数据正在呈指数级增长。之所以增长速度如此之快,背后有许多原因。现在几乎所有数据的产生形式,都是数字化的。各种传感器的剧增,高清晰度的图像和视频,都是数据爆炸的原因。
如何收集、管理和分析数据正在日渐成为我们网络信息技术研究的重中之重。以机器学习01、数据挖掘为基础的高级数据分析技术,将促进从数据到知识的转化、从知识到行动的跨越。
联邦政府的每一个机构和部门,都需要制定一个应对“大数据”(Big Data)的战略。02
——《规划数字化的未来:美国总统科学技术顾问委员会给总统和国会的报告》2010年
如果说《信息自由法》在法律的层面上规定了政府机关的文件可以公开,其后的《阳光政府法》规定政府机关的会议必须公开,《电子信息自由法》又规定了计算机内的数据也不能例外,那么奥巴马继续开拓的空间似乎已经不大了。
他所谓的“要建设一个前所未有的开放政府”,究竟指的是什么呢?
奥巴马是哈佛大学法学院的高才生,他在就读期间,就担任了久负盛名的《哈佛法律评论》的主编;博士毕业之后,曾在律师行从业多年,还长期在哥伦比亚大学讲授《宪法学》。严谨的科班训练加上律师实务生涯,他的逻辑思维是非常严密的。
他用“前所未有”(unprecedented)来形容他将要开创的事业,是因为,他清楚地知道:透明无止尽。对政府而言,只有更透明,没有最透明。虽然联邦政府的文件、会议甚至数据都规定了可以公开,但近年来信息技术突飞猛进的发展,特别是互联网的兴起,不仅给信息公开的内容、也给公开的方式带来了新的机遇和挑战。
这是个技术奔腾、信息爆炸的时代。奥巴马领导的联邦政府,正是美国社会的信息中枢。他的雄心,有广袤的用武空间。
摩尔定律:全世界半个世纪的发展规律
摩尔定律已经成为工业界一切呈指数型增长事物的代名词。……下一个十年,摩尔定律可能还将有效……可以肯定的是,创新无止境。03
——戈登·摩尔,英特尔公司创始人,2003年
联邦政府是美国最大的雇主,共雇用了约200万名工作人员。04
联邦政府主要由三大块组成:一是总统行政办公室(The Executive Office of the President),二是15个内阁部门(Cabinet Department),三是70多个独立的联邦机构(Independent Agency)。
总统行政办公室的结构
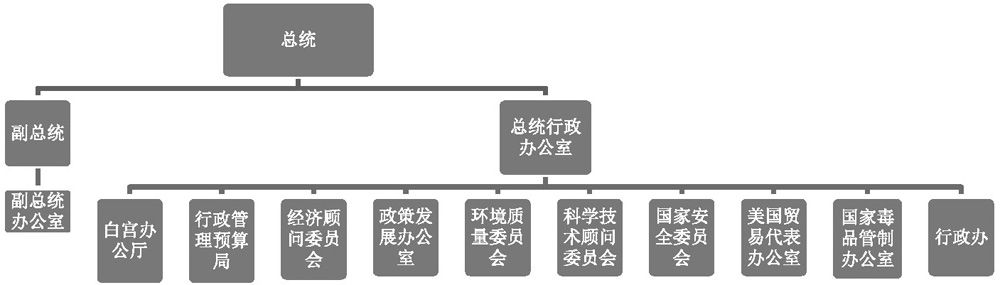
总统行政办公室是直接为总统服务的中枢部门。
其下辖白宫办公厅(The White House Office)、行政管理预算局(OMB)、经济顾问委员会(Council of Economic Advisers)、科学技术顾问委员会(PCAST)等机构。其中,最重要、最大的机构当属白宫办公厅和行政管理预算局,它们控制了信息、掌握了财权,是15个内阁部门和70多个独立机构的管理和协调单位,可谓中枢中的中枢。鉴于这两个机构的重要性,本书将会多次提及。
作为全美最庞大的组织和机构,联邦政府也一直号称他们是美国最大的信息生产、收集、使用和发布的单位。05
数据和信息的区别
很多情况下,“数据”和“信息”两个词经常替换使用。但严格地说,数据和信息这两个概念有很大的区别:
数据是对信息数字化的记录,其本身并无意义;信息是指把数据放置到一定的背景下,对数字进行解释、赋予意义。
例如:“1.85”是个数据,“奥巴马身高1.85米”则是一则信息。
但进入信息时代之后,人们趋向把所有存储在计算机上的信息,无论是数字还是音乐、视频,都统称为数据。
如果要考察信息的多少,就必须以物理存储器上保存的数据量作为度量。因为所有的信息,都是以数据的形式保存在物理存储器上的。由于人类的数据量不断增多,近几十年来,科学家也相应定义了一些新的名词,来表示新的存储单位,以方便对客观世界的描述。
美国联邦政府到底收集了多少数据,其总量无从得知,但我们可以从现有的一些研究资料中窥见一斑。
理解数据的存储单位
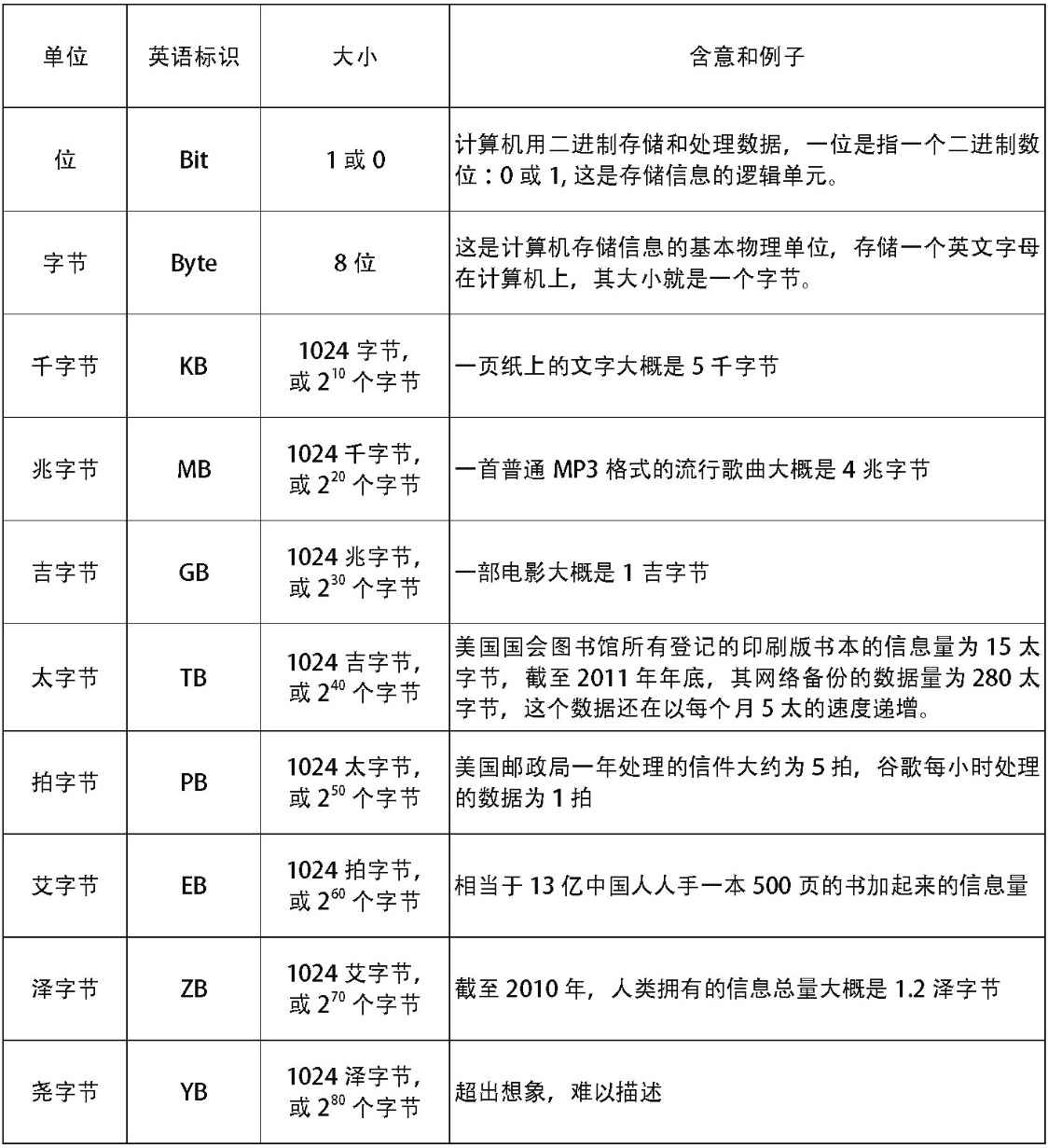
(部分例子参照了All too much,The Economist,2010年2月25日)
2009年美国各行业数据存储量对比
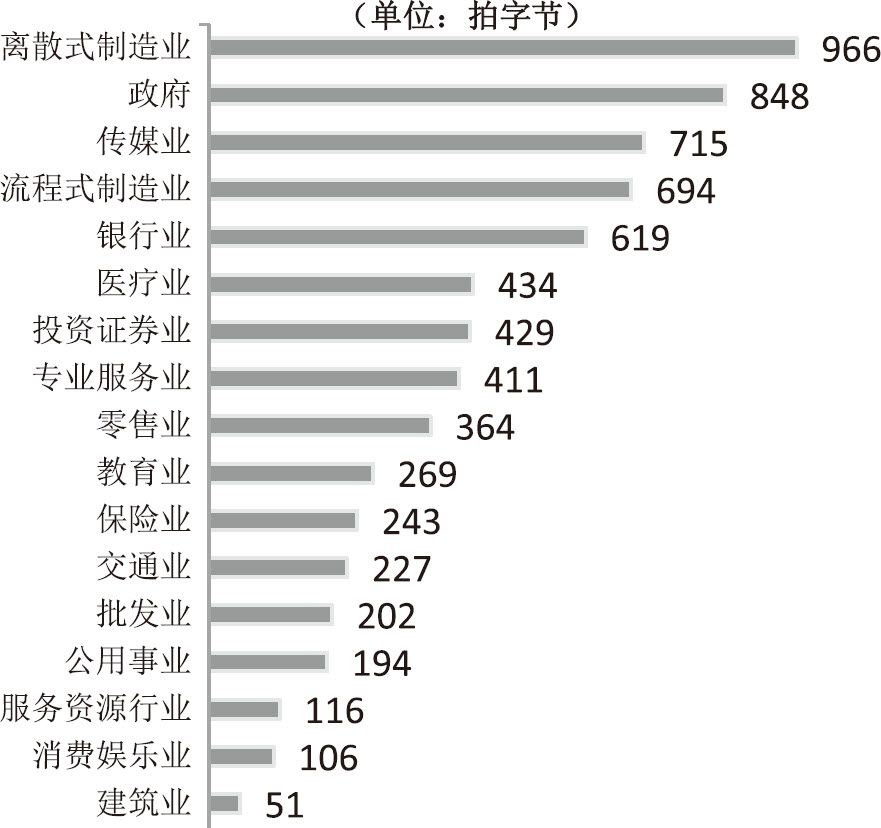
(数据来源:International Data Corporation)
2011年5月,麦肯锡公司下属的全球研究所(McKinsey Global Institute)出版了一份专门的研究报告《大数据:下一个创新、竞争和生产率的前沿》。06该报告对美国政府目前拥有的数据量进行了估算,在制造业、新闻业、银行业、零售业等17个行业当中,美国政府共拥有848拍字节(Petabyte)的数据总量,仅次于离散式制造业07的966拍,居第二位;居第三位的是新闻传媒业,共有715拍字节。
这是美国政府作为一个行业的总体情况,下面我们来考察联邦政府中具体的单个组织。
以商务部下属的美国普查局(USCB)为例,它目前拥有2560太字节(Terabyte)的数据。“太”,代表2的40次方,它的大小,已经大大超出了人类的直接感知能力,只能通过形象的比喻来描述:如果把这些数据全部打印出来,用4个门的文件柜来装,需要5000万个才能装得下。沃尔玛是世界上最大的零售王国,它每小时要处理100多万笔电子交易记录,可谓每分每秒都在源源不断地生产数据;2010年,其数据库大小为2500太字节左右,还没有赶上美国普查局。
除了美国普查局,国家安全局(NSA)和中央情报局(CIA)都拥有超级巨大的数据库。2011年5月,历经十年,美国人终于在巴基斯坦将本·拉登击毙,报了“9·11”的一箭之仇。帕拉契尼(John Parachini)是兰德(Rand)公司情报政策研究中心的主任,他在接受《巴尔的摩太阳报》的采访时介绍说,国家安全局是从电话监控的记录当中发现了本·拉登的蛛丝马迹。08该局对全美的电话进行监控,所收集的数据量是惊人的,它每6小时产生的数据量就相当于美国国会图书馆所有印刷体藏书的信息总量。而美国国会图书馆,是世界上馆藏量最大的图书馆。
