Fun with Perl Enhancements
最先由 Perl 提供的许多正则表达式概念,现在其他语言也提供了。包括非捕获型括号、环视(以及之后的逆序环视)、宽松排列模式(其实是大多数模式,实际上还包括配套的「\A」、「\z」和「\Z」)、固化分组、「\G」和条件判断结构。这些概念不再是Perl独有的,所以我把它们挪到本书的通用部分。
不过Perl者也没有停止创新,所以现在还有些重要的概念只有Perl提供。其中最有意思的是在匹配尝试中执行任意代码的功能。长期起来,Perl的特点之一就是正则表达式与代码的紧密集成,但是此特性把集成提升到了新的高度。
我们先来简单看看这个特性和目前Perl独有的其他特性,然后详细讲解。
动态正则结构
「(??{perl code})」
应用正则表达式时,每次遇到表达式中的这个结构,就会执行其中的Perl代码。执行的结果(或者是 regex 对象,或者是解释为正则表达式的字符串)会作为当前匹配的一部分即刻被应用。
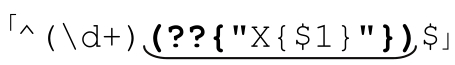 中的动态正则结构以下画线标注,这个正则表达式匹配的行开头是一个数,然后是字符‘X’必须重现对应的次数,直到行末尾。
中的动态正则结构以下画线标注,这个正则表达式匹配的行开头是一个数,然后是字符‘X’必须重现对应的次数,直到行末尾。
它能匹配‘3XXX’和‘12XXXXXXXXXXXX’,但不能匹配‘3X’或‘7XXXX’。
仔细看‘3XXX’就会发现,开头的「(\d+)」匹配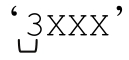 ’,把$1设为‘3’。之后正则引擎遇到动态正则结构,执行“X{$1}”,得到‘X{3}’,解释得到的「X{3}」作为当前正
’,把$1设为‘3’。之后正则引擎遇到动态正则结构,执行“X{$1}”,得到‘X{3}’,解释得到的「X{3}」作为当前正
则表达式的一部分(匹配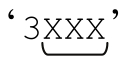 ),末尾的「$」匹配‘3XXX☞’,得到整体匹配。
),末尾的「$」匹配‘3XXX☞’,得到整体匹配。
下面我们会看到,匹配任意深度的嵌套结构时,动态正则结构尤其有用。
嵌套代码结构
「
(?{arbitrary perl code})
」
与动态正则结构一样,在正则表达式的应用过程中,遇到此结构也会执行其中的 Perl代码,但是这个结构更为通用,因为代码不需要返回任何特定的值。通常也不会用到返回值(不过如果表达式之后的部分需要,可以通过变量$^R得到☞302)。
有一种情况会用到这段代码的执行结果:如果内嵌的代码结构用作「(?if then|else)」中的if条件(☞140)。此时,结果会解释为布尔值,根据它来决定执行then还是else分支。
内嵌代码可以干许多事情,相当有用的就是调试。下面这段程序会在每次应用正则表达式时显示一条信息,内嵌的代码结构用下画线标注:

测试中,正则表达式只匹配1次,但是信息会显示6次,说明传动装置在第6次尝试之前已经在5个位置应用了正则表达式,第6次可以完全匹配。
正则文字重载
正则文字重载能够让程序员先自行处理正则文字,再将它们交给正则引擎。它可以用来为Perl的正则流派扩展新的功能。例如,Perl没有提供单独的单词起始和结束分隔符(只有「\b」),不过你可能希望使用\<和\>,让Perl能够识别这些结构。
正则重载有些重要的限制,严格制约了它的用途。在讲解\<与\>的例子时我们会看到这一点。
如果正则表达式中内嵌了Perl代码(无论是动态正则结构还是内嵌代码结构),最好是只使用全局变量,除非你明白关于338页讲解的 my变量的重要知识。关于 my变量的讨论,请参阅第338页。
用动态正则表达式结构匹配嵌套结构
Using a Dynamic Regex to Match Nested Pairs
动态正则表达式的主要用途之一是匹配任意深度的嵌套结构(长久以来人们认为正则表达式对此无能为力)。匹配任意深度的嵌套括号是个重要的例子。为了说明白动态正则如何解决这个问题,我们首先必须知道传统结构为什么不能解决这个问题。
匹配括号文本的简单表达式是「\(([^()])*\)」。在外层括号内不容许出现括号,所以不能容许嵌套(也就是,只容许深度为0的嵌套)。用regex对象来表示就是:

