只能在Java中进行,并且发现某些情形下其中一种组合更快。我原本期望,使用两个占有优先量词是最快的,所以这些结果让我相信,Sun的优化还不够彻底。
使用固化分组避免无休止匹配
如果要对「"([^\\"]+|\\.)*"」使用固化分组,最容易想到的办法就是把普通括号改成固化分组括号:「"(?>[^\\"]+|\\.)*"」。不过我们必须知道,在抛弃状态的问题上,「(?>…|…)*」与占有优先的「(…|…)*+」是迥然不同的。
「(…|…)*+」在完成时不会留下任何状态,相反,「(?>…|…)*」只是消除多选结构每次迭代时保留的状态。星号是独立于固化分组的,所以不受影响,这个表达式仍然会保留“跳过本轮迭代”的备用状态。也就是说,回溯中的状态仍然不是确定的最终状态。我们希望同时消除外面量词的备用状态,所以要把外面的括号也改成固化分组。也就是说模拟占有优先「(…|…)*+」必须用到「(?>(…|…)*)」 。
解决无休止匹配的问题时,「(…|…)*+」和「(?>…|…)*」都很有用,但是它们在抛弃状态的选择和时间上却是不同的(更多的差异,请参阅173页)。
简单的消除循环的例子
Short Unrolling Examples
现在我们大概了解了消除循环的思想,来看看书中曾经出现过的几个例子,想想该如何消除循环。
消除“多字符”引文中的循环
在第4章第167页,我们看到这个例子:

normal部分是「[^<]」,special部分是「(?!</?B>)<」,下面是改进的版本:

这里固化分组并不是必须的,但如果只能部分匹配,使用固化分组能够提高速度。
消除连续行匹配例子中的循环
连续行的例子出现在前一章的开头(☞186),当时使用的表达式是「^\w+=([^\n\\]|\\.)*」。看起来这很适合应用这种技巧:

与上一个例子一样,固化分组不是必须的,但它能让引擎更快地报告匹配失败。
消除CSV正则表达式中的循环
第5章用了很长的篇幅讨论CSV的处理,最后得到第216页的代码:

当时的结论是,最好在开头添加「\G」,这样就能避免驱动过程带来的麻烦,并且效率也会提高。现在我们知道如何消除循环,就可以此技巧来看看如何应用这个例子。
用来匹配微软的CSV字符串的正则表达式是「(?:[^"]|"")*」,它看起来很不错。其实,这个表达式已经区分了normal和special部分:「[^"]」和「""」。下面我们把这个表达式写清楚,用原来的Perl代码说明消除循环的过程:

如其他的例子一样,固化分组不是必须的,但可以提高效率。
消除C语言注释匹配的循环
Unrolling C Comments
现在来看个匹配更复杂字符串时消除循环的例子。在C语言中,注释以/*开头,*/结尾,可以有多行,但不能嵌套(C++、Java和C#也容许这种形式的注释)。匹配此类注释的正则表达式在许多情况下都有用,例如构建去掉注释的过滤程序。写这个程序时我首先想到的就是消除循环,而这个技巧现在已经成为我的正则表达式宝库中的重要装备。
真的需要消除吗
我在20 世纪 90 年代早期就开始开发本节讨论的这个正则表达式。在那之前,人们认为用正则表达式匹配 C 语言的注释即使不是不可能,也是很困难的事情,所以一些可行的办法由我开发出来之后,就成为匹配C语言注释的标准方法。不过,在Perl引入忽略优先量词之后,出现了简单得多的办法:使用能匹配所有字符的点号「/\*.*?\*/」。
在我写程序的时候忽略优先量词还没有出现,如果当时有这种现成的特性,就不用费这么多周折了。不过,我的解决办法仍然是有效的,因为即使在首次支持忽略优先量词的那一版 Perl 中,使用消除循环技巧的程序仍然要比使用忽略优先量词的快得多(我做了许多种测试,有时快50%,也有时快360%)。
不过,Perl 现在综合了各种优化措施,形势就颠倒过来,忽略优先量词的程序要快上 50%到550%。所以我现在使用「/\*.*?\*/」来匹配C语言的注释。
这是否意味着,现在匹配 C 语言注视用不着消除循环的技巧了?如果引擎不支持忽略优先量词,消除循环的价值就能体现出来。也不是所有的正则引擎都能综合各种优化:在我测试的其他任何语言中,消除了循环的程序都要更快——最快的时候速度相差60倍!消除循环的技巧确实很有用,所以下文讲解如何用它来匹配C语言注释。
因为匹配C 语言注释时不存在双引号字符串中转义字符\"的问题,可能有人觉得事情会比较简单,但问题其实更复杂。因为这里的“结束双引号”*/不止一个字符。直接用「/\*[^*]*\*/」可能看起来没问题,但不能匹配/**some comment here**/,因为其中还有‘*’,而这是必须匹配的,所以我们需要另外的办法。
换更清晰的表示方法
你可能觉得「/\*[^*]*\*/」难以阅读,即使本书的体例已经尽量做到容易看懂。但不幸的是,注释部分的边界符‘*’本身就是正则表达式的元字符,所以得使用反斜线转义,结果正则表达式看起来让人头疼。为了看得更清楚,我们在这个例子中使用/x…x/,而不是/*…*/。经过这个细微的改动,「/\*[^*]*\*/」变成了更容易看懂的「/x[^x]*x/」。这个表达式会随着我们的讲解变得越来越复杂,到时你会发现这个改动的价值。
直接的办法
在第5章(☞196),我给出了匹配分隔符之内文本的公式:
1.匹配起始分隔符;
2.匹配正文:匹配“除结束分隔符之外的任何字符”;
3.匹配结束分隔符。
现在我们的程序以/x和x/作为开始和结束分隔符,它似乎很符合这个模式。难处在于匹配“除结束分隔符之外的任何字符”。如果结束分隔符是单个字符,我们可以用排除型字符组。但字符组不能用来进行多字符匹配,不过如果能使用否定型顺序环视,我们就能使用「(?:(?!x/).)*」。这就是「除结束分隔符之外的任何字符」。
于是我们得到「/x(?:(?!x/).)*x/」。它没有问题,但速度很慢(在我做的一些测试中,速度要比下面的表达式慢几百倍)。这个思路很有用,但缺乏实用性,因为几乎所有支持顺序环视的流派都支持忽略优先量词,所以效率并不是问题,你完全可以用「/x.*?x/」。
那么,顺着这种分三步走的思路,是否有其他办法匹配第一个 x/之前的文本?能想到的办法有两个。之一是把 x作为开始分隔符和结束分隔符,也就是说,匹配除 x之外的任何字符,以及之后字符不为斜线的x。这样,“除结束分隔符之外的任何字符”就成了:
●除x之外的任何字符:「[^x]」。
●之后字符不是斜线的x:「x[^/]」。
这样得到「([^x]|x[^/])*」来匹配主体文本,「/x([^x]|x[^/])*x/」来匹配整个注释。我们会发现这条路行不通。
另一种办法是,把紧跟在 x 之后斜线当作结束分隔符。这样“除结束分隔符之外的任何字符”就成了:
●除斜线外的任何字符:「[^/]」。
●紧跟在x之后的斜线:「[^x]/」。
于是用「([^/]|[^x]/)*」匹配主体文本,「/x([^/]|[^x]/)*x/」匹配整个注释。
不幸的是,这同样是死路。
如果用「/x([^x]|x[^/])*x/」来匹配‘/xx·foo·xx/’,在‘foo·’之后,第一个x由「x[^/]」匹配,这当然没有问题。但是之后,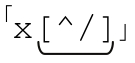 匹配
匹配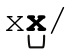 ,而这个 x 应该是标记注释的结束。于是继续下一轮迭代,「[^x]」匹配斜线,结果会匹配x/之后的文本。
,而这个 x 应该是标记注释的结束。于是继续下一轮迭代,「[^x]」匹配斜线,结果会匹配x/之后的文本。
「/x([^/]|[^x]/)*x/」也不能匹配‘/x/·foo·/x/’(整个注释都应该匹配)。如果注释结尾后紧跟斜线,表达式匹配的内容会超过注释的结束分职符(这也是其他解法的问题)。而在本例中,回溯可能有些令人迷惑,所以读者最好弄明白「/x([^/]|[^x]/)*x/」为什么能匹配
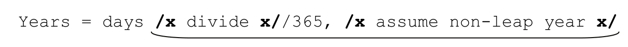
(可以在空余时间好好想想这个问题。)
怎么办
让我们来修正这些表达式。在第一种情况下,因为疏忽,「x[^/]」匹配了结尾的…xx/。如果我们用「/x([^x]|x+[^/])*x/」。我们认为,添加加号之后,「x+[^/]」匹配以非斜线字符结尾的一连串x。确实它能够这样匹配,但因为回溯“斜线之外的任意字符”仍然可以是x。首先,匹配优先的「x+」匹配我们需要的额外的x,但是如果全局匹配需要,回溯会逐个释放它们。所以它仍然会匹配过多内容:
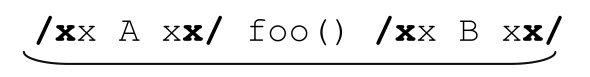
要解决这个问题,还得回到之前介绍的办法:准确表达我们希望表达的意思。如果我们说的“紧跟字符不是斜线的一些 x”其实就是除 x之外的非斜线字符,就应该用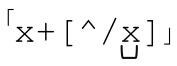 。它不会匹配
。它不会匹配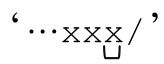 ’,一连串x中表示注释结束的那个x。事实上,它还有个问题,就是无法匹配注释结束之前的任意多个 x,所以会在
’,一连串x中表示注释结束的那个x。事实上,它还有个问题,就是无法匹配注释结束之前的任意多个 x,所以会在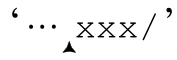 ’停下来。因为我们预计结尾分隔符前只有一个x,所以必须加入「x+/」处理这种情况。
’停下来。因为我们预计结尾分隔符前只有一个x,所以必须加入「x+/」处理这种情况。
于是得到「/x([^x]|x+[^/x])*x+/」,匹配最终的注释。