再说中情局,其本职工作就是收集情报信息。业内专家普遍认为,其数据库比普查局、国安局的还要大,很可能拥有全世界最大的数据库。
普查局、国安局、中情局只是联邦政府数百个机构当中的几个例子,还有财政部、卫生部、劳工部,这些都是数据密集型的行政管理部门。即以财政部为例,根据行政管理预算局的信息收集年度报告,2009年,财政部因为收集信息产生的社会负担为76亿小时,占全部联邦政府收集信息社会负担总数的78%,09之所以如此,是因为收税和退税的过程极为繁琐,但76亿小时收集工作会产生多少数据量,其大小也难以想象。
再换一个角度,我们来看看这个联邦政府的硬件资产。
1998年,联邦政府共拥有432所数据中心,专门负责各类数据的存储和维护工作。2010年,数据中心的总数跃升到2094所,翻了几倍。
庞大的数据资产,是需要经费来支持的。1996年,联邦政府的年度IT预算是180亿美元,十多年来不断地上升,2010年,已经高达784亿美元;由于连年巨额的投资,联邦政府已经声称,他们是全世界范围之内最大的信息技术消费者。而据报道,这些投资中的一半以上,都用在了购买存储数据的硬件设备上。
这是一个不折不扣的数据帝国。
帝国形成的原因,已经有很好的解释,这就是摩尔定律(Moore's Law)。
1965年,英特尔(Intel)的创始人之一戈登·摩尔(Gordon Moore)考察了计算机硬件的发展规律,提出了著名的摩尔定律。该定律认为,同一个面积集成电路上可容纳的晶体管数目,一到两年将增加一倍,10也就是说,其性能将提升一倍。换句话说,计算机硬件的处理速度和存储能力,一到两年将提升一倍。
1971年至2011年不同中央处理器上的晶体管数量和摩尔定律
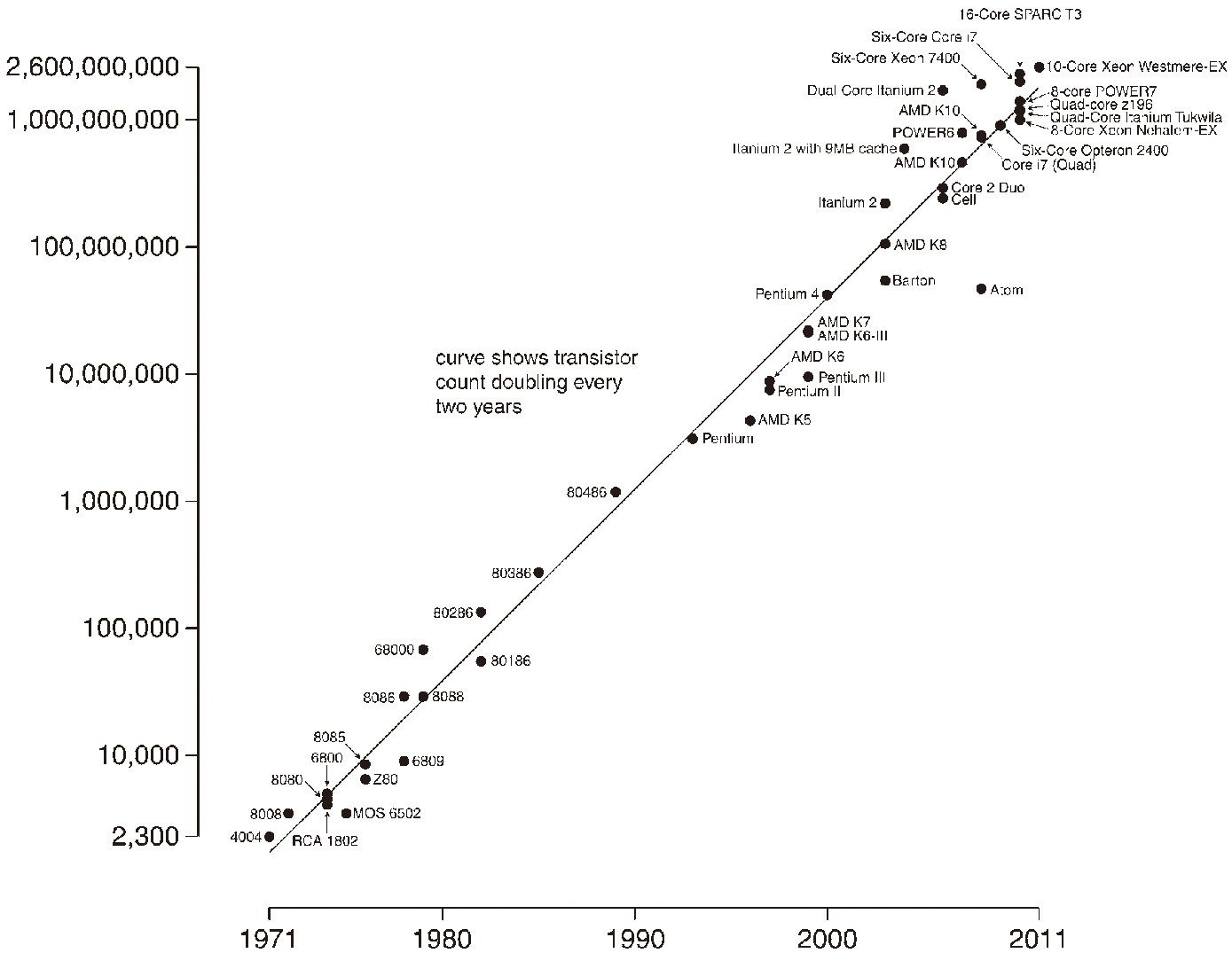
说明:纵坐标为晶体管数量,横坐标为年份。图中圆点表示不同品牌的中央处理器。该曲线表明,从1971年至2011年,大概每两年同一面积大小中央处理器集成电路上的晶体管就增加了一倍。(图表来源:维基百科)
回顾这近半个世纪的历史,硬件技术的发展,基本符合摩尔定律。摩尔定律的一个重要结果,是推动了全世界对物理存储器的消费;其消费量增加的速度,有学者认为,甚至比摩尔总结的硬件发展速度还要快,从1990年代起,全世界的物理存储器,每9个月就增加一倍。11

戈登·摩尔
出生于1929年,至今健在,他于1956获得加州理工学院的博士,1968年成为英特尔的创始人之一,也是摩尔定律的首创人。(图片来源:英特尔公司网页)
其中的原因,是因为物理存储器的性能不断提高,同时价格还不断下降。1955年,IBM推出了第一款商用硬盘存储器,每兆字节的存储量需要6000多美元。此后,硬盘存储器的价格以越来越大的加速度下降。1993年,购买1兆字节的存储量只需大概1美元;2010年,这个价格下降到不足1美分。多数专家都相信,计算机硬件的技术将持续发展,价格还将下跌,直到2020年,摩尔定律还将仍然有效。
计算机硬件这种令人“瞠目结舌”的发展速度,使全世界的数据处理和存储不仅越来越快、越来越方便,还越来越便宜,海量数据的积累最终成为可能。
但像盛水的杯子一样,存储器毕竟只是容器。关键的问题在于,帝国的数据从何而来?海量数据的源头在哪里?
美国联邦政府的数据来源,当然首先缘于它各个部门的业务工作,也就是业务数据。
作为社会管理和公共服务的提供部门,收集数据、使用数据,是自古以来全世界的政府都在普遍采用的做法。但政府开始大规模、系统地收集数据,其历史并不久远。在美国联邦政府的发展历史上,业务数据的收集,有一个重要的里程碑,这就是“最小数据集”。
最小数据集:上升到立法高度的开路先锋
一个好的数据结构和一个糟糕的代码,比一个糟糕的数据结构和好的代码要强多了。12
——埃里克·雷蒙
美国软件开源运动的领导者,1999年
最小数据集的概念起源于美国的医疗领域。
1973年,在国家生命健康统计委员会(NCVHS)的主导下,为了规范出院病人的信息收集工作,美国第一次制定了统一的出院病人最小数据集,既然是出院,核心的环节就是付钱,所以这些数据不久后又被用于创建统一的医疗账单(Uniform Bill,UB)。
1975年,美国医院协会(AHA)成立了国家统一账单委员会。经过了几年的讨论,1982年,该委员会出台了UB-82的数据格式,统一了全国的医疗账单格式。1992年,UB-82又被修改升级到UB-92,并被扩大应用到了医疗保险和索赔的领域。
由于其实用性,最小数据集的概念在医疗领域被迅速推广。近几十年以来,几乎每年都有新的最小数据集被定义、开发和推广。目前,已经被应用到眼科、牙科、皮肤科、妇科以及体检、护理、急救、住院等医疗服务的方方面面,衍生出各种各样的、特定的最小数据集。
随着时间的推移,“最小数据集”在美国已经演变成了一个一般性的概念,它指代国家的管理层面针对某个业务管理领域强制收集的数据指标。不少领域的“最小数据集”甚至被上升到立法的高度。例如,对于养老院的管理,美国国会就规定,每个养老院都必须提交一系列关于老人健康指标的最小数据集给州政府的医疗管理部门,该部门汇总之后,再提交联邦政府的管理部门。
当然,何为“最小”,政府的管理者、决策者和公共服务的提供方、接受方都有不同的需求和看法,很难达成一致。某一特定的数据指标是否应该纳入,不同的立场、视角、环境和管理水平都会导致不同的意见。而且,各个最小数据集本身可能是完整的、有效的,但当各行各业的最小数据集越来越多之后,从全局出发,它却不一定是合理的,因为可能存在更好的划分方法,使各个最小数据集之间具有更明确的边界和更少的重叠。
最小数据集(Minimum Data Set, MDS)
最小数据集是指通过收集最少的数据,最好地掌握一个研究对象所具有的特点或一件事情、一份工作所处的状态,其核心是针对被观察的对象建立一套精简实用的数据指标。
因此,每一个“最小数据集”的出台,都意味着多年的纷争和详尽的论证。