这能够匹配“substr($str,0,3)”,但不能配“substr($str,0,(3+2))”,因为它包含嵌套的括号。现在修改正则表达式来处理它,也就是需要能够处理深度为1的嵌套。
容许深度为 1 的嵌套意味着,外部的括号里头可以出现括号。所以,我们需要修改匹配外层括号内文本的表达式「[^()]」,添加一个子表达式匹配内层括号里的文本。我们可以这样,$Level0保存这样一个正则表达式,再从此往上叠加:
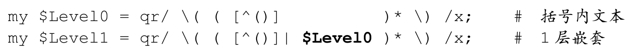
这里的$Level0与之前的相同,新出现了$Level1,匹配对应深度的括号,加上$Level0,就得到深度为1的嵌套。
为了增加嵌套的深度,我们可以用同样的方法,通过$Level1(仍然使用$Level0)得到$Level2:
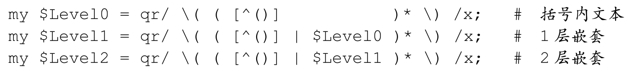
继续下去就是:

图7-1说明了开始几层的情况:
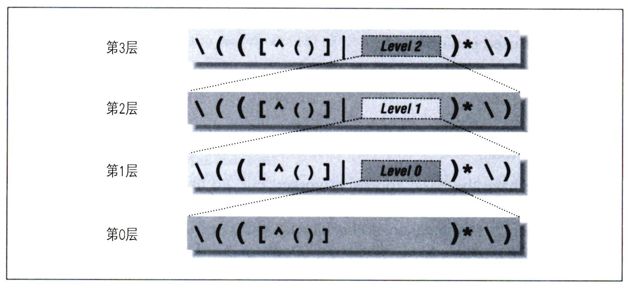
图7-1:层数较少的嵌套
把这些层级加起来的结果很复杂,下面是$Level13:
\(([^]|\(([^]|\(([^]|\(([^])*\))*\))*\))*\)
这相当难看。
幸运的是,我们不需要直接解释它(那是正则引擎的工作)。使用$Level变量很容易处理,但问题是,嵌套的深度是由$Level变量的数目决定的。这种办法不够灵活(用墨非定律来说就是,如果程序能处理深度为X的嵌套,则遇到的数据的嵌套深度必定会是X+1)。
幸运的是,动态正则可以应付任意深度的嵌套。你只需要想明白,除第一个之外,每个$Level变量的构建方式都是相同的:需要增加一级嵌套深度时,只需要包含上一级的$Level变量即可。但如果$Level变量都是相同的,它就同样能包含更深级别的$Level。事实上,它还可以包括自身。如果在匹配更深层的嵌套时它可以用某种方式包含自身,就能递归地处理任意深度的嵌套。
这就是动态正则的威力所在。如果我们创建一个regex 对象——比如$Level变量,就可以在动态正则中引用它(动态正则结构可以包含任意的 Perl 代码,只要结果能被解释为正则表达式,返回已存在的regex对象的Perl代码当然符合要求)。如果我们能把$Level之类的regex对象放入$LevelN,就可以用「(??{$LevelN})」来引用它:

它就能匹配任意深度的嵌套括号,用法同之前的$Level0:

哈!想明白其中的道理可不是件容易的事情,不过一旦用过,就会发现这个工具的价值。
现在我们已经有了基本的办法,我希望做些修改提高效率。我会替换捕获型括号为固化分组(这里既不需要捕获文本,也不需要回溯),之后可以把「[^()]」 改为「[^()]+」提高效率。(不要在固化分组中这样做,否则会造成无休止匹配☞226)。
最后,我希望把「\()和「\)」移动到动态正则表达式两端。这样,在确实需要用到之前,引擎不会直接调用动态正则结构。下面是修改之后的版本:
$LevelN=qr/(?> [^]+|\((??{$LevelN})\))*/x;
因为它不包含外部的「\(…\)」,调用$LevelN时必须手动添加。
这样一来,表达式就十分灵活,可以在任何可能出现嵌套括号的地方使用,而不仅仅是出现了嵌套括号的地方:

第343页还有一个关于$LevelN的例子。
使用内嵌代码结构
Using the Embedded-Code Construct
内嵌代码结构很适合调试正则表达式,以及积累正在进行的匹配的信息。下面几页详细给出了一组例子,最终得到模拟POSIX匹配的方法。讲解的过程可能比真正的答案更有意思(除非你只需要POSIX的匹配语意),因为在讲解中我们会收获有用的技巧和启发。
先从简单的正则表达式调试技巧开始。
用内嵌代码显示匹配进行信息
这段程序:

的结果是:

正则表达式的开头就是内嵌代码结构,所以只要正则表达式开始新一轮匹配,就会执行:
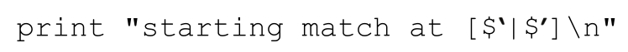
它用变量 和
和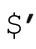 (☞300)(注9)表示目标字符串,用‘|’标记当前的匹配位置(在这里就是匹配开始的位置)。从结果中我们可以知道,传动装置(☞148)进行了 4 次应用,才匹配成功。
(☞300)(注9)表示目标字符串,用‘|’标记当前的匹配位置(在这里就是匹配开始的位置)。从结果中我们可以知道,传动装置(☞148)进行了 4 次应用,才匹配成功。
事实上,如果我们添加:
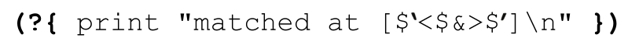
在正则表达式末尾,则结果是:
matched at [abc<d>efgh]
现在来看下面的程序,除了“主”正则表达式是「[def]」而不是「(?:d|e|f)」之外,其他部分与开头的例子是一样的:

从理论上说,结果应该是一样的,实际情况却是:
starting match at [abc|defgh]
为什么呢?Perl 足够聪明,对这个以「[def]」开头的正则表达式进行开头字符/字符组/字串识别优化(☞247),这样传动装置就能略过那些它认为必然会失败的尝试。结果是忽略了其他所有尝试,只进行了可能导致匹配的尝试,我们可以通过内嵌代码结构观察到这种现象。

用内嵌代码显示所有匹配
Perl使用的是传统型NFA引擎,所以一旦找到匹配就会停下来,即使还存在其他的匹配也是如此。如果巧妙地使用内嵌代码,我们能够让Perl显示所有的匹配。我们仍然以177页的‘onself’为例来说明。

结果如我们所料:
matched at [<oneself>sufficient]
表示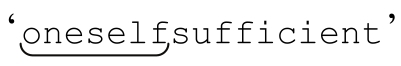 ’已经被正则表达式匹配。
’已经被正则表达式匹配。
重要的是认识到,结果中的“matched”的部分并不是所有“能够匹配”的文本,只是到目前获得的匹配。在这个例子中谈论其中的区别意义不大,因为内嵌代码结构位于正则表达式的最后。我们知道,内嵌代码结构完成时,整个正则表达式的所有匹配尝试都已结束,实际匹配的结果就是如此。
不过,在内嵌代码结构之后添加「(?!)」的情况如何呢?「(?!)」是否定型顺序环视,它必然会失败。如果它在内嵌代码执行之后生效(也就是在“matched”信息打印之后),就会强迫引擎回溯,查找新的匹配。每次输出“matched”信息之后,「(?!)」都会强迫引擎回溯,最终试遍所有的可能。

我们所做的修改确保正则表达式必然不能完整匹配,但是这样做却能让引擎报告显示所有可能的匹配。如果不使用「(?!)」,Perl只会返回第一个匹配,使用「(?!)」则可以见到其他可能。
了解了这一点之后,来看看下面的代码:
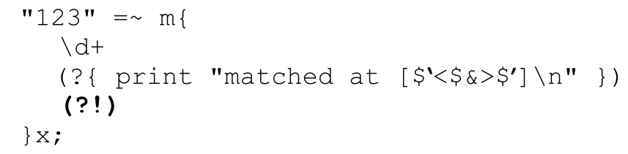
结果是:

前三行是我们能够想象的,但如果不仔细动动脑筋,可能没法理解后三行。「(?!)」强迫进行的回溯对应第二行和第三行。在开始位置的尝试失败之后,传动装置会启动驱动过程,从第二个字符开始(第4章对此有详细介绍)。第四行和第五行对应第二轮尝试,最后一行对应第三轮。
所以,添加(?!)之后确实能显示出所有可能的匹配,而不是从某个特定位置开始的所有匹配。不过,有时候只需要从特定位置开始的所有匹配,下面我们将会看到。
寻找最长匹配
如果我们不希望找到所有匹配,而是希望找到并保存最长的匹配,应该如何做呢?我们可以用一个变量来保存“到目前为止”最长的匹配,比较每一个“当前匹配”和它。下面是‘onself’的例子:

毫不奇怪,结果是‘longest match=[oneselfsufficient]’。这一段内嵌代码很长,不过将来我们可能会使用,所以我们把它和「(?!)」封装起来,作为单独的regex对象:

下面这个简单例子会找到最长的匹配‘9938’:

寻找最左最长的匹配
我们已经能找到最长的全局匹配,现在需要找到出现在最前边的最长匹配。POSIX NFA就是这样做的(☞177)。所以,如果找到一个匹配,就要禁止传动装置的驱动过程。这样,一旦我们找到某个匹配,正常的回溯会起作用,在同一位置寻找其他可能的匹配(同时需要保存最长的匹配),但是禁用驱动过程保证不会从其他位置寻找匹配。
Perl 不容许我们直接操作传动装置,所以我们不能直接禁用驱动过程,但如果$longest_match已经定义,我们能够达到实现禁用驱动过程的效果。测试定义的代码是「(?{defined$longest_match})」,但这还不够,因为它只测试变量是否定义。重要的是根据测试结果进行判断。
在条件判断中使用内嵌代码
为了让正则引擎根据测试结果改变行为,我们把测试代码作为「(?if then|else)」中的if部分(☞140)。如果我们希望测试结果为真时正则表达式停下来,就把必然失败的「(?!)」作为then部分。(这里不需要else部分,所以没有出现)。下面是封装了条件判断的regex对象:
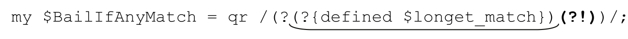
if部分以下画线标注,then部分以粗体标注。下面是它的应用实例,其中结合了前一页定义的$RecordPossibleMatch:
"800-998-9938"=~m{$BailIfAnyMatch\d+$RecordPossibleMatch}x;
得到‘800’,它符合POSIX标准——“所有最左位置开始的匹配中最长的匹配”。
在内嵌代码结构中使用local函数
Using localin an Embedded-Code Construct
local在内嵌代码结构中有特殊的意义。理解它需要充分掌握动态作用域(☞295)的概念和第4章讲解表达式主导的NFA引擎工作原理时所做的“面包渣比喻”(☞158)。下面这段专门设计(我们会看到,它有缺陷)的程序没有太多复杂的东西,但有助于理解local的意义。它检查一行文本是否只包含「\w+」和「\s+」,以及有多少「\w+」是「\d+\b」:
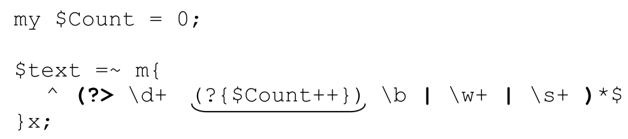
如果用它来匹配字符串‘123·abc·73·9271·xyz’,$Count 的值是 3。不过,如果匹配字符串‘123·abc·73xyz’,结果就是2,虽然应该是1。问题在于,‘73’匹配之后,$Count的值会发生变化,因为后面的「\b」无法匹配,「\d+」当时匹配的内容需要通过回溯“交还”,内嵌结构的代码却不能恢复到“未执行”的状态。
如果你还不完全了解固化分组「(?>…)」(☞139)和上面发生的回溯也没关系,固化分组用于避免无休止匹配(☞269),但不会影响结构内部的回溯,只会影响重新进入此结构的回溯。所以如果接下来的「\b」不能匹配,「\d+」的“交还”就完全没有问题。
简单的解决办法是,在$Count 增加之前添加「\b」,保证它的值只有在不进行“交还”操作的情况下才会变化。不过我更愿意在这里使用 local,来说明应用正则表达式期间这个函数对Perl代码的影响。来看这段程序:
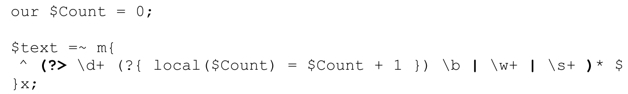
要注意的第一点是,$Count从my变量变为全局变量(我推荐使用use strict,如果这么做了,就必须使用our来“声明”全局变量)。
另一点要注意的是,$Count的修改已经本地化了。关键在于:对正则表达式内部的本地化变量来说,如果因为回溯需要“交还”local 的代码,它会恢复到之前的值(新设定的值会被放弃)。所以,即使 local($Count)=$Count+1 在「\d+」匹配‘73’之后执行,把$Count的值从1改为2,这个修改也只会是调用local时的“本地化到(当前正则表达式的)成功路径”。如果「\b」匹配失败,正则引擎会回溯到local之前,$Count恢复到1。这也就是正则表达式结束时的值。