这看起来很迷惑,对吗?真正的表达式(用*取代 x)就是「/\*([^*]|\*+[^/*])*\*+/」,这样更复杂了,更不容易看懂,所以在理解复杂的正则表达式时,一定要保持清醒的思维。
消除C语言注释的循环
为了提高表达式的效率,我们必须消除这个表达式的循环。下一页的表6-3给出了我们能够“消除循环”的表达式。
和子域名的例子一样,「normal*」必须匹配至少一个字符。子域名的例子中是因为 normal 部分不能为空。本例中必须的结束分隔符包含两个字符。我们确信,任何以结束分隔符的第一个字符结尾的任何normal序列,只有在紧跟字符不能组成结束分隔符的情况下,才会把控制权交给special部分。
表6-3:消除C语言注释的循环

所以,按照通用的消除套路,我们得到:
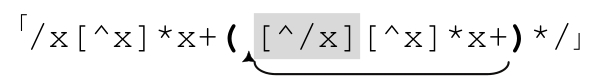
请注意☞标注的位置。正则引擎可能有两种办法到达此处(267页的表达式也是如此)。第一个是在开头的「/x[^x]*x+」匹配之后直接前进到此处,第二是在(…)*循环的某一轮中。无论哪种情况,只要到达此处,我们就知道已经匹配了x,到达关键位置(pivotal point),可已经进入了注释的结尾分隔符。如果下面的字符是斜线,则匹配完成。如果是其他字符(当然不是x),我们知道之前的判断是错误的,然后回到normal部分,等待下一个x。找到之后我们再一次回到标记位置。
回到现实
「/x[^x]*x+([^/x][^x]*x+)*/」还不能直接拿来用。首先,注释是/*…*/而不是/x…x/。当然,我们可以很容易地把每个x替换为\x(字符组中的x替换为*):
「/\*[^*]*\*+([^/*][^*]*\*+)*/」
实际情况中,注释通常会包括多行。如果匹配的注释包括多行,这个表达式也应该能够应付。如果是严格以行为处理单位的工具,例如egrep,当然没办法用一个正则表达式匹配所有的行。对本书中提到的大多数工具,我们的确可以用这个表达式来匹配多行,删除它们。
在实际中,会遇到许多问题。这个正则表达式能够识别C的注释,但不能识别C语法的其他重要方面。例如,划线的部分尽管不是注释,也能够匹配:
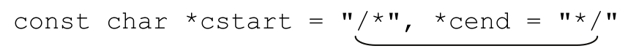
我们会在下一节接着讨论这个例子。