最小数据集的出现,最早是因为不同组织之间信息交换的需要,例如,两个医院之间,医院和政府医疗管理部门,医院和保险公司之间以及一些社会福利部门之间,都有交换信息的需要。随着最小数据集的推广,越来越多的社会组织、地方政府和联邦政府的业务部门之间都建立了标准的“数据接口”,从此彼此“数据”相连。
但到了1980年代,一场新的技术浪潮又把最小数据集的应用推上了新的高点。
这就是信息管理系统的兴起。
1975年,比尔·盖茨创办了微软。次年,史蒂夫·乔布斯成立了苹果电脑公司。之后,个人电脑、商业软件开始得到大面积普及,开发新的信息管理系统开始成为各行各业迈向信息化的主要措施。
所谓的“信息管理系统”,也就是实现某一特定业务管理功能的软件。
软件的构成,主要有两部分,一是程序(也可称为代码),二是数据(或称为数据库)。程序和数据的关系,就好像发动机和燃料,所有的程序,都是靠数据驱动的;数据之于程序,又好比血液之于人体,一旦血液停止流动,人就失去了生命,代码也将停止运行。
数据的生命力,甚至比程序更持久。程序可以不停地升级、换代甚至退出使用,但保存数据的数据库却会继续存在,其价值很可能与日俱增、历久弥新。世界万维网之父蒂姆·伯纳斯-李,曾经在2006年这样论述说:
“数据是宝贵的,它的生命力,比收集它的软件系统还要持久。”13
对于软件开发而言,数据库的设计甚至比程序的设计还要重要。埃里克·雷蒙,是美国软件开源运动的领袖,他在谈到代码和数据时曾表示:
“一个好的数据结构和一个糟糕的代码,比一个糟糕的数据结构和好的代码要强多了。”
最小数据集,其实就是一个业务管理过程当中最重要的数据指标。它在各个公共领域的定义和推广,成了这些部门在开发设计信息管理系统时最重要的一个参考,因为一旦核心的数据收集指标被确定,数据库的结构设计就成为一个水到渠成的过程。有些最小数据集,甚至直接就被引用,成为信息管理系统的数据结构。
就好像开路先锋,最小数据集为信息管理系统的开发和设计起了重要的铺垫作用。1970年代以来,随着计算机的普及,美国产生了越来越多的最小数据集,各种信息管理系统也开始大幅增加。截至2011年,美国的联邦政府已经拥有1万多个独立的信息管理系统。14
几乎每一项业务,每一个新的立法、新的计划,都会有一个数据库和信息管理系统与之对应。因为,没有任何一项工作,不涉及收集信息,而这些都离不开数据。
如今,联邦政府可谓事无巨细,都有一个信息系统在管理,其背后的数据库可谓五花八门,多不胜举。
例如,美国现在债台高筑、不断冲击上限,联邦政府甚至一度产生财务危机,奥巴马也为此头痛不已。联邦政府财政部下属的公共债务局(BPD)是国家债务的主管部门,要追踪这样一笔庞大国债的来龙去脉,该局自然拥有不少信息管理系统,其中,有一个是专门用来记录“捐款”的。
“欠债”和“捐款”,听起来似乎风马牛不相及。但在美国,两者还是拉上了关系,这是因为有些美国人试图通过自己的捐助来缓解国家的财政负担。公共债务局就为此专门建了一个信息系统,来记录美国公民为减少国债作出的个人捐赠。数据表明,2010财政年度,该局共收到2840466.75美元的捐款,2009年的捐款曾突破300万元,为3063057.05美元。捐款数量的下降,表明了人们的可支配收入在减少,也从另外一个侧面证明了美国经济确实在衰退。
历史上最大的一笔个人捐赠来自于2006年,一位俄亥俄州的老人在去世之后将自己价值110万美元的财产捐赠给了联邦政府公共债务局。当然,这些捐款,对于美国14.6万亿的债务来说,只是杯水车薪。但系统的管理,不仅笔笔在案、账目清晰,便于统计分析,也体现了对捐赠者的尊重。
民意几时有:选票催生的创新
我想要成就的事情,就是我的人民想要做的事情;我的任务,就是要准确地发现人民的需要。15
——亚伯拉罕·林肯,第16任美国总统
一般来说,业务数据都由下级部门和各类社会组织通过“数据接口”上报给联邦政府。
但作为一个中央政府,只接受数据是远远不够的,联邦政府也需要走出去,主动收集数据,了解全社会对某项政策的评价、单个公民对某个问题的看法,这就是所谓的民意调查、社会调查。
民意调查(Public Opinion Poll)
民意调查是指通过对一小群、有代表性人口的调查和访谈,预测社会全体公众对一些政治、经济和社会问题的态度和看法。其本质是“观一斑而知全豹”、“观一叶而知秋”。
美国的各种调查(Survey)之多,可谓铺天盖地,这些调查的直接目的,就是收集、掌握、分析反映民意和社情的第一手数据。

1948年,乔治·盖洛普登上《时代》杂志的封面。
这一年,杜威和杜鲁门竞选总统,盖洛普预测杜威将胜出。开票结果出来的当晚,《纽约时报》、《生活》、《芝加哥论坛报》等报刊都印刷好了杜威的照片,并题为“美国新总统”,但最终杜鲁门胜出。这次预测失败,又引起了人们对民意调查的质疑。盖洛普总结原因说:因为两人的民调一直相差太大,他们在大选前3周就提前结束了调查。此后,盖洛普持续改进调查的方法,最终在美国乃至在全世界都赢得了巨大的声誉。现在,盖洛普的品牌已经成为民意调查的代名词。
美国的民意调查最早源于对总统大选投票结果的预测。
1824年,位于宾夕法尼亚州的一家报纸Harrisburg Pennsylvanian第一次发布了关于谁能当选总统的预测。虽然其预测最后被证明是错误的,但却被大众一再津津乐道。
此后,各大报纸杂志都不想错过这个“抢眼球、聚人气”的话题,争相开展民意调查,以期准确地预测到底谁能当选总统,这开启了民意调查的时代。
蜂拥而上的结果,就是竞争。竞争的结果,就是民意调查的科学性不断提高,范围不断扩大;在20世纪30年代的美国,最终形成了一个社会调查的产业。
其中的转折点,是1936年。
这一年,第32任美国总统富兰克林·罗斯福为了争取连任,与共和党的兰登(Alfred Landon)对垒,打响了选战。
这时候,一本叫做《文学文摘》(Literary Digest)的杂志风头正劲。