所以,为了保证$Count的记数不发生错误,必须使用local。如果把「(?{print "Final count is $Count.\n"})」放在正则表达式的末尾,它会显示正确的计数值。因为我们希望在匹配完成之后使用$Count,就必须在匹配正式结束之前把它保存到一个非本地化的变量中。因为匹配完成之后,所有在匹配过程中本地化的变量都会丢失。
下面是一个例子:

看起来这么做有点儿折腾,但这个例子的目的是说明正则表达式中本地化变量的工作机制。我们会在第344页的“模拟命名捕获”中见到实际的应用。
关于内嵌代码和my变量的忠告
A Warning About Embedded Code and myVariables
如果my变量在正则表达式之外声明,那么在正则表达式之中的内嵌代码引用,就必须非常小心,Perl中变量绑定的详细规定可能会产生重大的影响。在讲解这个问题之前,我必须指出,如果正则表达式的内嵌代码中使用的都是全局变量就没有这种问题,完全可以跳过这一节。忠告:这一节难度不小。
下面的例子说明了问题:

程序中包含3个my变量,但是只有$start与此问题有关(因为其他两个并没有在内嵌代码中引用)。程序首先把$start 设为未定义的值,然后应用开头元素为内嵌代码的匹配,只是在$start未设定时,内嵌代码结构才会把$start设置到尝试开始位置。“本次尝试的起始位置”取自$-[0](@-的第1个元素☞302)。
所以,如果调用:
CheckOptimizer("test 123");
结果就是:
The optimizer started the match at character 5.
这没有问题,但如果我们再运行一次,结果就成了:

即使正则表达式检查的文本没有变化(而且正则表达式本身也没有变化),结果却不一样了,你发现问题了吗?问题就在于,在第二次调用中编译正则表达式时,内嵌代码中的$start取的是第一次运行之后设置的值。此函数的其他部分使用的$start其实是一个新的变量——每次函数调用的开始,执行my都会重新设置这个值。
问题的关键就在于,内嵌代码中的my变量“锁定”(用术语来说就是:绑定bound)在具体的 my变量的实例中,此实例在正则表达式编译时激活。(正则表达式的编译详见 348 页)每次调用 CheckOptimizer,都会创造一个新的$start实例,但是用户很难以察觉,内嵌代码中的$start仍然指向之前的值。这样,函数其他部分使用的$start实例并没有接收到正则表达式中传递给它的值。
这种类型的实例绑定称为“闭包(closure)”,Programming Perl和Object Oriented Perl之类的书中介绍了这种特性的价值所在。关于闭包,Perl社群中存在争议,比如本例中闭包究竟是不是一种“特性”,就有不同看法。对大多数人来说,这很难理解。
解决的办法是,不要在正则表达式内部引用 my变量,除非你知道正则文字的编译与 my实例的更新是一致的。比如我们知道,第 345 页 SimpleConvert 子程序中使用的 my 变量$NestedStuffRegex 没有这个问题,因为$NestedStuffRegex 只有一个实例。这里的 my不在函数或者循环之中,所以它只会在脚本载入时创建一次,然后一直存在,直到程序终止。
使用内嵌代码匹配嵌套结构
Matching Nested Constructs with Embedded Code
328页的程序讲解了如何使用动态表达式匹配任意深度的嵌套结构。一般来说,这都是最简单的方法,但是来看看只使用内嵌代码的办法也没坏处,所以接下来我会给出这种办法。
办法很简单:记录已经遇到的未配对开括号的数量,只有此数量大于 0 时,才容许出现闭括号。在匹配文本的过程中,我们使用内嵌代码来计数,不过在这之前必须得看看(目前还不能运行的)正则表达式的框架。