《文学文摘》成立于1890年,其畅销的主要原因,是因为它准确地预测了1920、1924、1928、1932年等4届总统大选的结果,随着该杂志销售量的年年攀升,民意调查的热度和可信度也不断上升。
1936年,《文学文摘》在对240万普通公众进行了调查之后,把“宝”压在了兰登的身上。这个时候,一家刚刚成立不久的研究所,只对5000人进行了调查,却宣布罗斯福会胜出。
这家研究所就是1935年成立的美国舆论研究所(AIPO),它的奠基人,是美国民意调查科学化的先驱:乔治·盖洛普(George Gallup)。
罗斯福最终以大比分击败兰登,成功连任;盖洛普也取代了《文学文摘》,成了新的行业领袖。这一仗,成了《文学文摘》的“滑铁卢”,该杂志次年就宣布破产、退出市场。5000人的问卷击败了240万人的调查,盖洛普领导的美国舆论研究所当然随之身价倍增、名扬全国。
盖洛普的成功,根本原因在于他掌握了一套科学的人群抽样方法,而不是盲目的大面积访谈。此后,一大批新的、专业化的民意调查机构应运而生,调查方法的科学性不断增强。从1936年到2008年,共举行了18次总统选举,盖洛普民调(Gallup)成功地预测了16次。16
报纸举办民意调查,其目的是为了一“鸣”惊人,制造新闻效应,扩大报纸的声誉和销量。但对总统候选人来说,他们也要参考民意调查的结果,因为他们对民意的掌握,往往关系到选举的最终成败。
这是因为,在民主社会,谁上谁下,人民的选票有最终的话语权。
票多,则胜。
作为候选人,争取选票的唯一方法就是争取民意。要争取民意,首先就要了解民意。现代政治学中,有一个“中间选民理论”很好地解释了其中的奥秘。
中间选民理论(Median Voter Theory)
该理论也是在1940年代提出的。在选举中,所有的选民都有自己的个人偏好,这个偏好对应于平面坐标上的一点,全部选民的偏好将呈正态分布,也就是一个钟形曲线,这个曲线就是民意分布图。
每个选民最终都会把自己的选票投给与自己意见最接近的候选人。在多个候选人竞争的情况下,候选人想要胜出,就要争取最多的选票,他就必须找准民意最集中的地方,为最多的民众说话,这一点,就是民意的“中值”。
中间选民理论提出,民意有一个“中值”,而民意调查,正是帮助候选人找准民意“中值”的“阿拉丁神灯”。
罗斯福虽然在当选总统前就半身瘫痪,长期坐在轮椅上,但后世却常常把他和华盛顿、林肯相提并论,公认为美国历史上最伟大的总统之一。作为唯一一位连任过4届的总统,他深谙民意调查的作用和潜力。他不仅在竞选中应用民意调查,1940年,他还正式将民意调查的方法引进到了联邦政府的政策制定过程当中,成为美国历史上第一位将民意调查和公共政策相结合的总统。这些成就,使他成为美国历届总统当中至今无人超越的“民意大师”。
民意的“中值”和选票多少的关系
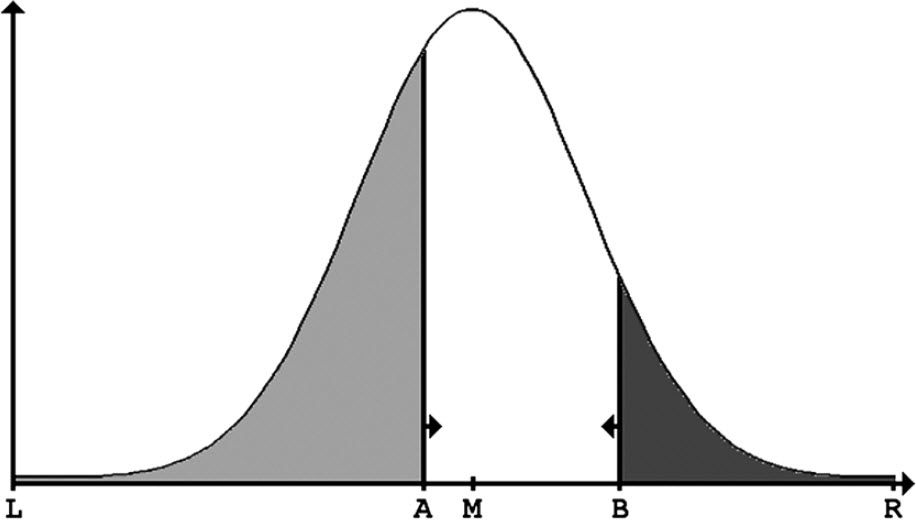
说明:图中的钟形曲线即代表民意的分布,左边浅色和右边深色的区域面积大小,分别代表候选人A和候选人B可以预期得到的选票多少。M代表民意的中值点,候选人A和B,谁能确定M点,不断向M点靠拢,谁就能获得更多的选票。
上图表明:候选人A比候选人B更接近民意的中值,将获得更多的选票。
罗斯福之后,几乎每一位美国总统,不论是竞选还是执政,都大规模地采用民意调查的方法。
随着计算机技术的不断发展、统计分析水平的提高,民意调查逐渐成了联邦政府了解社会、掌握民情最有效的工具和方法。调查的范围也不断扩大,从普通公民的观点和看法,慢慢延伸到个人的行为、事实和社会现象,最后发展成了更广泛意义上的社会调查。
到今天,可以说,联邦政府的各个职能部门都在开展社会调查。其中,有两个机构堪称联邦政府社会调查的“航空母舰”,它们每年开展无数大大小小的社会调查,其他机构都望尘莫及。这两艘“航空母舰”,一是劳工部下辖的劳工统计局(BLS),一是商务部下属的普查局(BC)。

富兰克林·罗斯福(1882-1945)
罗斯福从1921年起下半身全部瘫痪,但这位残疾人却在1933年至1945年连续4次当选总统,带领美国人走过了第二次世界大战的艰难时段。对于民意,他强调:不仅要掌握民意,还要领先民意一小步,才是民主政治中的胜选之道。(图片来源:维基百科)
劳工统计局对就业市场开展很多专业调查,其中最大的一种被称为“国家纵向调查”(National Longitudinal Survey)。所谓“纵向”,是指以时间轴为单位,在确定调查对象之后,对其进行长期的跟踪、反复的问卷,收集大量的数据,然后进行统计分析。
1966年,劳工统计局开展了美国历史上第一个国家纵向调查。调查对象是全国的男性,分为青年和老年两组,该局在全国范围内锁定了10245名男性,进行了长达24年的全方位跟踪调查,直到部分老人撒手归西为止。类似的国家纵向调查项目一共有4个。1997年最新铺开的一个,调查对象是1980年至1984年出生的青少年,简称为NLSY97(National Longitudinal Survey of Youth 1997),该局在全国范围内确定了约9000名青少年,每年都进行一次特定话题的跟踪问卷调查,至今还没有结束。
以1997年的青少年纵向调查为例,它跟踪调查的对象虽然是青少年本身,但受访人、问卷人却可以是家长、老师、雇主等等和该青少年密切相关的个人和群体,每次问卷都有数十个问题,需要受访人1小时左右才能完成。因为付出了时间,受访人在完成问卷之后,能获得8到20美元不等的报酬。同样的问题,也可能在不同的年份、在相同受访人员的问卷中重复出现,以测试受访人态度的变化。
NLSY97虽然是由劳工统计局负责实施,但却是一个综合项目,涉及青少年生活的方方面面,该局邀请了多个政府部门参与问卷的设计。例如,青少年犯罪预防办公室(OJJDP)隶属于美国司法部,是青少年犯罪问题的国家主管部门,他们帮助劳工统计局设计了有关青少年犯罪方面的问卷。就青少年犯罪而言,问题可能包括轻度违法记录、毒品滥用情况、酗酒情况、性行为、家庭成员的构成及背景、收入、教育、家庭关系、和父母的关系、青春期情况、约会情况、恋爱情况、生育情况、职业培训情况、接受社会福利项目的援助情况、个人时间管理、生活目标的变化、学习成绩、宗教活动、所住社区的人口特点、所在城市的经济特点,等等。
随着数据的积累,一幅以个人成长为中心、越来越大的社会画卷也开始展开。这种以一个国家为单位的大型社会调查,是研究一个社会长期变迁不可或缺的重要资源,也为政策的制定、调整和评价提供了重要的参考和依据。
另一艘“航母”是普查局。和劳工统计局相比,它的社会调查名目更多、范围更广。除了负责十年一次的人口普查之外,该局每年还在全国范围之内开展系统的行业调查,其中最著名的有:全国社区调查、全国消费者开支调查、全国医院调查、全国建筑调查、全国房屋调查,等等。
除了掌握民情、了解社会,问卷调查还是联邦政府评估资金使用绩效的主要工具。联邦政府每年都要下拨大量的专项资金,资金的使用效果和好坏,往往是来年是否继续拨款的决定性因素,联邦政府目前最重要的衡量手段,也是社会调查。
以卫生部下属的药物滥用和精神健康管理局(SAMHSA)为例,每年,该局都有专项基金,用于社区的毒品防治工作,全国的基层政府、公益组织都可以申请。但这笔钱也很“烫手”,拿了之后,有大量的问卷调查工作要开展、要上报。
社区的毒品防治工作主要是政策宣讲和培训。申领了专项资金的单位,就要开展培训,每个参加培训的人都要参加4次问卷调查,分别在培训开始前一次、培训中间一次、培训结束时一次,三个月以后还有一次。这些问卷调查的数据,基本都是通过互联网汇总上报。该局通过对比分析4次调查结果的具体指标,评估该单位的资金使用效果,再决定下期资金是否下拨。
联邦政府的这些调查,虽然目的不同、性质不同、方式不同,但最后产生的结果,无一例外,都同样是数据。
普适计算:计算机本身将从人们的视线中消失
最高深的技术是那些令人无法觉察的技术,这些技术不停地把它们自己编织进日常生活,直到你无从发现为止。17
——马克·韦泽,普适计算之父,1991年
1988年,互联网的概念刚刚兴起。这种新的信息共享方式,令全世界都兴奋不已。当时,绝大部分科学家,都还在品味和研究网络带来的巨大便利,沉浸在欣喜当中。
这时候,美国施乐公司(Xerox)的一名计算机科学家,却开创性地提出了“普适计算”(Ubiquitous Computing)的理论,为网络在人类未来生活中的作用以及计算方式的改变作出了前瞻性的预测。
他就是马克·韦泽(Mark Weiser)。
韦泽是密歇根大学毕业的计算机博士,青年时代就表现出杰出的天才。他毕业之后,曾经在马里兰大学任教8年,其后加入了施乐公司的帕罗奥多研究中心(PARC)。
帕罗奥多研究中心是全世界著名的创新中心,鼠标、激光打印机、以太网、语音压缩技术等等伟大的发明都在这里诞生。
韦泽领导了帕罗奥多研究中心计算机科学实验室的发展,1996年又担任了该中心的首席技术官。
韦泽认为,自从计算机发明以后,人类的计算方式,先后经历了两个阶段:一是主机型计算阶段(Mainframe Computing),指的是很多人共享一台大型机;二是个人型计算阶段(Personal Computing),指的是每一个人都可以拥有一台电脑。韦泽预测,由于网络技术的兴起,特别是无线网络技术的发展,计算机本身将从人们的视线中消失,计算将最终和环境融为一体。人们能够在任何时间和任何地点获取、处理信息,这就是普适计算的阶段,人类正在向这第三波计算浪潮迈进。
普适计算
通过在日常环境中广泛部署微小的计算设备,人们能够在任何时间和任何地点获取并处理信息,计算将最终和环境融为一体。这就是普适计算,是人类的第三波计算浪潮。
一句话:万事万物,凡存在,皆联网,凡联网,皆计算。

马克·韦泽(1952-1999)
曾为帕罗奥多研究中心首席技术官,被称为普适计算之父。
韦泽还是一名摇滚乐队的鼓手,在他的策划下,其乐队在1993年实现了美国互联网历史上的首次现场直播。他因此得名“摇滚乐队当中最聪明的鼓手”。(图片来源:维基百科)
实现普适计算的根本,是在人类生活的物理环境当中广泛部署微小的计算设备。
无处不在的微小计算设备和无处不在的互联网相结合,实现无处不在的信息自动采集、传递和计算。
这种微小的计算设备,就是传感器。近年来流行的物联网概念就是普适计算的最佳例子。
对于传感器及其网络的最早研究,始于美国国防部一个军事项目的研究,后来技术日臻成熟,传感器的应用逐渐从军事领域扩大到民用领域。
这可以追溯到20世纪60年代。
1962年,一场代号为“圣灰星期三”(Ash Wednesday)的风暴席卷了美国东海岸600多英里的海岸线,这场风暴持续了3天,影响了全美6个州,最后造成了40人死亡、1000多人受伤,导致了几亿美元的经济损失,被后人评为20世纪美国最严重的十大风暴之一。
由于损失惨重,美国国会对救灾防灾工作召开了专门的听证会,最后促成了军民联手的“海浪监测计划”:美国陆军工程部和美国国家海洋与大气管理局(NOAA)共同建设一个传感器监测系统,对兴风作浪的海洋进行监测。
这项计划的实施结果,是在全美海岸线和五大湖区建立了一个定点的、连续的、实时的传感器网络,对海浪的大小进行监控。受限于当时的技术,最早的传感器只能监测海浪的能量。从2005年起,美国国家海洋与大气管理局在浮标上装备了更高端的传感器,开始监测海浪的方向。
2009年,系统再次升级。该局开始着手建立一个覆盖全美海岸线、从浅水到深水的、精确的海浪监测网络。这个网络总共在近海、外大陆架、内大陆架和沿海设置了296个传感器。新的传感器不仅能监测海浪的能量和方向,还能计算它的传播速度、偏度和峰度。18
这些传感器以分秒为单位,将数据源源不断地实时传回到国家海洋数据中心(DODC)。
对海浪的监测,不仅能提高沿海地区对海啸、风暴等自然灾害的应急能力,还能极大地改善海上的交通安全。根据美国疾病防控中心(CDC)的统计,捕鱼业是美国最危险的职业之一,全美所有行业的平均致死率为0.004%,而捕鱼业的平均致死率高达0.155%,其中79%的死亡是天气变化的原因导致的。19