为了保证效率,我们使用了固化分组,因为如果$NestedGuts 用于更大的正则表达式,就可能导致回溯,这样「([…]+|…)*」就会造成无休止匹配(☞226)。举例来说,如果我们将其作为「m/^\($NestedGuts\)$/x」的一部分,应用到‘(this·is·missing·the·close’中,如果没有使用固化分组,就得在记录和回溯上花费漫长的时间。
为了配合计数,我们需要4步:
∂ 计数必须从0开始:
(?{local $OpenParens=0})
● 遇到开括号,就把记数器加1,表示有一对括号没有匹配。
(?{$OpenParens++})
÷遇到闭括号,就检查记数器,如果大于 0,就减去 1,表示已经匹配了一对括号。如果等于0,就停止匹配(因为闭括号与开括号不匹配),所以用「(?!)」强迫匹配失败。
(?(?{$OpenParens}) (?{$OpenParens--})|(?!))
这里使用了「(?if then|else)」条件判断(☞140),用内嵌代码判断记数器,作为if部分。≠ 一旦匹配结束就检查记数器,确保它等于 0,否则说明仍然有未匹配的开括号,因此匹配失败。
(?(?{$OpenParens!=0})(?!))
综合起来就得到:

这段程序的使用方法与第330页的$LevelN完全相同。
为了分离正则表达式中的$OpenParens 和程序中可能出现的其他全局变量,这里使用了local。但local的用法与之前的不同,这里不需要避免回溯,因为正则表达式使用了固化分组,一旦某个多选分支能够匹配,就不会变为“交还”。这样,固化分组既保证了效率,又保证了内嵌代码结构附近匹配的文本不会在回溯中交还(这样$OpenParens 就与实际匹配的开括号数目一致)。
正则文字重载
Overloading Regex Literals
通过重载,用户可以通过自己喜欢的方式预先处理正则文字中的文字部分。下面几节给出了例子。
添加单词起始/结束元字符
Perl没有提供作为单词起始/结束元字符的「\<」和「\>」,可能是因为绝大多数情况下「\b」已经够用了。不过,如果我们希望使用这两个元字符,我们可以通过重载,将表达式中的‘\<’和‘\>’分别替换为「(?<!\w)(?=\w)」和「(?<=\w)(?!\w)」。
先创建一个函数,MungeRegexLiteral,进行需要的预处理:

如果给此函数传递字符串‘…\<…’,它会将其转化为‘…(?<!\w)(?=\w)…’。记住,因为replacement部分类似双引号字符串,所以需要用‘\\w’表示‘\w’。
为了让它能够自动处理正则文字的每个文字部分,我们将其存入文件 MyRegexStuff.pm,供Perl重载:

将MyRegexStuff.pm放在Perl的库路径(library path,请参考Perl文档中的PERLLIB)下,所有需要使用此功能的 Perl 脚本都可调用。如果只是为了测试,可以将其放在测试脚本同一目录内,这样调用:

每个需要这样处理正则文字的程序文件都必须使用MyRegexStuff,但是MyRegexStuff.pm只需要构建一次(此功能在 MyRegexStuff.pm 内部不可用,因为它没有 use MyRegexStuff——我们肯定不会这样做)。
添加占有优先量词
我们继续完善MyRegexStuff.pm,让它支持占有优先量词——例如「x++」(☞142)。占有优先量词的作用类似普通的匹配优先量词,只是它们永远不会释放(也就是“交还”)任何已经匹配的内容。用固化分组来模拟的话,只需要去掉最后的‘+’,把量词修饰的所有内容放到固化分组里,「regex*+」就成了「(?>regex*)」(173)。
占有优先量词限定的部分可以是括号内的表达式,也可以是「\w」或者「\x{1234}」之类的元序列,或是普通字符。要处理所有情况并不容易,所以为简便起见,我们只关注作用于括号的?+、*+和++。有了330页的$LevelN,我们可以把这段程序:
$RegexLiteral=~s/(\($LevelN\)[*+?])\+/(?>$1)/gx;
添加到MungeRegexLiteral函数。
现在,它成为overload package的一部分,我们可以在正则文字中使用占有优先量词,例如第198页的这个例子:
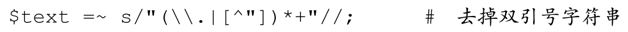
如果要处理的情况不只是括号,就要复杂很多,因为正则表达式中的变数很多,下面是一种尝试:

这个表达式的大体形式和之前一样:使用占有优先量词匹配一些内容,去掉最后的‘+’,将整个表达式用「(?>…)」围起来。要想识别 Perl 正则表达式的复杂语法,这样还很不够。匹配字符组的部分亟需改进,因为它并不能识别字符组内部的转义。更糟糕的是,这个表达式的基本思路有问题,因为它不能完整识别 Perl 的正则表达式。比如,它就不能正确处理‘\(blah\)++’中作为普通字符的开括号,而是认为「++」仅仅限定「\)」。
解决这个问题得花许多工夫,或许得想办法从前往后仔细遍历整个正则表达式(类似第132页的补充内容中的办法)。我本来希望改善处理字符组的元素,但是最后觉得没必要处理其他复杂情况,原因有两个。第一个是,这个表达式能应付大部分正常的情况,所以修正处理字符组的元素就能满足实用要求了。更重要的一点是,目前 Perl 的正则表达式重载有严重问题,结果它的用途大打折扣,讨论见下一节。
正则文字重载的问题
Problems with Regex-Literal Overloading
正则文字重载的功能非常有用,至少在理论上是如此,不幸的是实际情况并非如此。问题在于,它只对正则文字中的文字部分有效,而不会影响插值部分。例如,在m/($MyStuff)*+/中 MungeRegexLiteral 函数调用了两次,一次是在变量插值之前(“(”);另一次是插值之后(“)*+”)。(它永远不会影响$MyStuff 的值)。因为重载必须同时找到两个部分,而插入的值又是不确定的,所以实际上重载不会生效。
对之前添加的\<和\>来说,这不是个问题,因为变量替换不太可能把它们切段。但是因为重载不会影响插值变量,包含‘\<’或‘\>’的字符串或regex对象就不会受重载影响。上一节已经提到,如果由重载来处理正则文字,就很难每次都保证完整性和准确性。即使是与\>一样简单也会出问题,例如‘\\>’,它表示反斜线‘\’之后紧跟尖括号‘>’。
另一个问题是,重载不知道正则表达式所使用的修饰符。表达式是否使用了/x是很重要的问题,但重载没有确切的办法知道。
最后还必须指出,使用重载会禁止根据Unicode命名指定字符的功能(「\N{name}」☞290)。
模拟命名捕获
Mimicking Named Capture
讲完了重载的不便之后,我们来看看综合了许多特殊结构的复杂例子。Perl没有提供命名捕获(☞138)的功能,但是我们可以使用捕获型括号和$^N变量(☞301)来模拟,这个变量引用的是最近结束的捕获型括号匹配的内容(现在我假扮Perl开发人员,使用$^N,特意为Perl增加命名捕获的功能)。
来看个简单的例子:
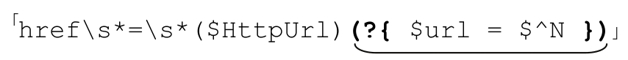
这里使用了303页的regex对象$HttpUrl。下画线部分是一段内嵌代码,把$HttpUrl匹配的内容保存到$url中。在这里用$^N取代$1似乎有些多此一举,甚至不必要使用内嵌代码,因为在匹配之后使用$1 更加方便。但是如果把其中一部分封装到 regex 对象,然后多次使用:

无论$HttpUrl是怎么匹配的,$url都会被设置为 URL。在这个简单应用中可以使用其他办法(例如$+变量☞301),但是在更复杂的情况中,$SaveUrl之外的办法更难维护,所以将它保存到命名变量中方便得多。
这里有一个问题,如果设定$url的结构在回溯中被“交还”,已设定的值却不会“撤销保存(unwritten)”。所以要在初始匹配时修改本地化的临时变量,只有在整体匹配真正确认之后才保存“真正”的变量,就像第338页的例子一样。
下面给出了一种解决办法。从用户的角度来看,在「(?<Num>\d+)」之后,「\d+」匹配的数值仍然可以以$^N{Num}访问。尽管未来版本的Perl可能会把%^N转换为某种特殊的系统变量,现在仍然不是特殊的,所以我们可以随意使用。
我们可以使用%NamedCapture之类的名字,但选择%^N是有理由的。之一是它类似$^N。另一个理由是,如果写明了use strict,它不需要预声明。最后,我希望Perl最终会内建对命名捕获的支持,所以我认为%^N是个好办法。如果果真如此,%^N就能够和正则表达式的其他变量(☞299)一样,自动使用动态作用域。但是目前,它只是普通的全局变量,所以不会自动使用动态作用域。
当然,即便是这个程序也会出现正则文字重载的办法所具有的问题,例如不能处理插值变量。