除了安全,海浪的监测还能为利用大海能量进行发电提供关键的分析型数据。
海浪监测只是联邦政府利用传感器网络自动采集数据、迈向普适计算的一个例子。事实上,由于无线传感器的快速发展,普适计算已经在美国的农业、运输、能源和建筑等领域逐步铺开。
2011年10月,联邦政府商务部下属的国家气象局(NWS)宣布,该局已经在全国2000辆客运大巴上装备了传感器,随着巴士的移动,这些传感器可以收集沿途所有地点的温度、湿度、露水、光照度等数据,并立刻传回国家气象局的数据中心。数据采集是每10秒钟一次,每天传感器要采集10万次以上的数据。这些数据是实时的、高精度的,这意味着,天气预报将不再仅仅是“预”报,将逐渐走向“实”报、“精”报。
此外,联邦政府国家邮政局(USPS)也宣布,他们正规划在全部邮车上安装传感器,在邮车投递邮件的同时,实时采集社区的空气质量、污染指数和噪声等数据指标。
有评论家感叹道:谁也没想到,汽车,这个工业时代的标志和先锋,如今又成为信息时代普适计算的“排头兵”。
近年来,传感器的发展可谓突飞猛进。一种新的无线传感器:射频识别标签(Radio Frequency Identification,RFID),正异军突起,也在美国联邦政府得到了大规模的应用。

薄如纸张的RFID

RFID动物耳标

更小更薄的RFID
(图片来源:网络)
RFID精巧轻便,既可以薄如纸张,也可以小如豆粒,却能无线存储、发送、读写数据,目前的应用主要集中在身份标识领域。以农牧业为例,1990年以来,全球各地陆续爆发动物疫情,2003年12月,美国发现了第一宗疯牛病病例。2004年起,联邦政府农业部启动了“全国动物身份识别系统”(National Animal Identification System)的项目,为全国的新生牲畜建档立户、配置射频识别耳标。通过这个移动传感器,对牲畜进行连续跟踪,一旦家畜疫情爆发,就能通过数据库追踪溯源,快速确定传染源和传播范围。美国现在已经装备射频识别耳标的家畜总数,无从得知,但可以肯定,这个数据库,也是海量级的。
从2005年起,美国食品与药品管理局(FDA)开始在药品上推行配备RFID的做法,以打击假药。美国国务院也开始颁发带有RFID标识的护照,以打击假护照,方便出入境的管理。
美国联邦政府通过传感器自动采集数据的例子,正在大幅增加。如果仅仅从数据量上来看,通过传感器自动采集的数据,已经取代了人工收集的业务数据,成为其最大的数据来源。还可以肯定的是,随着人类向普适计算不断迈进,通过传感器自动采集的数据将持续“爆炸”。
“大数据”战略:争夺全世界的下一个前沿
联邦政府的每一个机构和部门,都需要制定一个应对“大数据”的战略。20
——《规划数字化的未来:美国总统科学技术顾问委员会给总统和国会的报告》2010年
业务工作的管理数据,民意社情的调查数据,以及对大自然、动植物的特点和变化进行监控而产生的环境数据,是联邦政府的三大数据来源。这三种数据,其发展各有先后,收集方式各不相同,数据量也大小不一。它们之间,存在着一些交叉和重叠,有一些民意调查的数据,是业务数据,而一些因环境监控产生的数据,也可以是业务工作的数据。
联邦政府三种数据源的关系和数据量的大小比较
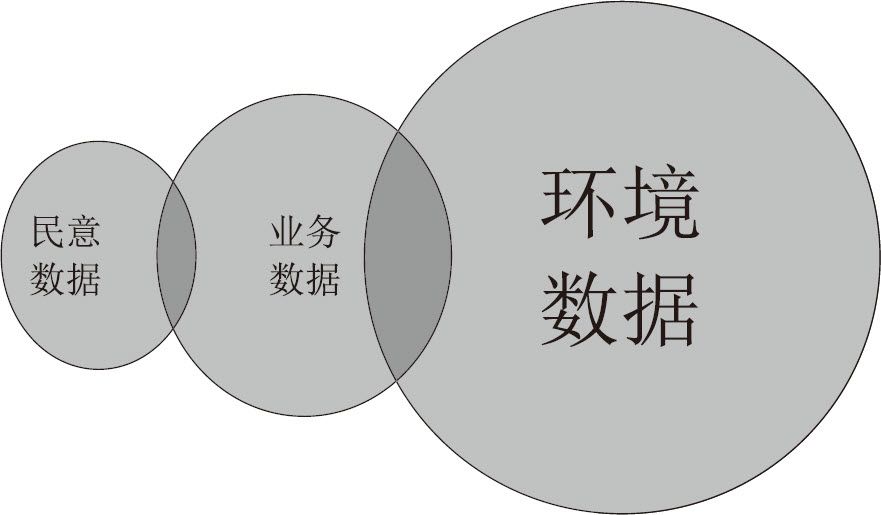
联邦政府三种数据源以及收集方式的对比

由于无线传感器的快速普及,环境数据增长得最快,成为联邦政府数据量最大的来源。
虽然环境数据增长得最快,但这三种数据,其实都在爆炸。这种爆炸,并不仅仅是数量一个维度的。2001年,著名的高德纳咨询公司(Gartner)在一份研究报告21中指出,数据的爆炸是“三维的”、是立体的,这三个维度,主要表现在以下三个方面:
一是同一类型的数据量在快速增大;
二是数据增长的速度在加快;
三是数据的多样性,即新的数据来源和新的数据种类在不断增加。
数据的爆炸性增长,也不仅仅限于联邦政府。如前文所述,2011年麦肯锡公司在其研究报告《大数据:下一个创新、竞争和生产率的前沿》中指出,在美国,仅仅制造行业就拥有比美国政府还多一倍的数据,此外,新闻业、银行业、医疗业、投资业、零售业都拥有可以和美国政府相提并论的海量数据。
哈尔·范里安(Hal Varian)是谷歌的首席经济学家,也是美国研究信息经济学的著名学者。2000年,他对数据和信息产生的速度进行了研究,他认为,人类社会每年产生的信息量,实在太大了,已经没办法用准确的方法来计算现有的数字信息总量,只能估算。他估计2000年新产生的数据量为1000拍到2000拍。但到2010年,仅仅全球企业一年新存储的数据量就超过了7000拍,而全球消费者新存储的数据量约为6000拍。
数据的三维增长
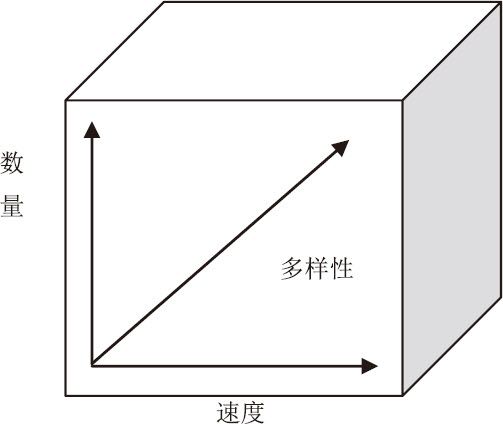
这种数据量的增长,已经大大超出了人类的预期和想象。时至今日,数据已经像“洪流”一样,在全球的政治、经济生活当中奔腾。而且,随着信息技术的普及和进步,新的支流还在不断产生,各个支流流动、交汇和整合的速度,还在继续加快。
作为美国社会的信息枢纽,联邦政府当然要正面迎对这个挑战。
2010年12月,总统行政办公室下属的科学技术顾问委员会(PCAST)、信息技术顾问委员会(PITAC)向奥巴马和国会提交了《规划数字化未来》的专门报告,该报告把数据收集和使用的工作,提到了战略的高度。
这个报告列举了5个贯穿各个科技领域的共同挑战,报告指出“每一个挑战都至关重要”,而第一个挑战就是“数据”问题。报告说:
“如何收集、保存、维护、管理、分析、共享正在呈指数级增长的数据是我们必须面对的一个重要挑战。从网络摄像头、博客、天文望远镜到超级计算机的仿真,来自于不同渠道的数据以不同的形式如潮水一般向我们涌来。这些数据以不同的格式存储在不同的环境中,有的在计算机的硬盘里,有的在数据仓库之内。
如何保证这些数据现在、将来的完整性和可用性,我们面临着很多的问题和挑战。如何使用这些数据,则是另外一个挑战……应对好这些挑战,将引导我们在科研、医疗、商业和国家安全方面开创新的成功。”
在报告中,两个委员会还例举了美国癌症研究所以及中央情报局如何通过收集海量数据、建立数据仓库、实施以数据挖掘为核心的自动分析技术,获得了出人意料的创新和成功。
委员会一致认为,如何有效地利用数据将贯穿所有科技领域的挑战。最后,两个委员会向奥巴马建议:联邦政府的每一个机构和部门,都需要制定一个“大数据”的战略。
大数据(Big Data)
大数据是指那些大小已经超出了传统意义上的尺度,一般的软件工具难以捕捉、存储、管理和分析的数据。
但是,具体多大的数据才能称为“大”,并没有普遍适用的定义。一般认为,大数据的数量级应该是“太字节”(240)的。麦肯锡全球研究所认为,我们并不需要给“什么是大”定出一个具体的“尺寸”,因为随着技术的进步,这个尺寸本身还在不断地增大。此外,对于各个不同的领域,“大”的定义也是不同的,无需统一。
其实,“大数据”这个名词并不新鲜,早在1980年代,美国就有人提出了“大数据”的概念。20多年来,各个领域的数据量都在迅猛增长,美国的企业界、学术界也不断地对这个现象及其意义进行探讨,“大数据”这个名词变得越来越流行、越来越重要,最后成为了国家和政府层面的发展战略。
之所以要称之为战略,是因为“大数据”之“大”,并不仅仅在于其“容量之大”。当然,由于数据容量的爆炸,数据的收集、保存、维护以及共享等等任务,都成为具有研究意义的现象和挑战。但“大数据”之“大”,更多的意义在于:人类可以“分析和使用”的数据在大量增加,通过这些数据的交换、整合和分析,人类可以发现新的知识,创造新的价值,带来“大知识”、“大科技”、“大利润”和“大发展”。
如前文所述,数据,是记录信息的载体,是知识的来源。数据的激增,意味着人类的记录范围、测量范围和分析范围在不断扩大,知识的边界在不断延伸。
2007年,雅虎的首席科学家沃茨博士在《自然》上发表了一篇文章《21世纪的科学》22,他发现,得益于计算机技术和海量数据库的发展,个人在真实世界的活动得到了前所未有的记录,这种记录的粒度23很高,频度在不断增加,为社会科学的定量分析提供了极为丰富的数据。由于能测得更准、计算得更加精确,他认为,社会科学将脱下“准科学”的外衣,在21世纪全面迈进科学的殿堂。例如,新闻的跟帖、网站的下载记录、社交平台的互动记录等等都为政治行为的研究提供了大量的数据,政治学这门古老的学科,将登堂入室,成为地道的“科学”。
麻省理工学院的教授布伦乔尔森(Erik Brynjolfsson)则比喻说,大数据的影响,就像4个世纪之前人类发明的显微镜一样。显微镜把人类对自然界的观察和测量水平推进到了“细胞”的级别,给人类社会带来了历史性的进步和革命。24而大数据,将成为我们下一个观察人类自身社会行为的“显微镜”和监测大自然的“仪表盘”。
这个新的显微镜,将再一次扩大人类科学的范围,推动人类知识的增长,引领新的经济繁荣。麦肯锡全球研究所在其2011年的报告中最后概括说:大数据,将成为全世界下一个创新、竞争和生产率提高的前沿。
抢占这个前沿,无异于抢占下一个时代的“石油”和“金矿”。
2012年3月29日,奥巴马政府又进一步推进了其“大数据”战略。奥巴马的高级顾问、总统科学技术顾问委员会(PCAST)的主席霍尔德伦(John Holdren)代表国防部、能源部等6个联邦政府部门宣布,将投入2亿多美元立即启动“大数据发展研究计划”(Big Data Research and Development Initiative),以推动大数据的提取、存储、分析、共享和可视化。霍尔德伦也是哈佛大学肯尼迪政府学院的知名教授,他在讲话中表示:像美国历史上对超级计算和互联网的投资一样,这个大数据发展研究计划将对美国的创新、科研、教育和国防产生深远的影响。
奥巴马则强调联邦政府必须和公司、大学结盟,全民动员(All Hands on Deck),来应对“大数据”时代的挑战。
人类知识的三大种类与科学的关系
人类所有的知识,可以划分为三个大类:自然科学、社会科学和人文艺术。
自然科学的研究对象是物理世界,讲的是“精确”,丝毫不能含糊,卫星上天、潜艇下海,差之毫厘,就会谬以千里。
社会科学研究的是社会现象,探讨的是人和社会的关系,如经济学、政治学、社会学,它也追求精确,但因为关系到多变善变的人,导致了“测不准”,所以社会科学又被称为“准科学”。
人文艺术则主要包括文学、艺术、哲学,它探讨的是人的信仰、情感和价值,并不强调精确,有时候甚至模糊就是美,所以位于科学的最外围。
在科学的谱系里,社会科学正好介于自然科学和人文艺术之间。
注释
01 机器学习(Machine Learning),是人工智能的一个分支,通过在大量数据上运行分析程序,达到让计算机自动学习、积累智能的目的。 02 Designing a Digital Future, Page. xvii, The President's Council of Advisors on Science and Technology, Dec 2010. 03 英语原文为:“Moore's Law has been the name given to everything that changes exponentially in the industry. Another decade is probably straightforward…There is certainly no end to creativity.”—Gordon Moore, February 2003 04 数据来源于美国劳工部对于联邦政府的介绍网页:With about 2.0 million civilian employees, the Federal Government, excluding the Postal Service, is the Nation's largest employer. http://www.bls.gov/oco/cg/cgs041.htm 05 从1996年起,美国联邦政府就认为自己是美国最大的单个信息生产、收集、使用和发布方,见OMB Circular A-130。 06 Big data: The next frontier for innovation, competition and productivity, McKinsey Global Institute, May 2011. 07 离散式制造业(Discrete Manufacturing)是指将不同的现成元部件装配加工成较大型系统的行业,例如汽车行业。流程式制造业(Process Manufacturing)是指通过一条生产线将原材料制成可以出售的成品的行业,比如制药。 08 Md.-based intelligence agencies helped track Bin Laden, 05-7- 2011, Scott Calvert, The Baltimore Sun. 09 本书第五章第一节将会具体解释这个负担小时的计算方法。数据来源为:Information Collection Budget Of The United States Government,Office of Management and Budget,2010。 10 摩尔1965年发表该定律时,认为这个周期是1年,1975年,他修订为2年;也有人认为,这个周期是18个月。 11 “The capacity of digital data storage worldwide has doubled every nine months for at least a decade, at twice the rate predicted by Moore's Law for the growth of computing power during the same period.”Fayyad, U. and Uthurusamy R., Evolving data mining into solutions for insights, Communications of the ACM, Vol. 45, No. 8, 2002, pp. 28-31. 12 英语原文为:“Smart data structures and dumb code works a lot better than the other way around.”—The Cathedral and the Bazaar, Eric Steven Raymond, 1999 13 英语原文为:“Data is a precious thing and will last longer than the systems themselves.”— Tim Berners-Lee, www2006 conference BCS interview, 2006 14 Uncle Sam's first CIO, Fortune Magazine, Interview by Geoff Colvin, July 13, 2011. 15 英语原文为:“What I want to get done is what the people desire to have done, and the question for me is how to find that out exactly.”— Abraham Lincoln 16 Election Polls—Accuracy Record in Presidential Elections, Gallup, http://www.gallup.com/poll/9442/election-polls-accuracy-record-presidential-elections.aspx. 17 英语原文为:“The most profound technologies are those that disappear. They weave themselves into the fabric of everyday life until they are indistinguishable from it.”—The Computer for the 21st Century, Mark Weiser, 1991. 18 A National Operational Wave Observation Plan, NOAA and USACE, March 2009. 19 Commercial Fishing Fatalities — California, Oregon, and Washington, 2000-2006, Centers for Disease Control and Prevention, April 2008. 20 原文为:“Every federal agency needs to have a ‘Big Data’ strategy.”—Designing a Digital Future, Page. xvii, The President's Council of Advisors on Science and Technology, Dec 2010. 21 3D Data Management: Controlling Data Volume, Velocity and Variety, Laney, Douglas. Feb 2001. 22 A twenty-first century science, Nature 445, 489; 1 February 2007, Duncan Watts. 23 数据粒度是指数据的细化程度。细化程度越高,粒度就越小;相反,细化程度越低,粒度级就越大。 24 The Age of Big Data, New York Times, Steve Lohr, February 11, 2012.